论文解读《Semi-supervised Contrastive Learning for Label-efficient Medical Image Segmentation》
论文解读《半监督对比学习高效标签的医学图像分割》
期刊名: MICCAI 2021
代码: 代码地址
论文地址: 论文地址
一、摘要:
1) 深度学习在医学图像分割中,依赖标注数据的监督训练。
2) 生物医学图像的注释需要该领域知识。
3) 对比学习学习数据(不带标签)有利于隐藏层特征提取。
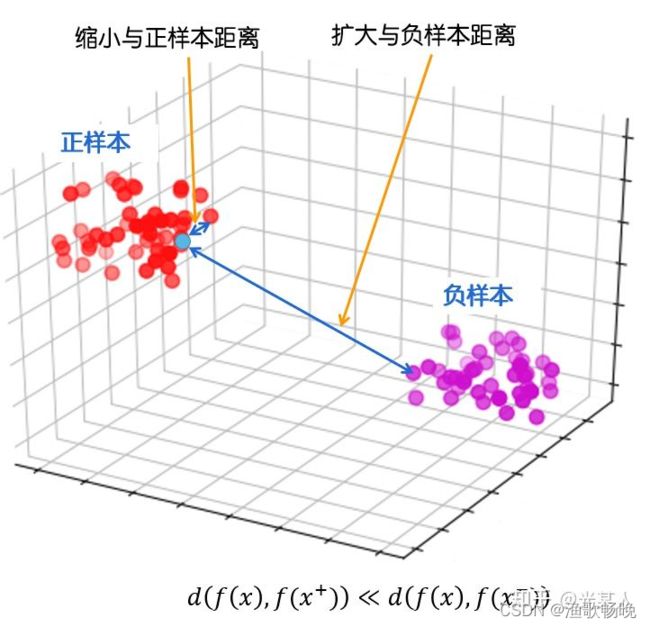
4) 预训练处理部分标签信息,监督局部对比损失,相同标签的像素聚集在 嵌入空间(embedding space) 周围。
5) 计算损失需要像素级的计算,下采样和块划分。
6) 评估两个公共生物医学图像数据集。提出方法始终优于最先进对比的方法和其他半监督学习技术。
二、介绍
2.1 标记医学图像需要特定领域的知识,像素级的注释很耗时。
生成对抗网络(GAN)进行数据扩展。但是,由于人工生成的图像和标签的缺陷,数据扩增只能对分割性能的提高起到有限的作用。
基于半监督学习的方法可以有效地利用标记数据和未标记数据。
2.2 现有的对比学习方法大多以图像分类为目标。另一方面,语义分割需要像素级的分类。首次尝试在只标记部分数据时使用对比学习来提高分割的准确性。
两步自监督对比学习,
1) 在预训练阶段从无标记数据中学习全局和局部特征。编码器路径将2D切片投影到潜在空间。编码器的基础上加入解码器块,中间特征映射进行局部对比学习。
2) 在微调阶段,预训练模型中监督对比学习使用部分标签数据训练。

2.3提出了一个由自监督的全局对比和监督的局部对比组成的半监督框架。
有监督局部对比能更好地增强同一类内特征之间的相似性,并能区分不具有监督局部对比的特征。
下采样和块分割 降低计算复杂度。两个不同模式的医学图像分割数据集评估。对于不同数量的标记数据,我们的框架总能产生比最先进的方法更高的分割结果。
对比学习介绍: 对比学习介绍1
对比学习介绍2

三、方法
3.1半监督框架概述

深度分割网络的结构骨干通常由编码器E和解码器d两部分组成。
编码器包括几个下采样块,用于从输入图像中提取特征;解码器包括多个上采样块,以恢复像素级预测的分辨率。
预训练阶段,1) 首先是一个自监督全局对比学习步骤,只使用无标签数据训练编码器E和捕获图像特征,
2) 是一个监督局部对比学习步骤使用部分标签数据进一步训练编码器E、解码器D和获取进行像素级特征。
给定一个输入批量数据B = {x1, x2,…, xb},其中xi表示一个输入2D切片,对B中的每幅图像随机进行两次图像变换组合,形成一对增广图像,与现有的对比学习方法相同。这些增广图像构成一个增广图像集A。设ai, i∈I={1…2b}表示A中的一个增广图像,设j(i)为A中另一个图像的索引,该图像由B中ai的同一张图像衍生而来,即 ai和aj(i)是一个增广对。
全局对比损失则表现为以下形式:

其中,zi是归一化的输出特征,在编码E中增加了head h1。head通常是一个多层感知器,增强了从E中提取特征的表示能力。τ是温度常数。
1) 全局对比学习后,将解码器D附加到编码器上,
2) 监督局部对比损失对整个网络进行再训练。
3.2 监督局部对比学习
对于特征图 f(ai),局部对比损失定义为
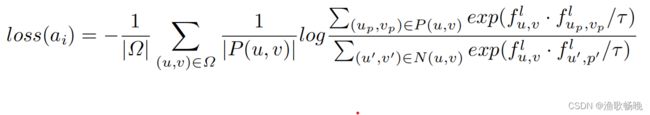
在没有标注信息的情况下,P(u, v)只包含在成对图像的特征映射上来自同一位置的点,即fu,v(aj(i)),负集为A中所有图像减去正集的并集。
 ,
,
其中c为通道号并表示特征图的第uth列和vth行特征。Ω是fu,v中用来计算损失的点的集合。P(u, v)和N(u, v)分别表示fu,v(ai)的正集和负集。
所有的局部对比损失为

1) 通常对比学习应用于图像分类任务时,提高准确率最大的数据增强是空间变换,如裁剪和切割。
2) 自监督,数据增强只能包含颜色畸变、高斯噪声、高斯模糊等强度变换。
这是因为经过空间变换后,f(ai)和f(aj(i))在同一位置的特征可以来自不同的点或区域,但在计算局部对比损失时仍将空间变换的数据视为与之前相似的数据。
3) 在没有任何监督的情况下,提取所有图像中的点可能都对应于背景区域,在这种情况下,模型不能有效地学习局部特征。
4) 数据集包含部分标签数据,于是监督局部对比学习在预训练阶段使用它。
5) 监督对比损失提供了来自同一类的特征的相似度和类间特征的不相似度的关键信息。
3.3 下采样和块划分
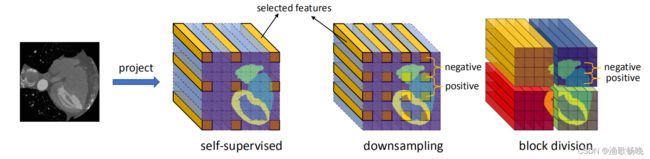
图2:三种从特征图中选择特征用于局部对比学习的策略。
左:自监督 中间:下采样,用固定步幅(fixed stride)分离特征,计算对比损失;右:块划分,在每个块中计算对比损失,然后取平均值。
分割标注时,特征图的大小与输入图像相同。考虑不属于背景的点,但 |p (u, v)|(正集) 计算复杂度仍然很大,输入图像维数 h x h。
例如“MMWHS”中的图像大小为“512×512”。将切片重塑为160×160,负集的大小大约是10 ^ 4,计算损失所需的总乘法大约是10 ^ 8。
1)下采样
为了解决这个问题,提出了两种策略来减少负集的大小,如图2所示。第一种方法是对 特征图进行固定步幅下采样( downsample the feature map with fixed stride) 。该方法的思想是邻近像素包含冗余信息,它们的嵌入特征在潜在空间中看起来非常相似。随着步数s的增加,P(u, v)的大小和损失函数的计算复杂度分别降低了s ^ 2和s ^ 4的1 / 4。由于步幅越大,负对的数量就越少,而负对的数量对于对比学习是非常重要的。在本工作中,将步幅设置为4,不会导致内存不足问题的最小值。
2) 块切分
图2所示。局部对比损失只在每个块内计算,然后在所有块之间平均。如果一个块中的所有像素都被标记为背景,将不计算其局部对比度损失。 P(u, v)的大小减小为块O(h’2)的特征个数,总计算复杂度为O((h/h’) ^2·h’ ^4) = O(h2h’2)。更小的块大小也会导致更少的负集对。因此,块的大小也应该根据训练时间/内存 (training time/memory ) 来确定。在本文中,我们将其设置为16X16,这是不会引起内存溢出。
四 实验与结果
4.1数据集和预处理
我们评估了我们的方法在两个公共医学图像分割数据集的不同模式,MRI和CT。
(1) Hippocampus数据集来自MICCAI 2018医学分段十项全能挑战赛。260个单模态MRI三维扫描体,具有前、后海马体的标注。
