ctr预估
背景
以电商场景优化用户点击为例,推荐系统的任务是从海量的候选商品中选出用户最感兴趣且最可能点击的商品。为了提升检索的效率,通常分为两阶段来检索。召回/候选生成(Matching/Candidate Generation)阶段根据U2I相关性从整个候选集中筛选出少量的候选商品(比如1000个),常用协同过滤方法。排序(Ranking)阶段根据排序模型预估这小部分候选商品的CTR,排序后展示给用户。
推荐系统中CTR预估的重要性不言而喻,其中个性化是提升CTR模型效果的关键。本文介绍一种全新的排序模型,主要的思想是融合Match中的协同过滤思想,在Rank模型中表征U2I的相关性,从而提升模型的个性化能力,并取得不俗的效果。
搜索场景中用户通过输入搜索词显式地表达用户的意图,而推荐场景中没有这种显式获取用户意图的方式。用户的意图往往隐藏在用户行为序列中,可以说用户行为序列就是推荐中的query。因此,对用户行为序列进行建模来抽取其中的用户意图就非常重要。DIN[1]以及DIEN[2]等后续工作关注用户兴趣的表征以提升模型效果,而我们的工作在此基础上又往前走了一步,关注U2I相关性的表征。U2I相关性可以直接衡量用户对目标商品的偏好强度。可以理解成从用户特征(用户兴趣表征)到U2I交叉特征(U2I相关性表征)的升级。
表征U2I相关性很容易想到召回中的协同过滤(CF)。I2I CF是工业界最常见的方法,预计算I2I的相似度,然后根据用户的行为和I2I相似度间接得到U2I相关性。因子分解(factorization)的方法更加直接,通过用户表征和商品表征的内积直接得到U2I相关性,这里暂且称这种方法为U2I CF。最近有一些深度学习的方法进入到相关领域:比如I2I CF中有NAIS[7],用attention机制区分用户行为的重要性,和DIN[1]的做法相似;U2I CF中有DNN4YouTube[3],把召回建模成大规模多分类问题,也就是常说的DeepMatch。DeepMatch可以看做factorization技术的非线性泛化。我们根据协同过滤中的U2I CF和I2I CF分别构建了两个子网络来表征U2I相关性。
模型介绍
DMR(Deep Match to Rank)模型的网络结构如图所示。仅仅依靠MLP隐式的特征交叉很难捕捉到U2I的相关性。对于输入到MLP中的U2I交叉特征,除了手工构建的U2I交叉特征,我们通过User-to-Item子网络和Item-to-Item子网络来表征U2I相关性,进一步提升模型的表达能力。

User-to-Item网络
受factorization方法的启发,我们用user representation和item representation的内积来表征U2I相关性,这可以看做是一种显式的特征交叉。user representation根据用户行为特征得到,一种简单的方法是做average pooling,即把每个行为特征看得同等重要。我们考虑到行为时间等context特征对行为重要性的区分度,采用attention机制,以位置编码(positional encoding,参考Transformer[4])等context特征作为query去适应性地学习每个行为的权重。其中位置编码行为序列按时间顺序排列后的编号,表达行为时间的远近。公式如下:

其中pt∈Rdppt∈Rdp是第tt个position embedding,et∈Rdeet∈Rde是第tt个用户行为的特征向量,Wp∈Rdh×dpWp∈Rdh×dp,We∈Rdh×deWe∈Rdh×de,b∈Rdhb∈Rdh and z∈Rdhz∈Rdh是学习参数,αtαt是第tt个用户行为的归一化权重。通过weighted sum pooling,得到定长的特征向量,然后通过全连接层进行非线性变化得到user representation,以匹配item representation的维度dvdv。最终的user representation u∈Rdvu∈Rdv可以定义为:

其中函数g(⋅)g(⋅)代表非线性变换,输入维度dede,输出维度dvdv, htht是第tt个用户行为的带权的特征向量。
目标item representation直接通过embedding lookup得到,这个embedding矩阵V′V′是单独的一个矩阵,用于输出端,和输入端的item使用的embedding矩阵VV不同(类似于word2vec[6]中一个单词有输入和输出两种表征)。有了user representation和item representation,我们用内积来表征U2I相关性:

我们希望rr越大代表相关性越强,从而对CTR预测有正向的效果。然后从反向传播的角度考虑,仅仅通过点击label的监督很难学出这样的效果。另外,embedding矩阵V′V′的学习完全依赖于唯一的相关性单元rr。基于以上两点,我们提出了DeepMatch网络(即图中最后侧的Auxiliary Match Network),引入用户行为作为label监督User-to-Item网络的学习。
DeepMatch网络的任务是根据前T−1T−1个行为预测第TT个行为,是一个大规模多分类任务,有多少候选商品就有多个分类。根据上述用户表征的形式,我们可以获得前T−1T−1个用户行为对应的user representation,记作uT−1∈RdvuT−1∈Rdv。用户在发生这T−1T−1个行为后,下一个点击商品jj的概率可以用softmax函数来定义:
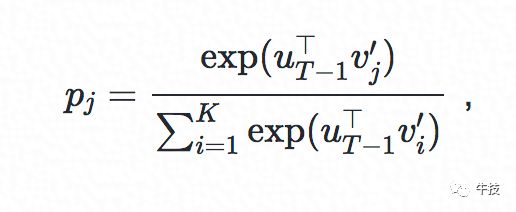
其中v′j∈Rdvvj′∈Rdv第jj个商品的(输出)表征。目标商品的输出表征 V′∈RK×dvV′∈RK×dv实际上就是softmax层的参数。以交叉熵为损失函数,我们有以下损失:

其中yij∈{0,1}yji∈{0,1}代表第II个样本的第jj个商品的label,pijpji是相应的预测结果,KK是不同的分类数,也就是商品数。yij=1yji=1当且仅当商品jj是用户行为序列中的第TT个行为。考虑到softmax的计算量太大,正比于商品总数KK,采用negative sampling的方法来简化计算,损失变为如下形式:

其中σ(⋅)σ(⋅)是sigmoid 函数, v′ovo′是正样本, v′jvj′是负样本, kk是采用的负样本数,远小于总体商品总数KK。DeepMatch的loss会加到MLP最终的分类loss上。DeepMatch网络会促使更大的内积rr代表更强的相关性,从而帮助模型的训练。实际上,User-to-Item Network是Ranking模型和Matching模型以统一的方式进行联合训练。这和简单地将召回阶段的match_type、match_score等特征加入到排序模型中不同。召回阶段通常是多路召回,不同召回方式的分数不在同一个metric下,无法直接比较(比如swing和DeepMatch的分数不能直接比较)。DMR通过User-to-Item网络能够针对任意给定的目标商品表征U2I相关性,且可以相互比较。
Item-to-Item网络
User-to-Item网络通过内积直接表征U2I相关性,而Item-to-Item网络通过计算I2I相似度间接表征U2I相关性。回忆一下DIN[1]等模型中的target attention,即以目标商品为query对用户行为序列做attention,区分出行为的重要程度。我们可以把它理解成一个I2I的相似度计算,和目标商品更相似的用户行为商品获得更高的权重,从而主导pooling后的特征向量。基于这样的理解,我们将所有的权重(softmax归一化之前)求和就得到了另一种U2I相关性表达。公式如下:
![]()
Item-to-Item网络使用additive attention[5]形式计算,区别于User-to-Item的内积形式,可以让增强表征能力。
除了U2I相关性表征,Item-to-Item网络也将target attention后的用户表征输入到MLP中。DMR如果没有U2I相关性表征以及positional encoding,则和DIN[1]模型基本相同。
实验
我们在阿里妈妈的公开数据集,以及1688为你推荐的生产数据集上做了一系列实验,验证模型整体的效果并且探索某个模块对模型的影响。
离线实验
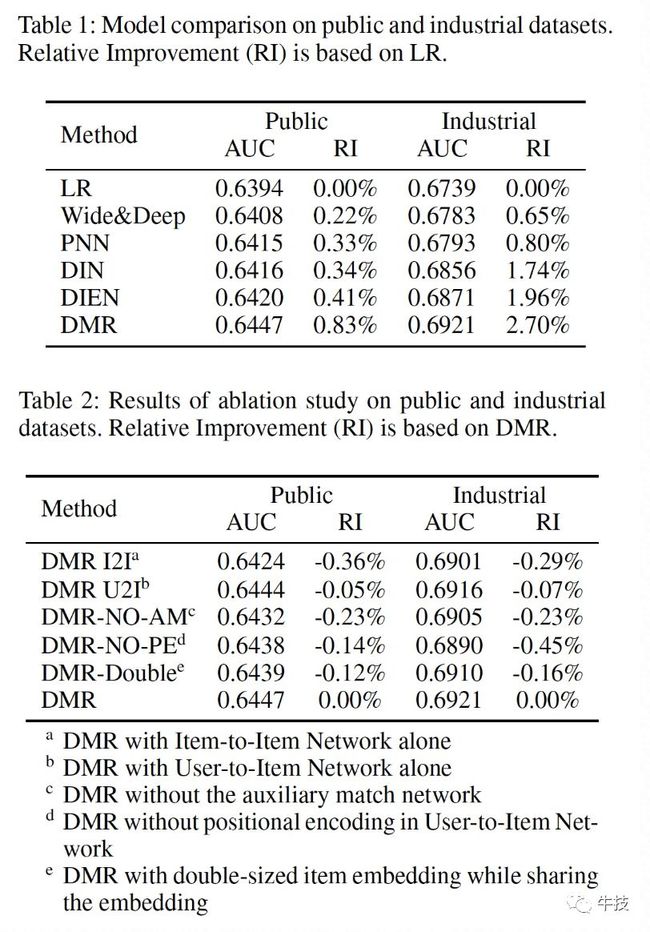
线上实验
我们在1688为你推荐上线DMR模型,对比模型是DIN[1](我们上一个版本的CTR模型),CTR相对提升5.5%,DPV相对提升12.8%,目前已经全量。
成果和展望
最初产生融合Matching和Ranking的想法是在4月份的时候,通过实验不断完善,在8月份拿到不错的线上效果,9月份论文投稿(Deep Match to Rank Model for Personalized Click-Through Rate Prediction),11月被AAAI-20录用(Oral)。背后是点滴的积累和团队的帮助。
DMR提供了一个Matching和Ranking联合训练的框架,U2I相关性表征的模块可以很容易嵌到现有的CTR模型中,相当于在你原来的模型上加了一些有效的特征。我们后续的CTR模型迭代会基于DMR的框架不断加入新的改进。
参考资料
[1] Deep Interest Network for Click-Through Rate Prediction - KDD18
[2] Deep Interest Evolution Network for Click-Through Rate Prediction - AAAI19
[3] Deep Neural Networks for YouTube Recommendations - ResSys16
[4] Attention Is All You Need - NIPS17
[5] Neural Machine Translation by Jointly Learning to Align and Translate - ICLR15
[6] Distributed Representations of Words and Phrases and their Compositionality - NIPS13
[7] NAIS - Neural Attentive Item Similarity Model for Recommendation - TKDE18