MCAN论文进阶——MoVie: Revisting Modulated Convolutions for Visual Counting and Beyond 论文笔记
MCAN论文进阶——MoVie: Revisting Modulated Convolutions for Visual Counting and Beyond 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 显式计数/推理模块
- 3.2 隐式推理
- 3.3 空间计数
- 3.4 通用视觉计数
- 四、带调制的计数
-
- 4.1 调制卷积
-
- 4.1.1 动机
- 4.1.2 管道和模块
- 4.1.3 瓶颈结构
- 4.1.4 调制方式
- 4.1.5 尺度鲁棒性
- 4.1.6 序列表示
- 4.2 MoVie 作为一个计数模块
- 五、实验
-
- 5.1 视觉计数
-
- 5.1.1 开放性的计数 benchmarks
-
- 5.1.1.1 调制模块的设计
- 5.1.1.2 瓶颈结构的数量
- 5.1.1.3 尺度鲁棒性
- 5.1.2 开放性计数结果
- 5.1.3 可视化分析
- 5.1.3 通用目标计数
- 5.2 视觉问答
- 5.3 超出计数范围外的任务
- 六、结论
- A 补充细节
-
- 1、问题表示
- 2、基于目标检测的计数
- B RMSE 变体的定义
- C 在 VOC 数据集上的通用目标计数
- D 对于 VQA 架构的计数模块
- E MoVie 模型究竟在哪些问题类型上其作用的可视化
写在前面
本文是 VQA 2021 Challenge 的冠军,方法上没有太复杂,主要是结合 Defense grid 的思路和 MCAN 的方法,再根据自己的 idea 做出一些创新,最终夺冠的模型采用了 32 个models 的 ensemble。
- 论文地址:MoVie: Revisting Modulated Convolutions for Visual Counting and Beyond
- 代码链接:Github
- 收录于:ICLR 2021
- 更新一:2022.4.29更新,结合源码,对模型结构部分进行更新,用黄色字体表示。
一、Abstract
本文关注于视觉计数:给定一幅图像和一个序列(一个问题或者类别),旨在预测出图像中与序列相关的目标数量。通过重新调制卷积模块来融合序列和局部的图像,本文提出了一个简单且有效的方法。由于是在残差瓶颈模块上设计的,因此称为调制卷积瓶颈网络(Modulated conVolutional bottlenecks,MoVie)。该网络在推理时仅需要单次前行传播,可以作为通用 VQA 模型中的计数模块,性能很强。此外,也可以作为通用的推理方法用于其他任务中。
二、引言
第一段指出视觉计数的定义(摘要里面的定义拓展一下),第二段表明现有的一些解决方法及其缺陷。

第三段论述本文的方法,如上图右侧所示,本文的方法简单,并不需要显式的或者符号化的推理。本文的方法建立在两个研究前沿之上:
- 在合成的CLEVR数据集上,使用序列来调制卷积能够大幅度提升卷积网络的推理性能,但是很难将其迁移到自然图像数据集上,部分原因可能是采用自下而上的区域注意力特征来表示图像;
- 但最近发现扁平化的卷积特征也可以起到类似于区域特征(defense grid 论文)的效果,而本文正是基于扁平化的特征,从而与区域特征进行对比。
根据局部多模态融合的计数方法,本文采用序列表示来重新调制卷积层。根据 ResNet(每一个瓶颈块被调制一下),本文的瓶颈块在其基础上堆叠多次。从而形成最终的模块。
本文提出的 MoVie在 VQA 2.0 和 TallyQA 数据集上以及一般的如 COCO 数据集上表现很好,并且容易插到 VQA 模型中提高计数能力。本文是其前身 “FiLM” 的改进,但是计算成本差不多。
