如何使用 AWS 和 ChatGPT 创建最智能的多语言虚拟助手
上周ChatGPT发布了,每个人都在尝试令人惊奇的事情。我也开始使用它并想尝试它如何使用AWS的AI 服务进行集成,结果非常棒!
在这篇文章中,我将逐步解释我是如何创建这个项目的,这样你也可以做到!
最重要的是,您无需成为AI 专家即可创建它!
我假设您已经知道 ChatGPT 是什么,并且有一个可以使用 AWS 的帐户。如果您不知道什么是 ChatGPT,请在此处查看什么是 ChatGPT 以及如何亲自尝试。
可以在此处找到该项目的完整代码。
robertgv / chatgpt-aws
聊天GPT + AWS
上周ChatGPT发布了,每个人都在尝试令人惊奇的事情。我也开始使用它并想尝试它如何使用AWS的AI 服务进行集成,结果非常棒!
在这篇文章中,我将逐步解释我是如何创建这个项目的,这样你也可以这样做:
How to create the smartest multilingual Virtual Assistant using AWS and ChatGPT - DEV Community
最重要的是,您无需成为AI 专家即可创建它!
项目步骤
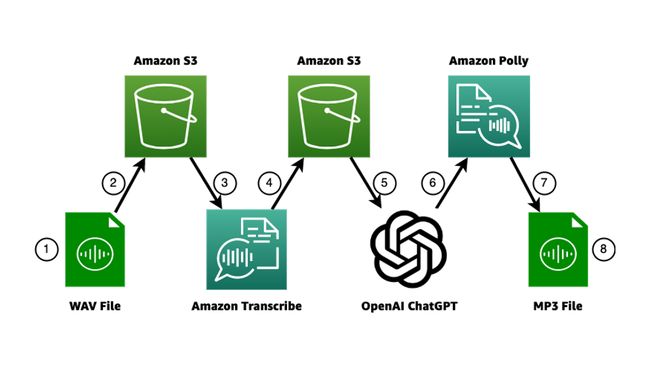
我将这个项目分为 8 个步骤:
- 录制音频并将其保存为 WAV 格式
- 将音频文件上传到 Amazon S3
- 使用 Amazon Transcribe 转录和检测保存在 S3 中的音频的语言
- Amazon Transcribe 将转录本保存在 Amazon S3 中
- 将转录内容发送到 ChatGPT
- 从 ChatGPT 接收文本答案并删除代码块
- 使用在……中检测到的语言将文本转换为音频
项目步骤
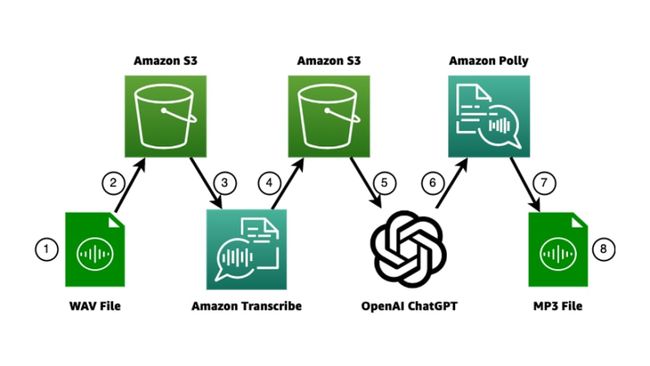
我把这个项目分为8个步骤:
- 录制音频并将其保存为 WAV 格式
- 将音频文件上传到 Amazon S3
- 使用 Amazon Transcribe 转录和检测保存在 S3 中的音频的语言
- Amazon Transcribe 将转录本保存在 Amazon S3 中
- 将转录内容发送到 ChatGPT
- 从 ChatGPT 接收文本答案并删除代码块
- 使用 Amazon Polly 使用在步骤 3 中检测到的语言将文本转换为音频并下载 MP3 格式的音频
- 再现音频文件
在我们开始之前,我们需要定义您需要创建并稍后在以下代码中替换的一般参数。此凭据的创建将在后续步骤中进行说明。
# ChatGPT params
chatGPT_session_token = ""
# AWS params
aws_access_key_id = ""
aws_secret_access_key = ""
aws_default_region = ""
aws_default_s3_bucket = ""
# Voice recording params
samplerate = 48000
duration = 4 #seconds
1.录制音频并保存为WAV格式
首先,我们需要录制音频,我们将在其中提出我们希望 ChatGPT 回答的问题。为此,我们将使用包sounddevice。确保您在操作系统的默认配置中选择了正确的麦克风。
在这种情况下,录制语音的时间为 4 秒。如果你想增加或减少这个时间,只需修改参数duration的值。
该脚本会将音频保存在当前工作目录中名为audio的文件夹中。如果这个文件夹不存在,它将使用os模块创建它。
def record_audio(duration, filename):