(2) MMWHS来自MICCAI 2017挑战赛,包含20个3D心脏CT容积。该标注包括心脏的7个结构:左心室、左心房、右心室、右心房、心肌、升主动脉、肺动脉。在预处理方面,我们将整个体积的强度归一化。然后我们调整同一数据集中所有卷的切片大小,使用双线性插值将它们统一起来。两个重塑数据集的分辨率分别为海马(64X64)和MMWHS(160X160)。
4.2实验设置
选择的分割网络骨干网是2D U-Net,编码器和解码器有三个部分组成,实现基于PyTorch库。
对于这两个集合,我们将数据分为三个部分,训练集Xtr,验证集xl和测试集Xts。
Hippocampus的|Xtr|: |Xvl|: |Xts|的比例为3:1:1,MMWHS的比例为2:1:1。
在Xtr中随机选取一定数量的样本作为标记数据,其余的视为未标记数据。我们将数据集分割了4次以生成4个不同的数据集合,并使用
Xts(测试集) 上的**平均DICE分数(the average dice score)**作为比较的指标。
我们选择Adam作为对比学习和接下来的分割训练的优化器。对比学习的学习率为0.0001,分割训练的学习率为0.00001。
对比学习(contrastive learning) 的训练步数为70,分割训练(segmentation training) 的训练步数为120。
实现了四种不同方法:
1) 全局对比学习和使用基于下采样(global+local(stride)) 的监督局部对比学习
2) 全局对比学习和块划分(global+local(block))的监督局部对比学习;
3) 使用基于下采样(local(stride)) 的监督局部对比学习
4) 使用块划分(local(block))的监督局部对比学习;
还为了比较,我们实现了 两种最新对比学习方法 :
5) 全局对比学习方法(global)
6) 自监督全局及局部对比学习方法(global + local(self))。
进一步实现了三种方法: 7) 随机初始化从头开始训练(random)、8) 基于数据增强的方法Mixup 和 9) 最先进的半监督学习方法TCSM。
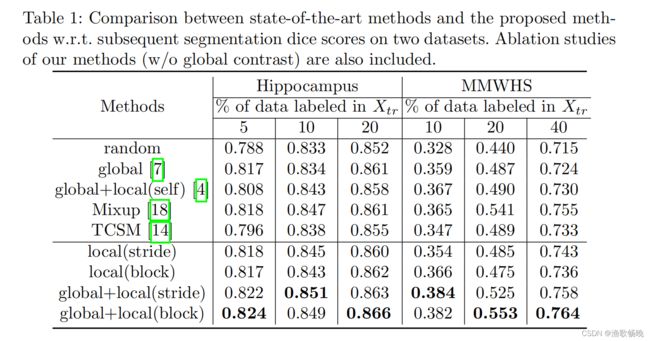
表1列出了所有方法的平均DICE分数。首先,与随机(random)方法相比,所有对比学习方法都能获得更高的DICE分数,这意味着当标签有限时,对比学习是一个可行的初始化方法。
最后,作者的方法、最先进的(global+local(self)[4])和随机方法在带有40%标记数据的MMWHS上的分割结果如图3所示。从图中可以清楚地看到,作者的方法表现最好。
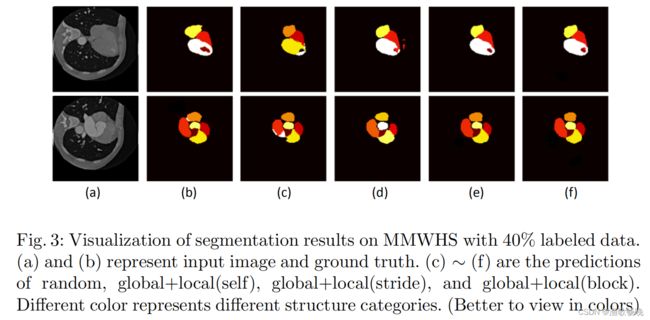
图3: 有40%标记数据的MMWHS上分割结果的可视化。(a)和(b)表示输入图像和ground truth。©、(d)、(e)、 (f)是random、global+local(self)、global+local(stride)、global+local(block)的预测。不同的颜色代表不同的结构类别。

图4: 对有40%标记数据的MMWHS应用t-SNE后嵌入特征的可视化。不同的颜色代表不同的阶层。这些特征都来自于最后一次逐点卷积前的特征图。
t-SNE :非线性的降维算法,为了将高维度的数据压缩到二维数据证明算法的有效性。
五、结论
1) 有限的标注一直是深度学习医学图像分割方法发展的障碍。针对这一挑战,提出了一种 监督局部对比损失 来学习像素级的表示。
2) 在此基础上,提出了 两种降低损失计算复杂度 的策略 (下采样和块切分)。
3) 在两个只有部分标签的医学图像数据集上实验表明,监督局部对比度与全局对比度相结合, 半监督对比学习在最先进的图像分割性能上得到了显著改善。