最后,本文除了验证 MoVie 在计数上的表现外,还验证了其在 GQA 和 CLEVR 数据集上的表现,结果证明 MoVie 可以作为解决其他任务的通用型视觉推理方法。
三、相关工作
3.1 显式计数/推理模块
指出前人如何处理计数任务的,例如强化学习。本文从哲学上不同于这些方法(?),寻求的是数据驱动,通用化的视觉推理。
3.2 隐式推理
除了调制卷积外,另一种方法是关系网络,利用简单的 MLPs 学习不同位置特征的成对关系,在 CLEVR 数据集上表现很好。接下来引出 TallyQA 数据集中的方法,但该方法基于区域网络,因而既不能泛化到 VQA 模型上,也不能泛化到其它的计数/推理任务上。本文提出的 MoVie 方法融合了局部的多模态信息,不同于这些方法。
3.3 空间计数
目标计数有着特殊的计数应用,例如:细胞计数,人群计数,交通计数,野生动物计数等。这些模型往往设计于解决单个类别的场景,且通常需要点标注再加上整体的数量标签,因此泛化能力不强。
还有一类与心理相关的计数,称之为 “数感”,在上一篇博文里面也提到了,主要是人类对于较小数量的目标比较敏感。
3.4 通用视觉计数
多类别多目标计数一般采用基于检测和嵌入的方法,TallyQA 在此基础上拓展:计数目标为自然语言描述的类别,本文提出的模型正是应用在这些更通用的计数任务上,采用问题或者类别 embedding 的调制模块。
四、带调制的计数
4.1 调制卷积
4.1.1 动机
卷积网络可以在具有空间维度的特征图上操作,序列表示可以经过全卷积的方式融合特征图上所有的位置信息,这表明至少有两个原因的存在使得卷积网络更加适合视觉计数:
- 计数任务是一个平移等效的问题:对于一个固定的局部窗口,输出会随着输入的变化而变化,因此,类似于调制卷积的方式更适合这些融合,尤其是当视觉特征被池化为一个单一的全局向量时(便于和问题或类别 embedding 融合)。
- 计数任务需要在所有可能的位置上进行搜索,因此相比于那些在每一个位置上都产生输出的卷积特征而言,那些基于自下而上的稀疏的区域级别注意力的特征,可能在召回率上很低。
4.1.2 管道和模块
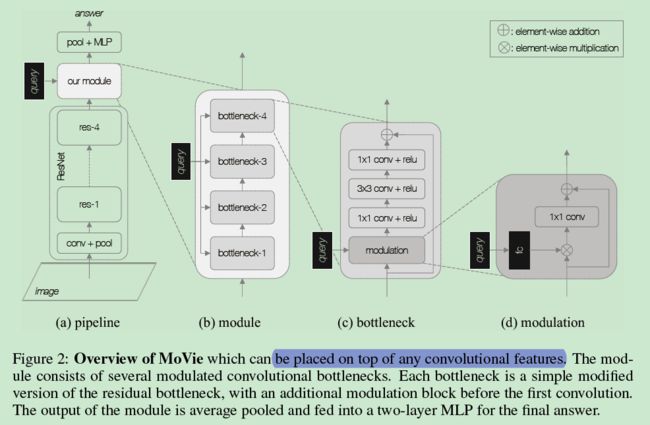
图2 是模型结构图,输出的卷积特征来源于标准卷积,之后送入到 Movie 模块(这里作者标了个尾注,意思是 MoVie 模块可以放在残差网络的任意位置,但是实验发现这并未有所帮助反而引入了额外的消耗)。MoVie 模块由 4 个调制卷积瓶颈结构组成,每一个瓶颈结构将序列作为额外的输入来建模特征图,并输出相同尺寸的特征图,最后采用平均池化进而喂给一个两层的分类器来预测答案。注意:MoVie 模块并未在序列和全局池化特征向量间进行融合,所有的序列和图像之间的迭代都发生在局部的调制瓶颈结构间。
更新一:
作者这里直接使用的是Faster 提取出来的特征输入到module中,但是每一个特征都是 32x32x2048的,这个 32 很可能是28维特征图尺寸+4(x,y,w,h)。
这里的 query 是文本嵌入矩阵经过 LSTM 和 6 层 SA输出的其中一支向量(batch,1024)。
modulation 中的图像特征首先经过一个 1x1 卷积,将特征维度变为 256,即捷径路线,再与主分支相加。
输入到 modulation 中的query 首先经过一个线性层将1024维升维至2048,与图像特征 (batch, 2048, 32, 32) 作点乘后送入 2D 卷积层输出特征维度 256。这个输出与捷径路线的图像特征相加,即得 modulation 的输出,然后经过 bottenleneck 中的 BN层和ReLu, 再依次经过1x1 卷积 + BN层 + ReLu激活得中间输出 (batch, 256, 32, 32)。最后经过 一个 1x1x1024的升维卷积,输出 (batch, 1024, 32, 32)。这个输出和 bottenleneck 中的捷径相加,即一开始的图像特征经过1个 1x1卷积后的 (batch, 1024, 32, 32), 得最终输出 (batch, 1024, 32, 32),不过,最终输出还得经过一个 ReLU 激活。
