YOLOF - You Only Look One-level Feature 原理与实现解析
paper: You Only Look One-level Feature
code: GitHub - megvii-model/YOLOF
前言
Feature Pyramid Networks(FPN)之所以有效的两个原因:一是多尺度特征融合,即融合不同分辨率的特征输入从而得到更好的特征表示;二是分治策略,即将不同大小的物体分配到不同大小的输出层上进行预测从而克服尺度预测问题。
本文研究了这两个因素对最终效果的影响,以单阶段检测器RetinaNet为基础,通过将这两个因素进行解耦,设计出了四种不同的结构,MiMo、SiMo、MiSo、SiSo,其中MiMo就是FPN原始的结构
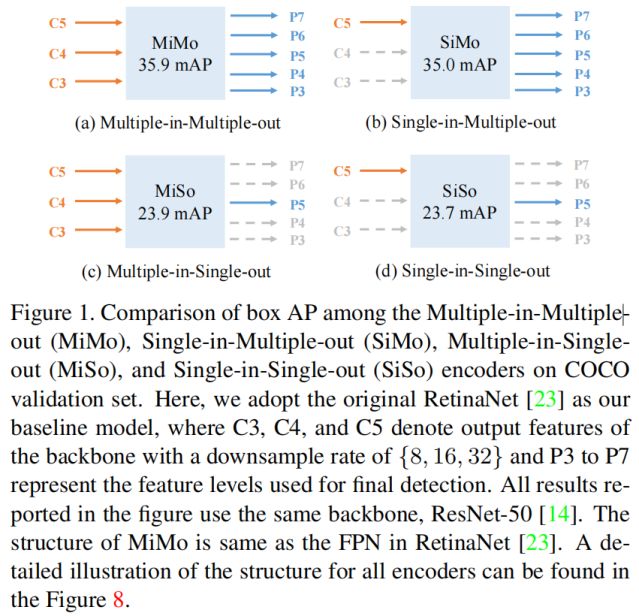
具体结构如下
从结果可以看出,相比与MiMo,SiMo的mAP只下降了0.9,而MiSo和SiSo下降了超过12个点,这说明(1)C5包含了足够的上下文信息来检测不同尺度的对象;(2)FPN中分治优化的作用远大于多尺度融合的作用。
作者将检测模型切分成backbone、encoder、decoder三个部分的组合,然后对比了MiMo和SiSo下各个部分的FLOPs,从下图可以看出,MiMo的decoder部分的FLOPs远大于SiSo,速度也比后者慢很多,这主要是因为需要在高分辨率的特征图上检测,比如降采样率为8的C3。

介绍
因为C5包含足够的信息进行检测,并且MiMo结构计算量大速度慢,因此作者希望用SiSo结构替换MiMo。但是SiSo的精度下降严重,作者发现精度下降主要是两个原因导致的:(1)C5感受野的范围是有限的,无法应对实际场景中变化剧烈的目标尺寸;(2)单层feature map中稀疏的anchor导致的样本不平衡问题。针对这两点,作者分别提出了Dilated Encoder和Uniform Matching,具体如下
Dilated Encoder
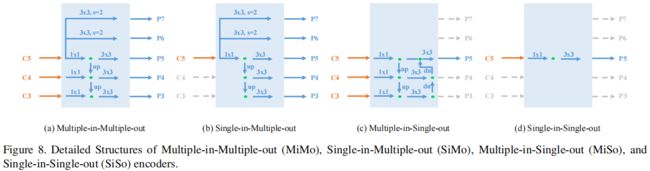
在MiMo和SiMo结构中,构建了多层次不同感受野的特征(P3-P7),并在不同的层级中分别检测尺度相匹配的物体。但是single-level特征的感受野是固定的,如下图(a)所示,C5的感受野只能覆盖有限的尺度变化范围,因此当目标的尺度与感受野不匹配时就会影响模型的检测效果。当使用膨胀卷积增大C5的感受野时,如下图(b)所示,因为是对所有原始覆盖的尺度乘以一个大于1的因子,所以虽然感受野变大了,但原本覆盖的一些尺度范围现在又覆盖不到了。

