CVPR 2018 Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering

论文地址:https://arxiv.org/pdf/1707.07998.pdf
Background
在本文方法出现之前,大多数image captioning模型的视觉特征提取都是使用CNN来提取grid features。本文提出了使用目标检测方法,得到一个图片中相对重要的目标区域来进行视觉特征的提取。如下图所示,左边是常规的grid features,右边是本文提出的目标检测特征提取方法。

其次在这之前所有的模型都是一种 top-down的结构,以部分完成的caption文本输出的表示或与图像相关的内容作为上下文,这些结构通常被训练为有选择地关注卷积神经网络(CNN)的一个或多个层的输出。然而,这种方法很少考虑到如何确定需要注意的图像区域。在本文中,提出了一种bottom-up和top-down相结合的视觉注意机制。这两种机制的结合,让视觉特征的注意力机制能够更好的提取更加相关的特征以进行文本描述的生成。
Improvement
文中提出的两种注意力机制如下:
- top-down attention,由非视觉或任务特定上下文所驱动
- bottom-up attention,更容易被显著的、突出的、新奇的事物吸引
作者认为这些通过某一特定的任务驱动去选择性注意 CNN 某一两层卷积输出特征的方式并不是很关注这些感兴趣区域是如何选出来的。而人类实际上的注意方式总是会自发地注意到那些比较显著的内容,而后自主地去根据任务要求关注需要的地方。基于这样的启发,作者将 top-down attention 和 bottom-up attention 结合。
bottom-up attention 提取出显著图像区域,每个区域有一个自己对应的池化卷积特征。这时的显著图像区域是纯视觉上的特征,并没有受特定任务驱动,对显著区域的关注并不会厚此薄彼。接着,需要 top-down attention 根据任务特定的上下文预测图像区域的注意力分布,通过对这些区域的 image feature 的加权平均得到 attended feature vector。这就相当于我们现在根据额外的信息学习到了需要更注重哪一块而忽略哪一块,所以重新调整一下图像区域的权重。
Bottom-Up Attention
根据前面的描述 bottom-up attention 要做的事情就是提取纯视觉上的显著图像区域。作者通过 Faster RCNN(backbone:ResNet-101) 来产生这样的视觉特征 V V V,将 Faster RCNN 检测的结果经过非最大抑制和分类得分阈值选出一些显著图像区域,这些显著图像区域如下图所示.

具体来说,我们记输入的图片为 I I I,那么文本生成模型的输入都是一个大小为 k k k 的图像特征集 V = v 1 , v 2 , . . . , v k , v i ∈ R D V={v_1,v_2,...,v_k}, v_i \in R^D V=v1,v2,...,vk,vi∈RD 。作者对 Faster RCNN 的输出分类别按 IoU 阈值进行非最大抑制。然后,选择那些分类得分超过置信度阈值的区域作为显著图像区域。这样就保证了每一个框能对应一个类别。对于区域的特征是通过平均池化得到的, D = 2048 D=2048 D=2048.
Top-Down Attention LSTM
本文使用了两个LSTM模型,第一个是top-down visual attention model,第二个则是语言模型。具体结构如下图:
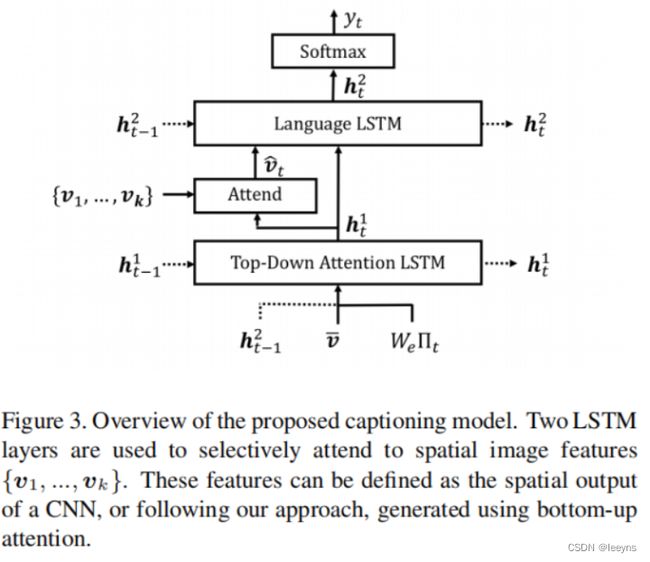
其中top-down visual attention model是用来找到当前step模型最应该关注的图像区域,它的输入为:
x t 1 = [ h t − 1 2 , v ‾ , W e Π t ] \boldsymbol{x}_{t}^{1}=\left[\boldsymbol{h}_{t-1}^{2}, \overline{\boldsymbol{v}}, W_{e} \Pi_{t}\right] xt1=[ht−12,v,WeΠt]
其中 v ‾ = 1 / k ∑ i v i \overline{\boldsymbol{v}}=1/k \sum_i v_i v=1/k∑ivi ,它是图片的平均池化特征, h t − 1 2 h_{t-1}^2 ht−12 是上一补的语言模型的输出, Π t \Pi_{t} Πt 是这一层的文本输入。
通过这一层LSTM模型得到 h t 1 h_t^1 ht1,通过线性映射从而能够得到当前step模型最应该关注的区域。公式如下:
a i , t = w a T tanh ( W v a v i + W h a h t 1 ) α t = softmax ( a t ) \begin{aligned} a_{i, t} & =\boldsymbol{w}_{a}^{T} \tanh \left(W_{v a} \boldsymbol{v}_{i}+W_{h a} \boldsymbol{h}_{t}^{1}\right) \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{a}_{t}\right) \end{aligned} ai,tαt=waTtanh(Wvavi+Whaht1)=softmax(at)
最终输入语言模型LSTM的图像特征表示为
v ^ t = ∑ i = 1 K α i , t v i \hat{\boldsymbol{v}}_{t}=\sum_{i=1}^{K} \alpha_{i, t} \boldsymbol{v}_{i} v^t=i=1∑Kαi,tvi
语言模型LSTM和常规LSTM类似,这里就不再赘述了,它的输入为top-down visual attention model 中LSTM的输出,以及通过attention得到的图像特征:
x t 2 = [ v ^ t , h 1 t ] x_t^2=[\hat{\boldsymbol{v}}_{t},h^t_1] xt2=[v^t,h1t]
Conclusion
最后作者也给出了一些例子,其中可以发现top-down 和 bottom-up相结合,让模型依赖显著的图像区域特征在一定程度上能起到作用。如下图:

但是如果存在模型区域识别有问题的例子,模型的表现就不太好,如下面狗跳起来去追飞盘,但是模型理解为了狗摊在草地上。作者的解释是在提取显著图像区域的时候并没有区分狗的头部和腿部。
