Python实现长短记忆神经网络(LSTM)预测经验模态分解(EMD)各模态变化的组合时间序列预测模型
本实验使用环境为Anaconda3 Jupyter,调用Sklearn包、Keras包,请提前准备好。只提供数据格式而不提供数据,本人是代码缝合怪小白,望大牛指点。
1.导包
主要包含pandas、numpy、绘图包、日期格式、数学计算、pyhht 、标准化、验证函数等包。有一些包可能没啥用…忘了什么时候导入的了。
import csv
import numpy as np
import time
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import explained_variance_score
from sklearn import metrics
from sklearn.svm import SVR
import matplotlib.pyplot as plt
from sklearn import metrics
from datetime import datetime
from pandas import Series
from pandas import concat
from pandas import read_csv
from pandas import DataFrame
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from math import sqrt
from matplotlib import pyplot
from pyhht.emd import EMD
from pyhht.visualization import plot_imfs
from sklearn.metrics import mean_absolute_error # 平方绝对误差
2.导入数据
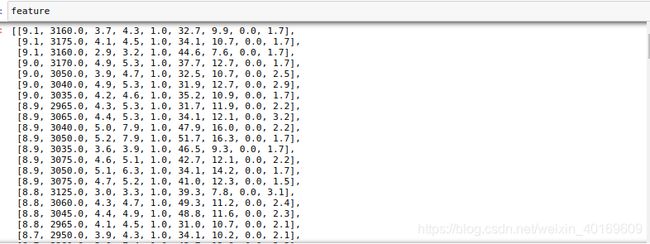
