李宏毅老师机器学习第一部分:知识介绍
李宏毅老师机器学习第一部分:知识介绍
- 一、机器学习介绍
-
- 1.1 人工智慧
- 1.2 hand-crafted rules
- 1.3 我们的目标
- 1.4 机器学习的简化步骤
- 二、机器学习相关技术
-
- 2.1 监督学习
- 2.2 半监督学习
- 2.3 迁移学习
- 2.4 无监督学习
- 2.5 监督学习重的结构化学习
- 2.6 强化学习
- 2.7 补充知识
- 三、为什么要学习机器学习
-
- 3.1 AI训练师
一、机器学习介绍

1.1 人工智慧
人工智慧这个词现在非常的热门,但人工智慧是什么呢?人工智慧其实就是指的人工智能AI(Artificial Intelligence),在1950年代就有了。这个词意味着一个人类长远以来的目标,希望机器可以跟人一样的聪明。在科幻小说里面,我们看要很多这样的幻想和期待。但很长段时间里面,人们并不知道怎么做到人工智慧这件事情,直到后来,大概1980年代以后,有了机器学习的方法,机器学习顾名思义就是让机器拥有学习的能力。
人工智慧是我们想要达成的目标,而机器学习是想要达成目标的手段,希望机器通过学习方式,他跟人一样聪明。而另一个比较常见的概念——深度学习,是机器学习的其中一种方法。
生物学告诉我们说:生物的行为取决于两件事,一个是先天的本能,另一个是后天学习的结果。对于机器来说要么就是通过后天学习的手段表现的很有智慧,要么就是它的先天的本能。机器的先天的本能是来自于他的创造者,所以说一个好的机器离不开一个好的创造者。
关于生物本能的一个例子就是河狸,河狸修建水坝是一种生物本能,也就是说就算一个河狸没有父母告知他修建水坝,当他听见流水声也会有想要去搞一个水坝的冲动。科学家们就曾经在一个墙上播放水流的声音,然后河狸就去墙上开始修建水坝目的是把扬声器的声音盖住。
1.2 hand-crafted rules
hand-crafted rules实现的人工智能,其本质就是通过许多if判断语句去实现,然而并不能完成比较复杂的任务,由于需要编写大量的if 语句,工作量非常大不说还会经常出现一些可笑的错误。
使用hand-crafted rules有什么样的坏处呢,它的坏处就是:使用hand-crafted rules你没办法考虑到所有的可能性,它非常的僵化,而用hand-crafted rules创造出来的machine,它永远没有办法超过它的创造者人类。人类想不到东西,就没办法写规则,没有写规则,机器就不知道要怎么办。
比如有一天你想要做一个chat-bot,如果你不是用机器学习的方式,而是给他天生的本能的话,那像是什么样子呢?你可能就会在这个chat-bot里面,在这个聊天机器人里面的设定一些规则,这些规则我们通常称hand-crafted rules,叫做人设定的规则。那假设你今天要设计一个机器人,他可以帮你打开或关掉音乐,那你的做法可能是这样:设立一条规则,就是写程序。如果输入的句子里面看到“turn off”这个词汇,那chat-bot要做的事情就是把音乐关掉。这个时候,你之后对chat-bot说,Please turn off the music 或can you turn off the music, Smart? 它就会帮你把音乐关掉。看起来好像很聪明。别人就会觉得果然这就是人工智慧。但是如果你今天想要欺负chat-bot的话,你就可以说please don‘t turn off the music,但是他还是会把音乐关掉。这是个真实的例子,你可以看看你身边有没有这种类似的chat-bot,然后你去真的对他说这种故意欺负它的话,它其实是会答错的。这是真实的例子,但是不告诉他是哪家公司产品,这家公司也是号称他们做很多AI的东西的。
1.3 我们的目标
我们要做的其实是让机器他有自己学习的能力,也就我们要做的应该machine learning的方向。讲的比较拟人化一点,所谓machine learning的方向,就是你就写段程序,然后让机器人变得了很聪明,他就能够有学习的能力。接下来,你就像教一个婴儿、教一个小孩一样的教他,你并不是写程序让他做到这件事,你是写程序让它具有学习的能力。然后接下来,你就可以用像教小孩的方式告诉它。假设你要叫他学会做语音辨识,你就告诉它这段声音是“Hi”,这段声音就是“How are you”,这段声音是“Good bye”。希望接下来它就学会了,你给它一个新的声音,它就可以帮你产生语音辨识的结果。

