图解OpenAI的秘密武器GPT-2:可视化Transformer语言模型
大数据文摘出品
来源:github
编译:小七、池俊辉、Andy今年,我们见识了许多令人眼花缭乱的机器学习的应用成果。其中OpenAI训练的GPT-2模型就展示出了惊艳的能力,它能够撰写出连贯而富有激情的论文,比当下其他所有的语言模型写的都好。
GPT-2其实并不是一种特别新颖的架构,它的架构非常类似于Transformer模型的Decoder结构。然而,GPT2是一个非常大的基于Transformer的语言模型,需要基于大量数据集进行训练。在这篇文章中,我们将介绍什么样的结构能够让模型产生好的结果,深入研究模型中的self-attention层,此外,我们将研究除语言建模之外的Transformer模型Decoder结构的应用。
我写本文主要是为了补充我之前的“图解Transformer模型”系列。
系列链接:
https://jalammar.github.io/illustrated-transformer/
通过图解的方式更直观地解释Transformer模型的内部工作原理,以及它们自发布以来的演变过程。我希望通过这种图形示例能够更容易地解释后来基于Transformer的模型,毕竟它们的内部工作原理是在不断发展的。
本文主要从以下几方面展开阐述
第一部分:GPT2和语言建模
语言模型的含义
用于语言建模的Transformers模型
与BERT的区别
Transformer 架构的演变
速成课程:探索GPT-2内部工作原理
深入了解内幕
GPT-2小结
第二部分:图解Self-Attention(自我关注)模型
自注意力(Self-Attention,不加mask)
- 创建查询向量、键向量和值向量
- 打分
- 求和
图解Masked Self-Attention
GPT-2的Masked Self-Attention
你做到了!
第三部分:语言建模番外
机器翻译
生成摘要
迁移学习
音乐生成
结论
第一部分 GPT2和语言模型
那么究竟什么是语言模型呢?
语言模型的含义
在The Illustrated Word2vec中,我们研究了语言模型是什么,它是能根据一个句子前半部分的单词预测出下一个单词的机器学习模型。最著名的语言模型是智能手机键盘,可以根据您当前键入的内容建议出下一个单词。
The Illustrated Word2vec:
https://jalammar.github.io/illustrated-word2vec/jalammar.github.io
从这个意义上讲,我们可以说GPT-2基本上是键盘应用程序的下一个单词预测功能,但它比你手机上的键盘输入法具有更大更复杂的功能。GPT-2是基于一个名为WebText大型数据集进行的训练,这个数据集大约有40G,是OpenAI研究人员为了研究从互联网上爬下来的。就存储大小来说,我使用的键盘应用程序SwiftKey占用了78MB的空间。训练出来的GPT-2的最小变体,占用500MB的存储空间来存储其所有参数。GPT-2的最大变体是最小变体的13倍,因此它可能需要占用超过6.5 GB的存储空间。
使用AllenAI GPT-2 Explorer来进行GPT-2建模是一个很好的方法,它使用GPT-2显示10个对下一个单词的预测结果,以及它们的概率分数。您可以选择其中一个单词,然后再查看下一个预测列表,循序渐进,持续不断地写下去。
用于语言建模的Transformers模型
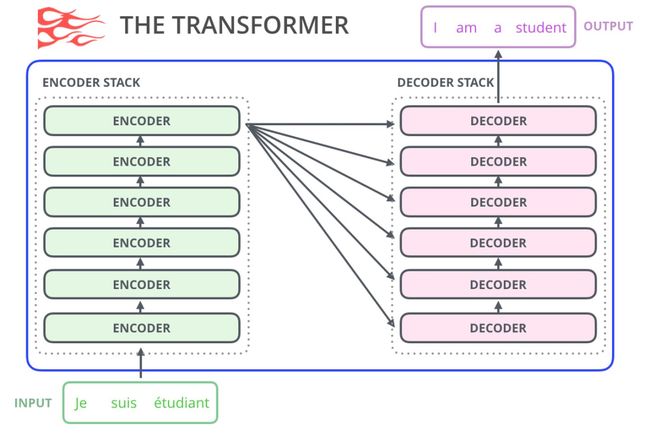
正如我们在“图解Transformer模型”中看到的那样,原始的 transformer模型由encoder和decoder组成,每个都是我们称之为 transformer 架构的堆栈。这种架构是合理的,因为该模型解决了机器翻译问题——过去encoder-decoder结构解决的问题。