print("[INFO] Start of the recording")
mydata = sd.rec(int(samplerate * duration), samplerate=samplerate,channels=1, blocking=True)
print("[INFO] End of the recording")
sd.wait()
sf.write(filename, mydata, samplerate)
print(f"[INFO] Recording saved on: {filename}")
#Check if folder "audios" exists in current directory, if not then create it
if not os.path.exists("audio"):
os.makedirs("audio")
# Create a unique file name using UUID
filename = f'audio/{uuid.uuid4()}.wav'
record_audio(duration, filename)
2. 将音频文件上传到 Amazon S3
在这一步中,首先我们需要创建一个Amazon S3 Bucket。为此,我们转到 AWS 控制台并搜索服务 Amazon S3。然后单击创建存储桶。
我们需要输入存储桶的名称(存储桶名称在所有 AWS 区域的所有 AWS 账户中必须是唯一的)并选择 AWS 区域。
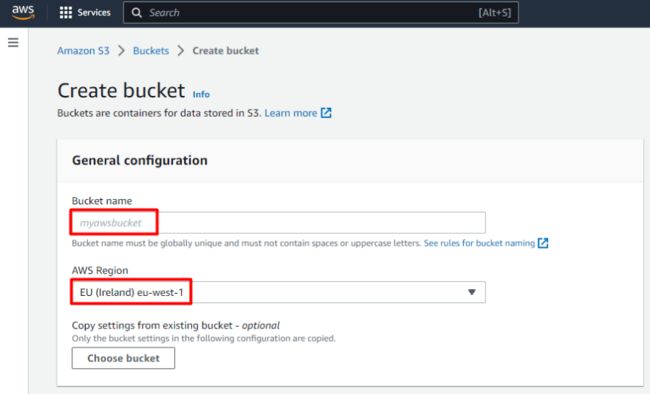
其余参数我们可以将它们保留为默认值。最后,单击页面底部的创建存储桶。
在开始的参数部分中,我们需要用存储桶名称和所选区域替换此值:
aws_default_region = ""
aws_default_s3_bucket = ""
下一步是创建一个新用户,我们将使用该用户使用boto3访问此 S3 存储桶。Boto3是用于 Python 的 Amazon Web Services (AWS) 软件开发工具包 (SDK),它允许 Python 开发人员编写使用 Amazon S3 和 Amazon EC2 等服务的软件。
要创建新用户,我们在 AWS 控制台上搜索IAM 。然后单击访问管理下左侧菜单中的用户:
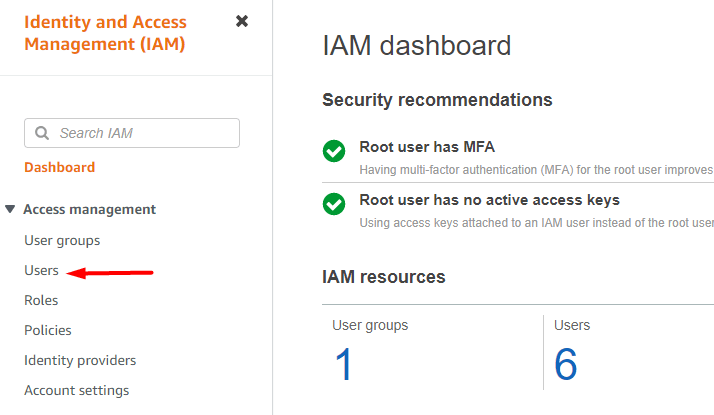
单击右上角的添加用户。我们需要提供一个用户名,然后点击Access key - Programmatic access复选框。
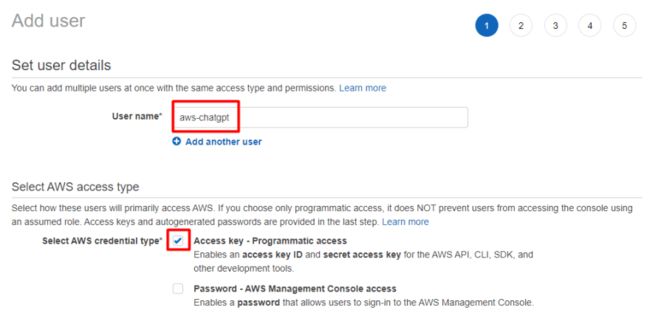
然后单击“下一步:权限”。在这里点击Attach existing policies directly然后点击Create policy。
在这里我想提一下,我们可以只选择名为AmazonS3FullAccess的策略,它会起作用,但这违背了最小特权权限的原则。在这种情况下,我们将只提供对我们之前创建的存储桶的访问。
在创建策略页面上单击选择服务并搜索S3并单击它。然后在操作上单击选项:
- 列表桶
- 获取对象
- 删除对象
- Put对象
在Resources上单击Specific,然后在 bucket 上单击Add ARN,输入我们之前创建的 bucket 名称并单击Add。在对象上还单击添加 ARN并放置之前创建的存储桶名称,在对象名称上单击复选框Any。
然后点击Next: Tags和Next: Review。最后,为新策略命名并单击Create policy。
创建策略后,返回创建用户页面并搜索创建的新策略。如果它没有出现,请单击刷新按钮。
