实例分割模型 YOLACT 和 YOLACT++
Paper:CVPR 2019 YOLACT: Real-time Instance Segmentation,CVPR 2020 YOLACT++: Better Real-time Instance Segmentation
目录
1. YOLACT
1.1 相关工作/模型比较
1.1.1 Mask-R-CNN
1.1.2 FCIS
1.2 YOLACT
1.2.1 模型整体解析
1.2.2 backbone 和 neck
1.2.3 Protonet 定义与结构
1.2.4 Prediction head + Mask 定义与结构
1.2.5. Mask Assembly
1.2.6 Fast NMS
1.2.7 Loss
1.2.8 实验
2. 核心优势/特色 以及 缺陷
2. YOLACT++
2.1 改进1 Predition head
2.2 改进2 在Backbone中有间隔的引入DCN(Deformable Conv,可变形卷积)
2.3 改进3 引入新的小分支,优化mask的预测质量
2.4 YOLACT++的小总结
1. YOLACT
先要明确的知道,YOLACT是一个一阶段(one stage)、全卷积(FCN)、实例分割(instance segmentation)、!!anchor base!!模型。核心关注点在实时性上,该模型在单个Titan Xp上以33 fps在MS COCO上实现了29.8 mAP。
论文目的在于实现一个实时实例分割的任务,建立一个快速的单级实例分割模型。
1.1 相关工作/模型比较
1.1.1 Mask-R-CNN
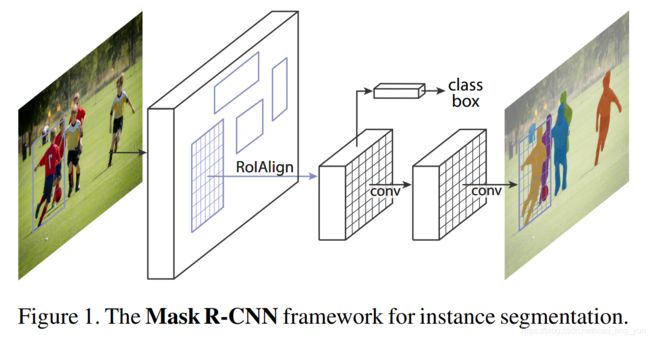
two-stage 实例分割模型的集大成者,在检测框的基础上进行像素级的语义分割,简化了实例分割的难度,是 '先检测再分割’ 这一范式上的极致代表。我们知道在Faster-R-CNN中有两个主要的输出,对于每一个ROI(也称candidate object)输出分类结果以及预测anchor的坐标偏置(offset),为了完成实例分割任务,Mask-R-CNN在此基础之上添加了第三个输出:object mask,也就说对每个ROI都输出一个mask,就像下图1所示,两个conv完成了预测anchor的mask预测。
1.1.2 FCIS
FCN 最终输出的是类别的概率图,只有类别输出,没有单个实例输出,InstanceFCN输出3*3的位置信息图, 只有单个实例输出,没有类别信息,需要单独的downstream网络完成类别信息。FCIS通过计算position-sensitive inside/outside score maps,同时输出 instance mask 和类别信息。
尽管从概念上讲比两阶段方法要快,但它们仍然需要repooling或其他特殊的计算(例如,mask voting)。这严重限制了它们的速度。
1.1.3 上述模型的一些总结
目前最好的two-stage实例分割方法,在预测mask的时候非常依赖于特征定位准确与否,也就是在一些b-box / Rois 区域要对特征进行“repooling”(RoI pooling/align),之后将新的定位特征送入mask预测分支中,这个过程是内在有序的(顺序执行),故很难加速。
1.2 YOLACT
1.2.1 模型整体解析
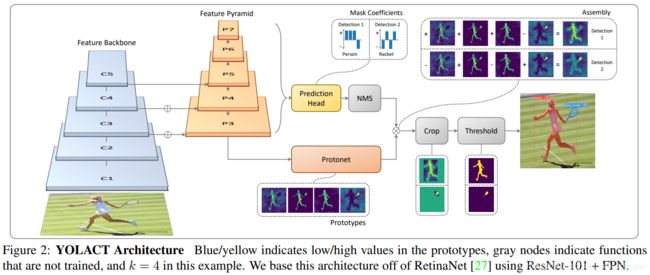
YOLACT的目的是将mask分支添加到现在的one stage目标检测模型中,为此,本文将实例分割这一复杂任务分解为两个更简单的并行任务,任务结果可以组合并形成最终的mask。
第一个任务分支(Protonet),该分支使用全卷积网络(FCN)来生成一组与原图像尺寸一样(存疑,在1.2.3的结构图中不是一样的)的 “原型掩码”(prototype masks),该掩码不依赖于任何一个特定的实例,是共用的。
第二个任务分支(mask coefficients),该分支向目标检测分支(预测 anchor )添加额外的 head 为每一个 实例 / anchor 预测一系列 “掩模系数”(mask coefficients)。
然后对经过NMS后的预测anchor(也可以说是实例,因为预测了掩模系数,相当于预测了类别),我们通过线性组合(Assembly)两个分支的结果来计算该 anchor或实例 的 mask 。