将准备好的CSV文件导入,将数据分为目标集和特征集。由于是时间序列预测,所以目标集和特征集需要需要反转,数据是某养殖场室内气体数据,共10天,10分钟1条,1584条。
#时间
time=[]
#特征
feature=[]
#目标
target=[]
csv_file = csv.reader(open('XXJYSJ.csv'))
for content in csv_file:
content=list(map(float,content))
if len(content)!=0:
feature.append(content[1:11])
target.append(content[0:1])
csv_file = csv.reader(open('XJYJSJ.csv'))
for content in csv_file:
content=list(map(str,content))
if len(content)!=0:
time.append(content)
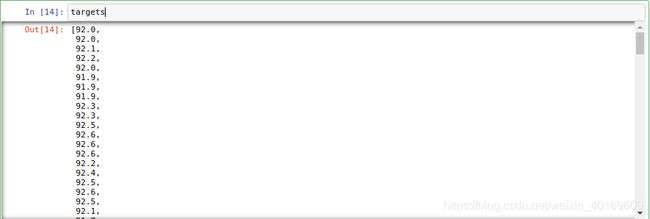
targets=[]
for i in target:
targets.append(i[0])
feature.reverse()
targets.reverse()
3.特征标准化
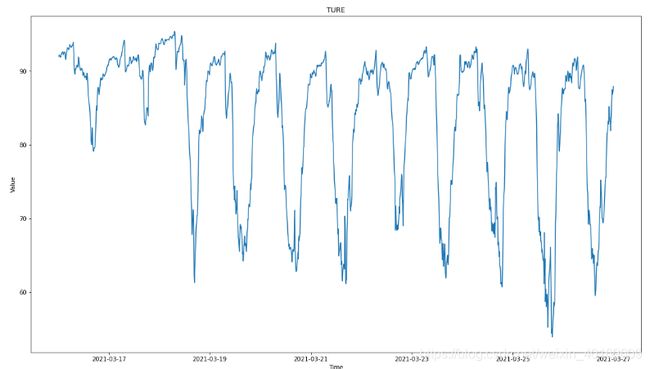
将特征数据标准化操作(本次实验没用到特征数据…),将时间数据倒转,展示目标数据。
feature= scaler.transform(feature)
#str转datetime
time_rel=[]
for i,j in enumerate(time):
time_rel.append(datetime.strptime(j[0],'%Y/%m/%d %H:%M'))
time_rel.reverse()
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title('TURE')
plt.plot(time_rel, targets)
plt.xlabel('Time')