或者希望他学会怎么做影像辨识,你可能不太需要改太多的程序。因为他本身就有这种学习的能力,你只是需要交换下告诉它:看到这张图片,你要说这是猴子;看到这张图片,然后说是猫;看到这张图片,可以说是狗。它具有影像辨识的能力,接下来看到它之前没有看过的猫,希望它可以认识。

machine learning所做的事情,关键就是在寻找一个function。要让机器根据你提供给他的资料,去寻找出我们要寻找的function。
1.4 机器学习的简化步骤
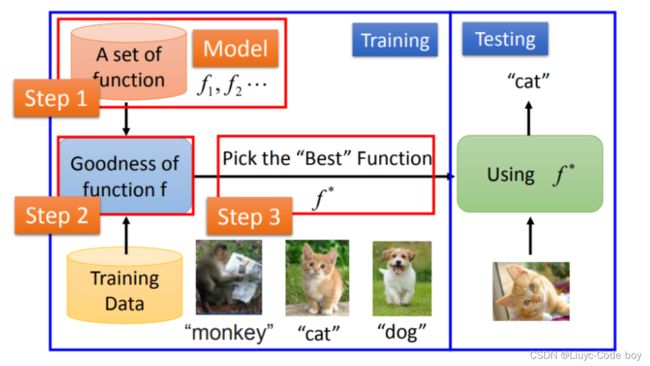
第一步:先准备一个function set(集合),这个function里面有成千上万的function。
第二步:使用一些训练的资料,这些训练资料告诉机器说一个好的function,它的输入输出应该长什么样子,有什么样关系。
第三步:从function set里面挑出一个最好的的function,这个最好的function将它记为f*。
最终我们希望机器能够实现举一反三的功能。
根据上面的分析我们把机器学习的三个简化步骤可以类比把大象关进冰箱,都是三个步骤完成。
二、机器学习相关技术
2.1 监督学习
监督学习中包括了回归问题(Regression)和分类问题(Classification),其中回归问题主要是针对于连续性的数值进行预测,比如房价预测、PM2.5含量的预测等等。分类问题主要是针对于离散型的数据进行分析,最终得出所要预测的值是什么类型,比如一封邮件是否为垃圾邮件(是/否)、一个细胞是否为癌细胞(是/否)等等。