再说一遍:YOLACT将实例分割问题分解为两个并行的部分,分别产生 “prototype masks” 和 “mask coefficients”。
1.2.2 backbone 和 neck
还是由上图可知,backbone还是熟悉的味道 ResNet残差结构 + FPN结构,论文中使用了 ResNet101,在后期公开的源代码中作者还实现了 ResNet50 和 DarkNet53。
neck部分可以看到,组合C3, C4, C5层的feature map构成FPN(特征金字塔网络P3, P4, P5, P6, P7),使用FPN的用意很简单,深层网络的feature map拥有更高的感受野、更抽象的特征能够更好的表达图像全局信息(比如是什么),浅层网络的feature map尺寸更大,拥有更多细节信息,能够更好的检测小目标。
接下来就是两个并行的分支:Protonet 和 mask coefficients。P3作为 Protonet 的输入,P3~P7作为Prediction Head的输入。
1.2.3 Protonet 定义与结构
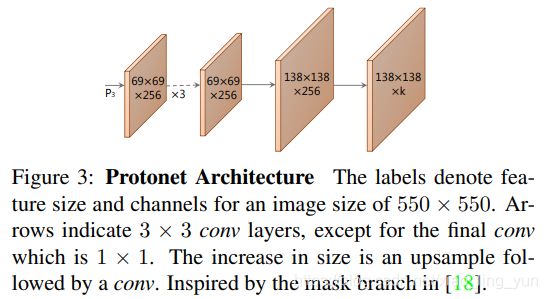
原论文图3将的就是YOLACT核心分支之一:Protonet。该分支可以看作是一个FCN网络。
Protonet 部分对于每张输入图像预测k个prototype masks。对于coco数据集,作者尝试了k取8,16,32,64,128,256,发现32效果最好。因此最终这部分输出的 mask 维度是 138*138*32,即 32 个 prototype mask,每个大小是 138*138。
注意:你会发现mask的数量 k 不依赖于类别数量,也就是类别可能比模板数量多。论文中说的是,YOLACT学习到的是一种分布式的表示,其中每个实例都由多个 prototype masks(模板原型)组合分割,这些模板在不同类别之间共享。
这种分布式使得不同的prototype mask模板域出现了一些情况:一些mask在空间上划分开了图像,一些定位实例,一些检测实例的轮廓,一些编码对位置敏感的方向图谱,可能同时也会划分图像,看看原文图5的实验。
给你们翻译一下:图5展示了六种不同的prototype mask对不同图像特征的响应,反映了不同 prototype mask 的效果。
1,4,5 可以清晰检测出目标的轮廓(尤其是图b,d,e,f,尤为明显);2 突出左下方向的特征 ; 3 区分前景和背景(图e,f比较明显);6 能够识别出背景。
接下来,我们来简单的看下Protonet 的网络结构。其是一个全卷积网络,P3是该部分的输入。
class ProtoNet(nn.Module):
def __init__(self, in_channels):
super().__init__()
# 每一个都是same卷积,尺寸不变
self.proto_net = torch.nn.Sequential(torch.nn.Conv2d(in_channels, 256, kernel_size=3, padding=1),
torch.nn.Conv2d(256, 256, kernel_size=3, padding=1),
torch.nn.Conv2d(256, 256, kernel_size=3, padding=1),
)
# 线性插值,上采样
self.inter_polate = torch.nn.functional.interpolate
self.proto_net2 = torch.nn.Sequential(torch.nn.Conv2d(256, 256, kernel_size=3, padding=1),
torch.nn.Conv2d(256, 32, kernel_size=1),
)
self.activation = torch.nn.ReLU(inplace=True)
def forward(self, x):
proto_out = self.proto_net(x)
proto_out = self.inter_polate(proto_out, scale_factor=2, mode='bilinear', align_corners=False)
proto_out = self.proto_net2(proto_out)
proto_out = self.activation(proto_out)
proto_out = proto_out.permute(0, 2, 3, 1).contiguous()
