深度学习笔记
- 神经网络
- 二分分类
单神经网络:输入x,经过单个神经元进行线性运算得到输出y。
大的神经网络由多个不同的神经元堆叠而成。
喂给神经网络多个x,y的数据,神经网络会自己决定中间的节点是什么。(节点就是中间的小圆圈,神经元)
神经元:ReLu函数,修正性单元。修正表示取不小于0的值
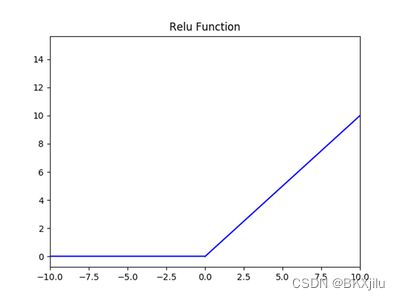
神经网络的强大之处在于你无需考虑它中间经历怎样的过程,只要输入x,就能得到y。
神经网络类型:
标准神经网络,卷积神经网络(CNN,主要用于图像识别),循环神经网络(RNN,主要处理非结构数据)
数据类型:
非结构数据与结构数据
结构数据是具有实际意义的比如像素值,房价。
非结构数据比如图像,音频,对计算机来说难以理解。我们可以提取非结构数据中的结构数据,比如计算机能理解图像的像素值,使计算机识别图像。
mei
import os
import json
import torch
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import transforms
from model_v3 import mobilenet_v3_large
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
def main():
if torch.cuda.is_available(): device = torch.device("cuda:0")
else: device = torch.device("cpu")#使用cuda或CPU运行
Image_Proc = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224), #前两步增强图像
transforms.ToTensor(), #(H,W,C)
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])
img_path = input('请输入图片路径:')
#显示图片的路径格式,在终端输入格式,第二种是img_path = "turtle.jpg",输入的图片必须放在操作的文件夹C:\Users\Baokexin\Desktop\寒假第二次培训-20220126\MobileNetV3
if not os.path.exists(img_path):
print("文件不存在")
exit()
img = Image.open(img_path)
plt.imshow(img)
img = Image_Proc(img)
#plt.show()
img = torch.unsqueeze(img, dim=0)
json_file = open("./class_indices.json")
classes_dict = json.load(json_file)
model = mobilenet_v3_large(num_classes=5).to(device)
weight_path = './MobileNetV3.pth'
model.load_state_dict(torch.load(weight_path, map_location=device))
model.eval()
with torch.no_grad(): #关闭梯度计算
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0) #将多个神经元的输出映射到(0,1)区间,并保证概率和为1
predict_class = torch.argmax(predict).numpy() #获取最大值的索引
predict_res = "class: {} prob: {:.3}".format(classes_dict[str(predict_class)], predict[predict_class])# 将
print(predict_res)
plt.title(predict_res)
plt.show()
return
if __name__ == '__main__':
while True:
main()#程序从这里入口
借用的这段代码表示:输入图片路径,即可判断图片的类型。
"0": "ACGN",
"1": "PangXie",
"2": "QingWa",
"3": "WuGui",
"4": "YingWu"
}2.二分分类
特征向量x:将图片中所有的像素值列出来.
二分分类问题的目标是训练出一个分类器。
以特征向量x作为输入,预测测试结果标签y是1还是0。
用一对(x,y)来表示一个单独的样本,其中x是nx维的特征向量,标签y为1或0。m个训练样本组成训练集。
训练集:(X(1),y(1)) ,(X(2),y(2)), (X(3),y(3))……(X(m),y(m)).
M=Mtrain强调训练样本的个数。
Mtest=#test表示测试集的样本数。
输入X={ X1, X2,…… Xm }用样本数为m,高度为nx的矩阵表示。用Python表示是有X.shape.(nx,m)
注:训练样本有时作为行向量堆叠而不是列向量堆叠。
标签Y={y1, y2,y3……ym],用Python表示为Y.shape等于(1,m).
sigmoid函数也叫 Logistic函数 ,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
代价函数:目的是为了训练参数w和b.
用numpy计算前向神经网络,loss,和反向传播。
for t in range(300):
y_predict = model(x)
loss=loss_function(y_predict,y)
print(t,loss.item())
plt.ion()
plt.show()
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.cla()
plt.scatter(x_np,y.data.numpy())
plt.plot(x_np,y_predict.data.numpy(),'r-',lw=5)
plt.pause(0.1)
不太理解的点:
手工组件是什么?

如图:增加训练集的大小,能提高算法的准确性,为什么第四条是对的
- 减小NN的大小通常不会影响算法的性能,这可能会有很大的帮助。
- 增加训练集的大小通常不会影响算法的性能,这可能会有很大的帮助。(正确)
- 减小训练集的大小通常不会影响算法的性能,这可能会有很大的帮助。
- 增加NN的大小通常不会影响算法的性能,这可能会有很大的帮助。(正确)