在随后的许多研究工作中,这种架构要么去掉了encoder,要么去掉了decoder,只使用其中一种transformer堆栈,并尽可能高地堆叠它们,为它们提供大量的训练文本,并投入大量的计算机设备,以训练其中一部分语言模型,这一研究需要花费数十万美元,就像在研究AlphaStar时也投入了数百万美元的资金。
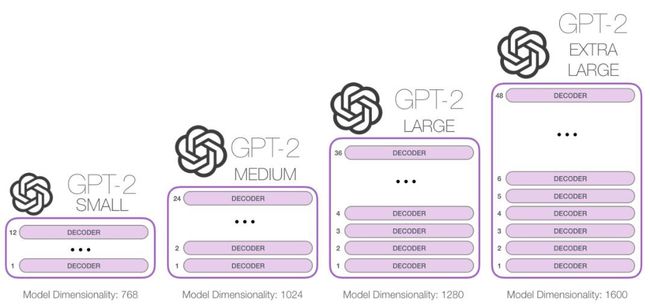
那么我们可以将这些块堆叠多高呢?事实证明,堆叠的高度是不同的GPT2模型之间大小有别的主要影响因素之一。
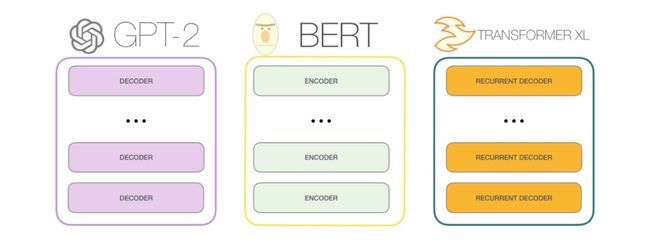
与BERT的区别
GPT-2是基于 transformer模型的decoder架构构建的。而BERT则是基于 transformer模型的encoder结构构建的。我们将在以下部分中研究两者的差异。两者之间的一个关键区别是,GPT2与传统语言模型一样,一次输出一个token。接下来让我们来举例说明,经过训练的GPT-2是如何背诵机器人第一定律(First Law of Robotics)的。
这些模型实际工作的方式是在生成每个token之后,添加到输入序列中,而新序列将成为下一步模型的输入。这就是“自回归(auto-regression)”的思想。但这种想法也使得RNN的效率大打折扣。
GPT2以及一些后来的模型如TransformerXL和XLNet本质上都是自回归的。而BERT不是,它是一种权衡。在失去自回归的过程中,BERT可以获得两边的单词,以结合上下文去获得更好的结果。而XLNet既使用了自回归,同时也找到了根据两边单词融合上下文的替代方法。
Transformer架构的演变
一个是encoder结构,如下图所示:
来自原始 transformer论文的encoder模块可以输入直到某个最大序列长度(例如512个token)。如果输入序列短于此限制,我们可以填充序列的其余部分。
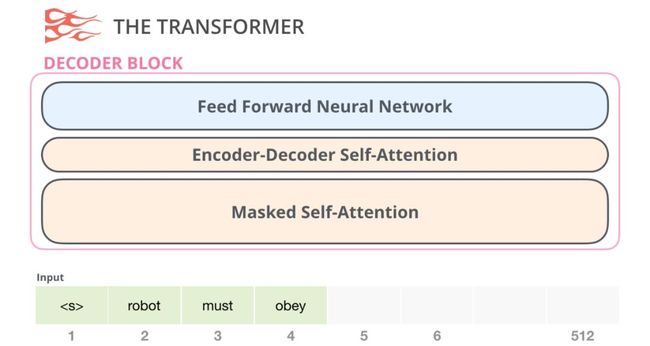
另一个是decoder结构,这个结构与encoder具有较小的体系结构差异——多了一层用于关注encoder中的特定片段:
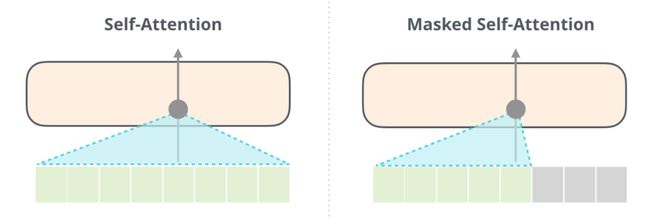
self-attention层的一个关键区别在于它隐藏了未来的tokens,而不是像BERT那样,将单词更改为[mask(掩码)],而是通过干扰阻止了从正在计算的位置右侧的tokens中得到的信息进入到self-attention层计算。
例如,如果我们要强调位置#4的路径,我们可以看到它只允许参与当前和之前的tokens:
重要的是,BERT使用的self-attention和GPT-2使用的masked self-attention之间的区别是明确的。正常的self-attention允许在其右侧的tokens达到峰值。而Masked self-attention可防止这种情况发生:
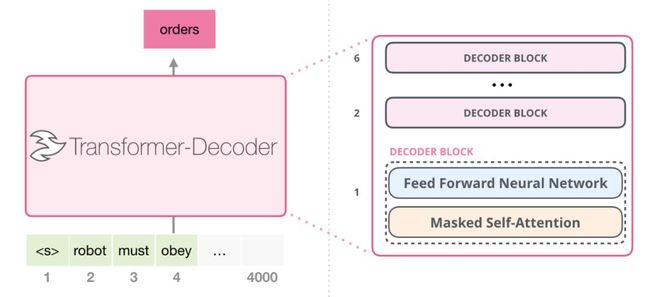
然后是只包含decoder的架构,在发表论文“通过总结长序列来生成Wikipedia”后,提出了另一种能够进行语言建模的transformer结构。这个架构不再使用Transformer的encoder结构。因此,我们将模型称为“Transformer-Decoder”。这种早期基于transformer的语言模型由六个decoder结构组成:
论文链接:
https://arxiv.org/pdf/1801.10198.pdf
Decoder结构是相同的。我扩展了第一个,所以你可以看到它的self-attention层是掩码变体。请注意,该模型现在可以在某个段中处理多达4,000个tokens——原来的 transformer只能处理512个,该模型有了较大提升。