return proto_out1.2.4 Prediction head + Mask 定义与结构

如上图所示,本文predition head 改自于Retina Net,同时采取共享卷积网络的trick,从而可以提高速度,达到实时分割的目的。
该分支的输入是 P3~P7 ,共计五个特征图,Prediction Head 也有五个共享参数的预测层与之一一对应。每个特征图先生成anchor,每个像素点生成3个anchor,比例是 1:1、1:2 和 2:1。五个特征图的anchor基本边长分别是24、48、96、192和384。
看代码,输入特征图 x,先经过一个upfeature,其结果作为三个并行分支(bbox_layer,conf_layer,mask_layer)的输入,每个像素点预测 3 个anchor ,最终为每个anchor预测(4 + c + k)个值,其实4:anchor坐标偏移,c:每个anchor一共有c个类,k:k个prototype mask的系数。对应上文 prototype mask ,k = 32时,模型效果最好。
class PredictionModule(nn.Module):
def __init__(self, in_channels, out_channels=1024, aspect_ratios=[[1]], scales=[1], parent=None, index=0):
super().__init__()
self.num_classes = cfg.num_classes
self.mask_dim = cfg.mask_dim # Defined by Yolact
self.num_priors = sum(len(x) * len(scales) for x in aspect_ratios)
self.parent = [parent] # Don't include this in the state dict
self.index = index
self.num_heads = cfg.num_heads # Defined by Yolact
if parent is None:
self.upfeature = nn.Sequential(nn.Conv2d(in_channels, 256, 3, padding=1),
nn.ReLU(inplace=True))
out_channels = 256
self.bbox_layer = nn.Conv2d(out_channels, self.num_priors * 4, kernel_size=3, padding=1)
self.conf_layer = nn.Conv2d(out_channels, self.num_priors * self.num_classes, kernel_size=3, padding=1)
self.mask_layer = nn.Conv2d(out_channels, self.num_priors * self.mask_dim, kernel_size=3, padding=1)
self.aspect_ratios = aspect_ratios
self.scales = scales
self.priors = None
self.last_conv_size = None
self.last_img_size = None
def forward(self, x):
src = self if self.parent[0] is None else self.parent[0]
conv_h = x.size(2)
conv_w = x.size(3)
x = src.upfeature(x)
bbox_x = x
conf_x = x
mask_x = x
bbox = src.bbox_layer(bbox_x).permute(0, 2, 3, 1).contiguous().view(x.size(0), -1, 4)
conf = src.conf_layer(conf_x).permute(0, 2, 3, 1).contiguous().view(x.size(0), -1, self.num_classes)
mask = src.mask_layer(mask_x).permute(0, 2, 3, 1).contiguous().view(x.size(0), -1, self.mask_dim)