另外,查看源代码,上述输出在和 bottenleneck 中的捷径相加前还经过了一个 SE 注意力模块。关于 SE 模块,具体参考文章(Squeeze-and-Excitation Networks),可能会提升模型性能,但是不影响输出的 Size,话说论文也没讲啊,不知道几个意思。
经过 4 个堆叠的 bottleneck,即 modelue 结构化,送入一个自适应 2D 池化层,除去 w,h 维度 + 1个 LayerNorm 层,得其输出 (batch, 1024)
4.1.3 瓶颈结构
如 图2[C] 所示,在第一个卷积层之间插入一个调制模块,然后将序列信息作为另一个边的信息建模特征图。
4.1.4 调制方式
首先引入 Feature-wise Linear Modulation(FiLM) 的介绍,单个特征图上的向量为 v ∈ R C v\in\mathbb{R}^{C} v∈RC,其中 C C C 是通道尺寸,FiLM 对 v v v 上的每一个通道进行线性 transform 输出 v ˉ FiLM \bar{v}_{\text{FiLM}} vˉFiLM:
v ‾ F i L M = ( v ⊗ γ ) ⊕ β \overline{\mathbf{v}}_{\mathrm{FiLM}}=(\mathbf{v} \otimes \gamma) \oplus \beta vFiLM=(v⊗γ)⊕β
其中 ⊗ \otimes ⊗ 表示逐元素乘积, ⊕ \oplus ⊕ 表示逐元素相加(类似一般的向量加法), γ ∈ R C \gamma\in\mathbb{R}^{C} γ∈RC 意为对特征向量进行缩放, β ∈ R C \beta\in\mathbb{R}^{C} β∈RC 表示迁移。 γ \gamma γ 和 β \beta β 都是基于序列 q ∈ R C \text{q}\in\mathbb{R}^{C} q∈RC 的表示(利用一个全连接层 { W γ , W β } ∈ R D × C \left\{\mathbf{W}_{\gamma}, \mathbf{W}_{\beta}\right\} \in \mathbb{R}^{D \times C} {Wγ,Wβ}∈RD×C )。
训练 FiLM 的关系细节在于不是预测 γ \gamma γ,而是预测可微分的 Δ γ \Delta\gamma Δγ,其中 γ = 1 + Δ γ \gamma=\mathcal{1}+\Delta\gamma γ=1+Δγ, 1 \mathcal{1} 1 表示值全为 1 的向量,本质是建立起残差连接:
v ‾ F i L M = [ v ⊗ ( 1 ⊕ Δ γ ) ] ⊕ β = v ⊕ [ ( v ⊗ Δ γ ) ⊕ β ] \overline{\mathbf{v}}_{\mathrm{FiLM}}=[\mathbf{v} \otimes(1 \oplus \Delta \gamma)] \oplus \beta=\mathbf{v} \oplus[(\mathbf{v} \otimes \Delta \gamma) \oplus \beta] vFiLM=[v⊗(1⊕Δγ)]⊕β=v⊕[(v⊗Δγ)⊕β]
其中 F FiLM ≜ ( v ⊗ Δ γ ) ⊕ β \mathcal{F}_{\text {FiLM }} \triangleq(\mathbf{v} \otimes \Delta \gamma) \oplus \beta FFiLM ≜(v⊗Δγ)⊕β 为调制残差函数,输入是 v \text{v} v 和 q \text{q} q,然后再加回 v \text{v} v。以上为本文创建用于计数的 F ( v , q ) \mathcal{F}\left(\text{v},\text{q}\right) F(v,q) 奠定了基础。