这些结构与原始decoder结构非常相似,只是它们消除了第二个self-attention层。在“具有更深的Self-Attention的角色级语言建模”(https://arxiv.org/pdf/1808.04444.pdf)一文中实验了类似的体系结构,以创建一次预测一个字母/字符的语言模型。
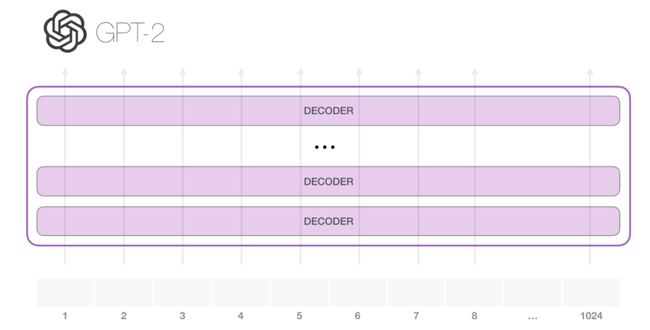
OpenAI GPT-2模型使用的就是只有decoder结构的transformer模型。
速成课程:探索GPT-2内部工作原理
看看里面,你会发现,这些话正在我的脑海深处割裂。电闪雷鸣,锋利的言语正在将我逼向疯狂的边缘。
让我们来研究一个已经训练好的GPT-2,看看它是如何工作的。
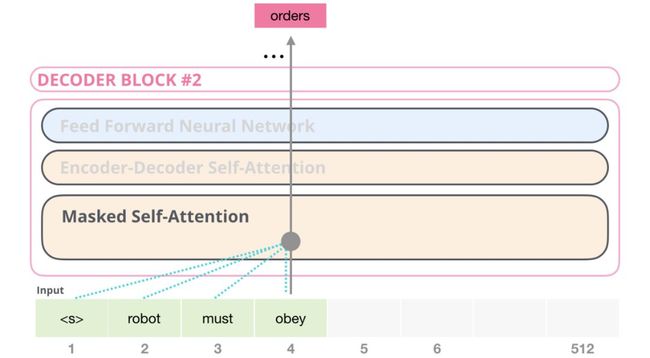
GPT-2可以处理1024个tokens。每个token沿其自己的路径经过所有的decoder结构。
运行经过训练的GPT-2的最简单方法是允许它自己进行漫游(技术上称为生成无条件样本),或者我们可以给它提示让它生成关于某个主题的文本(也就是生成交互式条件样本)。在不设条件的情况下,我们可以简单地给它设置一个开始token,并让它开始生成单词(训练模型使用<|endoftext|>作为其开始token,称之为
)。
该模型只有一个输入token,因此该路径将是唯一的活动路径。token通过所有层依次处理,然后沿该路径生成向量。该向量可以根据模型的词汇量进行评分(模型知道的所有单词,GPT-2中的单词为50,000个)。在这种情况下,我们选择了概率最高的token——“the”。但是我们也可能把事情搞混,因为有时你连续点击键盘应用程序中建议的第一个单词,它有时会卡在重复的循环中,唯一的出路就是你点击第二个或第三个建议的单词。这里就可能发生这种情况。GPT-2有一个名为top-k的参数,我们可以使用该参数让模型考虑除第一个字之外的采样(当top-k = 1时就是这种情况)。
在下一步中,我们将第一步的输出添加到输入序列,并让模型进行下一个预测:
请注意,第二条路径是此计算中唯一有效的路径。GPT-2的每一层都保留了自己对第一个token的解释,并将在处理第二个token时使用它(我们将在下一节中详细介绍有关self-attention的内容)。GPT-2不会根据第二个token重新解释第一个token。
深入了解内幕
输入编码
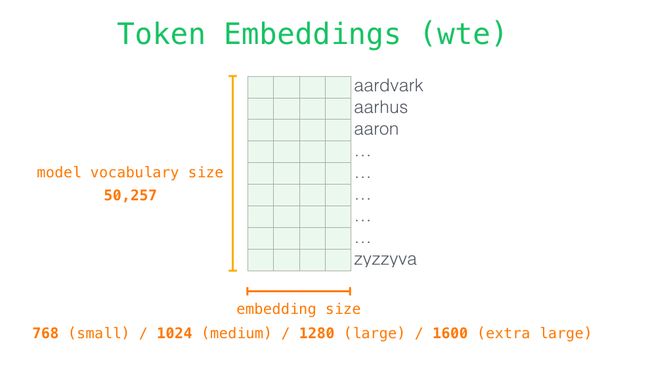
接下来看一下更多细节,以便更清楚地了解模型。让我们从输入开始。正如我们之前讨论过的其他NLP模型一样,模型在其embedding matrix(嵌入矩阵)中查找输入单词的embedding,embedding matrix是我们训练模型获得的结果之一。
每一行都是一个word embedding(单词嵌入):一个数字列表代表一个单词,并捕获它的一些含义。在不同的GPT2模型大小中该列表的大小是不同的。最小的模型使用每个字或每个token的embedding大小为768。
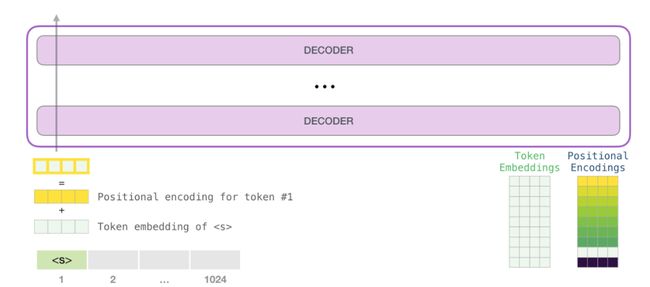
所以在开始时,我们会在embedding matrix中查找起始token
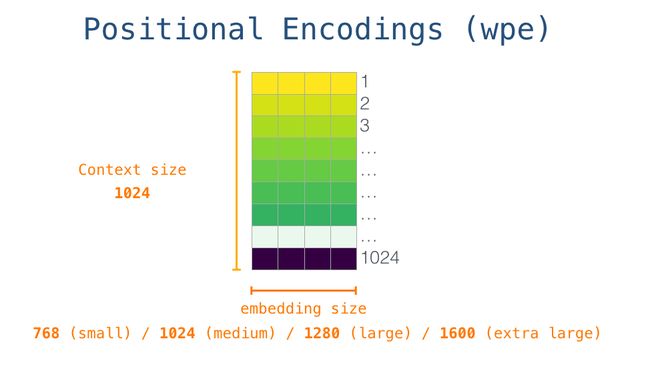
的嵌入。在将其交给模型中的第一个模块之前,我们需要结合位置编码,位置编码是一个指示序列中的字到transformer模块中顺序的信号。经过训练的模型包含一个矩阵,其中包含输入中1024个位置中每个位置的位置编码向量。
在此基础上,我们已经介绍了在传递给第一个 transformer模块之前如何处理输入单词。我们还知道构成训练好的GPT-2模型的两个权重矩阵。