mask = torch.tanh(mask)
priors = self.make_priors(conv_h, conv_w, x.device)
preds = {'loc': bbox, 'conf': conf, 'mask': mask, 'priors': priors}
return preds1.2.5. Mask Assembly
依然是参照这个图:

将 mask coefficient 和 prototype mask 做一个线性组合就得到了每个实例 / anchor 的分割图像。具体做法是采用如下的矩阵乘法:![]()
其中 P:h×w×k的 prototype mask;C:n×k的mask系数矩阵;n:通过NMS和阈值过滤的 实例 / anchor,每个实例对应有 k 个mask 系数。
看公式很容易知道,每一个实例最终预测的mask,由 k 个 prototype mask(所以实例共享) 分别乘以 prototype mask 对应的mask系数(为每一个实例预测k个mask系数,并且该系数与其他实例独立),最终将k个结果线性组合而来。
!!!需要注意的是,为了能够通过线性组合多个 prototype mask 来得到最终想要的mask,能够从最终的mask中减去原型mask是很重要的。换言之就是,mask系数必须有正有负。所以,在mask系数预测时使用了tanh函数进行非线性激活,因为tanh函数的值域是(-1,1)。
(1)对prototype mask P 和 mask系数矩阵C,做矩阵乘法。
(2)组合之后得到每一个目标实例的mask,对该mask进行crop操作,即将实例框之外的位置置零。训练时采用的是ground truth的检测框,测试时使用目标检测部分得到的检测框。
(3)最后以 threshold = 0.5 作为阈值,对输出的mask做二值化操作,将mask中值的范围限制在[0,1]之间。
1.2.6 Fast NMS
在得到位置偏移后,可以通过 预设anchor 的位置加上位置偏移得到 RoI 位置。然后通过NMS 算法筛出重叠ROI。但是因为NMS计算速度较慢,本文提出了一种NMS的简化版的 Fast NMS。
Fast NMS步骤:
(1)对于每个类别的前n个得分(Roi中目标是当前类的概率)最高的结果进行降序排列,然后计算它们两两之间的IoU得到一个C×n×n(其中C是类别总数)的矩阵 N,其中的每个n×n矩阵都为对角阵。
(2)同样针对某一类,剔除掉与得分更高结果重合的检测框Roi。
具体操作:删除矩阵N对角线以及下三角元素;然后取每一列的最大值,每一列的最大值大于阈值 t 的则被筛除,剩下的便是经过nms之后的检测结果。
下面的例子来自于博客:图像分割之YOLACT & YOLACT++
对于Person类,假设有 5 个RoI,按照置信度由高到低分别是 b1、b2、b3、b4 和 b5。接下来通过矩阵运算得出它们彼此之间的 IoU,假设结果如下图:
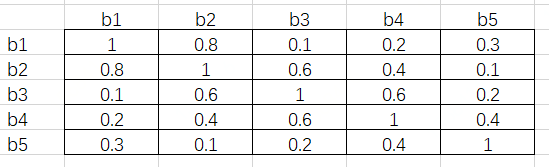
接下来将这个矩阵的下三角和对角线元素删去,得到如下图结果:
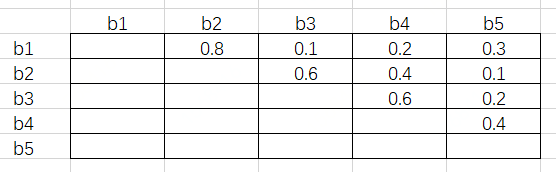
这其中的每一个元素都满足行号小于列号。接下来对每一列取最大值,得到 [-, 0.8, 0.6, 0.6, 0.4]。假设阈值为 0.5,即 IoU 超过 0.5 的两个 RoI 需要舍弃掉置信度低的那一个。根据最大值,b2、b3 和 b4 对应的列都超出了阈值,所以这三个 RoI 会在这一步舍去。
这样做的原因是,由于每一个元素都是行号小于列号,而序号又是按照置信度从高到低降序排列的,因此任一元素大于阈值,代表着这一列对应的 RoI 与一个比它置信度高的 RoI 过于重叠了,需要将它筛除。
这里需要注意的是,b3 虽然和 b2 过于重叠(IoU 为 0.6),但 b3 与 b1 的 IoU 只有 0.1,而 b2 与 b1 的 IoU 为 0.8。按照传统 NMS 算法,b2 会在第一轮循环中被舍去,这样 b3 将会被保留。
这也是 Fast NMS 与 NMS 不同的地方,即原文所述:..., we simply allow already-removed detections to suppress other detections, which is not possible in traditional NMS.
