ICLR21(classification) - 未来经典“ViT” 《AN IMAGE IS WORTH 16X16 WORDS》(含代码分析)
文章目录
-
- 原文地址
- 论文阅读方法
- 初识
- 相知
-
- 主要技术
- 相关讨论
- 实验
- 回顾
- 代码分析
-
- 预制模块
- Transformer-Block
- ViT
原文地址
Arxiv原文
论文阅读方法
三遍论文法
初识
文章完整题目《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
Transformer本身在NLP领域就已经“大红大紫”了,在CV领域,attention机制本身就已经融入了CNN结构,要么与CNN一同应用,要么代替CNN中的某一部分。ViT这篇文章主要证明了:在视觉领域CNN结构不是必须的,仅使用Transformer就可以在图像分类任务上起到很好的效果。并且当ViT在大量数据上进行预训练后达到SOTA。
其主要的核心思想就是将图像切分成Patch(16x16),经过线性映射后组成序列送入Transformer中执行分类任务。每个Patch就相当于NLP任务中的token(words),这也就是文章题目中体现的An image is worth 16x16 words.
如果对transformer本身不熟悉或者初学者的话,博主强烈建议先看以下资料进行学习:
[1] 李宏毅老师:https://www.bilibili.com/video/av56239558/
[2] 3W字长文带你轻松入门视觉transformer https://zhuanlan.zhihu.com/p/308301901
相知
Related work不再介绍,有兴趣请参看原文
主要技术
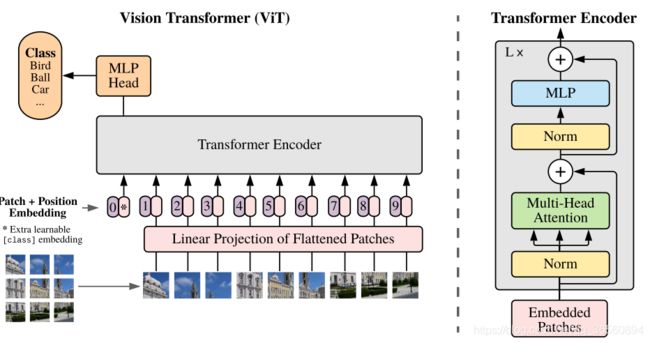
如上图所示,ViT整个网络的架构与原始的Transformer并无太大区别(甚至可以说是一模一样),主要的区别就是在输入序列中额外增加了一个classification token,即上图中的0。
首先输入图像维度为 H × W × C H\times W\times C H×W×C,将图像切分成一组Patch序列,其维度变为 N × ( P 2 C ) N\times(P^2C) N×(P2C) 。其中, ( P , P ) (P,P) (P,P)为Patch的尺寸, N = H × W / P 2 N=H\times W/P^2 N=H×W/P2为图像块的个数,每个图像块都展开变为1维。接着,使用线性映射(可学习)将其变为D维。
参照BERT,预先在序列中设定一个可学习的嵌入token( Z 0 = x c l a s s Z_0=x_{class} Z0=xclass),并且最后在Transformer编码器末尾中用该位置上的输出在作为整副图像的presentation。比如上图中,图像分为了9个patch,但最后Transformer会输入10个token,最后也是取第0个位置上的输出送到MLP头中执行分类。
关于为什么要加一个分类token,这主要是由于ViT只使用了Transformer中的编码器结构,没有解码器。因此引入一个可学习的token,类似于开启解码标志(Query)。
参考https://zhuanlan.zhihu.com/p/308301901,
接下来,引入位置编码,相较于原始Transformer,ViT比较简单,直接使用一个1维的可学习参数作为位置编码加到输入序列中。最后Transformer的结构不变,每个Block还是由MSA(多头注意力模块),MLP,以及Layernorm构成。
Transformer的细节就不过多叙述了
相关讨论
偏执归纳:CNN将"局部、2维领域结构、 平移不变性 "融入模型的每一层(主要是由于卷积、池化层的特性)。Transformer只有MLP具有局部、平移等价性 (不太明白为什么MLP具有这两个性质,求指导),而剩下的注意力层都是具有全局特性的;二维邻域结构也应用地非常少。这也体现了Transformer与CNN架构不同的特性。
关于偏执归纳可以简单地视作:模型先验
参考https://www.zhihu.com/question/264264203
混合结构:这里作者提到了LeCun之前文章中的idea,就是把经过CNN提取特征后的feature map切分patch,作为输入。以及还提到了一种特殊情况,将全图切成1x1的patch,相当于直接把原图扩展送进Transformer(作为后续试验中的hybrid)。
Fine-tuning与更高的分辨率:在执行预训练时使用MLP头,微调阶段使用DxK线性映射进行微调。作者还提到在微调阶段,使用比预训练时更高的图像分辨率往往能达到更好的分类效果。此时保持patch大小不变,增加序列长度,因此对于预训练的position embedding引入了2D插值。
实验
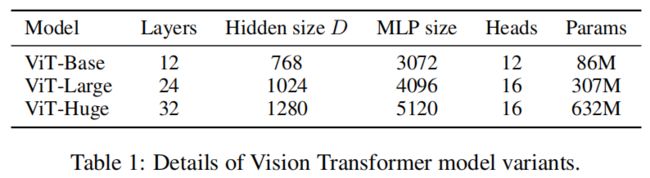
模型主要有三种不同设置(base,Large及Huge),分别对应着不同的参数设置,见下图:
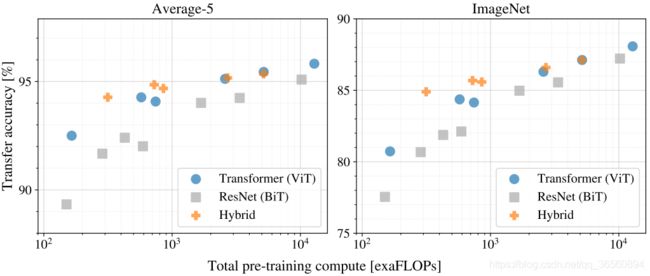
实验主要基于ImageNet,JFT这类大数据集上进行训练,然后报告了在迁移学习上的效果,见下图。在相同的数据集(G家私有的JFT-300M)进行预训练,效果超过了同类方法,并且相比之下,所需的计算消耗更少。
对比的方法BiT-L为ECCV2020的基于ResNet上的有监督迁移学习方法,Noisy Student为CVPR的半监督学习方法。
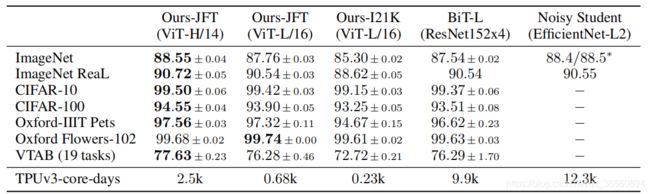
弱弱提一句,所有实验都是在TPU上进行训练的,表格最后一行也输出了计算损耗,在单核TPU上需要训练的天数… 有卡任性啊
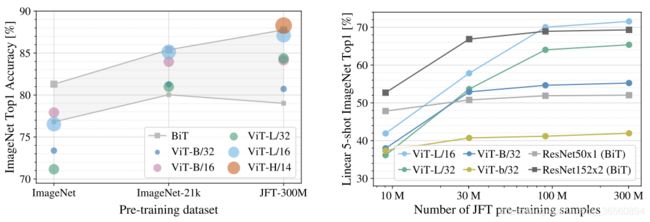
为了去验证训练好ViT到底需要多大的数据集,作者做了实验验证,如下图所示,左图展示了在不同尺寸数据集上预训练后的表现,在ImageNet这种体量的数据集下,性能没有优于CNN架构下的BiT,只有在JFT这类超大数据集下,才好于BiT。右图展示了采用JFT中不同大小的子集进行训练时,ViT与BiT的性能对比,也是需要较大的数据集预训练下效果才变好。
在相等的训练损耗下,作者也做了实验,从下图来看:a. 相同训练时间下ViT显然优于BiT,这也说明ViT在性能-计算权衡方面比ResNet架构要好;b. 其次Hybrid结果在小数据集上略优于ViT,但随着数据集的增长,这种差距也逐渐消失(Hybrid结构见前文);c. ViT看起来性能仍没有饱和,这也会促使未来工作的进展。
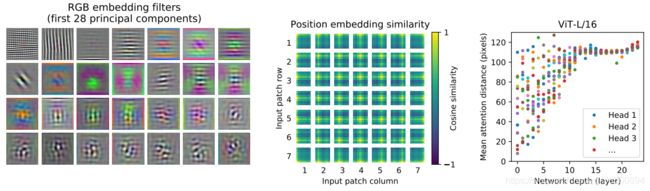
随后,作者紧接着做了一些可视化的实验,下图的最左边展示了线性映射层的前28个filter的情况,看起来像是一些基函数;中图展示了学习到的位置嵌入向量间的cosine相似度,可以看到相邻patch间的相似度很高,并呈现了行列规律性;右图展示了不同网络深度下的各head的平均注意力距离情况(类似于CNN中的感受野),可以看到在浅层有些head捕获长距离信息,有些head捕获短距离信息,但在高层就基本都捕获到的是全局信息了。
最后一张图也展示了可视化后ViT对输入图像的注意力区域。

回顾
transformer现在已经火遍了整个视觉领域,不管什么方向都能见到其身影。ViT这篇文章目前已被ICLR2021收录,并且目前引用量已经700+了,并且正在持续飙升。
单从这篇文章来看,虽然有令人欣喜的地方,Transformer给CV领域带来了新的活力,甚至有一统CV、NLP的趋势。但值得注意的是,如文章所说的那样,Transformer的训练需要足够多的样本,而且一般人和小公司也确实train不起来,而且在小数据的情况下,效果无法超过CNN架构。还有官方代码也只开源了在ImageNet上的预训练模型,没有JFT数据上的预训练模型。
这也侧面说明,直接把Transformer强行用在一般的CV任务上,效果还真不好说。但本文起到一个挖坑的效果,之后各路大佬大牛涌入了这个坑,也出现了一大批优秀的工作。
代码分析
主要参考自github,但具体链接我忘记了,就是有一个大佬复现了很多视觉领域的Transformer,大家搜搜应该就能找到。
代码主要用到了 einops 这个张量操作库,对于一些较为复杂的矩阵变换和运算提供了不小的便利,大家也可以关注关注
主要分模块谈谈代码:
预制模块
这两个模块主要是为后面Transformer的Block搭建服务的,第一个是PreNorm,首先对输入进行Layernorm归一化,然后送入fn模块中进行下一部分的运算。第二个是MLP,这个就比较简单了,主要是对输入进行fc-gelu-dropout-fc-dropout的操作。
class PreNorm(nn.Module):
''' Combine Normalization '''
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x):
return self.fn(self.norm(x))
class FeedForward(nn.Module):
''' MLP FeedForward Layer '''
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
Transformer-Block
主要为多头注意力层的构建,需要设置head的数量及对应的维度,以及最后输出的维度,需要注意,head*dim_head需要等于输入的维度。
class Attention(nn.Module):
''' Multi-heads Self-attention Layer '''
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = heads * dim_head
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5 # 归一化系数