plt.ylabel('Value')
这次数据还是不错的
4.使用经验模态分解(EMD)
使用EMD将目标信号分解成若干个模态+残差
nptargets=np.array(targets)
decomposer = EMD(nptargets)
imfs = decomposer.decompose()
#绘制分解图
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
plot_imfs(nptargets,imfs)
结果如下:
EMD将目标数据(信号)分解成了7个模态+1个剩余信号(Res)。
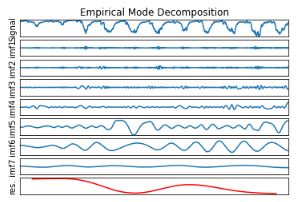
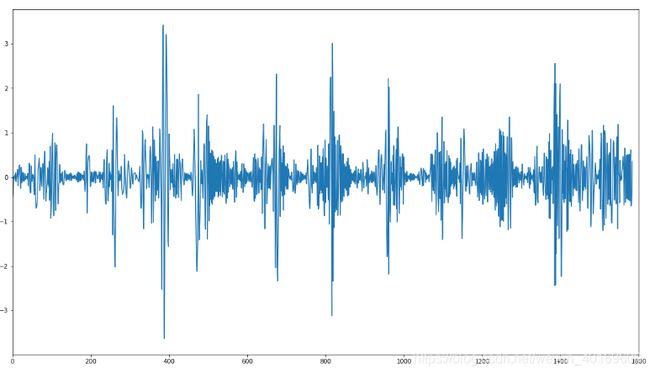
IMF1:
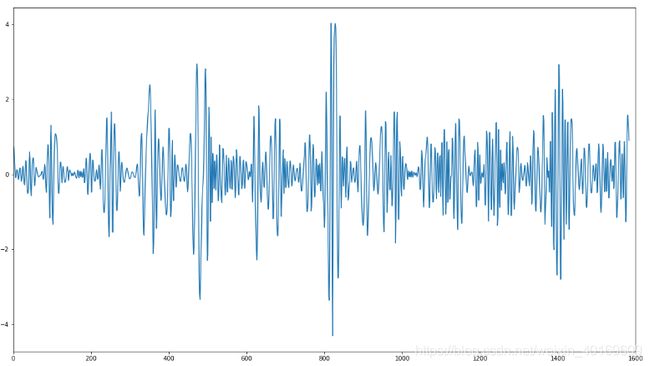
IMF2:
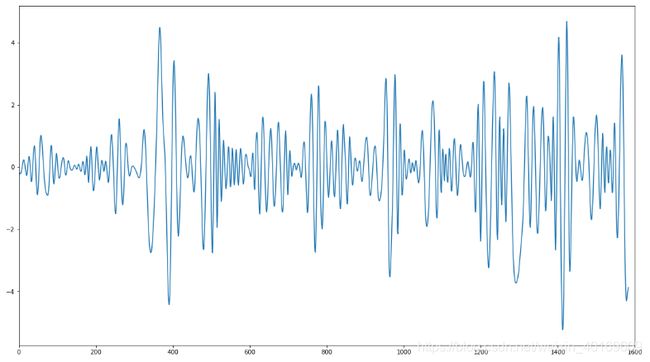
IMF3:
IMF4:
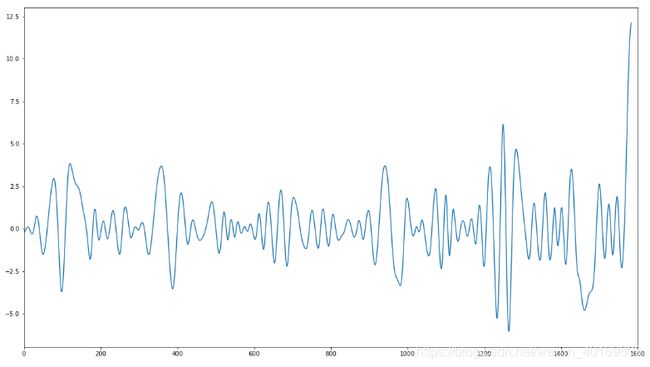
IMF5:
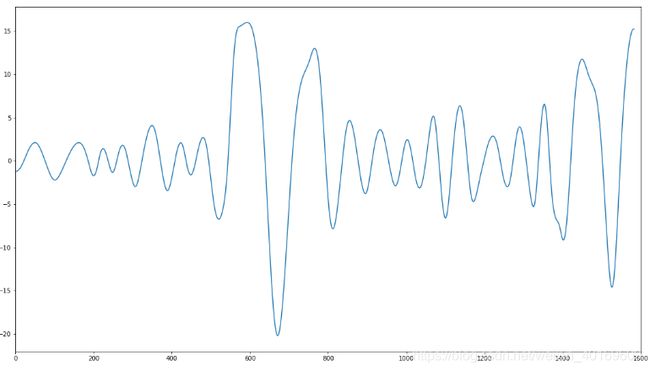
IMF6:
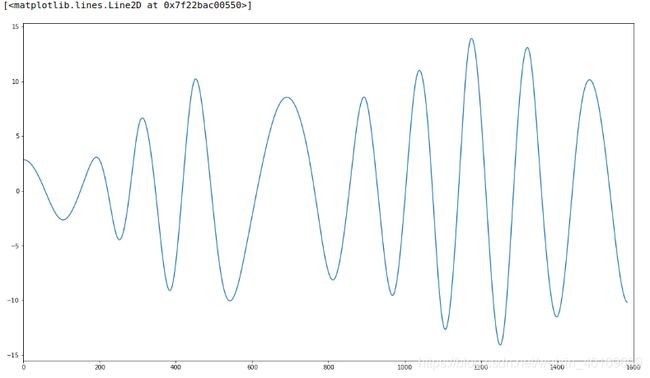
IMF7:
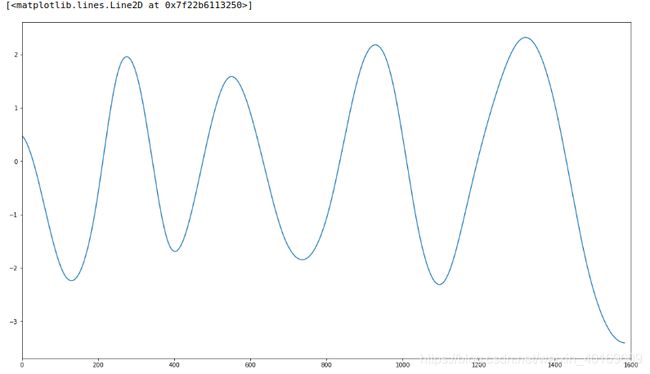
剩余信号Res:
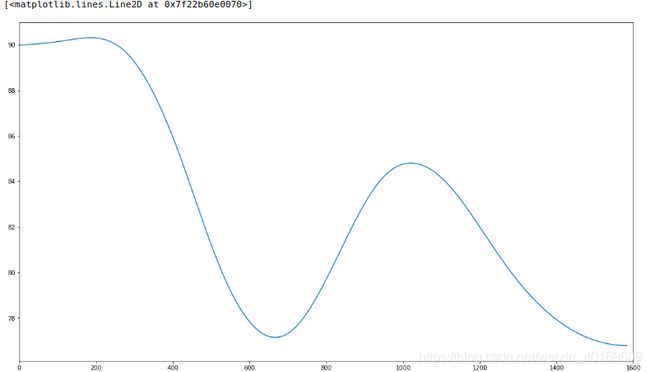
将上述全部值累加即可得到原值,可以看出分解效果不是很好,剩余信号太大了。
5.使用LSTM对原始数据进行预测
使用LSTM对整体目标数据进行预测,固定随机种子,防止每次预测结果不同。使用前90%做训练集,使用后10%作为验证集。单步预测,设置1维,两轮验证,四个神经元,可以自行调参。
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
预测预测!