因此作者提出了Dilated Enconder,通过将C5原始覆盖尺度范围和扩大后的尺度范围结合从而覆盖所有尺度范围,如上图(c)所示。
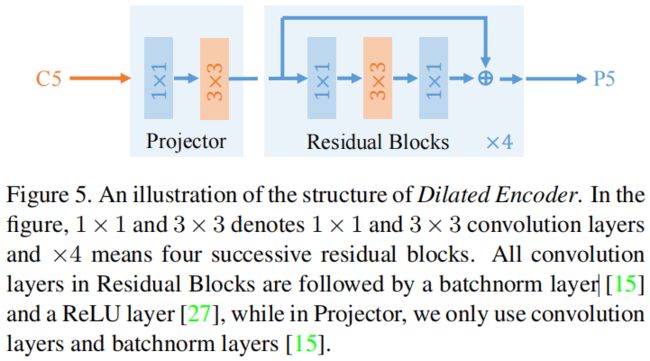
Dilated Encoder由Projector和Residual Blocks组成,其中Projector包含一个1x1卷积用于降维和一个3x3卷积用于提炼语义信息,这部分和原始的FPN是一样的。接下来是4个连续的Residual Block,中间的3x3卷积是膨胀卷积,每个Residual Block中的膨胀率不同从而可以得到不同感受野的特征,覆盖目标的所有尺度范围。文中dilation rate分别设置为2,4,6,8。
Uniform Matching
当从MiMo结构换成SiSo时,anchor的数量从100k降到了5k,当从原始的密集anchor变成稀疏anchor并且使用Max-IoU的匹配方式时,如下图所示,大目标会产生更多的positive anchor,造成正样本不平衡问题,从而导致模型在训练时更关注大目标而忽略小目标。
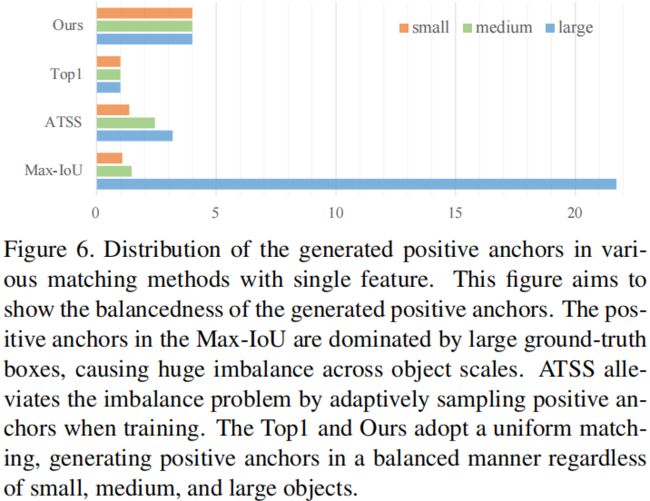
为了解决这个问题,作者提出了Uniform Matchting匹配策略,即对每个ground-truth box都选择最近的k个anchor作为正样本,这样每个目标不管尺度大小都有相同数量的正样本,从而保证每个目标都能参与训练并且贡献程度相同。此外还有一个附加条件,即忽略IoU>0.7的负样本和IoU<0.15的正样本。
YOLOF
YOLOF的完整结构如下所示
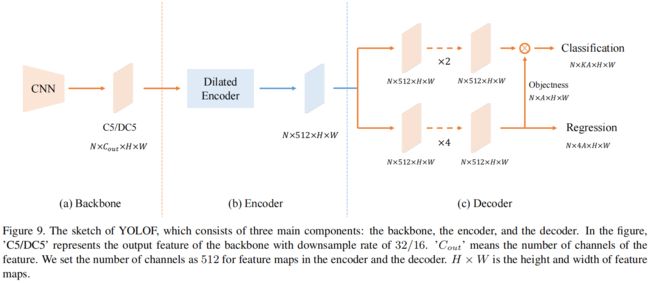
具体细节
- backbone采用ResNet或ResNeXt,取backbone的输出特征图C5,通道数为2048,下采样率为32。
- Dilated Encoder中Projector的1x1和3x3卷积的输出通道数为512,Residual Blcoks中第一个1x1卷积负责降维输出通道数为128,3x3膨胀卷积的dilation rate分别为2,4,6,8,最后的1x1卷积输出通道数为512。