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim, inner_dim*3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
# 输入x为(b,n,c) b是batchsize,n是patch个数,c是channel维度
b, n, _, h = *x.shape, self.heads
# 将输入映射成q,k,v三个向量
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv)
#
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
下面为完整的Transformer模块,需要设置维度,模型深度,head数量以及每个head对应的维度,以及MLP中的隐层维度等。
构造深度为depth的Transformer模型,每个transformer block包含Attention + MLP,可以参照最开始的网络架构图。
具体过程见代码注释
class Transformer(nn.Module):
''' Transformer Module '''
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth): # 构建depth个Transformer模块
# 每个模块包含的内容
self.layers.append(nn.ModuleList([
# Norm + Attention
PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),
# Norm + MLP
PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
# skip connection
x = attn(x) + x
x = ff(x) + x
return x
ViT
下面为ViT的整体网络架构,除了之前介绍到的Transformer模块,还涉及到位置嵌入、分类head的设计。首先需要传入图像尺寸,patch大小,分类的数量,中间层维度;transformer的深度,head数量以及给个head内的维度,mlp隐藏层数量,dropout概率等等。
具体过程见代码注释
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth,
heads, mlp_dim, pool='cls', channels=3, dim_head=64,
dropout=0.,emb_dropout=0.):
super().__init__()
assert image_size % patch_size == 0
num_patches = (image_size // patch_size)**2
patch_dim = channels * patch_size **2
# 两种分类形式:一个采用class token位置上的向量,另一种是对所有向量进行平均池化
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
# 对图像进行reshape,每幅图像对应hxw个图像块,并进行维度映射到dim维
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_size, p2=patch_size),
nn.Linear(patch_dim, dim)
)
# 位置嵌入向量
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches+1, dim))
# 分类token(可学习)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
# 构造transformer
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
# mlp分类head
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
# 划分patch,进行线性映射
x = self.to_patch_embedding(img)
b, n, _ = x.shape
# 构造b个分类token (b为batch size)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
# 将图像块数量与class token拼接作为输入
x = torch.cat((cls_tokens, x), dim=1)
# 嵌入位置向量
x += self.pos_embedding[:, :(n+1)]
x = self.dropout(x)
# 送入transformer
x = self.transformer(x)
# 提取特征用于分类
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x) # 返回分类结果