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=targets[int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in targets:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d=[]
for j in predictions2d:
predictions1d.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d)
pyplot.legend(['True','R'])
pyplot.show()
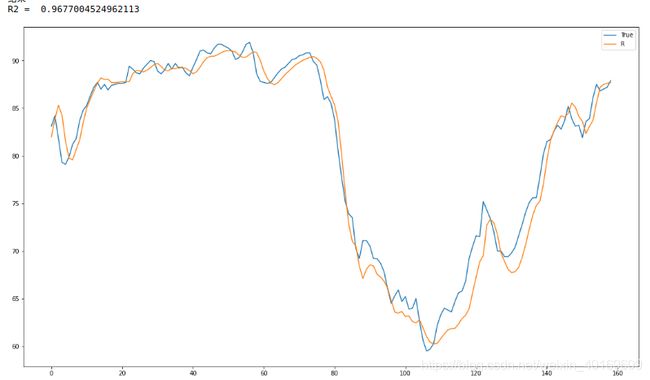
结果如下:
貌似还不错,记住了这个0.96
6.使用LSTM对全部EMD信号进行预测并累加验证
其实选好阈值后分组累加预测效果会更好一些,跑的次数也会更少,但是本实验是全都跑了一遍再累加验证。
IMF1:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[0][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[0]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d1=[]
for j in predictions2d:
predictions1d1.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d1)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d1)
pyplot.legend(['True','R'])
pyplot.show()
结果:
不知道为什么…
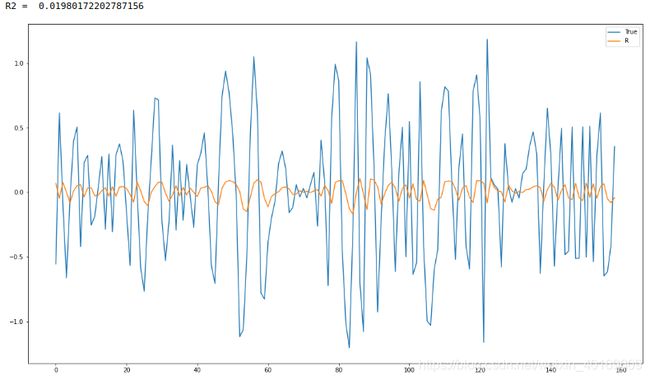
IMF2:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[1][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[1]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d2=[]
for j in predictions2d:
predictions1d2.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d2)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d2)
pyplot.legend(['True','R'])
pyplot.show()
结果:
稍微正常点?
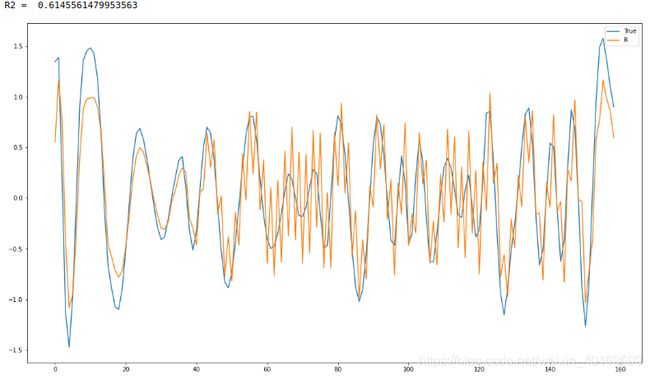
IMF3:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[2][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[2]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d3=[]
for j in predictions2d:
predictions1d3.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d3)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d3)
pyplot.legend(['True','R'])