- Decoder部分采用和RetinaNet一样的两个平行的任务分支,分类和回归。但有两处改动:一是仿照DETR中的FFN,分类分支有2个卷积层,回归分支有4个卷积层;二是仿照Autoassign增加一个implicit objectness预测分支,这个分支没有监督信息,用于抑制背景区域的高响应,和分类分支的输出相乘作为最终的分类结果。
- 因为稀疏的anchor导致和gt的匹配质量下降,对原始输入增加random shift操作来缓解这个问题。训练过程中上下左右随机移动图片最多32个像素,增加gt和高质量anchor匹配的概率。
- 限制anchor中心的位移,即当中心坐标的预测相比anchor中心偏离大于32个像素时,强制裁剪为32,防止产生较大的梯度。
- 在输出特征图上每个位置设置宽高比为1,5种尺度共5个anchor
实现差异
这部分是MMDetection官方解读的内容
在文章中,label assignment的方式如下:
- 遍历每个 gt bbox,然后选择 topk 个距离最近的 anchor 作为其匹配的正样本
- 由于存在极端比例物体和小物体,上述强制 topk 操作可能出现 anchor 和 gt bbox 的不匹配现象,为了防止噪声样本影响,在所有正样本点中,将 anchor 和 gt bbox 的 iou 低于 0.15 的正样本(因为不管匹配情况,topk 都会选择出指定数目的正样本)强制认为是忽略样本,在所有负样本点中,将 anchor 和 gt bbox 的 iou 高于 0.75 的负样本(可能该物体比较大,导致很多 anchor 都能够和该 gt bbox 很好的匹配,这些样本就不适合作为负样本了)强制认为是忽略样本
作者在代码中的实现方式如下:
- 遍历每个 gt bbox,然后选择 topk 个距离最近的 anchor 作为其匹配的正样本
- 遍历每个 gt bbox,然后选择 topk 个距离最近的预测框作为补充的匹配正样本
- 计算 gt bbox 和预测框的 iou,在所有负样本点中,将 iou 高于 0.75 的负样本强制认为是忽略样本
- 计算 gt bbox 和 anchor 的 iou,在所有正样本点中,将 iou 低于 0.15 的正样本强制认为是忽略样本
可以发现相比于论文描述,实际上代码额外动态补充了一定量的正样本,同时也额外考虑了一些忽略样本。相比于纯粹采用 anchor 和 gt bbox 进行匹配,额外引入预测框,可以动态调整正负样本,理论上会更好。
但这种匹配方式可能会引起重复索引匹配的问题,具体细节见参考中的解释,这里不再细述。
实验结果
Comparison with RetinaNet
