线性回归模型_深度学习线性回归模型


线性回归模型主要包括模型部分(即线性关系)、数据集、损失函数、优化函数这几个基本要素。
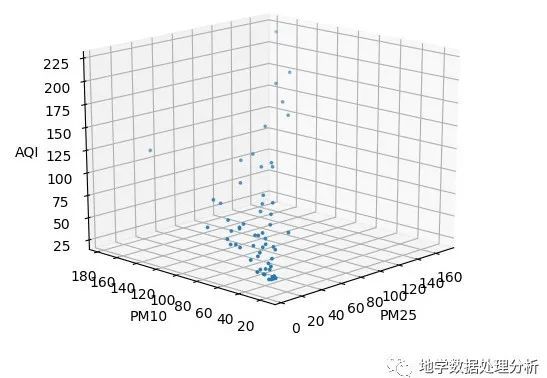
0 1模型根据我们所拥有的数据,假设AQI指数只取决于PM25, PM10, SO2, CO, NO2, O3这几个因素。线性回归假设输出与各个输入之间是线性关系,即:![]()
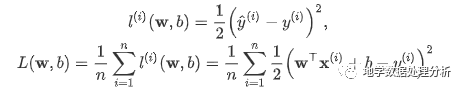
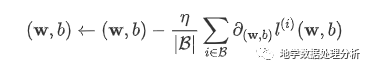
学习率: η代表在每次优化中,能够学习的步长的大小
批量大小: B是小批量计算中的批量大小(batch size)
总结一下,优化函数的有以下两个步骤:
(i)初始化模型参数,一般来说使用随机初始化;
(ii)在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
05实现import torchimport torch.utils.data as Datafrom torch import nnfrom torch.nn import initimport torch.optim as optimfrom matplotlib import pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport numpy as npimport pandas as pd# 初始化参数,一般是随机生成def init_parameters(num_inputs): w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32) b = torch.zeros(1, dtype=torch.float32) w.requires_grad_(requires_grad=True) b.requires_grad_(requires_grad=True) return w, b# 模型: 线性模型def model(X, w, b): return torch.mm(X, w) + b# 损失函数def squared_loss(y_hat, y): return (y_hat - y.view(y_hat.size())) ** 2 / 2# 优化函数-梯度下降def sgd(params, lr, batch_size): for param in params: param.data -= lr * param.grad / batch_size此处每个小批量有3个样本,并重复训练100次来迭代模型参数。
def main(): # super parameters init lr = 0.00005 # 学习的步长的大小 num_epochs = 100 # 训练重复次数 batch_size = 3 # 批量大小 features, labels = loadData("data.txt") # set input feature number num_inputs = features.shape[1] # set example number num_examples = features.shape[0] w, b = init_parameters(num_inputs) net = model loss = squared_loss # training for epoch in range(num_epochs): # # 训练重复次数 for X, y in read_data_batch(batch_size, features, labels): l = loss(net(X, w, b), y).sum() l.backward() # 后向传播计算梯度 sgd([w, b], lr, batch_size) # 小批量随机梯度下降更新模型参数 w.grad.data.zero_() # 梯度清零 b.grad.data.zero_() train_l = loss(net(features, w, b), labels) print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))# 当 lr = 0.00005, num_epochs = 100, batch_size = 5时...epoch 98, loss 32.237270epoch 99, loss 23.895002epoch 100, loss 23.717735W: [[0.7877328991889954], [0.3964788615703583], [-0.12595394253730774], [0.05453995242714882], [0.01380900852382183], [0.19781270623207092]]b: [0.04311537370085716]# 当 lr = 0.0002, num_epochs = 100, batch_size = 5时epoch 1, loss 740278.187500epoch 2, loss 173101648.000000epoch 3, loss 114911019008.000000epoch 4, loss 6522003259392.000000epoch 5, loss 608186748006039552.000000epoch 6, loss 38219160520935604224.000000epoch 7, loss 2773605162385879859200.000000epoch 8, loss 1774152400068472209408.000000![]()
说说线性规划
泰勒图的MATLAB实现
Python爬取高德地图--瓦片图
高斯混合模型判定交通拥堵状态
ArcPy批量定义投影和批量投影转换
机器人局部规划算法--DWA算法原理
数据分享GIMMS NDVI 3gv1(1982-2015)
ArcGIS时间滑块实现车辆轨迹动态展示
GPS数据处理---在野外采样寻点中的应用
![]()
![]()