将字发送到第一个transformer模块意味着查找其embedding并将位置#1的位置编码向量相加。
堆栈之旅
现在第一个模块可以首先将token传递给self-attention层处理,然后将其传递给神经网络层来处理。一旦第一个transformer模块处理了该token,它就会将其结果向量发送到堆栈中,以便由下一个模块处理。每个模块中的过程是相同的,但每个模块在self-attention层和神经网络子层中都有自己的权重。
Self-Attention回顾
语言严重依赖于语境。例如,看看下面的机器人第二定律:
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
我在句子中突出显示了三个地方,这三个单词都是指的是其他单词。如果不合并他们所指的上下文,就无法理解或处理这些单词。当模型处理这句话时,它必须能够知道:
It指的是机器人。
Such orders指的是前面所说的人类给予的命令。
The First Law是指前面完整的第一机器人定律。
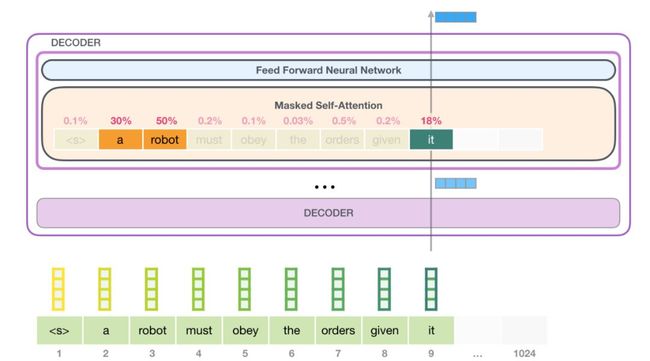
这就是self-attention层的作用。它结合了模型对有关的和相关连的词的理解,在处理该词之前解释某个词的上下文,并将其传递给神经网络层。它通过为分段中每个单词的相关性分配分数,并将它们的向量表示相加来实现这一点。
作为一个例子,第一模块中的这个self-attention层在处理单词“it”时正在关注“a robot”。它将传递给它的神经网络的向量是三个单词中每一个向量乘以它们的分数之和。
Self-Attention处理层
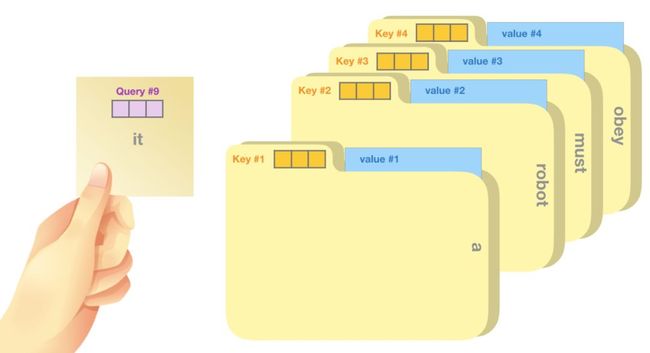
Self-attention 是沿着段中每个token的路径来处理。重要的组成部分是三个向量:
查询向量(query):查询是当前单词的代表,用来去对其他所有词(使用他们的键向量)进行打分,我们只关心我们当前正在处理的token的查询。
键向量(key):键向量类似于段落中所有单词的标签,它们是我们搜索相关单词时所匹配的内容。
值向量(value):值向量是实际的单词表示,一旦我们得出每个单词的相关程度,这些加起来表示当前单词的值。
一个粗略的比喻就是把它想象成一个文件柜。查询向量就像是一个粘滞便笺,上面有您正在研究的主题。键向量就像机柜内文件夹的标签。当您将标签与便签匹配时,我们会取出该文件夹的内容,这些内容是值向量。但是您不仅要查找一个值,还要使用文件夹的混合值。
将查询向量乘以每个键向量会为每个文件夹生成一个得分(技术上:先进行点积运算然后再用softmax函数进行归一化处理)。
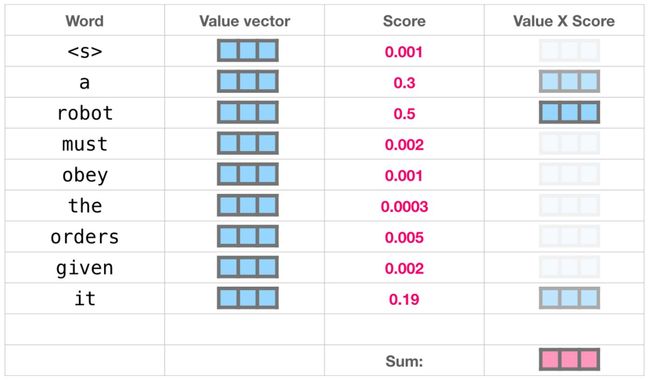
我们将每个值乘以其得分并相加——从而产生我们的self-attention结果。
这种加权的混合值向量产生了一个向量,它对robot这个词的“attention”为50%,对于单词a为30%,对 单词it为19%。在本文的后期,我们将更深入地研究self-attention。所以,让我们先继续沿着堆栈走向模型的输出。
模型输出
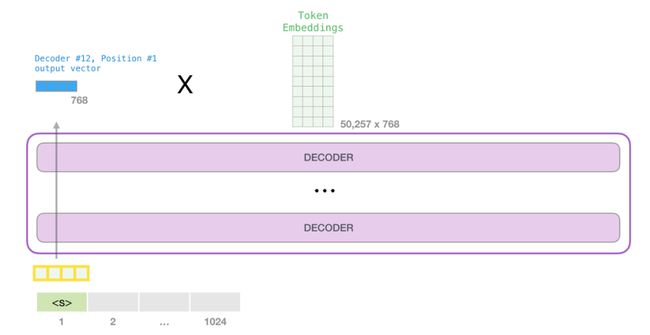
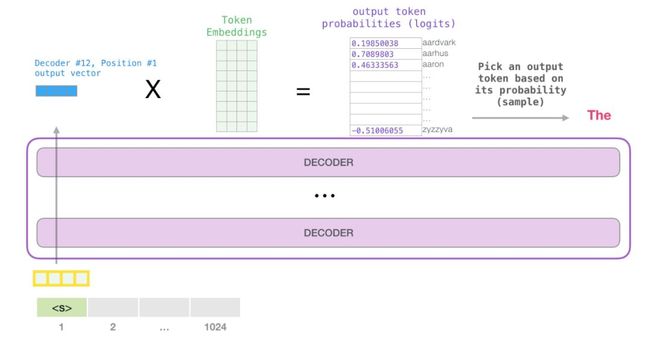
当模型中的第一模块产生其输出向量(self-attention的结果以及神经网络的结果)时,模型将该向量乘以embedding matrix。
回想一下,embedding matrix中的每一行都对应于模型词汇表中单词的embedding 。这种乘法的结果被解释为模型词汇表中每个单词的分数。