MoVie 的调制模块如 图2[d] 所示,调制函数定义如下: F M o V i e ≜ W T ( v ⊗ Δ γ ) \mathcal{F}_{\mathrm{MoVie}} \triangleq \mathbf{W}^{T}(\mathbf{v} \otimes \Delta \gamma) FMoVie≜WT(v⊗Δγ),其中 W ∈ R C × C \mathbf{W} \in \mathbb{R}^{C \times C} W∈RC×C 为可学习的权重( 1 × 1 1\times1 1×1 卷积)。直觉上来说,不是直接使用 v ⊗ Δ γ \mathbf{v} \otimes \Delta \gamma v⊗Δγ 的输出,而是通过 W \mathbf{W} W 中的每一列单独对通道 C C C 上 v ⊗ Δ γ \mathbf{v} \otimes \Delta \gamma v⊗Δγ 的内积进行加权。
与 FiLM 相比,MoVie 的参数更少,这取决于通道 C C C 的相关尺寸和序列维度 D D D。
4.1.5 尺度鲁棒性
卷积网络需要担心的可能就是其对输入图像尺度的敏感性,因为卷积网络的基础并非尺度不变的。而基于区域的计数模型往往对尺度变化更加鲁棒,这是因为其特征是在固定范围内(例如 7 × 7 7\times7 7×7 )计算的而不是 bounding boxes 范围内。本文发现两个细节上的实现对解决这个问题很有帮助:
- 固定输入的尺寸:对于一幅图像,重新调整并填充到全局最大尺寸上,注意这里并不是指 batch 上的最大尺寸(不同 batch 的长宽比可能会改变);
- 利用多尺度训练:从一个统一的预定义集合中采样目标尺寸。注意:输入和输出图像的尺寸是解耦的,这个差距可以通过零填充( zero-padding )补上。
4.1.6 序列表示
问题的序列表示 q ∈ R D \text{q}\in\mathcal{R}^{D} q∈RD 有两种形式:问题或类别。
- 对于问题的序列表示,本文采用 LSTM 和 Self Attention(SA) 层来编码问题。具体来说,一个由 N N N 个单词组成的问题,首先转化为一个长度为 N N N,维度为 300-d 的 GloVe 词嵌入序列 Q 0 = { w 1 0 , … , w N 0 } \mathbf{Q}^{0}=\left\{w_{1}^{0}, \ldots, w_{N}^{0}\right\} Q0={w10,…,wN0},之后喂给一个单向的 LSTM,后面再跟着一个堆叠 L = 4 L=4 L=4 次的 SA 层,记为:
Q 1 = L S T M → ( Q 0 ) Q l = S A l ( Q l − 1 ) \begin{aligned} \mathrm{Q}^{1} &=\overrightarrow{\mathrm{LSTM}}\left(\mathrm{Q}^{0}\right) \\ \mathrm{Q}^{l} &=\mathrm{SA}_{l}\left(\mathrm{Q}^{l-1}\right) \end{aligned} Q1Ql=LSTM(Q0)=SAl(Ql−1)
其中 Q l = { w 1 l , … , w N l } , l ∈ { 2 , … , L + 1 } \mathrm{Q}^{l}=\left\{w_{1}^{l}, \ldots, w_{N}^{l}\right\},l\in\left\{2,\dots,L+1\right\} Ql={w1l,…,wNl},l∈{2,…,L+1} 是第 ( l − 1 ) \left(l-1\right) (l−1) SA 层后的 D = 512 D=512 D=512 维度下问题词的序列表示。
