LeNet5详解+Pytorch代码
从零开始学习深度学习,从较早的经典模型开始学习,希望能够坚持下去,写成一个系列。LeNet5网络既经典又重要,网上关于该模型的解释数不胜数,我也就不做重复的劳动了,直接给出个人认为比较好的介绍的链接,只对其中部分内容作简要介绍,算是自己的笔记,给自己看的。
论文地址:https://ieeexplore.ieee.org/document/726791
论文详解:https://www.datalearner.com/blog/1051558664111790
模型

输入: 32*32的灰度图像,每个像素的取值范围0-255。
C1层: 卷积层,6个5*5的卷积核,步长为1,得到6个28*28的图像;。
S2层: 下采样层,或者池化层,大小为2*2,平均池化,步长为2,得到6个14*14的图像。
C3层: 卷积层,16个大小为5*5的卷积核,步长为1,得到16个10*10的图像。
通常所说卷积核个数指的是后一层输出个数,但是每个卷积核中参数数量不仅是5*5,还与前一层连接数量有关。比如前一层有6张图片,经过16个卷积核,卷积核大小为5*5,输出16张图片,假设每个卷积核与前一层6张图片中每一张都进行运算,则每一个卷积核实际参数数量为:5*5*6,所有卷积核共有参数数量:5*5*6*16。
论文中,16个卷积核并不是和前一层6张图片的每一张都做卷积,而是只和前一层部分图片做卷积。其对应关系如下所是:
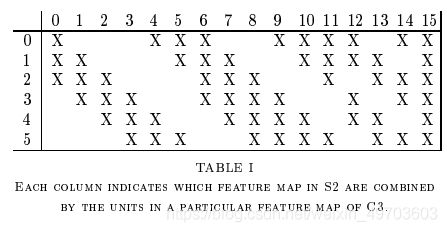
这样卷积核的参数就由2400个,减少到了1516个。
S4层: 下采样层,或池化层,池化大小为2*2,采用平均池化,步长为2,得到16个5*5的图像。
C5层: 卷积层,120个5*5的卷积核,得到120个神经元,至此没有图像。同理,卷积核的参数数量为:5*5*16*120。
C6层: 全连接层,输出为84个神经元。
C7层: 输出层,输出10个神经元,代表数字0-9,共10类。
Pytorch代码
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
# Hyper parameters
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = True
train_data = torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor(),
download=DOWNLOAD_MNIST
)
#
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2
)
test_data = torchvision.datasets.MNIST(
root='./mnist',
train=False
)
test_x = Variable(torch.unsqueeze(test_data.test_data,dim=1),volatile=True).type(torch.FloatTensor)[:2000]/255.
test_y = test_data.test_labels[:2000]
# CNN
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d( #(1*28*28)
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1, #步长
padding=2,
), #(16*28*28)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),#(16*14*14)
)
self.conv2 = nn.Sequential( # 16*14*14
nn.Conv2d(16,32,5,1,2), #32*14*14
nn.ReLU(),
nn.MaxPool2d(2) # 32*7*7
)
self.out = nn.Linear(32*7*7,10) #全连接
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x) #(batch,32,7,7)
x = x.view(x.size(0),-1) #(batch,32*7*7)
output = self.out(x)
return output
cnn = CNN()
# print(cnn)
optimizer = torch.optim.Adam(cnn.parameters(),lr=LR)
loss_func = nn.CrossEntropyLoss()
# training and testing
for epoch in range(EPOCH):
for step,(x,y) in enumerate(train_loader):
b_x = Variable(x)
b_y = Variable(y)
output = cnn(b_x)
loss = loss_func(output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = cnn(test_x)
pred_y = torch.max(test_output,1)[1].data.squeeze()
accuracy = sum(pred_y == test_y) / test_y.size(0)
print('Epoch: ',epoch,'| train loss: %4.f' %loss.item(),'| test accuracy: ',accuracy)
# print 10 predictions from test data
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output,1)[1].data.numpy().squeeze()
print(pred_y,'prediction number')
print(test_y[:10].numpy(),'real number')