2.2 半监督学习
监督学习的问题是我们需要大量的训练数据。通过训练数据我们得到要找的function的输入值(x)和输出之间(y)的关系。如果我们在监督学习下进行学习,我们需要给出输入和输出值。但是输出值(y)往往没有办法用很自然的方式取得,需要人工的力量把它标注出来,一般function的输出值(y)叫做label标签。
半监督学习的目的就是减少label需要的量。
假设你先想让机器鉴别猫狗的不同。你想做一个分类器让它告诉你,图片上是猫还是狗。你有少量的猫和狗的labelled data,但是同时你又有大量的Unlabeled data,但是你没有力气去告诉机器说哪些是猫哪些是狗。在半监督学习的技术中,这些没有label的data,他可能也是对学习有帮助。
2.3 迁移学习
迁移学习是另外一个减少data用量的方向。
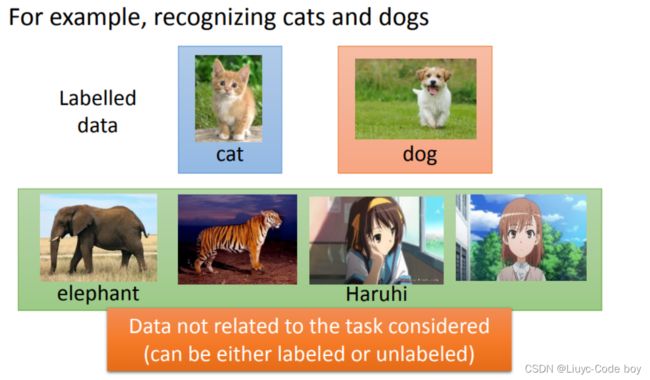
迁移学习的意思是:假设我们要做猫和狗的分类问题,我们也一样,只有少量的有label的data。但是我们现在有大量的data,这些大量的data中可能有label也可能没有label。但是他跟我们现在要考虑的问题是没有什么特别的关系的,我们要分辨的是猫和狗的不同,但是这边有一大堆其他动物的图片还是动画图片(凉宫春日,御坂美琴)你有这一大堆不相干的图片,它到底可以带来什么帮助。
2.4 无监督学习
无监督学习就是指在完全没有label标签的情况下(即只有输入没有输出的情况下),让机器去得到一些我们想要的结果。
要让机器学会每一个词汇的意思,你可以想成是我们找一个function,然后你把一个词汇丢进去。比如说你把“apple”丢进这个function里面,机器要输出告诉你说这个词会是什么意思。也许他用一个向量来表示这个词汇的各种不同的特性。但现在讲是无监督学习的问题,你现在只有一大堆的文章,也就是说你只有词汇,你只有function的输入,没有任何的输出。
2.5 监督学习重的结构化学习
structured learning 中让机器输出的是要有结构性的,举例来说:在语音辨识里面,机器输入是声音讯号,输出是一个句子。句子是要很多词汇拼凑完成。它是一个有结构性的object。或者是说在机器翻译里面你说一句话,你输入中文希望机器翻成英文,它的输出也是有结构性的。或者你今天要做的是人脸辨识,来给机器看张图片,它会知道说最左边是长门,中间是凉宫春日,右边是宝玖瑠。然后机器要把这些东西标出来。

2.6 强化学习
在reinforcement learning里面,我们没有告诉机器正确的答案是什么,机器所拥有的只有一个分数,就是他做的好还是不好。若我们现在要用强化学习方法来训练一个聊天机器人的话,他训练的方法会是这样:你就把机器发到线下,让他的和面进来的客人对话,然后想了半天以后呢,最后仍旧勃然大怒把电话挂掉了。那机器就学到一件事情就是刚才做错了。但是他不知道哪边错了,它就要回去自己想道理,是一开始就不应该打招呼吗?还是中间不应该在骂脏话了之类。它不知道,也没有人告诉它哪里做的不好,它要回去反省检讨哪一步做的不好。机器要在强化学习的情况下学习,机器是非常智能的。 强化学习也是比较符合我们人类真正的学习的情景,这是你在学校里面的学习老师会告诉你答案,但在真实社会中没人回告诉你正确答案。你只知道你做得好还是做得不好,如果机器可以做到强化学习,那确实是比较智能。
2.7 补充知识
其实多数人可能都听过regression,也听过classification,你可能不见得听过structure learning。很多教科书都直接说,machine learning是两大类的问题,regression,和classification。machine learning只有regression和classification两类问题,就好像告诉你:我们所熟知的世界只有五大洲,但是这只是真实世界的一小部分,真正的世界是如图所示。
真正世界还应该包括structure learning,这里面还有很多问题是没有探究的。
三、为什么要学习机器学习
3.1 AI训练师
就像神奇宝贝需要有训练师才能发挥更强的实力(没有弱的神奇宝贝,只有弱的训练师),同样地AI训练师需要为机器挑选合适的model和loss function。不同的model和loss function适合解决不同的问题。
因此,要训练出厉害的人工智能AI,AI训练师非常重要!