然后点击Next: Tags和Next: Review。最后,检查一切正常,然后点击Create user。
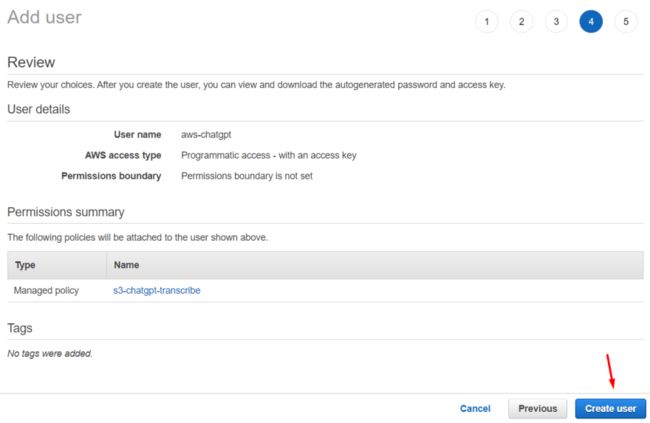
在下一页中,我们将获得Access key ID和Secret access key。确保保存它们(特别是秘密访问密钥)并且不要共享它们。在一开始的参数部分,我们需要替换这些值:
aws_access_key_id = ""
aws_secret_access_key = ""
这样我们就有了一个有权写入之前创建的 S3 存储桶的用户。
# Connect to Amazon S3 using Boto3
def get_s3_client():
return(boto3.client('s3', region_name=aws_default_region, aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key))
def upload_file_to_s3(filename):
s3_client = get_s3_client()
try:
with open(filename, "rb") as f:
s3_client.upload_fileobj(f, aws_default_s3_bucket, filename)
print(f"[INFO] File has been uploaded successfully in the S3 bucket: '{aws_default_s3_bucket}'")
except:
raise ValueError(f"[ERROR] Error while uploading the file in the S3 bucket: '{aws_default_s3_bucket}'")
upload_file_to_s3(filename)
3-4。使用 Amazon Transcribe 转录和检测保存在 S3 中的音频的语言
Amazon Transcribe是一项 AWS 人工智能 (AI) 服务,可让您轻松地将语音转换为文本。使用自动语音识别 (ASR) 技术,您可以将 Amazon Transcribe 用于各种业务应用程序,包括基于语音的客户服务电话的转录、音频/视频内容的字幕生成以及对内容进行(基于文本的)内容分析音频/视频内容。
为了能够将Amazon Transcribe与在上一步中创建的IAM 用户一起使用,我们需要通过IAM Policy提供对它的访问权限。
为此,我们需要转到AWS 控制台中的IAM,单击左侧菜单中的用户,然后单击之前创建的用户。单击添加权限,然后直接附加现有策略。搜索AmazonTranscribe并单击AmazonTranscribeFullAccess的复选框。
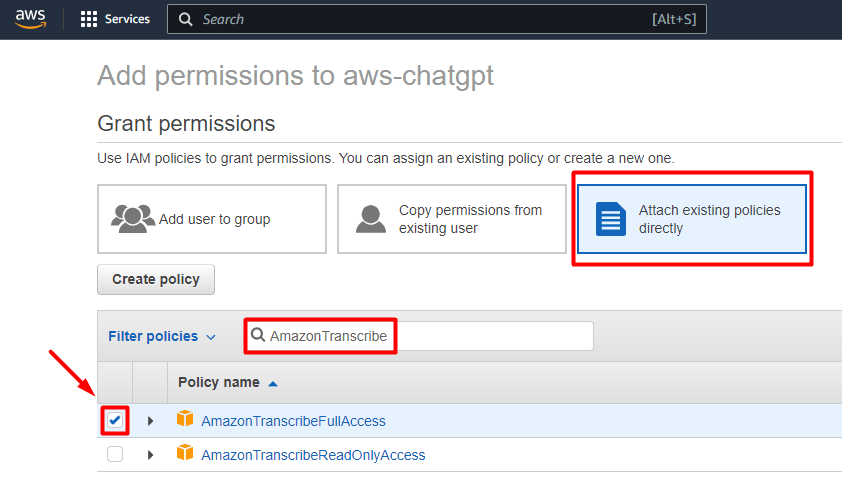
点击Next: Review and Add permissions。
此时此用户应该有 2 个附加策略:
添加此额外权限后,您无需修改/更新access key id或secret access key。
在以下 python 代码中,我们通过boto3包使用Amazon Transcribe将音频中录制的语音转录为文本。Amazon Transcribe 还会检测音频中使用的语言。
在这里,您可以阅读boto3 文档中有关TranscribeService的所有文档。