对于最终的输出 Q L + 1 Q^{L+1} QL+1,利用一个两层 512 维度的带 ReLU 的 MLP 给每一个词表示 w N L + 1 w_{N}^{L+1} wNL+1 计算出注意力分数 s n s_n sn,之后利用 softmax 归一化所有的得分来提取注意力权重 α n \alpha_{n} αn,最后在 Q L + 1 Q^{L+1} QL+1 上,利用权重求和得到聚合表示 q \text{q} q。 - 对于类别,采用一个 N N N 类别的嵌入矩阵 C e = { c 1 , … , c N } , c n ∈ R D C_{e}=\left\{c_{1}, \ldots, c_{N}\right\},c_{n}\in\mathbb{R}^{D} Ce={c1,…,cN},cn∈RD 来表示。第 n n n 个类别的序列表示为 q = L2-Norm ( c n ) \text{q}=\text{L2-Norm}(c_n) q=L2-Norm(cn)。
4.2 MoVie 作为一个计数模块
针对基于问题的计数,一个模型最重要的属性就是能否将其作为一个模块整合到通用的 VQA 模型中。本文通过添加两个辅助的仅用于训练的分支构成一个三分支的训练计划。这两个辅助分支,一个分支仅用 i ∈ R C ′ \text{i}\in\mathbb{R}^{C'} i∈RC′(图像表示) 来训练 ,另一个分支用 v ∈ R C v\in\mathbb{R}^{C} v∈RC(添加的池化特征) 和 MLP 来训练,还有一个专门用于训练 VQA 模型的联合分支。三个分支的损失权重相同,但是训练 i \text{i} i 和 训练 ( i+v ) (\text{i+v}) (i+v) 联合分支的参数并不共享。在测试过程中,仅仅采用联合分支,在没有牺牲推理速度的同时提高了与数量相关的问题得分。

更新一:作者这一小节要吐槽一下,写的过于简单了,直接三个训练带过去了。实际上:图 C 中间那一块从左到右依次是【MCAN算法 + 问题特征向量】/ 【池化后的 MoVie 图像、文本特征向量的组合特征】+ 【MCAN算法 + 问题特征向量】+ 【问题特征向量】/ 【池化后的 MoVie 图像、文本特征向量的组合特征】。左边的表示为 MCAN 算法,中间的是表示为 MoVie 算法与 MCAN 算法和问题特征向量的结合,右边的是 MoVie 图像、文本特征向量的组合特征。注意,不要看到 V \mathcal V V 就以为是图像特征,作者这里用 V \mathcal V V 表示 问题特征向量,那么这个向量怎么来的?这个向量是问题嵌入矩阵经过 LSTM 和 6 层的 SA 模块,再经过加权注意力池化后得到的,共有 2 个分支,其中一个给中间 MoVie 去了,另外一个自身用于训练。
这三个分支:中间分支的输出分别从 (batch,1024) 升维到 (batch,2048) 后相加再做一次 LayerNorm 作为一个输出,另外两个输出分别是左边 和右边升维到 (batch,2048) 的 tensor 的 LayerNorm。
上面三个输出用 torch.stack 堆叠形成一个 (batch, 3, 2048) 的向量送入一个三分支的线性分类器得出用于训练的 logits。这个三分支的线性分类器其实就是三个线性全连接层 (2048,3129),然后再次进行堆叠,得到 Logits (batch, 3, 3129)。
损失函数用的是三元组 BCE 损失,也就是分别计算三个 BCE 后的损失均值求和,然后乘以候选答案数量 3129 进行输出得总损失。
五、实验
Adam 优化器,batch=128,初始学习率 l r = 1 e − 4 lr=1e^{-4} lr=1e−4,动量及其衰减 0.9 , 0.98 0.9,0.98 0.9,0.98,3 个 epoch 的 warming up 学习率 l r = 2.5 e − 5 lr=2.5e^{-5} lr=2.5e−5,在第 10 个 epoch 时,乘以 0.1 0.1 0.1 衰减因子,总共训练 13 个 epoch。
