乐元素 X Hologres:一站式高性能游戏运营分析平台
客户介绍
乐元素创立于2009年,是一家以游戏研发运营为主营业务的游戏公司,同时业务涵盖动画作品、授权商品、音乐、演唱会、广播剧等在内的知名互动娱乐公司 。乐元素旗下拥有《开心水族箱》、《开心消消乐》、《海滨消消乐》 《Merc Storia》、《Ensemble Stars》 等多款畅销产品,以及《星梦手记》动画 和卡通形象品牌“消消乐萌萌团” 。其中,《开心消消乐》更是堪称国民级三消游戏。
面对多款DAU超千万的热门游戏产品,每天产生海量的游戏日志数据,如何通过数据运营获引起家对兴趣,提升游戏体验,降低用户流失成为决定游戏产品成败的关键。然而数据规模巨大、分析模式复杂,对游戏业务的运营分析数据产品形成了巨大的挑战。一方面手游产品迭代速度快、平均生命周期短,市场、运营需要快速的对玩家动态做出判断,这要求数据流转速度必须要快;另一方面,产品、用户、营销运营关注多数据面广,既需要通过宏观数据了解产品健康状况,有需要通过多种微观数据溯源问题原因,要求数据产品需要提供高灵活性的计算能力。
基于此背景,乐元素数仓团队升级技术架构,通过阿里云Hologres替换开源Hive+Presto架构,支持运营分析更加高效、实时,显著提升运营效率,进一步辅助业务精细化运营。
急需一个实时、灵活、可扩展的游戏数据分析平台
在乐元素手游类产品运营分析中更加重视玩家数据的多维数据上卷、下钻分析能力。例如,运营同学在发现用户流失严重的游戏关卡时,需要迅速通过调整关卡设置,增加游戏道具等方式,保持玩家对游戏的关注度。市场、产品运营分析的主要内容涵盖以下几方面:
- 用户相关部分:活跃用户/设备数、用户活跃度、关卡留存率、流失率及实时在线玩家等统计指标;
- 推广效果分析:如抽奖活动的点击率,参与率等分析评估对活跃度、用户转化的效果;
- 付费分析:付费用户结构、付费用户行为等;
在数仓构建方面,手游数据主体来源于各款游戏的埋点数据、离线用户标签特征、业务数据。游戏行业数仓有别于典型的电商、广告业务的数仓模型,游戏相关数仓模型构建以玩家行为事件数据为核心,特征维度数据为辅助,同时游戏之间玩家数据关联性较弱,游戏数据彼此正交,形成如下图所示的主要数仓结构:
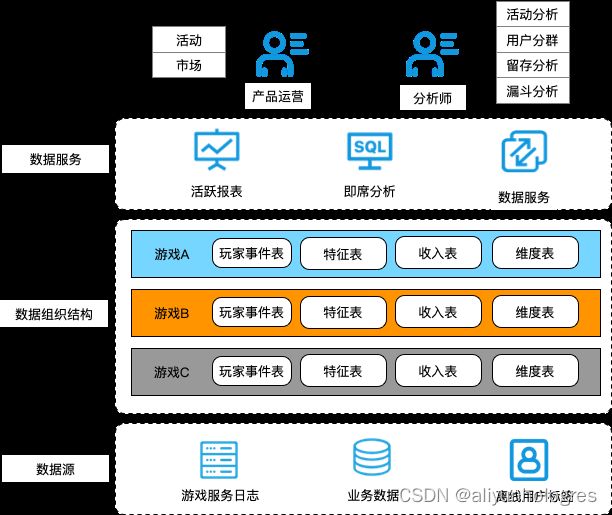
结合业务痛点,乐元素数仓研发、分析工具团队、运维团队需要为运营团队提供具有以下能力的自助分析平台:
- 高实时性:面对海量的日志数据,需要保障实施入库,数据产生即可用;
- 高灵活性:面对指标数据、多维分析等复杂场景,能提供即席计算能力和丰富的SQL生态支持;
- 高扩展性:产品、分析需求增长的同时能有效控制资源成本,集群规模扩充时能提供完善的监控和运维工具;
Hologres替换Hive+Presto助力实时数仓架构升级
数仓架构探索
游戏业务的数据层应用主要为产品运营、市场运营同学提供高效、灵活的即席查询能力,满足报表、分析等常规业务场景,同时在新品发布、活动推广等场景中,也需要第一时间提供用户的行为趋势,方便运营快速了解用户行为数据,而如果提供天级或者小时级的数据更新,往往不能满足业务实时性的要求。因此,在游戏业务的数据应用层中查询的灵活性、数据的实时性是核心诉求。
针对应用层特点,实时数仓探索的初期为了满足离线报表和实时查询的需求。系统架构的示意图如下:
- 我们使用自建的HDP集群作为数据存储底座,以提供离线ETL、数据报表等需求;
- 使用Presto读取HDP数据方式,为自助分析平台提供即席分析能力。
- 对于实时性要求高的活动统计、流量分析业务,埋点数据通过实时数据链路,将近N分钟数据写出到指定的HDFS文件上,然后在Hive中创建分区并关联到该文件上,满足查询实时数据需求;
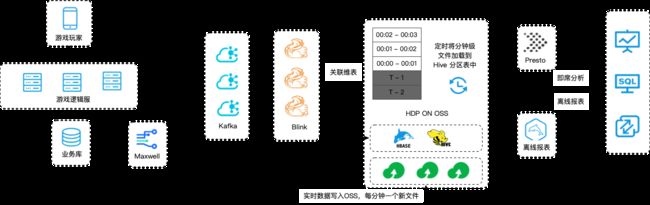
整个架构中,实时和离线采用两套链路:
- 实时数据流:游戏服务端日志、业务系统Binlog同步到Kafka,通过Flink关联维度进行实时ETL,持久化到OSS上每分钟创建的文件中;定时将分钟级文件通过新分区方式追加到Hive的事实表分区中,在计算端通过Presto查询Hive数据提供分钟级实时能力。