我们可以简单地选择得分最高的token(top_k = 1)。但如果模型也考虑了其他条件,则可以获得更好的结果。因此,更好的策略是使用分数作为选择该单词的概率,从整个列表中去抽样单词(因此具有较高分数的单词具有更高的被选择机会)。中间地带将top_k设置为40,并且让模型考虑具有最高分数的40个单词。
由此,模型完成了迭代,从而输出单个单词。模型继续迭代,直到生成整个上下文(1024个token)或直到生成序列结束token。
GPT-2模型小结
至此,关于GPT2的工作原理我就介绍完了。如果您想知道self-attention内部工作原理是什么,那么下文部分非常适合您。我创建它是为了引入更多的图形示例来描述self-attention,以便后来的transformer模型更易于检查和描述(比如:TransformerXL和XLNet)。
我想在这篇文章中提醒一些过于简化的内容:
在本文中“words”和“token”是可以互换使用的。但实际上,GPT2在词汇表中创建token是使用的字节对编码(Byte Pair Encoding)。这意味着token通常是words的一部分。
我们展示的示例在其推理/评估模式下运行GPT2。这就是为什么它一次只处理一个单词。在训练时,模型将针对较长的文本序列进行训练并一次处理多个tokens。此外,在训练时,模型将处理较大批量(512)并评估使用的批量大小。
我对向量进行了旋转或转置,以便更好地管理图像中的空间。在实施时,必须更精确。
Transformers使用大量的图层规范化,这非常重要。我们在“图解Transformer模型”一文中已经注意到其中的一些,在这篇文章中要更多地关注self-attentionin。
有时我需要显示更多的框来表示矢量,我指的是“放大”。如下图:
第二部分:图解self-attention(自我关注)模型
在前面的帖子当中,我们拿出这张图片来展示self-attention机制被应用在处理单词“it”的层中的示意:
在本节中,我们将详细介绍如何完成此操作。请注意我们将会以一种试图了解单个单词会发生什么的方式来看待它。这也是我们将会展示很多单个向量的原因。而实际的实现则是通过巨型矩阵的相乘来完成的。但是我想把重点放在对单词级别在这里会发生什么的直觉认识上。
Self-Attention(不加mask)
让我们首先看一下在自编码模块中计算出的初始的self-attention。我们使用一次只能同时处理四个tokens的简易的transformer模块。
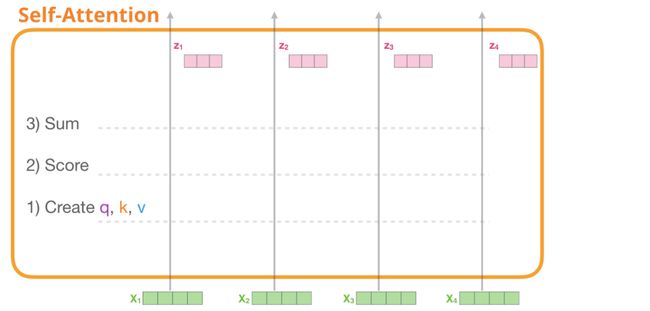
Self-attention被应用在下面三个主要的步骤中:
- 为每个路径创建query(查询向量), Key(键向量),和 Value vectors(值向量)。
- 对于每个输入token,使用其query(查询向量)对所有其他Key(键向量)进行评分。
- 将值向量乘以他们的相关分数后进行求和。
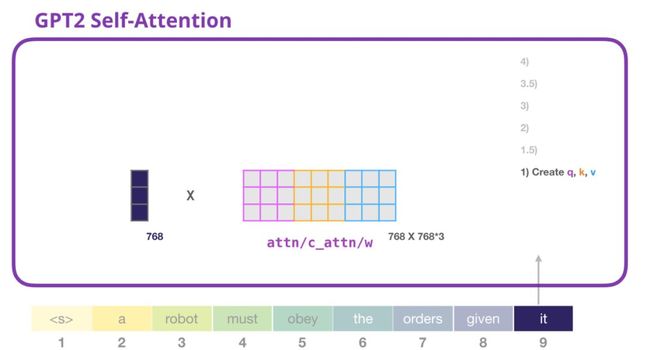
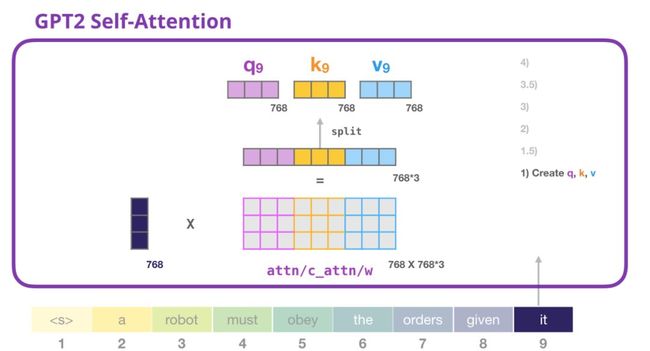
1.创建query(查询向量), key(键向量),和 value vector(值向量)
我们来看第一条路径。我们将取出它的query(查询向量)然后和所有的Key(键向量)进行比较。每个Key(键向量)会产生一个分数。自注意力机制的第一步就是为每一个token路径分别计算三个向量(我们先暂时忽略attention heads):
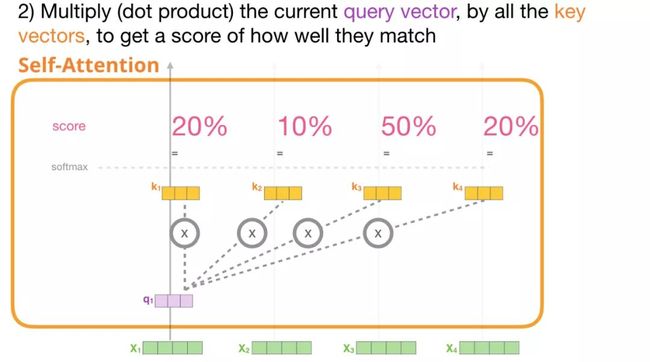
2.打分
现在我们得到了一些向量,在第二步中我们只使用query(查询向量)和 Value vectors(值向量)。我们不妨先看第一个token,我们将它的query(查询向量)和所有其他的key(键向量)相乘来得到四个tokens中每个token的分数。