pyplot.show()
结果:
强
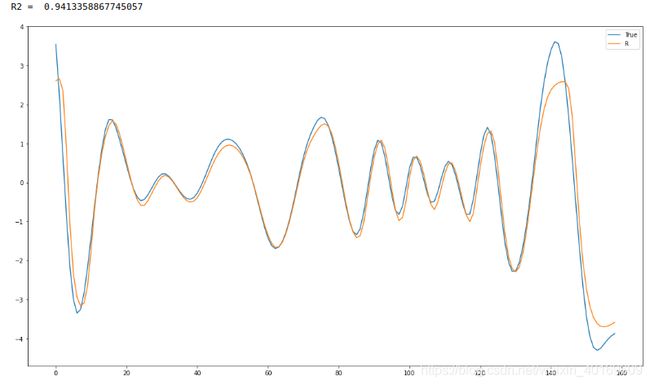
IMF4:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[3][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[3]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d4=[]
for j in predictions2d:
predictions1d4.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d4)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d4)
pyplot.legend(['True','R'])
pyplot.show()
结果:
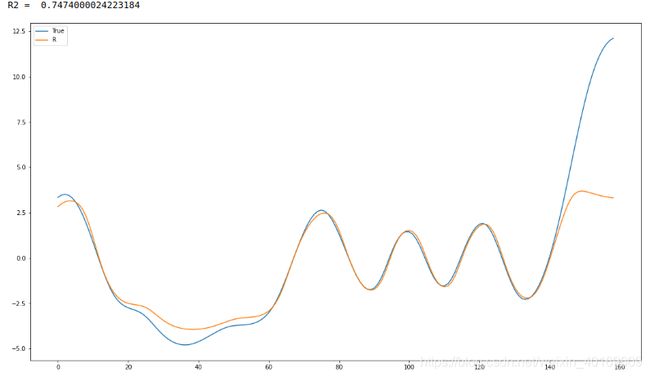
IMF5:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[4][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[4]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d5=[]
for j in predictions2d:
predictions1d5.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d5)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d5)
pyplot.legend(['True','R'])
pyplot.show()
结果:
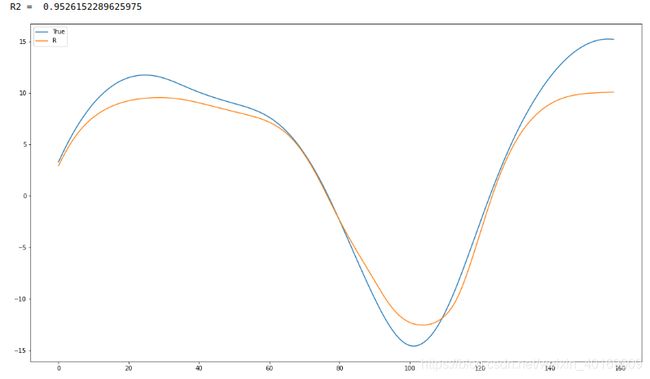
IMF6:
快扶我一把,我还能粘
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[5][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[5]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d6=[]
for j in predictions2d:
predictions1d6.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d6)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d6)
pyplot.legend(['True','R'])
pyplot.show()
结果:
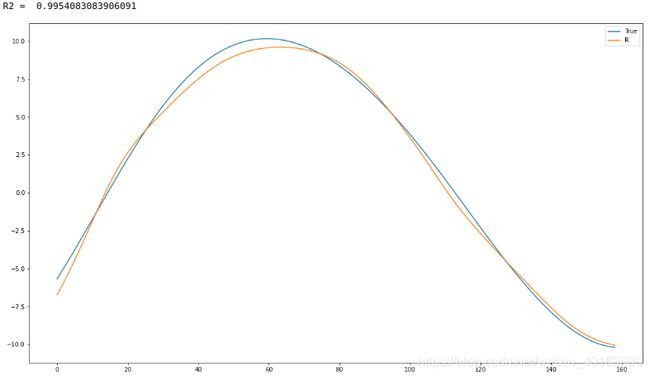
IMF7:
实验就是这么无聊,写博客记录更无聊
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[6][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[6]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d7=[]
for j in predictions2d:
predictions1d7.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d7)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d7)