1.2.7 Loss
YOLACT在损失函数这一方面主要由三类别构成(但是还引入了其他的loss):
1. Roi分类损失,使用 Smooth L1;
2. Roi坐标偏置回归损失,使用 Smooth L1(这一块和之前所有的论文方法基本上都一致,比如yolo、faster、mask);
3. 目标mask损失,这里用的是 二分类交叉熵loss。其中mask loss在计算时,因为mask的大小是138*138(mask结果是来自于prototype mask 和 mask系数矩阵,其中prototype mask的尺度是138 * 138 * k),因此需要先将原图的mask数据通过双线性插值缩小到这一尺寸。
1.2.8 实验
一般来说这一块是不想说的,但是这个模型满足了实时的条件下实现了实例分割,还是有必要比较一下它和传统two-stage实力分割模型在性能上的差异。
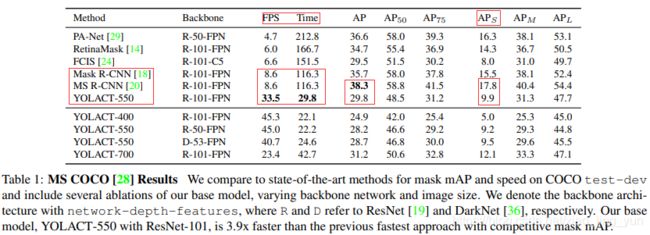
我们核心来看一下红框部分,对比two-stage实例分割模型Mask-R-CNN,MS R-CNN,YOLACT的FPS是它们的4 倍;相对的,观察AP指标,大概和最好的MS R-CNN相比有10个点的差距;我们着重观察小目标分割,大概在AP上有8个点的差距,说实话在AP这方面差距还是挺大的。现在形如自动驾驶这方面确实需要实时的语义分割or实例分割,但是这一类任务对准确率和实时性的要求都很高,所以还是比较期待作者的进一步改进。
2. 核心优势/特色 以及 缺陷
总结一下 YOLACT 三个显著的优势:
1)速度快:one-stage模、最终mask的预测是一个矩阵操作(可以利用现有的库)、FastNMS在略微牺牲性能的前提下基于矩阵操作完成Roi的筛选;
2)mask质量高,信息利用充分:不包含repooling类操作(主要体现在 protoNet)、残差网络+FPN的结构使得模型获得了充分的语义特征;
3)普适性强:这种生成原型mask和mask系数的思路可以应用在目前很多流行的检测器上。
缺陷:
在2020年这个时间点,大多数任务都需要实时性和准确率兼并,YOLACT性能低于目前最好的实例分割方法(AP上10个点不少了!),那么这里面一定有原因!作者实验发现,错误大多数都是由检测器(predition head)引起的,比如检测错误,分类错误和边界框的位移等。这一部分详细可以去看看原论文中的 discussion 部分。
下面说明两个由YOLACT的mask生成方法造成的典型错误:
(1)定位误差(Localization Failure)
当在图像某个位置存在多个重叠的目标时(或者说prototype mask上某一个点存在的目标太多),网络可能无法通过自身学习到的 prototype mask 对每一个目标进行定位。在这种情况下,会输出更接近前景mask的内容,而不是某些目标的分割。
如下图所示,红色飞机下面的两辆卡车没有被正确分开(就是蓝色 truck:0.91)。

(2)泄露(Leakage)这一块我不是很懂???????你们比较明白的,评论区给小弟我解释一下可好
