MNN卷积性能提升90%!ARMv86正式投用

ARMv86指令集新增了通用矩阵乘指令与bf16的支持,这些指令理论性能是ARMv82sdot的2倍;使用这些指令实现int8/bf16矩阵乘能够带来显著的性能提升。本文使用ARMv86的新增指令对MNN的ConvInt8和MatMul算子进行实现,最高得到了大约90%的性能提升。

技术背景
为了提升端侧推理速度,降低内存占用,MNN除了支持fp32的模型推理外,还支持fp16, bf16, int8等数据类型的推理。这些低bit数据类型能够损失部分精度的情况下降低内存占用,提升推理速度。目前fp16和int8在支持ARMv82的设备上使用sdot加速能够带来超过fp32的性能;bf16由于没有计算指令的支持,只能通过回退到fp32进行计算,因此只能降低内存占用,无法带来性能提升。ARMv86指令集新增了通用矩阵乘指令和bf16的计算指令,这将提升int8和bf16的计算性能,使得低精度计算的性能收益更高。
Armv8.6-A在SVE和NEON指令中新增了通用矩阵乘(GEMM)指令,这些指令相比之前的乘法、乘加指令,能够降低访存并提升计算量。而在深度学习的模型推理中,GEMM是计算占比非常高的计算,因此使用ARMv8.6-A中的新指令可以大幅提升模型推理性能。

目前iOS中使用A16的设备:iPhone 14 Pro/Pro Max,Android中使用高通骁龙8+的设备:小米12系列、三星Galaxy S22系列、一加10系列、iQOO 9/10系列、Realme GT 2 Pro、摩托罗拉Edge X30等设备都已经支持了ARMv8.6-A指令,因此目前ARMv86指令已经到了应用阶段,可以使用该指令在移动端加速模型推理。

加速原理
本文主要介绍加速指令为smmla与bfmmla利用smmla计算GEMM-int8,bfmmla指令来计算GEMM-bf16;这两条指令相比sdot指令,在延迟不变的情况下,计算量是sdot的2倍,因此相比sdot理论加速比为100%。

smmla
指令格式:
SMMLA Vd.4S, Vn.16B, Vm.16Bsmmla指令对int8矩阵执行乘法和累加操作。该指令具体会对输入的的两个128 bit寄存器执行GEMM-int8操作,并将结果存储在一个128 bit的寄存器中。其中两个寄存器的内容分别2 x 8 x int8, 结果寄存器的内容为2 x 2 x int32,实际执行的操作为[2, 8] @ [8, 2] -> [2, 2],共执行32次乘法和32次加法;对应的逻辑如下:for i = 0 to 1 for j = 0 to 1 sum = Elem[addend, 2*i + j, 32]; for k = 0 to 7 sum += Int(Elem[op1, 8*i + k, 8]) * Int(Elem[op2, 8*j + k, 8]); Elem[result, 2*i + j, 32] = sum;bfmmla
指令格式:
BFMMLA Vd.4S, Vn.8H, Vm.8Hbfmmla指令对bf16矩阵执行乘法和累加操作。该指令具体会对输入的的两个128 bit寄存器执行GEMM-bf16操作,并将结果存储在一个128 bit的寄存器中。其中两个寄存器的内容分别2 x 4 x bf16, 结果寄存器的内容为2 x 2 x fp32,实际执行的操作为[2, 4] @ [4, 2] -> [2, 2],共执行16次乘法和16次加法;对应的逻辑如下:for i = 0 to 1 for j = 0 to 1 sum = Elem[addend, 2*i + j, 32]; for k = 0 to 3 prod0 = BFMul(Elem[op1, 4*i + 2*k + 0, 16], Elem[op2, 4*j + 2*k + 0, 16]); prod1 = BFMul(Elem[op1, 4*i + 2*k + 1, 16], Elem[op2, 4*j + 2*k + 1, 16]); sum = BFAdd(sum, BFAdd(prod0, prod1)); Elem[result, 2*i + j, 32] = sum;