pyplot.legend(['True','R'])
pyplot.show()
结果:
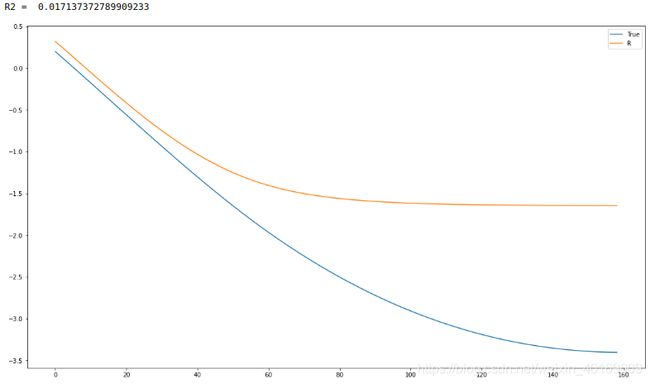 Res:
Res:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=imfs[7][int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in imfs[7]:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 2, 4)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d8=[]
for j in predictions2d:
predictions1d8.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d8)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d8)
pyplot.legend(['True','R'])
pyplot.show()
结果:
虽然很离谱,但是仔细看都是在±1左右波动
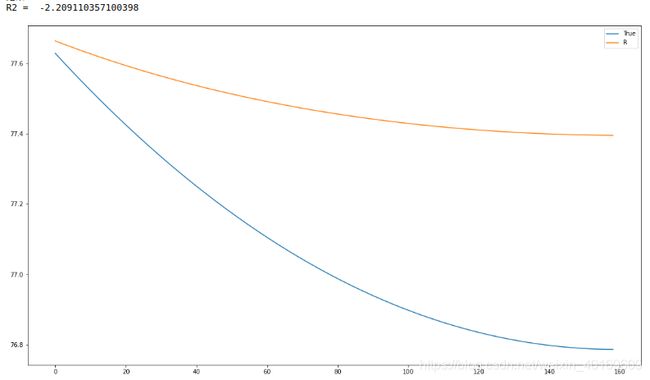
把八次预测结果加起来:
predictions1d1=np.array(predictions1d1)
predictions1d2=np.array(predictions1d2)
predictions1d3=np.array(predictions1d3)
predictions1d4=np.array(predictions1d4)
predictions1d5=np.array(predictions1d5)
predictions1d6=np.array(predictions1d6)
predictions1d7=np.array(predictions1d7)
predictions1d8=np.array(predictions1d8)
emdlstm=predictions1d1+predictions1d2+predictions1d3+predictions1d4+predictions1d5+predictions1d6+predictions1d7+predictions1d8
快送去预测!
testtest=targets[int(len(targets)*0.9):int(len(targets))]
EMDPSOLSTMRESULT=emdlstm
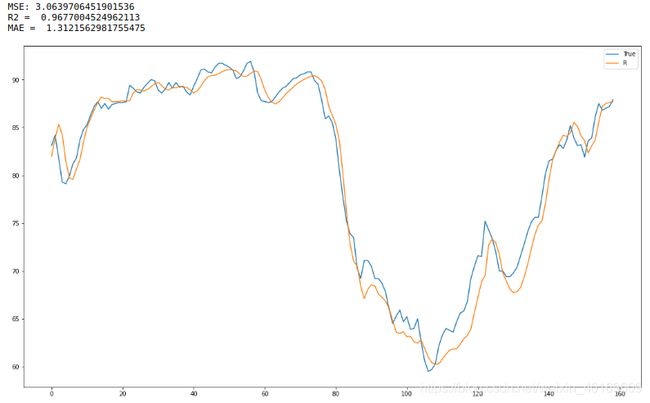
print("MSE:",mean_squared_error(testtest,emdlstm))
print("R2 = ",metrics.r2_score(testtest,emdlstm)) # R2
print("MAE = ",mean_absolute_error(testtest,emdlstm)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(testtest)
pyplot.plot(emdlstm)
pyplot.legend(['True','R1'])
pyplot.show()
结果:
好了,我凉了,就当给你们提供思路了。
我相信如果设置合理的阈值并分组,选择合适的数据集,精度一定会提高。
轻易不要像我这样把每一个模态都去预测再累加,否则就是花费大量时间,最后效果也不理想。
哎~~
EMD-LSTM:
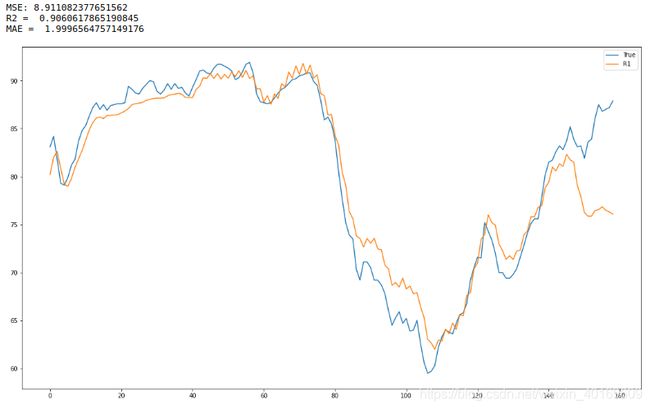
LSTM: