深度学习(13): Anomaly Detection(异常侦测)
Anomaly detection(异常侦测)
让机器可以知道我不知道这件事情
Problem Formulation
定义一个函数侦测输入的数据集x和训练集的相似度

不一定detect不好的东西,只是找和训练资料不一样的东西。
Different approaches use different ways to determine the similarity
What is Anomaly?
取决于你提供给机器的训练资料

Applications
- Fraud Detection training data:正常刷卡,x:盗刷
- Network Intrusion Detection training data:正常联系,x:攻击行为?
- Cancer Detection Training data:正常细胞,x:癌细胞
Binary classification?
Train a binary classifier

并没有那么简单,很难把异常侦测视为普通的二分类问题

不属于训练集的数据太多了,无法把这些异常的资料都定义为一个class,异常的资料变化太大了,很难collect 异常的data。
Categories

有label的:
利用labeled data训练出一个classifier
所有的label里都没有unknown,但希望classifier对于x不在training data里的输出一个unknown类别。
叫做open-set recognition
没有label的:
- clean:所有的训练集都是normal
- polluted:有一些训练集的数据是异常的
Case 1:with classifier
每一个training data的x都有一个label值
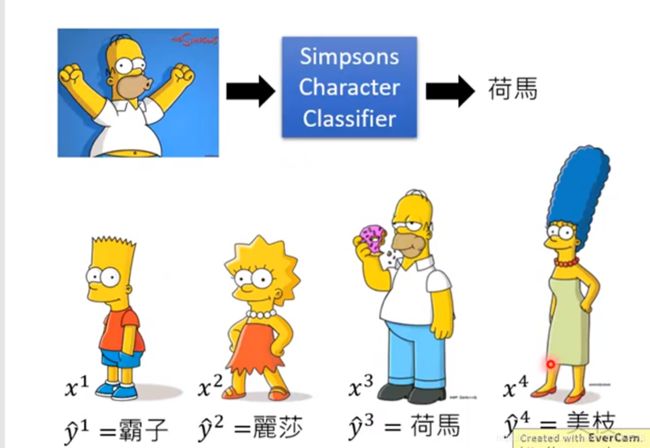
how to use the classifier
不止做分类,还会output一个信心分数 C
当信心分数小于threshold时,该输入x可当作一个异常点


- output是一个distribution,如果输出的结果是某一个值很突出时,可以算是confidence score很高的输入
- 如果distribution的分布率很均匀,则c很低,即该input被视作异常值
信心分数的确定
Confidence:the maximum scores
计算entropy,如果entropy越大,不确定性越强,则distribution分布很平均。
实验结果


Network for confidence estimation
Learning a network that can directly output confidence
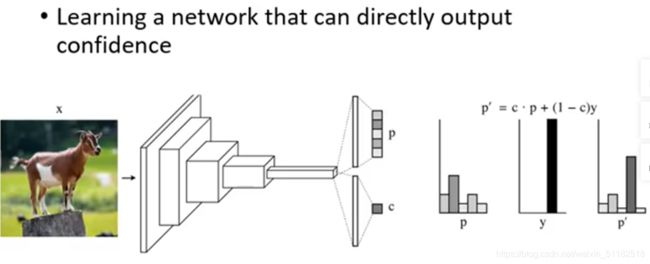
输出分类+信心分数
Framework
Dev set:模仿testing test,如果属于辛普森家族的人物,不需要知道他是哪一个具体的人物,只需要知道是或者不是。
在dev set上侦测classifier的性能,用dev set 去调参

如何计算一个异常侦测系统的performance好坏
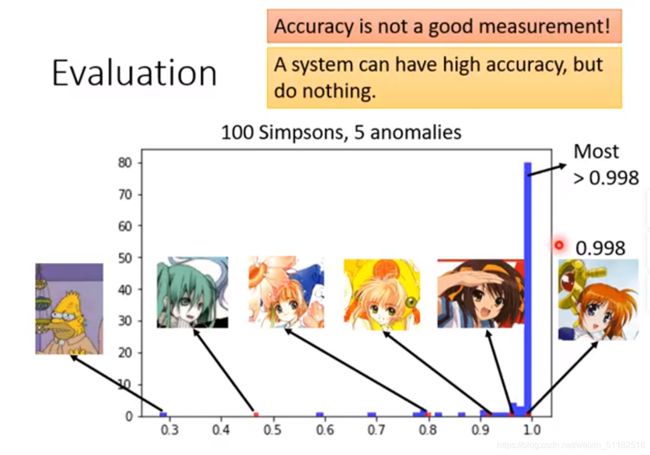
在binary classification中用正确率作为好坏
有时正确率并不是一个好的方式。
有的系统可能正常的有100张,异常的只有5个,这会使分类的正确率很高,但并不是一个很好的系统
set a lambda,正确率高达95.2%。只是因为日常的资料很少。
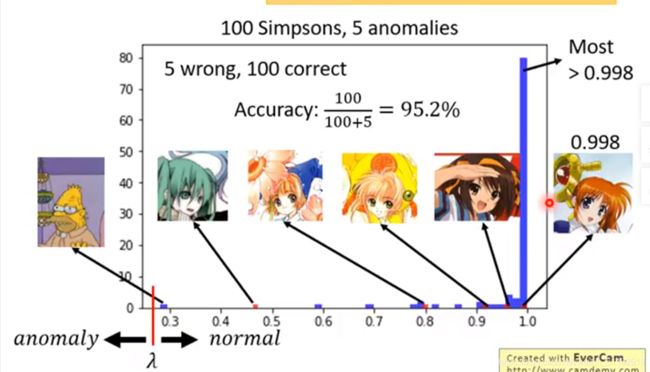
不要用正确率作为evaluation measure
- 异常的被判断为正常
- 正常的被判断为异常
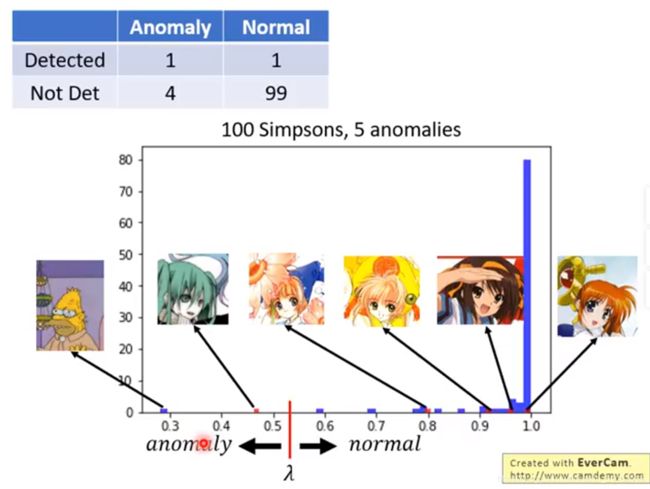

换一个阈值

第一种情况:1个false alarm,四个missing
第二种:6个false alarm,3个missing
set cost table
对于false alarm更加在意

对于missing更在意,有一个missing扣100分
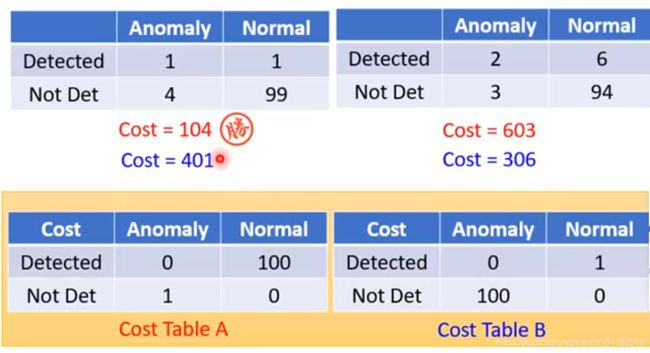
根据不同的任务可以有不同的cost table,如果做癌症检测,倾向于对missing更在意,对于错查,忽略了真正的癌症病例更严重。

AUC也可以用来衡量一个evaluation metrics
Possible issues
对于猫和狗的分类:
对于既没有猫和狗的特征,只能把它放在boundary上,信息分数很低
对于和猫类似,和狗类似的,比如老虎和狼。机器无法识别出与normal class 相似度很高的 输入数据

How to solve
如果在异常数据上加入一些normal class的特征,那么系统会有更高的概率missing 异常数据

解决方法:
- 不要让机器只分类,让机器对于正常的给与高的信心分数,对于异常值给与低的信心分数。但收集异常data很难
- 学习一个生成模型来生成很多的异常数据。

Case 2:without labels
Twitch plays pokemon

Problem Formulation
- 需要训练资料
- 找到一个函数训练input x

- 只有大量的x,但是没有y
- 建立一个模型输出p(x)

相比于case1有label的情况使用信心分数来评判输入x是normal还是异常,没有label的情况下,生成一个概率模型,概率大于某个阈值设为正常,小于阈值设定为异常。这个阈值有开发者手动决定。

将每一个玩家用二维向量描述,一个代表说垃圾话,一个代表无政府状态发言
可以观察每个维度上的概率分布


数据集x的概率分布可观察到
使用极大似然估计
假设这些样本数据由一个函数构成
- θ \theta θ决定了函数的形状
- θ \theta θ不知道,需要根据训练资料找到
- f θ ( x ) f_{\theta}(x) fθ(x)是一个概率密度函数
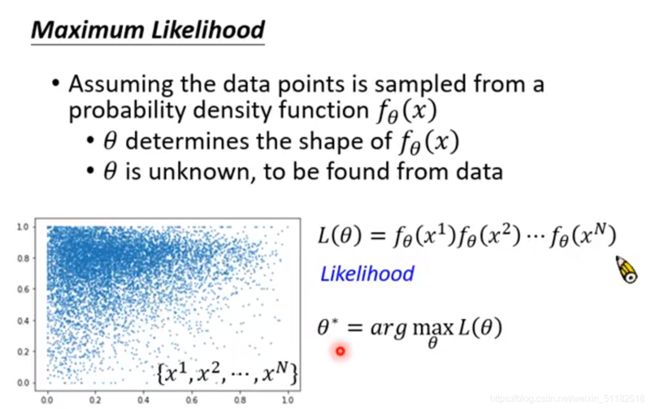
计算likelihood
找到 θ \theta θ使似然函数最大
将概率密度分布设定为混合高斯分布,此时的 θ \theta θ为mean和 covariance matrix
- input:x vector
- output:x被采样到的几率


极大似然估计对mean和covariance分别就偏导后找到似然函数最大值下的mean和covariance

定义好了f(x)的模型后,就可以对数据集里的值进行分类:normal和anomaly。

可以选定更多的feature:


还可以使用auto-encoder


因为training data训练的都是辛普森一家
所以在test中表现好的更有可能是辛普森一家,表现不好的有很大概率是异常值
more