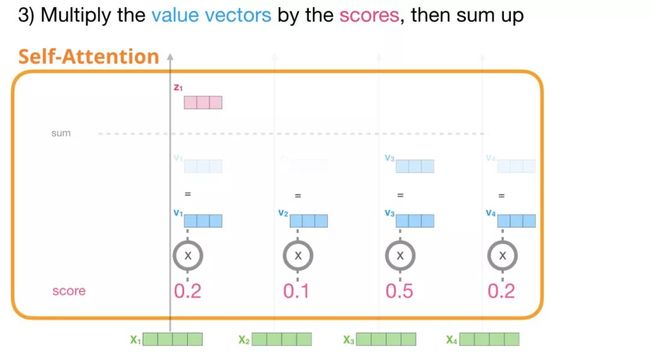
3.求和
我们现在可以将分数和value vector(值向量)相乘。在我们将其相加求和后,对应高分的value vector(值向量)将占所得向量的大部分。
分数越低,我们看到的value vector(值向量)就越透明。这是为了表明乘以一个小数会稀释vector的值。
如果我们对每条路径都做同样的操作,我们最终会得到一个向量来表示包含了适当的上下文的token。将它们传给transformer模块的下一个子层(前馈神经网络):
图解Masked Self-Attention
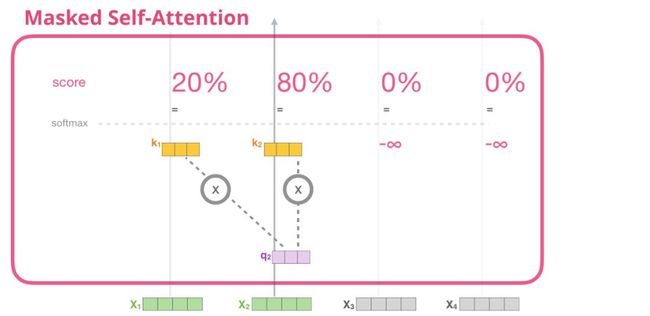
现在我们已经知道了transformer内部的self-attention机制的步骤,下面我们继续来看masked self-attention机制。Masked self-attention机制和self-attention机制除了步骤2之外基本相同。假设这个模型只有两个token作为输入,我们来观察第二个token。在这种情况下,后两个tokens被掩蔽了。因此该模型干涉了评分的步骤。它基本上总是将未来的token记为0,因此这个模型不会在未来的单词上达到峰值。
这种掩蔽通常用attention mask矩阵来实现考虑一个由四个单词组成的序列(例如“robot must obey orders”)。在语言的场景建模中,这个序列被分为四步,每步一个单词(假设现在每个单词都是一个token)。由于这些模型分批工作,我们可以假设一个批的规模是4,这些简易模型将整个序列(包含四个步骤)作为一个批处理。
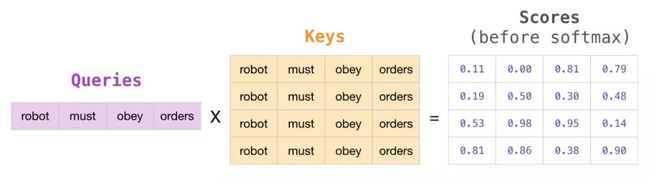
在矩阵形式中,我们将一个query(查询向量)矩阵和一个key(键向量)矩阵相乘来计算分数。我们下面来将其可视化,除单词外,还有与该单元格中该单词相关联的query(查询向量)(或key(键向量)):
在做乘法之后,我们将其转化为三角矩阵。将我们想要掩蔽的单元格设置成副无穷大或一个一个非常大的负数(例如在GPT2中我们设置成-1亿):
然后,对每一行使用softmax生成我们在self-attention机制中实际上使用的分数:
这个分数表的意思如下所述:
当模型处理数据集中的第一个实例时(图中的第一行),这里只包含一个单词(“robot”),100%的注意力都将集中在这个词上。
当模型处理数据集中的第二个实例时(图中的第二行),这里包含了(“robot must”),当模型处理单词“must”时,48%的注意力将集中在“robot”上,而另外52%的注意力将会集中在“must”上。
依次类推
GPT-2 Masked Self-Attention
让我们来详细了解一下GPT-2’s masked attention的更多细节。
评估时间:一次只处理一个token
我们可以让GPT-2机制完全像masked self-attention机制一样来运作。但在整个评估过程中,当我们的模型在每次迭代后只添加一个新单词的时候,沿着早期路径重新计算已经处理过的self-attention的token是效率极低的。
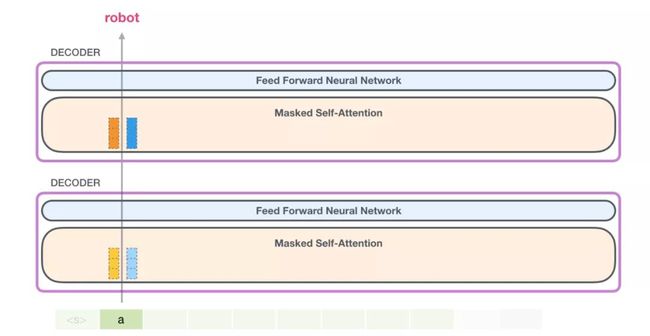
在这种情况下,我们处理第一个token(暂时忽略
)。
GPT-2保留a的key(键向量)和value vector(值向量)。每一个self-attention层都保留这个token的相应的key(键向量)和value vector(值向量):
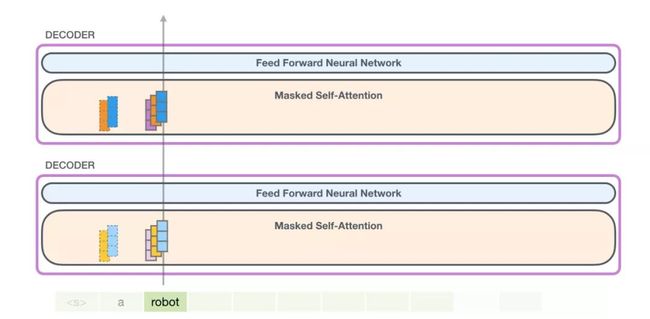
现在在下一次迭代中,当我们的模型处理单词robot时,它不需要再为token a 生成query(查询向量), key(键向量), 和 value(值向量)查询。它只需要复用它在第一次迭代中保存的那些:
我们假设模型正在处理单词it。如果我们讨论底层模块,那么它对该token的输入将是it的embedding加上插槽9处的位置encoding:
Transformer中的每一个模块都有它的权重(稍后在帖子中细分)。我们第一个遇到的就是我们用于创建queries(查询向量), key(键向量), 和 value vector(值向量)的权重矩阵。
Self-attention将它的输入和它的权重矩阵相乘(并且加一个偏置向量,这里不做说明)。
乘法计算产生的vector基本上是单词it的query(查询向量),key(键向量), 和 value vector(值向量)共同得到的结果。
Attention权重vector和输入vector相乘(并且在后面加上一个偏置向量)得到这个token的key(键向量), value vector(值向量), 和 query(查询向量)。
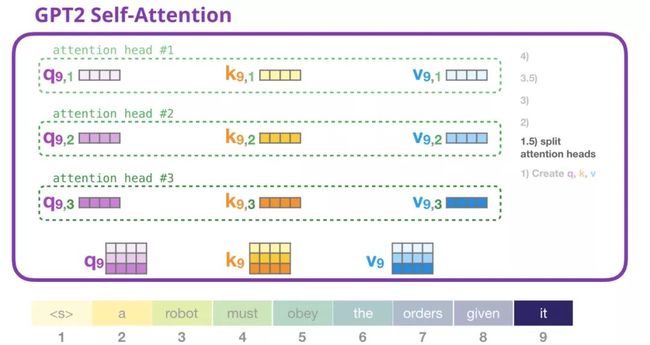
在前面的例子当中,我们直接进入self-attention而忽略了“multi-head”部分。现在对这部分概念有所了解将是大有用处的。Self attention机制在Q,K,V vectors的不同部分多次进行。“分裂” attention heads只是简单的将长向量重塑成为一个矩阵。小型的GPT2有12个attention heads,因此那将成为重塑后矩阵的第一维:
在前面的例子中,我们已经看到一个attention head中会发生什么。一个考虑多个attention-heads 的方法是像这样的(如果我们只想像12个attention heads中的3个):
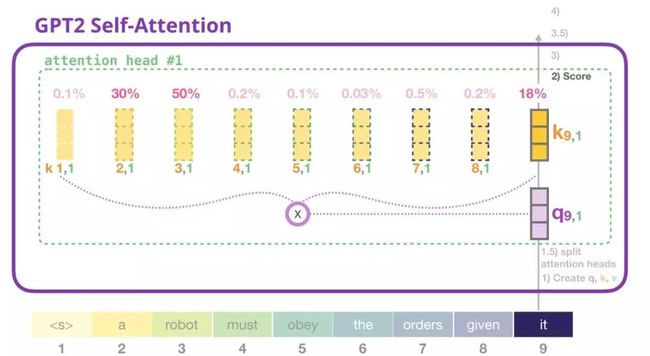
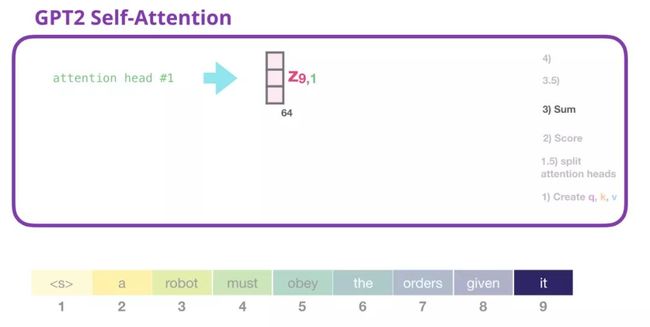
我们现在可以着手进行评分,在已知我们只关注一个attention head的情况下(并且其他所有的都进行类似的操作):
现在,token可以针对其他所有token进行评分(在先前迭代的attention head #1中计算的):
正如我们之前所看到的,我们现在将每个value乘以其得分,然后把它们加起来,产生的就是attention-head #1的self-attention结果。
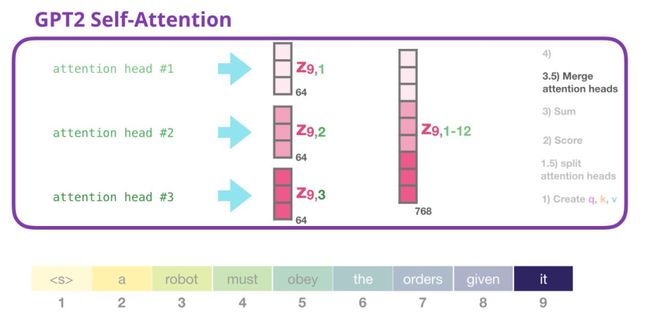
我们处理各种attention heads的方式是我们首先将它们连接成一个vector:
但是这个vector尚未准备好发送到下一个子层。我们需要首先将这个隐藏状态的弗兰肯斯坦怪物(人造的)变成一个同质的表示。
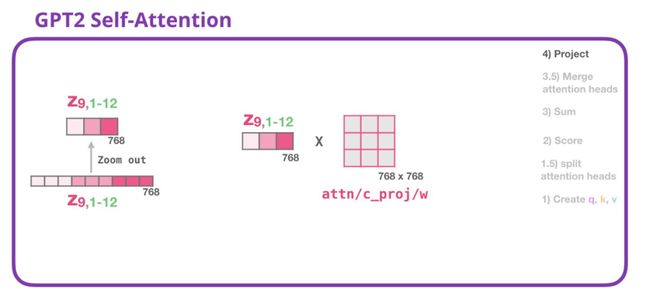
我们将让模型学习如何最好地将连接的self-attention结果映射到前馈神经网络可以处理的向量中。这是我们的第二个大权重矩阵,它将attention heads的结果映射到self-attention子层的输出向量中:
有了这个,我们就可以生成可以发送到下一层的向量。
全连接神经网络是该模块在self-attention在其表示中已经包含了适当的上下文后处理它的输入token的地方。它由两层组成。第一层是模型大小的4倍(当小型GPT2的规模为768,这个网络将有768*4=3072个单元)。为什么有四倍呢?这只是初始transformer运行的大小(模型维度是512,该模型的第一层是2048).这似乎为transformer模型提供了足够的表示能力来处理迄今为止面临的任务。
第二层将第一层的结果投影回模型维度(小型GPT2为768)。这个乘法的结果是这个token的transformer模块的结果。
你做到了!