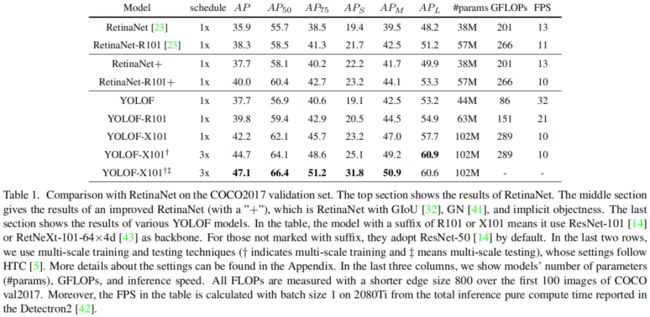
YOLOF在减少57%的flops和2.5倍的推理速度的情况下,可以获得和RetinaNet相似的精度。因为C5的感受野比较大,所以小目标的检测不如RetinaNet,但同时因为采用了dilated residual block,大目标的检测效果要比RetinaNet好。
Comparison with DETR
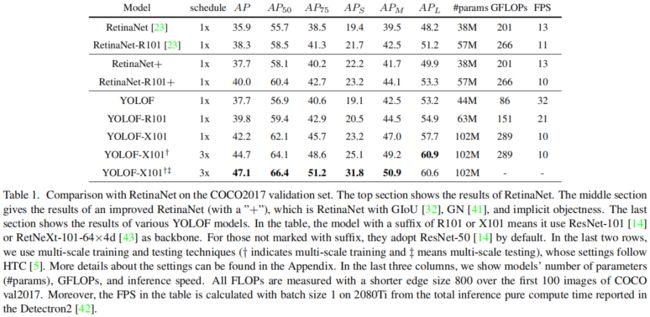
YOLOF可以获得和DETR相似的精度,但收敛速度时后者的7倍。因为DETR的transformer层捕捉全局信息,而YOLOF中的卷积层更关注局部信息,因为在小目标的检测上YOLOF的效果更好,在大目标上DETR更好。
Comparison with YOLOv4

在采用了和YOLOv4相同的数据增强方法,three-phase训练方式,并且backbone的输出特征图采用膨胀卷积后,YOLOF在精度和速度上都超过了YOLOv4。
消融实验
Dilated Encoder and Uniform Matching
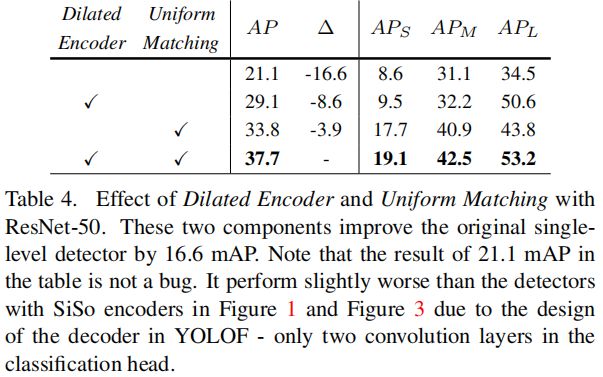
可以看出Dilated Encoder和Uniform Matching都能带来精度的提升,一起使用时精度进一步提升。
Number of ResBlock

Dilated Encoder中residual block的数量虽然越多精度越高,但为了平衡精度和速度,文章中选的4。
Different dilations
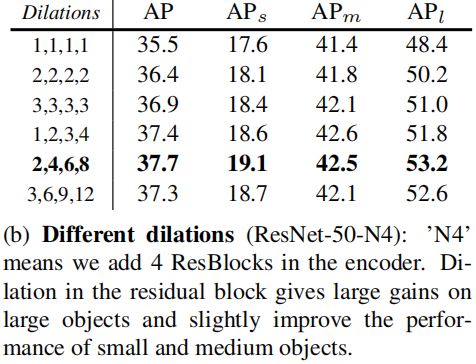
residul block中膨胀卷积的膨胀率为2,4,6,8时,模型的精度最高。
Add shortcut or not
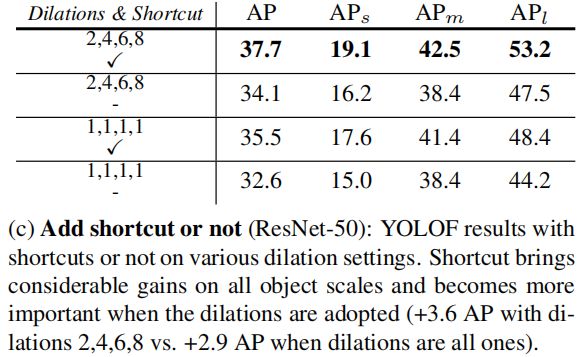
有shortcut时精度更高,因为shortcut可以组合不同的尺度范围。
Number of positives

在Uniform Matching中,k=4时精度最高。
Uniform matching vs. other matchings
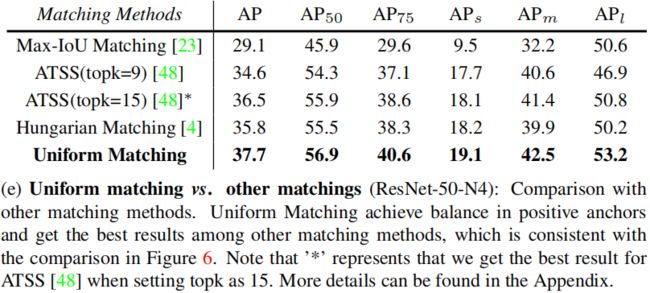
可以看出,Uniform Matching的分配方式取到了最高的精度。
参考
轻松掌握 MMDetection 中常用算法(六):YOLOF - 知乎