转录保存在 Amazon S3 中的 JSON 文件中。您可以选择将转录本保存在您自己的 Amazon S3 存储桶中,或者让 Amazon Transcribe 使用安全的默认存储桶。在我的例子中,我选择了拥有的 Amazon S3 存储桶上的默认选项。如果我们选择默认选项,则在作业到期(90 天)时删除成绩单。如果我们想在这个过期日期之后保留抄本,我们必须下载它。
# Generate UUID for the job id
job_id = str(uuid.uuid4())
# Connect to Amazon Transcribe using Boto3
def get_transcribe_client():
return(boto3.client('transcribe', region_name=aws_default_region, aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key))
def get_text_from_audi(filename):
transcribe = get_transcribe_client()
print("[INFO] Starting transcription of the audio to text")
transcribe.start_transcription_job(TranscriptionJobName=job_id, Media={'MediaFileUri': f"https://{aws_default_s3_bucket}.s3.{aws_default_region}.amazonaws.com/{filename}"}, MediaFormat='wav', IdentifyLanguage=True)
print("[INFO] Transcribing text: *",end="")
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_id)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("*",end='')
time.sleep(2)
print("") #End of line after loading bar
if status['TranscriptionJob']['TranscriptionJobStatus'] == 'COMPLETED':
response = urllib.request.urlopen(status['TranscriptionJob']['Transcript']['TranscriptFileUri'])
data = json.loads(response.read())
language_detected = data['results']['language_identification'][0]['code']
transcript = data['results']['transcripts'][0]['transcript']
print(f"[INFO] Transcription completed!")
print(f"[INFO] Transcript language: {language_detected}")
print(f"[INFO] Transcript text: {transcript}")
return(transcript, language_detected)
else:
raise ValueError("[ERROR] The process to convert audio to text using Amazon Transcribe has failed.")