泄露:噪声渗入实例掩码中,在某一个Roi中将另一个目标的部分误识别为当前目标的mask,如下图最右绿色滑雪者的anchor的左下角,你会发现预测出来的绿色 Roi 明显过大了,因为左下角包含了不属于绿色滑雪者的部分。
YOLACT 最终 mask 是在经过线性组合后crop(裁剪)得到的,该操作在 predition head 生成Roi后,所以没有抑制 Roi 外部噪声的功能。如果预测的Roi(也可以称为检测框)定位不准,那么就会导致mask泄露现象。
另外,当多个同类实例相隔较远但大小又很大的时候,也可能发生这种现象。因为网络可能认为(这个是学习到的特性)这几个实例已经离得很远了,自身不需要去分开定位它们,裁剪分支会负责处理这种情况。如下图所示,就属于这种情况。

!!论文最后,作者认为 该问题可以通过mask error down-weighting 机制得到缓解,如MS R-CNN(Mask Scoring R-CNN)中那样,其中显示这些错误的mask可以被忽略。
(3)论文实验解释 AP 差异的来源,Understanding the AP Gap
这部分不细说,作者对比mask-r-cnn经过相关实验说明了,AP的差异来自于预测anchor的准确率。
2. YOLACT++
作为YOLACT的改进,YOLACT++模型大体继承YOLACT,在保证实时性(大于或等于30fps)的前提下,对原版的 YOLACT 主要做出了三点改进,大幅度提升了mAP:
2.1 改进1 Predition head
上文章节1中最后总结了作者对YOLACT的分析中说道,YOLACT与MASK-R-CNN等实例分割模型存在10AP左右的性能差异,其主要原因在于预测出来的anchor也就是Roi不准确,因此在++中,作者使用了 更好的 anchor 尺度和长宽比 提高了大目标的Recall。
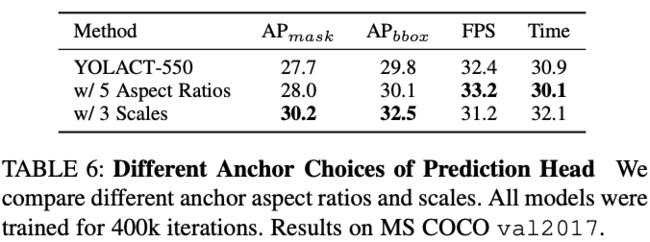
作者在这里做了两组实验(1)固定anchor的尺寸(面积),调整长宽比例,比例从 变为 ,这种方案就相当于增加了 ![]() 的anchor数目;(2)固定长宽比例,改变anchor的尺寸,,其中x是原来的尺寸(有3种),所以这种方案相当于把原来每一个anchor尺寸扩展了3倍(总体也是扩展了3倍,现在有9种尺度的anchor)。总之这两种方案都是牺牲速度,给与anchor更多的选择,个人认为有性能提升是正常的,但是这个长宽比例和anchor尺寸的调整系数我不是很理解是怎么计算来的????(经验吗?)下面放一下性能图:
的anchor数目;(2)固定长宽比例,改变anchor的尺寸,,其中x是原来的尺寸(有3种),所以这种方案相当于把原来每一个anchor尺寸扩展了3倍(总体也是扩展了3倍,现在有9种尺度的anchor)。总之这两种方案都是牺牲速度,给与anchor更多的选择,个人认为有性能提升是正常的,但是这个长宽比例和anchor尺寸的调整系数我不是很理解是怎么计算来的????(经验吗?)下面放一下性能图:
2.2 改进2 在Backbone中有间隔的引入DCN(Deformable Conv,可变形卷积)
需要注意的是:引入DCN其实是比正常的卷积耗时的(性能提升的代价),因此作者在论文中尝试了不同的替换方案(将ResNet中的conv替换成DCN),不同方案有不同的FPS和AP,这一个部分感兴趣可以去看看原文。
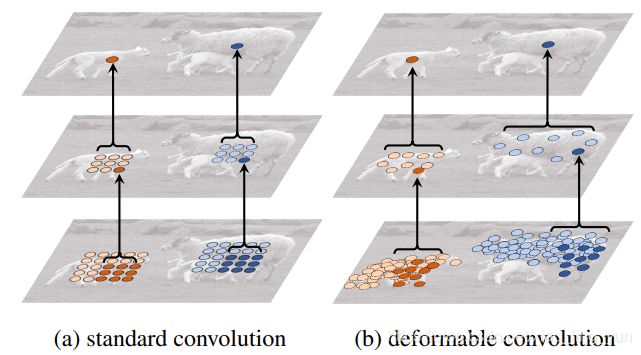
简单的解释下DCN,就是这种卷积突破了传统矩形卷积的限制,认为卷积核应该是可以变化的,卷积核应该更加关注那些核心的或者感兴趣的信息,这样得到的特征更具有代表性。
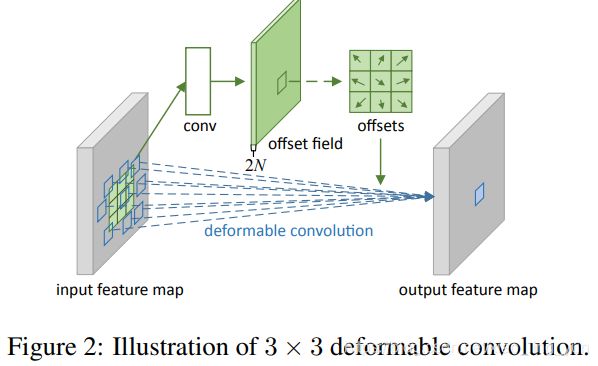
具体实现,我们以3 * 3 的卷积核为例,论文原图如下:其实就是在不同的卷积层后面加入一个卷积层来学习输入特征图中每个像素点的位置偏移,然后将学到的X轴和Y轴上的位置偏移加入到输入特征图中,在进行后续的卷积。(细节的话可以去看看专门讲这一块的博客或者原文或者等我出一个。。。)
可形变卷积和一般卷积的区别,更直观的体现可以看下图:可以发现 可形变卷积 在卷积操作时候采样的点更符合目标本身的形状和尺寸,反观标准卷积 卷积操作时候采样的点是固定的。
2.3 改进3 引入新的小分支,优化mask的预测质量
YOLACT++ 受 Mask Scoring R-CNN 的启发,预测anchor中目标分类的置信度(概率)和 预测结果mask的好坏之间关联并不大(比如分类结果正确,但mask质量不一定好),高质量的mask并不一定就对应着高的分类置信度,因此在模型后面添加Mask R-Scoring Network分支,该分支用来预测mask和Ground Truth之间的IOU(回归),最终将预测的IOU与分类置信度相乘作为最后的得分。
Mask Re-Scoring Network:
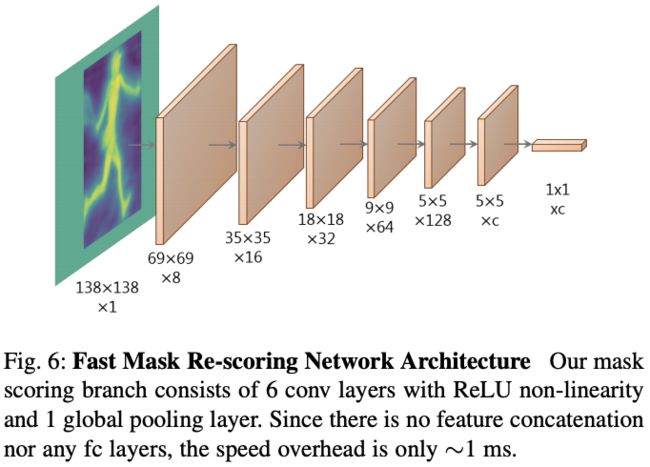
注意:(1)输入上的区别:该分支的输入是 YOLACT 经过crop后的(未经过 [0, 1] 阈值处理) mask (按理说这个输入就是YOLACT论文中Crop部分的输出!);而 MS R-CNN 对应分支使用 ROI Align 后的 特定尺寸特征 拼接 mask预测分支的结果作为输入;
(2)结构上的区别:应该也是为了实时性,YOLACT++的 Mask Re-Scoring 分支仅使用6个具有非线性ReLU激活函数的卷积层以及1个全局池化层组成,该分支没有特征的拼接、融合,没有FC,据悉耗时仅增加了1.2 ms,提升了1.5左右的mAP,这种代价还是比较合适的;但是MS R-CNN就有FC层,耗时28ms。
2.4 YOLACT++的小总结
总的来说,通过2.1 ~ 2.3 的这三个优化,使得模型与MS R-CNN这一类二阶段实例分割模型 大约10AP左右的差距变成了现在的4AP;与YOLACT相比提升了5AP左右,FPS下降了10左右,不过1秒27帧的处理速度还是挺快的。