这是我们将要进入的transformer模块的最详细的版本!你现在几乎拥有一个transformer语言模型内部发生的绝大部分图片。回顾一下,我们勇敢的输入向量遇到了这些权重矩阵:
每一个模块都有它自己的一组权重。另一方面,这个模型只有一个token embedding矩阵和一个位置encoding矩阵:
如果你想看看模型的全部参数,现在我把它们都罗列出来:
由于某些原因,它们总共增加了127M个参数而不是117M个。我不确定这是为什么,但是这是在发布的代码中它们看起来的数量(如果我错了,请联系我纠正)。
第三部分:语言建模番外
decoder-only transformer在语言模型之外不断获得超越。这里有很多成功的应用,可以通过类似视觉的效果来进行描述。让我们来看一些这里成功的应用结束这篇文章。
机器翻译
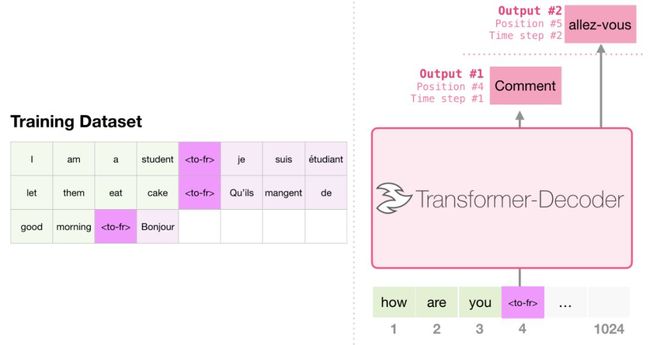
Encoder不需要进行翻译。同样的任务可以用decoder-only transformer来解决。
生成摘要
这是第一个decoder-only transformer被训练的来解决的任务。也即是说,它被训练来读维基百科的文章(去掉在目录之前的开头部分),然后生成摘要。文章的实际开头部分被用作训练集的标签。
本文针对维基百科的文章对模型进行了训练,因此训练后的模型可以用来生成文章的摘要。
迁移学习
在使用单个预训练transformer的样本高效文本摘要中,首先使用 decoder-only transformer对语言模型进行预训练,然后进行微调来生成摘要。事实证明,在有限的数据设置下,它比预训练的encoder-decoder transformer获得了更好的效果。
GPT2论文还显示了在对语言建模进行预训练之后的摘要结果。
音乐生成
音乐transformer使用decoder-only transformer来生成具有表现力和动态的音乐。“音乐模型”就像语言模型一样,就是让模型以无监督的方式来学习音乐,然后让它输出样本(我们此前称之为“漫游”)。
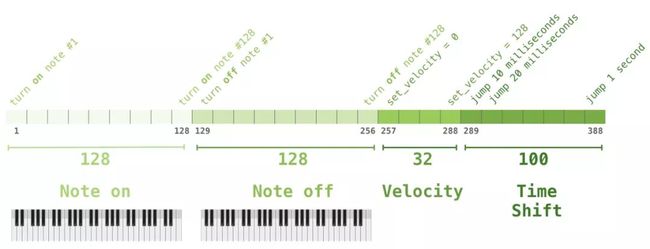
你可能会对在这种情况下如何表示音乐感到好奇。记着,语言模型可以通过将作为单词部分的字符或单词或token转化为向量表示来完成。通过音乐表演(让我们暂时先考虑钢琴),我们必须表示音符,但同时还要表示速度——衡量钢琴键按下的力度。
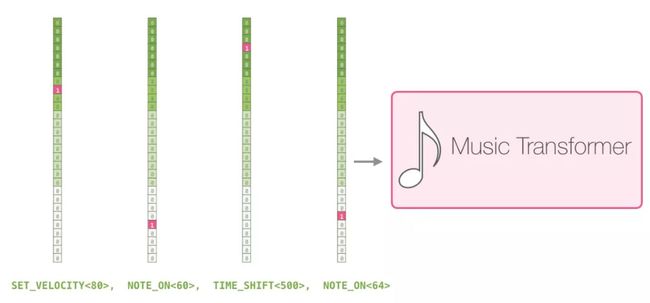
一首曲子只是这一系列one-hot vectors的载体。一个midi文件可以转换成为这种格式。本文有以下示例输入序列:
用one-hot vector表示这些输入序列可以看做下面这样:
我喜欢文章中的可视化,展示了音乐Transformer中的self-attention。我在这里添加了一些注释:
这件作品有一个重复出现的三角形轮廓。这个区域出现在后面的一个高峰,它关注的是之前所有高峰的高音,一直到乐曲的开头。图中显示了一个查询(所有注意线的来源)和正在处理的以前的记忆(接收到更多softmax probabiliy的注释被突出显示)。注意线的颜色对应不同的头部,宽度对应softmax概率的权重。
如果你不清楚这种音符表示,请查看这个视频
视频链接:
https://www.youtube.com/watch?v=ipzR9bhei_o
结论
这就结束了我们的GPT2以及对其父模型decoder-only transformer的探索之旅。我希望你能够更好的理解self-attention,你越是深入transformer越能更好的理解这一机制。
一些资源:
来自OpenAI的GPT2 Implementation:
https://github.com/openai/gpt-2
pytorch-transformers library:
https://github.com/huggingface/pytorch-transformers
原文链接:
https://jalammar.github.io/illustrated-gpt2/