transcript, language_detected = get_text_from_audi(filename)
5. 将转录发送到 ChatGPT
从 Amazon Transcribe 收到成绩单后,我们需要将其发送到 ChatGPT。为此,我使用了revChatGPT包。要使用这个包,我们需要对 ChatGPT 进行身份验证,这可以使用用户名和密码或使用session_token来完成。就我而言,因为我使用的是 Google OAuth 身份验证方法,所以我将使用session_token。
要获取会话令牌,我们需要登录到ChatGPT,然后单击F12或右键单击并检查。然后搜索Application选项卡并在左侧菜单中搜索Cookies。选择网站https://chat.openai.com然后搜索名称为__Secure-next-auth.session-token 的cookie并复制此 cookie 的值。
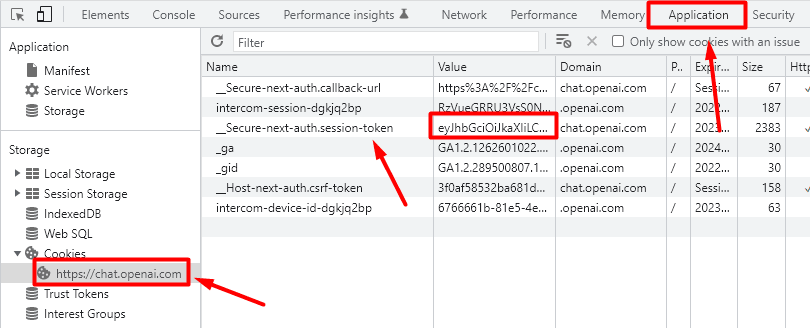
在一开始的参数部分,我们需要用您拥有的会话令牌值替换此值:
chatGPT_session_token = ""
如果您想使用电子邮件和密码作为身份验证方法,您可以在此处查看操作步骤。
完成后,我们应该能够使用 Python 连接到 ChatGPT。
def get_gpt_answer(prompt):
print(f"[INFO] Sending transcript to ChatGPT")
config = {"email": "" ,"session_token": chatGPT_session_token}
chatbot = Chatbot(config, conversation_id=None)
chatbot.refresh_session()
response = chatbot.get_chat_response(prompt, output="text")["message"]
print(f"[INFO] ChatGPT answer: {response}")
return(response)
chatgpt_answer = get_gpt_answer(transcript)
6. 从 ChatGPT 接收文本答案并删除代码块
一旦我们从ChatGPT得到答案,我们就可以得到一个或多个代码块。在这种情况下,我正在应用正则表达式函数来删除代码块。
您还可以在此处添加自己的规则,以了解如何过滤或清除来自 ChatGPT 的答案。
def clean_audio_text(text):
# Clean the code chuncks from the audio using regex
result = re.sub(r"```
[^\S\r\n]*[a-z]*\n.*?\n
```", '', text, 0, re.DOTALL)
return(result)
7. 使用 Amazon Polly 使用在步骤 3 中检测到的语言将文本转换为音频并下载 MP3 格式的音频
Amazon Polly使用深度学习技术合成听起来自然的人类语音,因此我们可以将文本转换为语音。
从 ChatGPT 清除答案后,我们准备将其发送到Amazon Polly。
为了能够将Amazon Polly与创建的用户一起使用,我们需要像在上一步中对Amazon Transcribe所做的那样,使用策略提供对它的访问权限。
为此,我们需要转到AWS 控制台中的IAM,单击左侧菜单中的用户,然后单击之前创建的用户。然后单击添加权限,然后直接附加现有策略。搜索AmazonPolly并单击AmazonPollyFullAccess的复选框。
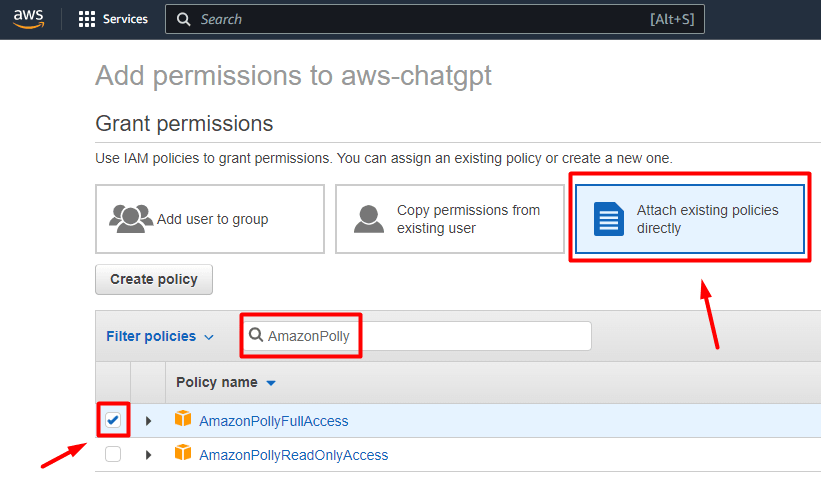
点击Next: Review and Add permissions。
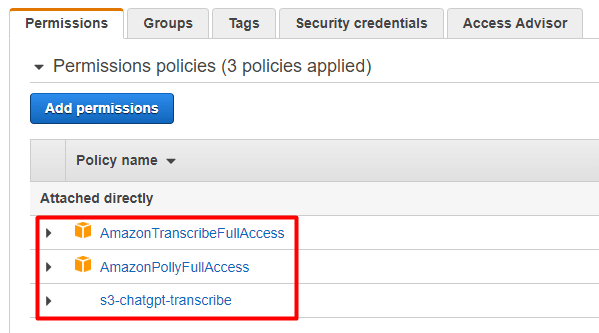
此时此用户应该有 3 个附加策略:
Amazon Polly支持多种语言和不同性别。在这种情况下,我提供的代码预定义了 3 种语言:英语、西班牙语和加泰罗尼亚语。另请注意,对于每种语言,您可以根据国家/地区的不同而有不同的变化。例如,对于英语,我们有en-US、en-GB、en-IN等。
此处提供了所有可用语言和变体的完整列表。
将文本发送到 Amazon Polly 后,我们将收到包含合成语音的流。
def get_polly_client():
return boto3.client('polly', region_name=aws_default_region, endpoint_url=f"https://polly.{aws_default_region}.amazonaws.com", aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key)
def generate_audio(polly, text, output_file, voice, format='mp3'):
text = clean_audio_text(text)
resp = polly.synthesize_speech(Engine='neural', OutputFormat=format, Text=text, VoiceId=voice)
soundfile = open(output_file, 'wb')
soundBytes = resp['AudioStream'].read()
soundfile.write(soundBytes)
soundfile.close()
print(f"[INFO] Response audio saved in: {output_file}")
def get_speaker(language_detected):
