pytorch安装与测试

PyTorch的飞速发展
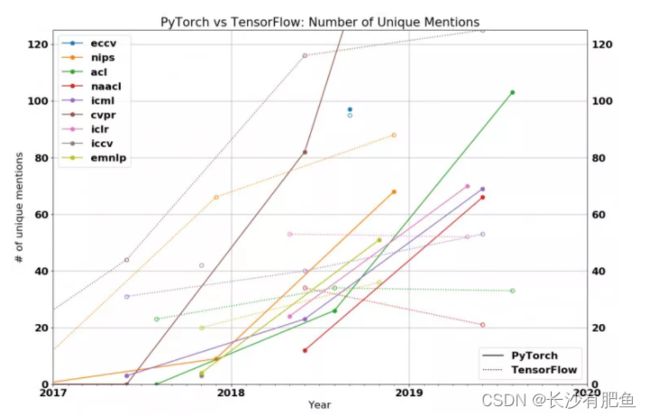
- 框架好不好用,看图说话!

安装PyTorch:使用PIP的方法比较简单
先查看你的cuda版本:
nvidia-smi 我的电脑cudaban版本是11.1的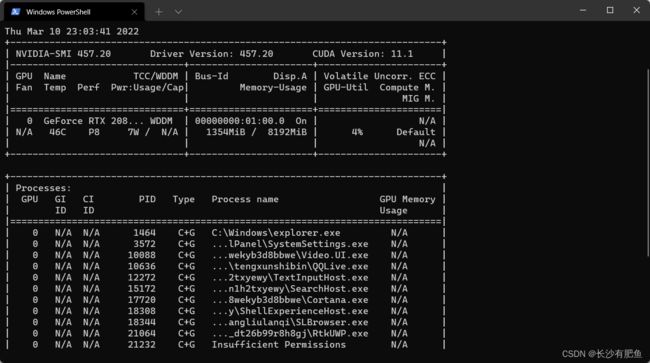
用下面的网址找到对应的cuda版本,然后复制命令行在miniconda或者Anaconda的环境里安装即可。
https://pytorch.org/get-started/previous-versions/ https://pytorch.org/get-started/previous-versions/
https://pytorch.org/get-started/previous-versions/
我的电脑安装命令就是:
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html安装完成后,打开jupyter notebook:
import torch torch.__version__'1.9.0+cu111'安装成功后会显示你安装的版本号
接下来用一个简单的小例子做GPU训练:
线性回归
构造一组输入数据X和其对应的标签y
import numpy as np x_values = [i for i in range(11)] x_train = np.array(x_values, dtype=np.float32) x_train = x_train.reshape(-1, 1) x_train.shape(11, 1)y_values = [2*i + 1 for i in x_values]#y=2x+1 y_train = np.array(y_values, dtype=np.float32) y_train = y_train.reshape(-1, 1)# reshape把数据转换成矩阵格式 y_train.shape
(11, 1)
import torch import torch.nn as nn
线性回归模型
- 其实线性回归就是一个不加激活函数的全连接层
class LinearRegressionModel(nn.Module): def __init__(self, input_dim, output_dim): super(LinearRegressionModel, self).__init__() self.linear = nn.Linear(input_dim, output_dim) def forward(self, x): out = self.linear(x) return outinput_dim = 1 output_dim = 1 model = LinearRegressionModel(input_dim, output_dim)modelLinearRegressionModel( (linear): Linear(in_features=1, out_features=1, bias=True) )指定好参数和损失函数
epochs = 1000 learning_rate = 0.01 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) criterion = nn.MSELoss()训练模型
for epoch in range(epochs): epoch += 1 # 注意转行成tensor inputs = torch.from_numpy(x_train) labels = torch.from_numpy(y_train) # 梯度要清零每一次迭代 optimizer.zero_grad() # 前向传播 outputs = model(inputs) # 计算损失 loss = criterion(outputs, labels) # 返向传播 loss.backward() # 更新权重参数 optimizer.step() if epoch % 50 == 0: print('epoch {}, loss {}'.format(epoch, loss.item()))epoch 50, loss 0.002772861160337925 epoch 100, loss 0.0015815184451639652 epoch 150, loss 0.0009020335855893791 epoch 200, loss 0.0005145024042576551 epoch 250, loss 0.0002934486838057637 epoch 300, loss 0.00016736680117901415 epoch 350, loss 9.546181536279619e-05 epoch 400, loss 5.444709677249193e-05 epoch 450, loss 3.105417636106722e-05 epoch 500, loss 1.771174902387429e-05 epoch 550, loss 1.0104487046191934e-05 epoch 600, loss 5.762907676398754e-06 epoch 650, loss 3.2866553283383837e-06 epoch 700, loss 1.8745893157756655e-06 epoch 750, loss 1.0692875775930588e-06 epoch 800, loss 6.096717015680042e-07 epoch 850, loss 3.4797531611729937e-07 epoch 900, loss 1.9841668574827054e-07 epoch 950, loss 1.1307743363886402e-07 epoch 1000, loss 6.446471445542556e-08测试模型预测结果
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy() predictedarray([[ 0.9995279], [ 2.9995959], [ 4.999664 ], [ 6.999732 ], [ 8.9998 ], [10.999867 ], [12.999936 ], [15.000004 ], [17.00007 ], [19.00014 ], [21.000206 ]], dtype=float32)模型的保存与读取
torch.save(model.state_dict(), 'model.pkl')model.load_state_dict(torch.load('model.pkl'))使用GPU进行训练
- 只需要把数据和模型传入到cuda里面就可以了
import torch import torch.nn as nn import numpy as np class LinearRegressionModel(nn.Module): def __init__(self, input_dim, output_dim): super(LinearRegressionModel, self).__init__() self.linear = nn.Linear(input_dim, output_dim) def forward(self, x): out = self.linear(x) return out input_dim = 1 output_dim = 1 model = LinearRegressionModel(input_dim, output_dim) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) criterion = nn.MSELoss() learning_rate = 0.01 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) epochs = 1000 for epoch in range(epochs): epoch += 1 inputs = torch.from_numpy(x_train).to(device) labels = torch.from_numpy(y_train).to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() if epoch % 50 == 0: print('epoch {}, loss {}'.format(epoch, loss.item()))epoch 50, loss 0.16363602876663208 epoch 100, loss 0.09333190321922302 epoch 150, loss 0.053232986479997635 epoch 200, loss 0.03036210499703884 epoch 250, loss 0.01731737330555916 epoch 300, loss 0.00987718254327774 epoch 350, loss 0.005633558612316847 epoch 400, loss 0.0032131734769791365 epoch 450, loss 0.0018326828721910715 epoch 500, loss 0.0010452885180711746 epoch 550, loss 0.0005961966817267239 epoch 600, loss 0.00034004641929641366 epoch 650, loss 0.0001939479261636734 epoch 700, loss 0.00011062397243222222 epoch 750, loss 6.309369928203523e-05 epoch 800, loss 3.5986384318675846e-05 epoch 850, loss 2.052540730801411e-05 epoch 900, loss 1.1706931218213867e-05 epoch 950, loss 6.677555120404577e-06 epoch 1000, loss 3.8078255784057546e-06