技术实现
在支持最新指令时需要考虑以下问题:
用户接口:用户执行模型推理时可以方便的选择推理使用数据类型;
编译兼容性:低版本NDK/编译器也能够正常编译;
执行兼容性:在不支持ARMv86的设备上能够正确执行;
性能:在使用新指令时重新计算Kernel分块大小,尽可能降低访存冗余;
▐ 用户接口
对于int8量化模型,在用户执行推理时会模型使用int8精度计算量化算子。如果设备支持ARMv86则会使用smmla指令加速的算子。对于浮点模型,在用户执行模型推理时,可以通过BackendConfig中的Precision选项来控制推理精度,选择默认精度Precision_Normal时会使用fp32进行推理,选择低精度Precision_Low时则会使用fp16进行推理。为了区分fp16与bf16,我们新增了Precision_Low_BF16 选项,当用户将精度设为此选项时,会执行bf16后端,如果设备支持ARMv86则会使用bfmmla指令加速的算子。
▐ 编译兼容性
直接使用上述指令需要较高版本的编译器支持,为了兼容低版本的编译环境,选择在汇编中使用二进制指令.inst的方式使用上述指令。为降低代码开发和维护难度,通过Python脚本对汇编代码进行预处理的方式来生成.inst代码;该脚本可以执行如下转换:
smmla v16.4s, v2.16b, v0.16b -> .inst 0x4e80a450 // smmla v16.4s, v2.16b, v0.16bbfmmla v19.4s, v7.8h, v1.8h -> .inst 0x6e41ecf3 // bfmmla v19.4s, v7.8h, v1.8h
转换代码如下,可以逐行读取文件并根据指令的寄存器编号生成对应的二进制指令,并将原指令作为同行注释。
class Assembly():
# ....
def sdot(self, operand1, operand2, operand3):
# SDOT ., ., .[offset]
Vd, Ta = self.operand_spilt(operand1)
Vn, Tb = self.operand_spilt(operand2)
Vm, Tc = self.operand_spilt(operand3)
Tc, offset = self.t_split(Tc)
# other flag:
# offset = flag[4] * 2 + opcode[-1]
# dst == '4s' ? opcode[1] = 1 : opcode[1] = 0
opcode = list('01001111100')
flag = list('111000')
# set Q
if Ta == '2s' and Tb == '8b':
opcode[1] = '0'
# set offset
if offset == 1 or offset == 3:
opcode[-1] = '1'
if offset == 2 or offset == 3:
flag[4] = '1'
opcode = ''.join(opcode)
flag = ''.join(flag)
return self.gen_inst(opcode, flag, Vm, Vn, Vd)
def smmla(self, operand1, operand2, operand3):
# SMMLA .4S, .16B, .16B
opcode = '01001110100'
flag = '101001'
Vd = self.operand_to_bin(operand1)
Vn = self.operand_to_bin(operand2)
Vm = self.operand_to_bin(operand3)
return self.gen_inst(opcode, flag, Vm, Vn, Vd)
def bfmmla(self, operand1, operand2, operand3):
# BFMMLA .4S, .8H, .8H
opcode = '01101110010'
flag = '111011'
Vd = self.operand_to_bin(operand1)
Vn = self.operand_to_bin(operand2)
Vm = self.operand_to_bin(operand3)
return self.gen_inst(opcode, flag, Vm, Vn, Vd) ▐ 执行兼容性
上述指令仅支持最新的设备,考虑执行兼容性问题,需要在运行时通过CPU flag来判断设备是否支持该指令。在Linux系统中可以使用 getauxval(AT_HWCAP) & HWCAP2_I8MM 来判断;在Android系统中可以使用 getauxval(AT_HWCAP) & 0x00002000 来判断。
▐ 通用矩阵乘实现
对于[e, l] @ [l, h] -> [e, h]的矩阵乘,内存访问次数为:![]() ,实际访存存在冗余情况,其中weight和input都重复访问了h, e次。
,实际访存存在冗余情况,其中weight和input都重复访问了h, e次。
for i in e:
for j in h:
for k in l:
output[i, j] += weight[i, k] * input[k, j]对e, h进行loop tiling可以降低访存冗余次数, 对于tiling size为ep, hp的矩阵乘,内存访问次数为:![]()
for i in e/ep:
for j in h/hp:
y00 = y01 = ... = ynn = 0
for k in l:
w0 = weight[i * ep + 0]
# ...
wn = weight[i * ep + ep-1]
x0 = input[k, j * hp + 0]
# ...
xn = input[k, j * hp + hp-1]
y00 += x0 * w0
# ...
ynn += xn * wn
output[i * ep, j * hp] = y00
output[i * ep + ep-1, j * hp + hp-1] = ynn因此我们可以对GEMM进行Tiling,并实现ep, hp的GemmKernel,从而降低访存冗余。而ep和hp的大小则受限于寄存器的数目,因此可以求解如下公式来获得最佳的ep与hp,进而实现对应的Kernel。
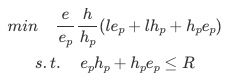
▐ GemmInt8实现
int8矩阵乘主要用于量化卷积的运算。在MNN中,量化卷积算子为ConvInt8,大部分情况下该算子的实现为Im2Col + GemmInt8。因此可以使用smmla指令实现GemmInt8函数从而对量化卷积算子进行加速。
忽略MNN的NC4HW4布局,ConvInt8的计算流程可以简化为以下步骤:
模型加载时对
weight重排序,将[oc, ic, kh, kw]重排为[oc, ic*kh*kw];模型推理时对
input执行Im2Col获取[ic*kh*kw, oh*ow]执行矩阵乘
GemmInt8,[oc, ic*kh*kw] @ [ic*kh*kw, oh*ow] -> [oc, oh, ow]
考虑到smmla执行为2x8的操作,因此一次可以计算lp = 8,每个向量寄存器可以加载h或e维度的数据量为2,可用向量寄存器总数为32,在计算量不变的情况下尽可能降低内存访问次数,所以可以得到如下公式:

同时考虑MNN的NC4HW4存储格式,lp = 8因此需要对输入的ic进行重排,因此设置ep = 4不再需要对输出内存布局进行重排;可以计算得到hp = 10时访存次数最低。所以我们采用的分块策略为[ep = 4, hp = 20, lp = 8],实现该分块策略的kernel所需要的向量寄存器数量为:weight = 2, input = 10, res = 20,总共使用32个。对于oh*ow除以20的余数部分,分别实现hp = 16, 8, 4, 2, 1的kernel即可。
由于smmla的结果是2x2的矩阵,因此其并不连续,还需要对数据进行重排,可以使用unzp指令实现。

kernel部分实现如下:
LoopSz_TILE_20:
// src : 10 x [2 x 8] : v2-11
// weight : 2 x [2 x 8] : v0-1
// dst : 10 x 2 x [4] : v12-v31
ld1 {v0.16b, v1.16b}, [x12], #32 // weight
ld1 {v2.16b, v3.16b, v4.16b, v5.16b}, [x11], #64 // src
.inst 0x4e80a44c // smmla v12.4s, v2.16b, v0.16b
.inst 0x4e81a44d // smmla v13.4s, v2.16b, v1.16b
.inst 0x4e80a46e // smmla v14.4s, v3.16b, v0.16b
.inst 0x4e81a46f // smmla v15.4s, v3.16b, v1.16b
ld1 {v6.16b, v7.16b, v8.16b, v9.16b}, [x11], #64
.inst 0x4e80a490 // smmla v16.4s, v4.16b, v0.16b
.inst 0x4e81a491 // smmla v17.4s, v4.16b, v1.16b
.inst 0x4e80a4b2 // smmla v18.4s, v5.16b, v0.16b
.inst 0x4e81a4b3 // smmla v19.4s, v5.16b, v1.16b
ld1 {v10.16b, v11.16b}, [x11], #32
.inst 0x4e80a4d4 // smmla v20.4s, v6.16b, v0.16b
.inst 0x4e81a4d5 // smmla v21.4s, v6.16b, v1.16b
.inst 0x4e80a4f6 // smmla v22.4s, v7.16b, v0.16b
.inst 0x4e81a4f7 // smmla v23.4s, v7.16b, v1.16b
.inst 0x4e80a518 // smmla v24.4s, v8.16b, v0.16b
.inst 0x4e81a519 // smmla v25.4s, v8.16b, v1.16b
.inst 0x4e80a53a // smmla v26.4s, v9.16b, v0.16b
.inst 0x4e81a53b // smmla v27.4s, v9.16b, v1.16b
.inst 0x4e80a55c // smmla v28.4s, v10.16b, v0.16b
.inst 0x4e81a55d // smmla v29.4s, v10.16b, v1.16b
subs x13, x13, #1
.inst 0x4e80a57e // smmla v30.4s, v11.16b, v0.16b
.inst 0x4e81a57f // smmla v31.4s, v11.16b, v1.16b
bne LoopSz_TILE_20
LoopSzEnd_TILE_20:
add x2, x2, x15 // weight += dz * src_depth_quad * (GEMM_INT8_UNIT * GEMM_INT8_SRC_UNIT);
sub x5, x5, #1 // dz--
// transpose
uzp1 v11.2d, v12.2d, v13.2d
uzp2 v12.2d, v12.2d, v13.2d
// ...
uzp1 v29.2d, v30.2d, v31.2d
uzp2 v30.2d, v30.2d, v31.2d
Int32ToFloat v11, v12, v13, v14
Int32ToFloat v15, v16, v17, v18
Int32ToFloat v19, v20, v21, v22
Int32ToFloat v23, v24, v25, v26
Int32ToFloat v27, v28, v29, v30
cbnz x8, Tile20Quan
sub x4, x4, #256
st1 {v11.4s, v12.4s, v13.4s, v14.4s}, [x0], #64
st1 {v15.4s, v16.4s, v17.4s, v18.4s}, [x0], #64
st1 {v19.4s, v20.4s, v21.4s, v22.4s}, [x0], #64
st1 {v23.4s, v24.4s, v25.4s, v26.4s}, [x0], #64
st1 {v27.4s, v28.4s, v29.4s, v30.4s}, [x0], x4