# Get speaker based on the language detected by Amazon Transcribe (more info about available voices: https://docs.aws.amazon.com/polly/latest/dg/voicelist.html)
voice = ""
if language_detected == "en-US":
voice = "Joanna"
elif language_detected == "en-GB":
voice = "Amy"
elif language_detected == "en-IN":
voice = "Kajal"
elif language_detected == "ca-ES":
voice = "Arlet"
elif language_detected == "es-ES":
voice = "Lucia"
elif language_detected == "es-MX":
voice = "Mia"
elif language_detected == "es-US":
voice = "Lupe"
else:
voice = "Joanna"
print(f"[WARNING] The language detected {language_detected} is not supported on this code. In this case the default voice is Joanna (en-US).")
print(f"[INFO] Speaker selected: {voice}")
return(voice)
polly = get_polly_client()
voice = get_speaker(language_detected)
output_file = f"audio/{job_id}.mp3"
generate_audio(polly, chatgpt_answer, output_file,voice=voice)
8.再现音频文件
最后,我们只需要播放来自Amazon Polly 的音频结果。
根据操作系统或您运行的位置,它可能无法工作。在我的例子中,当我在 macOS 中从终端运行函数speak_script(output_file)时,它工作正常。如果您使用的是像 Jupyter Notebook 这样的笔记本,那么请使用函数speak_notebook(output_file)。
def speak_notebook(output_file):
print(f"[INFO] Start reproducing response audio")
display(Audio(output_file, autoplay=True))
def speak_script(output_file):
print(f"[INFO] Start reproducing response audio")
return_code = subprocess.call(["afplay", output_file])
speak_script(output_file)
示例输出
如果我们按照前面的所有步骤进行操作,我们应该准备好开始使用我们新的多语言虚拟助手了。为了向您展示输出的样子,我记录了自己问“什么是 Amazon Web Services?” 您可以清楚地看到,这正是 Amazon Transcribe 生成的文字记录,然后是 ChatGPT 提供的答案。
$ python3 ChatGPT-AWS.py
[INFO] Start of the recording
[INFO] End of the recording
[INFO] Recording saved on: audio/6032133a-ec26-4fa0-8d0b-ad705293be09.wav
[INFO] File has been uploaded successfully in the S3 bucket: 'chatgpt-transcribe'
[INFO] Starting transcription of the audio to text
[INFO] Transcribing text: *********
[INFO] Transcription completed!
[INFO] Transcript language: en-US
[INFO] Transcript text: What is Amazon Web Services?
[INFO] Sending transcript to ChatGPT
[INFO] ChatGPT answer: Amazon Web Services (AWS) is a cloud computing platform that provides a wide range of services, including computing, storage, and content delivery. AWS offers these services on a pay-as-you-go basis, allowing businesses and individuals to access the resources they need without having to invest in expensive infrastructure. AWS is widely used by organizations of all sizes, from small startups to large enterprises.
[INFO] Speaker selected: Joanna
[INFO] Response audio saved in: audio/168a94de-1ba2-4f65-8a4c-d3c9c832246d.mp3
[INFO] Start reproducing response audio
我希望您像我在构建和使用这些服务时一样喜欢它。我认为这些最先进的技术有很多机会/潜力,当我们将所有这些技术结合使用时,结果会很棒!