- 离线数据流:游戏服务日志、业务系统数据,离线同步至自建的HDP离线数仓,离线进行ETL用来提供历史数据分析能力;
上述架构与2019年投入生产,系统上线初期业务规模较小,运行相对稳定。但随着诸多爆款游戏的上线,数据规模迅速上涨,基于HDP的系统架构出现多次节点故障,问题排查时间较长,系统升级维护的成本很高;另一方面,计算、存储资源变得更加不匹配,系统的扩展性也面临一定挑战。总结来说,主要的问题有以下三点:
- 数据流转慢: 受限于实时链路实现方案,实时链路端到端的延迟在分钟级左右,流量高峰时段延迟会更长;
- 计算性能差: Presto引擎兼容性虽好,但性能远不如其他开源OLAP引擎,如ClickHouse、Hologres等;另一方面,实时数据链路架构文件数过多,对计算性能影响较大;
- 运维成本高:自建HDP版本较老,出现问题排查成本高,且Hortonworks被Cloudera收购之后,后续维护计划不明朗;集群规模不断扩大,出现链路故障恢复时间长,运维成本高;
- 开发成本高:需要定制开发一些模块来处理实时数据加载调度等功能,需要投入一些人力开发运维;同时链路较长,监控成本也比较高;
分析引擎选型
由于历史技术架构的种种问题,我们开始调研业界实时数仓的实践模型,希望引入一个全场景的OLAP引擎,来解决数据时效性、计算性能、成本三方面问题。在一段时间的摸索后,我们进行了ClickHouse、Presto、Hologres的多方面对比,Hologres相对于另外两个引擎优势较大,主要变现在以下几方面(性能数据为业务实际测试结果):
- 实时写入性能较强, 单Core可以支持2万~3万RPS的写入,并且与Flink可以无缝集成,能很好的满足实时数仓的需求;
- 在相同规模性资源下,对业务系统中计算量较大的UV统计、留存计算、漏斗计算等场景进行压测,性能项目Presto提升了5~10倍,96核的Presto集群完全可以使用64核的Holgores集群替换;
- Hologres的系统能力,如资源队列、慢Query监控、连接管理等,可以大大提升管理效率;
- Hologres原生内置游戏行业场景化的解决方案,如留存分析、人群画像等组件支持,对业务提效有很大帮助。
| OLAP 引擎 | 实时写入 | 计算性能 | 运维成本 | 业务开发成本 |
|---|---|---|---|---|
| Presto | 需要自建Kudu集群 | 中 | 中 | 较高 |
| ClickHouse | 弱 | 较高 | 高 | 较高 |
| Hologres | 强 | 高 | 免运维 | 较低 |
数仓架构升级
因此,我们最终决定使用Hologres替换现有基于Hive + Presto构建的实时数仓架构,整体系统架构演化为如下结构:
- 由Hologres作为统一的数据存储,存储Flink实时写入的数据以及离线加速的数据
- 通过Hologres对接数据应用层,提供统一对外的数据出口,满足运营的分析需求。
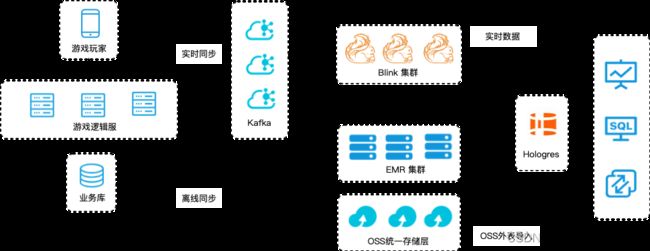
上述系统架构在2022年5月上线,对高频计算场景优化效果明显,即席分析平均耗时降低数倍。截止目前,《海滨消消乐》、《偶像梦幻季》等游戏已经完全迁移到Hologres架构。
- 依托Hologres数据加密的功能,我们也部署了海外机房,快速支持了海外业务扩展。总体来讲,对业务运营效率、研发迭代效率提升明显。
- 从系统指标层面看,初期使用128core的Hologres实例,可以承载离线数据高压力导入,导入RPS约400万+;实时数据承载了当时10k ~ 20k实时读写请求,单实例数据规模目前为15~10TB左右;高频计算场景如近7天留存、近30天漏斗等计算时长均缩短至10s以下,基数运算可以在毫秒级完成。
典型的游戏行为分析场景实践
以下,我们针对一些典型的场景介绍下Hologres上的业务落地方案。选择留存分析和漏斗分析作为示例进行介绍:
留存分析
留存分析是手游中统计用户参与度、活跃情况的一种重要的分析模型,通过留存分析可以了解手游用户的留存率,流失率情况,针对流失率用户群进行其他潜在维度的上卷统计,可以进一步探索用户流失原因。