5.1 视觉计数
两种设计,使用问题序列的开放性计数,使用类别序列的通用目标计数。
5.1.1 开放性的计数 benchmarks
HowMany-QA 数据集,训练集问题来自于 VQA 2.0 的训练集和 VG,验证集来源于VQA 2.0 val,每个 GT 不超过 20。TallyQA数据集,主要是 test 测试集,分成 test-simple(怕打脸的试试这个),test-complex(有挑战性的)——需要模型具备一定的推理能力才能回答其问题,GT不超过15。评估指标采用 ACC 和 RMSE。
首先在 HowMany-QA 数据集上进行消融实验:采用 ResNet-50 作为 backbone,采用预训练 VG上的权重,在 HowMany-QA 训练集上训练,在 val 数据集上评估。结果如下表所示:
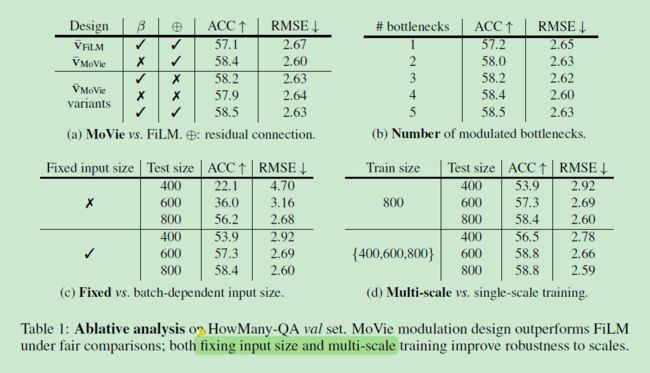
5.1.1.1 调制模块的设计
如 表1(a) 所示。
5.1.1.2 瓶颈结构的数量
如 表1(b) 所示。
5.1.1.3 尺度鲁棒性
如 表1(c,d) 所示。
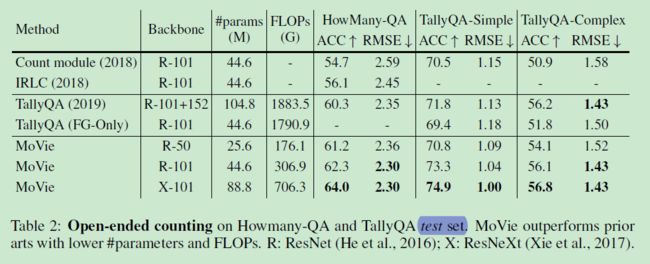
5.1.2 开放性计数结果
如表2 所示,数据集采用 HowMany-QA 和 TallyQA,MoVie 的参数更少,性能更牛皮。
5.1.3 可视化分析

两个案例失败的原因:要么未能预测出正确的答案,要么预测出了错误的注意力图。
5.1.3 通用目标计数
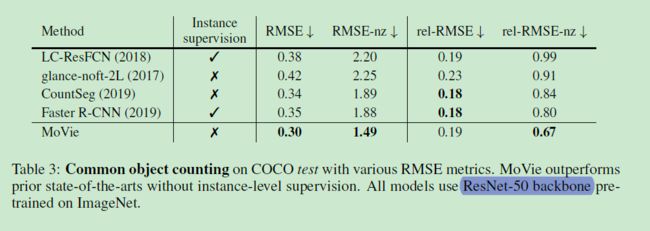
序列是一种目标类别的通用目标计数。采用 ResNet-50 预训练在 ImageNet 上,然后在数据集上微调。由于 0 和非 0 答案存在偏斜分布,因此训练过程中执行平衡化的采样。
在COCO数据集上的表现如表 3 所示:
5.2 视觉问答
接下来将 MoVie 作为一个计数模块整合到通用的 VQA 模型上(MCAN),但采用单尺度训练,学习率和 MCAN 相同,ResNet-50 Backbone。
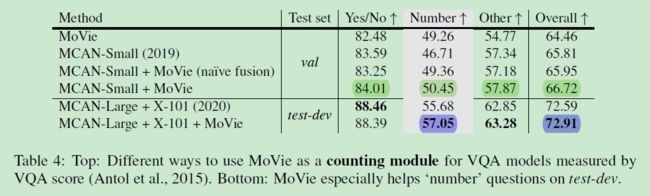
5.3 超出计数范围外的任务
在 CLEVR 数据集上进行评估,Backbone ResNet-101,训练 45 个 epoch,在测试集上有 97.42 % 97.42\% 97.42% 的精度。这表明与 FiLM 中特定形式不同,一般的调制卷积也可以帮助在 CLEVR 数据集上实现更好的性能。
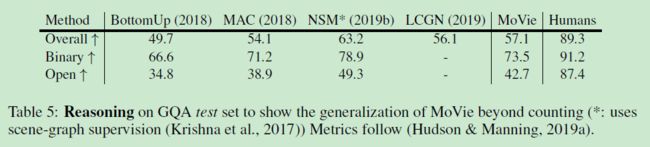
同时验证的还有 GQA 数据集,如表 5 所示,Backbone ResNeXt-101,VG 上预训练的权重。
六、结论
MoVie 通过重新调制卷积模块来融合序列和局部的图像,模型简单,性能强,在推理时只需前向传播一次。三个数据集 HowMany-QA,Tally-QA,COCO, VQA 2.0 上进行评估,同时能够拓展到 CLEVR 和 GQA 数据集上,表明调制卷积的方法可以作为通用的机制从而应用到其他超出计数的推理任务中去。
A 补充细节
1、问题表示
主要是 Self Attention 中并未包含位置嵌入。
2、基于目标检测的计数
主要是 Faster R-CNN 的实现过程。
B RMSE 变体的定义
和上一篇博文:多类别目标计数 Towards Partial Supervision for Generic Object Counting in Natural Scenes 论文笔记类似。
- 标准的绝对均方误差 RMSE:
R M S E = 1 M ∑ i = 1 M ( c ^ i − c i ) 2 \mathrm{RMSE}=\sqrt{\frac{1}{M} \sum_{i=1}^{M}\left(\hat{c}_{i}-c_{i}\right)^{2}} RMSE=M1i=1∑M(c^i−ci)2
其中 c ^ i \hat{c}_{i} c^i 为 GT, c i {c}_{i} ci 为预测, N N N 为样本数量。 - 非零绝对均方误差 RMSE-nz:
R M S E − n z = 1 M n z ∑ i ∈ { i ∣ c ^ i > 0 } ( c ^ i − c i ) 2 \mathrm{RMSE-nz}=\sqrt{\frac{1}{M_{n z}} \sum_{i \in\left\{i \mid \hat{c}_{i}>0\right\}}\left(\hat{c}_{i}-c_{i}\right)^{2}} RMSE−nz=Mnz1i∈{i∣c^i>0}∑(c^i−ci)2
其中 M n z {M_{n z}} Mnz 是 GT 不为 0 的样本数量,即答案中至少包含一个数量的难样本,旨在评估模型对于难样本的计数能力。 - 相对绝对均方误差 rel-RMSE:
rel-RMSE = 1 M ∑ i = 1 M ( c ^ i − c i ) 2 c ^ i + 1 \text { rel-RMSE }=\sqrt{\frac{1}{M} \sum_{i=1}^{M} \frac{\left(\hat{c}_{i}-c_{i}\right)^{2}}{\hat{c}_{i}+1}} rel-RMSE =M1i=1∑Mc^i+1(c^i−ci)2
旨在惩罚那些数量比较小时犯错误的模型(例:GT = 2 时,模型预测为1,相比 GT = 100 惩罚更严格)。 - 相对非零绝对均方误差 rel-RMSE-nz:
rel-RMSE-nz = 1 M ∑ i ∈ { i ∣ c ^ i > 0 } ( c ^ i − c i ) 2 c ^ i + 1 \text { rel-RMSE-nz }=\sqrt{\frac{1}{M} \sum_{i \in\left\{i \mid \hat{c}_{i}>0\right\}} \frac{\left(\hat{c}_{i}-c_{i}\right)^{2}}{\hat{c}_{i}+1}} rel-RMSE-nz =M1i∈{i∣c^i>0}∑c^i+1(c^i−ci)2
旨在计算非零样本相对的 RMSE,既具有挑战性,又符合人类的感知。
C 在 VOC 数据集上的通用目标计数
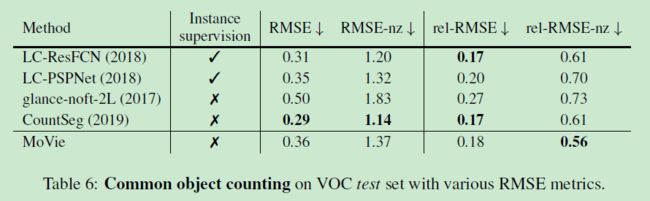
MoVie 在 COCO 数据集上的表现优于 CountSeg,但在 VOC 上比不过,因此,MoVie 更适合大尺度和多数量的数据集。
D 对于 VQA 架构的计数模块

注意:测试中的参数是比较小的,因为只需要使用联合分支进行推理(采用三分支进行训练)。同时整合 MoVie 到通用的 VQA 模型中有利于提高计数能力,这一点不同于通用化的模型提升。
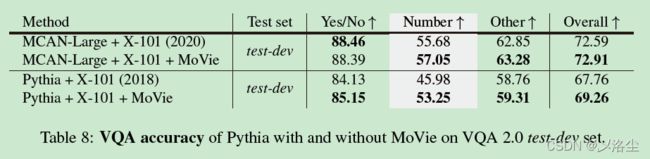
图 8 表示 MoVie 能够泛化到更一般的 Pythia 模型上,并显著提高其计数能力。
E MoVie 模型究竟在哪些问题类型上其作用的可视化


对比图 5,6,发现:
- 现有的擅长融合全局特征的模型不适合计数问题,相反表明了执行局部融合的 MoVie 模型可以作为一个计数模型而插入到通用的 VQA 模型上;
- “是/否” 类问题更容易从 MoVie 中获益,因为计数问题可能也包含验证性的问题;
- 对于 Pythia,MoVie 能帮助回答与颜色相关的问题,这就验证了 MoVie 拥有计数任务外的能力。
写在后面
哎,疫情又封校,安安心心盘论文吧,希望早点结束~