add x4, x4, #256▐ GemmBF16实现
bf16矩阵乘是低精度浮点矩阵乘,在对精度要求不是特别高的情况下可以替代fp32矩阵乘法。在MNN中,MatMul, Conv等算子在设置为低精度的情况下都会使用fp16/bf16的矩阵乘进行计算,因此可以使用bfmmla对低精度矩阵乘进行加速。该实现与smmla理论相似,不同的是bfmmla执行的是2x4的计算,因此lp = 4,因此不需要对输入的ic进行重排计算,可以取hp = 8, ep = 12,此时需要的寄存器数目为: weight = 4, input = 6, dst = 24, 超出2个;此时可以将weight分2次加载。这种实现相对于smmla的实现,还需要考虑oc % 8 != 0的情况,分别实现hp = 8, 4; ep = 12, 8, 4, 2, 1的kernel即可。
该kernel的部分实现如下:
LoopL:
// A [12, 4, bf16] : rn = 6 : v2 - v7
// B [ 8, 4, bf16] : rn = 2 : v0 - v1
// C [12, 8, fp32] : rn = 24 : v8 - v31
ld1 {v2.8h, v3.8h, v4.8h, v5.8h}, [x15], #64 // A: 8 * 4 * sizeof(int16_t)
ld1 {v6.8h, v7.8h}, [x15], #32 // A: 4 * 4 * sizeof(int16_t)
ld1 {v0.8h, v1.8h}, [x2], #32 // B: 4 * 4 * sizeof(int16_t)
.inst 0x6e40ec48 // bfmmla v8.4s, v2.8h, v0.8h
.inst 0x6e41ec49 // bfmmla v9.4s, v2.8h, v1.8h
.inst 0x6e40ec6a // bfmmla v10.4s, v3.8h, v0.8h
.inst 0x6e41ec6b // bfmmla v11.4s, v3.8h, v1.8h
.inst 0x6e40ec8c // bfmmla v12.4s, v4.8h, v0.8h
.inst 0x6e41ec8d // bfmmla v13.4s, v4.8h, v1.8h
.inst 0x6e40ecae // bfmmla v14.4s, v5.8h, v0.8h
.inst 0x6e41ecaf // bfmmla v15.4s, v5.8h, v1.8h
.inst 0x6e40ecd0 // bfmmla v16.4s, v6.8h, v0.8h
.inst 0x6e41ecd1 // bfmmla v17.4s, v6.8h, v1.8h
.inst 0x6e40ecf2 // bfmmla v18.4s, v7.8h, v0.8h
.inst 0x6e41ecf3 // bfmmla v19.4s, v7.8h, v1.8h
ld1 {v0.8h, v1.8h}, [x2], #32 // B: 4 * 4 * sizeof(int16_t)
.inst 0x6e40ec54 // bfmmla v20.4s, v2.8h, v0.8h
.inst 0x6e41ec55 // bfmmla v21.4s, v2.8h, v1.8h
.inst 0x6e40ec76 // bfmmla v22.4s, v3.8h, v0.8h
.inst 0x6e41ec77 // bfmmla v23.4s, v3.8h, v1.8h
.inst 0x6e40ec98 // bfmmla v24.4s, v4.8h, v0.8h
.inst 0x6e41ec99 // bfmmla v25.4s, v4.8h, v1.8h
.inst 0x6e40ecba // bfmmla v26.4s, v5.8h, v0.8h
.inst 0x6e41ecbb // bfmmla v27.4s, v5.8h, v1.8h
.inst 0x6e40ecdc // bfmmla v28.4s, v6.8h, v0.8h
.inst 0x6e41ecdd // bfmmla v29.4s, v6.8h, v1.8h
.inst 0x6e40ecfe // bfmmla v30.4s, v7.8h, v0.8h
.inst 0x6e41ecff // bfmmla v31.4s, v7.8h, v1.8h
subs x12, x12, #1
bgt LoopL
LoopLEnd:
uzp1 v7.2d, v8.2d, v9.2d
uzp2 v8.2d, v8.2d, v9.2d
// ...
uzp1 v29.2d, v30.2d, v31.2d
uzp2 v30.2d, v30.2d, v31.2d
cbz x4, StoreLH8
性能对比
性能测试使用高通骁龙8gen1,其中单元测试使用Cortex-A710大核;模型测试使用Cortex-X2超大核。
▐ GemmInt8性能对比
smmla理论性能为sdot的2倍,在规模较大的卷积h,w = 33, kh = kw = 2, ic = 256, oc = 1024, 此时e = h = l = 1024, 实测性能为: sdot: 16.404401 ms, smmla: 8.703851 ms,性能提升为88.47%,接近理论性能;对于其他规模的卷积测试性能如下:

目前的实现的加速效果主要在卷积算子,在模型测试中平均性能提升大约20%,具体性能对比如下:

▐ GemmBF16性能对比
bfmmla测试e = h = l = 1024的较大规模矩阵乘性能为:fp16-fmla: 32.04557 ms, bfmmla: 16.68548 ms,性能提升为92.10%,接近理论性能。对于其他规模矩阵乘的性能对比如下:
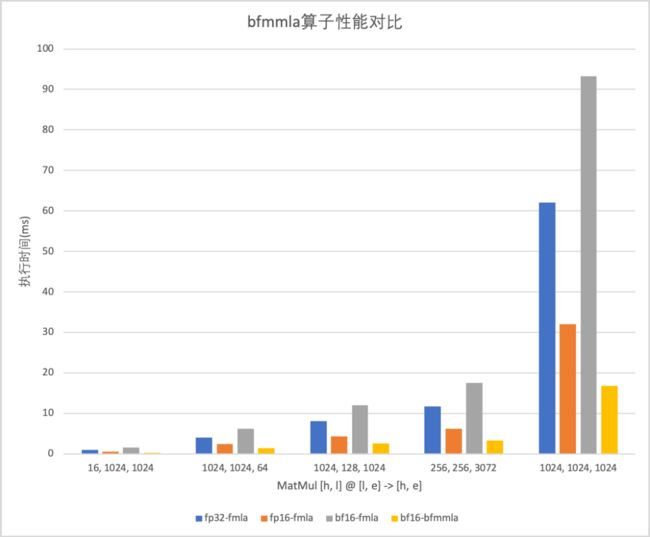
使用bfmmla实现的GemmBF16相比之前使用bf16-fmla的实现,有数倍的性能提升,解决了bf16后端性能劣势问题,使bf16更加实用;相比fp16-fmla在大模型大有约30%的性能提升,小模型性能持平。


展望
目前bf16后端仅Gemm使用新指令,其他部分仍使用fp32进行计算,模型推理速度相比于fp16优势不大;
目前GemmKernel实现还没有达到Near-Optimal-Gemm,仍有优化空间;
使用ARMv9的SVE指令,谓词指令可以减少Kernel实现数目,降低二进制大小;

参考
https://developer.arm.com/documentation/ddi0596/2020-12/SIMD-FP-Instructions/SMMLA--vector---Signed-8-bit-integer-matrix-multiply-accumulate--vector--
https://developer.arm.com/documentation/ddi0596/2020-12/SIMD-FP-Instructions/BFMMLA--BFloat16-floating-point-matrix-multiply-accumulate-into-2x2-matrix
https://docs.kernel.org/translations/zh_CN/arm64/elf_hwcaps.html
https://cs.android.com/android/platform/superproject/+/master:bionic/libc/kernel/uapi/asm-arm64/asm/hwcap.h;drc=04da58f5b3bc40dbbafb4f8422aa2991479d9e1e;l=70

团队介绍
大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。先后发布端侧推理引擎MNN,端侧实时视觉算法库PixelAI,商品三维重建工具Object Drawer等技术。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
该实现已在Github发布,地址:https://github.com/alibaba/MNN/releases/tag/2.2.0
本篇内容作者:王召德(雁行)
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法