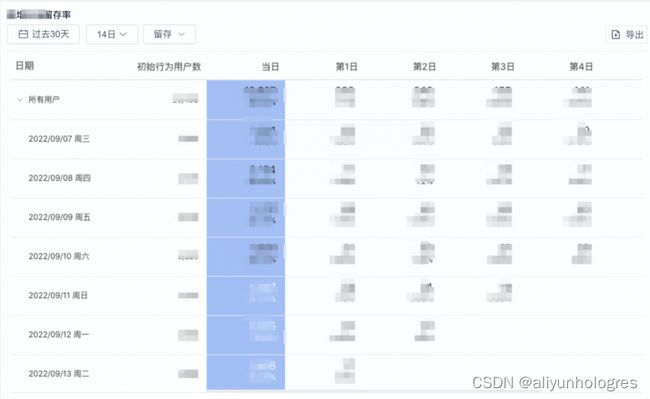
在留存分析中,我们针对玩家在一个时间段内的时间进行统计,指定一个初始事件和多个回访事件,通过统计玩家在指定时间段内的事件序列计算用户留存指标。初期基于Presto构建的自助分析平台,留存分析只能通过用户事件表的反复JOIN来计算, 而事件表本身数据规模非常大(百亿级别),JOIN运算开销非常大,对集群造成很大压力。
计算引擎替换成Hologres后,可以直接使用流量分析函数进行计算,函数通过对时间表的一次扫描完成留存计算,大大提升了计算效率,在典型的留存计算场景中,响应时间降低了一个数量级,同时,流量分析函数均支持延伸计算,分析师可以对对留存客群进一步分析。
例如,计算用户登录到用户进入游戏主场景的多日留存情况,并对每日的留存用户统计游戏分享次数的计算中;基于Presto我们需要通过通过Join来完成留存人群的过滤,再JOIN一次计算游戏分享事件次数;计算逻辑示例如下:
WITH init_events AS (
SELECT uid, ds AS init_date
FROM dwd_events
WHERE ds BETWEEN '2021-07-14' AND '2021-08-13' AND event_id = 'sdk_login'
GROUP BY 1,2
), -- 初始行为
return_events AS(
SELECT uid, ds AS retention_date
FROM dwd_events
WHERE ds BETWEEN '2021-07-14' AND '2021-08-20' AND event_id = 'app_lifecycle'
GROUP BY 1,2
), -- 回访行为
mertic_events AS (
SELECT uid, ds
FROM dwd_events
WHERE ds BETWEEN '2021-07-14' AND '2021-08-20' AND event_id = 'sdk_share'
) -- 统计维度
SELECT i.init_date,
COALESCE(COUNT(CASE WHEN r.retention_date - i.init_date = 1 THEN 1 ELSE NULL END), 0) retention__1,
COALESCE(COUNT(CASE WHEN r.retention_date - i.init_date = 3 THEN 1 ELSE NULL END), 0) retention__3,
COALESCE(COUNT(CASE WHEN r.retention_date - i.init_date = 3 THEN 1 ELSE NULL END), 0) retention__7
FROM init_events i -- JOIN 事件表,关联回访行为
JOIN (
SELECT r.*
FROM return_events r -- 关联统计维度
JOIN mertic_events m ON r.uid = m.uid AND r.retention_date = m.ds
) r ON i.uid = r.uid
GROUP BY i.init_date;
通过Hologres的留存函数进行延伸计算时,可以通过range_retention_count函数直接计算留存人群,该函数通过一次表扫描即可完成留存运算,效率非常高,运算逻辑示例如下:
WITH retention_detail AS (
SELECT uid,
to_timestamp((unnest(detail) >> 32) * 86400)::date AS init_date,
to_timestamp((unnest(detail) & 4294967295) * 86400)::date AS retention_date
FROM (
SELECT uid,
public.range_retention_count(
ds >= '2021-07-14' AND ds < '2021-08-13' AND event_id = 'sdk_login', -- 初始行为
ds >= '2021-07-14' AND ds < '2021-08-20' AND event_id = 'app_lifecycle', -- 回访行为
ds,
ARRAY[1, 3, 7], -- 计算1、3、7天的留存
'day',
'expand'
) AS detail
FROM dwd_events
WHERE ds >= '2021-07-14' AND ds < '2021-08-20'
GROUP BY uid
) r
)
SELECT r.init_date,
COUNT(CASE WHEN r.retention_date - r.init_date = 1 THEN 1 ELSE NULL END) AS retention_1,
COUNT(CASE WHEN r.retention_date - r.init_date = 3 THEN 1 ELSE NULL END) AS retention_3,
COUNT(CASE WHEN r.retention_date - r.init_date = 7 THEN 1 ELSE NULL END) AS retention_7
FROM retention_detail r
JOIN dwd_events m ON r.uid = m.uid AND r.retention_date = m.server_time::date -- 关联统计维度
GROUP BY r.init_date;
漏斗分析
在游戏玩家的转化率稳定阶段,漏斗分析可以应用于多个流量采渠道评估转化效果,同时对于新用户的转化过程,通过漏斗分析,可以找出转化过程中用户的流失环节,进行及时的查漏补缺。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-coHzWKhH-1668478626715)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/c5dad26e1722446a8951c64bc1eb1584~tplv-k3u1fbpfcp-zoom-1.image “乐5.png”)]
初期使用老架构的自助分析平台,需要针对性的开发UDF,用来完成漏斗分析计算。计算引擎升级成Hologres 后可以直接使用windowfunnel漏斗函数进行运算。同时Hologres内表可以通过clustering_key 指定数据排序字段、通过event_time_column可以实现数据分区内更细粒度的数据过滤,诸多特性都可以直接应用在windowfunnel的计算中。替换成Hologres引擎后,漏斗分析的性能也有5倍以上的提升。
升级数仓架构,业务运营效率提升10倍+
自助分析平台交互式分析引擎底座自2022年5月投入生产以来, 运营团队、产研团队对平台都给予了很高评价;从整体数据服务角度,使用Hologres进行技术升级带来诸多好处:
- 运营效率显著提升:在基础的用户分群、活动分析、用户留存、漏斗分析场景中,计算耗时都有数倍的提升;其中留存、漏斗计算性能提升近10倍。
- 平台稳定性提升:基于Hologres的引擎,完全可以承载高峰时期实时写入压力,相对历史架构有质的改善;同时,极大降低自建系统的运维成本,高峰时期系统的弹性扩缩容能力也能在分钟级完成,大大提升数据产品的稳定性、扩展性、可运维性,产研同学得以将更多精力,投入到数据研发方面;
- 成本节省:升级使用Hologres为分析引擎后,整体节约约50%机器成本,年节约成本数十万元;
未来的展望
- 目前在Hologres中行为类数据的存储仍然较高,计划通过Hologres后续发布冷热数据分层功能,将查询频次低、长周期的数据迁移到冷存储中;实现持续的降本增效;
- 目前离线数据仍然使用oss外表方式进行导入,手工运维的成本比较高;计划通过Hologres后续External Schema以及数据湖集成能力,降低手工运维成本。
了解Hologres:https://www.aliyun.com/product/bigdata/hologram