基于使用MindStudio完成Rosetta_Resnet34_vd模型开发
目录
一、介绍... 2
1.1 模型介绍... 2
1.2 MindStudio介绍... 2
1.3 MindStudio配置... 3
二、MindStudio项目搭建... 5
2.1 项目创建... 5
2.2 项目配置... 9
三、获取模型代码... 13
3.1 获取源码... 13
3.2 安装依赖... 14
四、获取数据集... 16
4.1 数据集下载... 16
4.2 数据集预处理... 17
五、模型转换... 18
5.1 转onnx模型... 18
5.2 转om模型... 21
六、模型推理... 25
6.1 获取推理工具... 25
6.2 进行推理... 26
6.3 精度验证... 27
七、问题总结... 29
八、参考资料... 30
一、介绍
本文将介绍使用MindStudio进行Rosetta_Resnet34_vd模型离线推理开发,并在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,推理精度能够达到80.64%。
1.1 模型介绍
Rosetta是用于图像中文本检测和识别的大规模系统,文本识别是使用称为 CTC 的全卷积模型完成的(因为它在训练期间使用序列到序列的 CTC 损失),该模型输出字符序列。最后一个卷积层在输入词的每个图像位置预测最可能的字符。论文链接为:
https://arxiv.org/abs/1910.05085
Rosetta_Resnet34_vd是基于是PadlePaddle框架的实现,相关信息可参考官网说明:
PaddleOCR/algorithm_rec_rosetta.md at release/2.6 · PaddlePaddle/PaddleOCR · GitHub
1.2 MindStudio介绍
MindStudio提供了AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务,依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。
本文主要介绍使用MindStudio进行Rosetta_Resnet34_vd模型离线推理开发过程。
关于MindStudio的详细特性,可以通过官网查看:
昇腾社区-官网丨昇腾万里 让智能无所不及
可以通过MindStudio社区,获得帮助以及进行经验分享和交流,另外还可以参与MindStudio官方举办的各种活动:
华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云
本文参考了《使用MindStudio进行Mindx模型st-gcn开发(1)》这篇社区帖子来进行MindStudio的环境搭建,链接为:
华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云
MindStudio的安装过程可以参考官方指导手册,链接为:
昇腾社区-官网丨昇腾万里 让智能无所不及
1.3 MindStudio配置
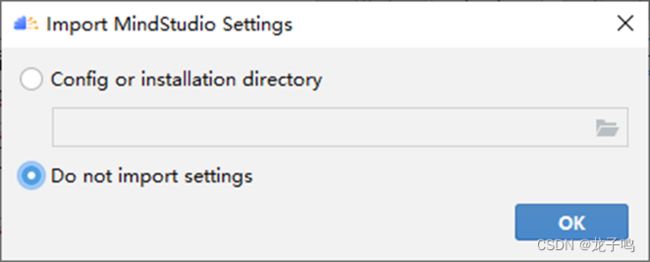
初次打开MindStudio会提示是否导入配置,如上图,可以选择“Do not import settings”,点击“OK”。
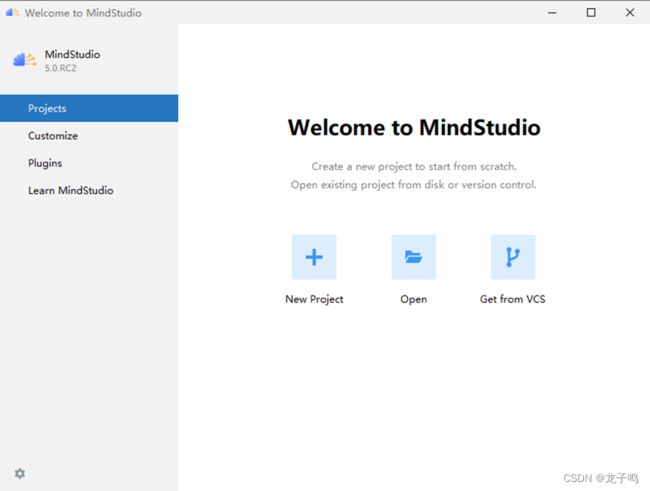
上图为MindStudio的主界面,主要包括4个标签:
Projects:用于项目的创建、打开等功能。
Customize:主要是用户喜好设置等功能。
Plugins:主要用于插件的安装、卸载等。
Learn MindStudio:提供获取帮助的途径。
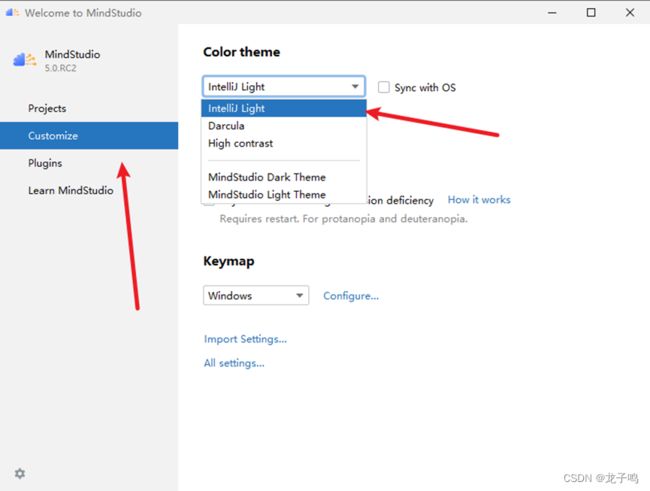
通过Customize标签将主题设置为“IntelliJ Light”,如上图所示。
二、MindStudio项目搭建
2.1 项目创建
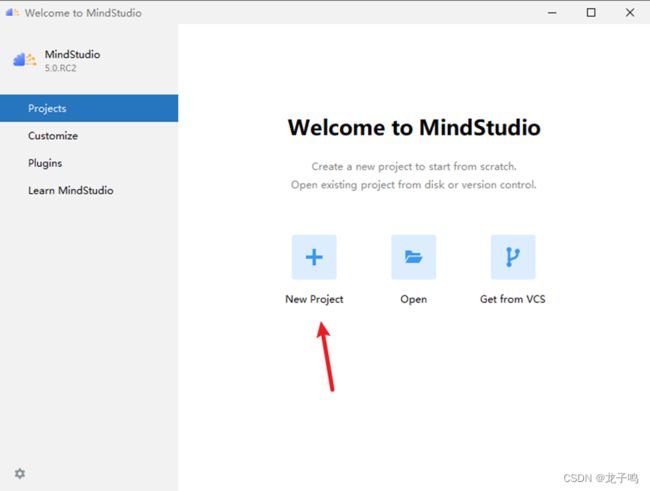
在主界面Projects标签中点击“New Project”,如上图。
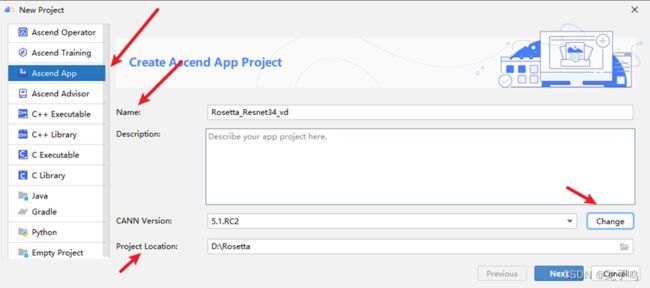
选择“Ascend App”标签,设置项目名称和项目路径,点击CANN Version选项的“Change”。
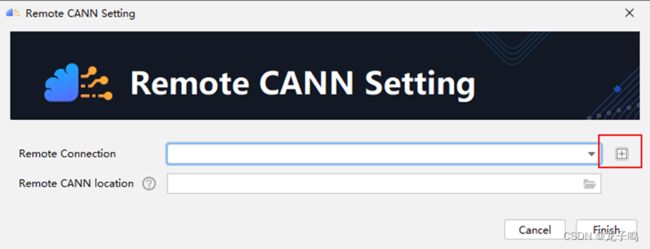
在CANN配置对话框中点击+号。
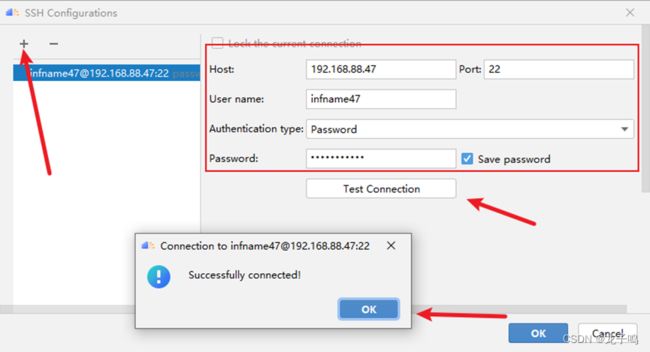
在弹出的配置对话框中点击+号,填写远程服务器信息,点击“Test Connection”测试连接是否正常,弹出“Successfully connected”说明连接正常,如上图,依次点击“OK”完成配置。
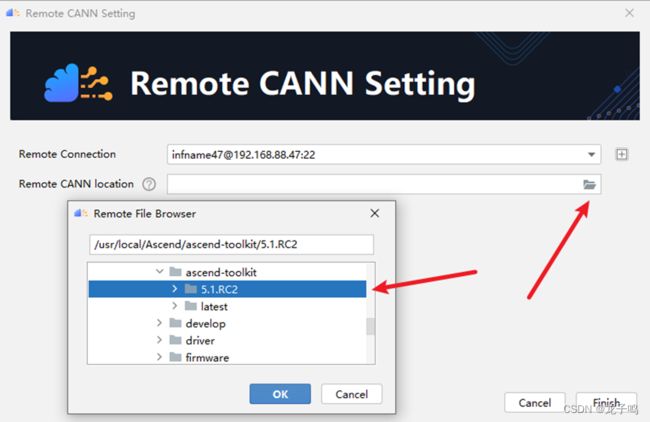
点击文件夹图标,选择远程CANN包安装目录,点击“OK”。
点击Finish开始同步远程CANN环境。
同步完成后点击“Next”进入下一步。
选择“ACL Project(Python)”,点击“Finish”。
此时创建好了一个空的项目,这时会弹出提示对话框,可以点击“Next Tip”查看提示信息,点击“Close”关闭提示,如果选择“Don`t show tips”则不再显示提示信息。
2.2 项目配置
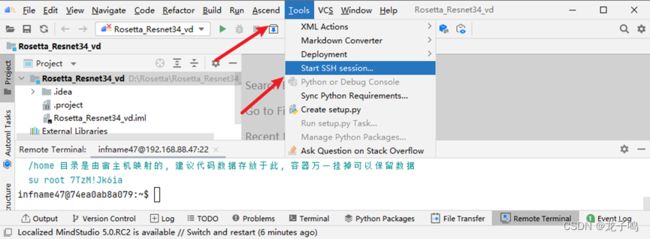
如上图所示,启动远程SSH终端。
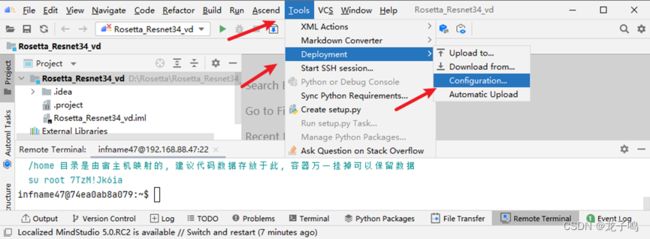
点击“Tools”、“Deployment”、Configuration,进行开发环境配置,如上图所示。
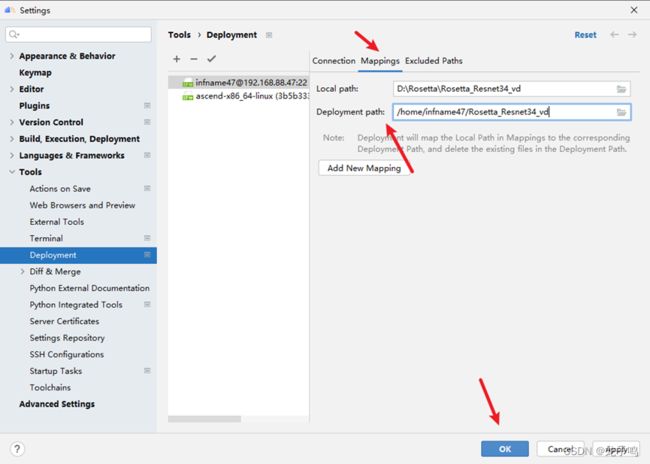
选择“Mappings”,填入“Deployment Path”远程映射路径,点击“OK”。
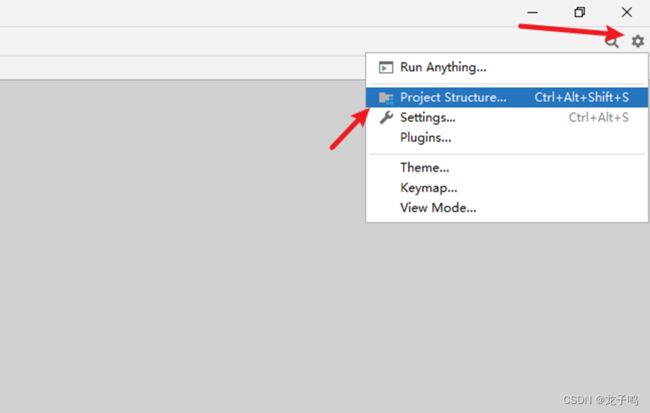
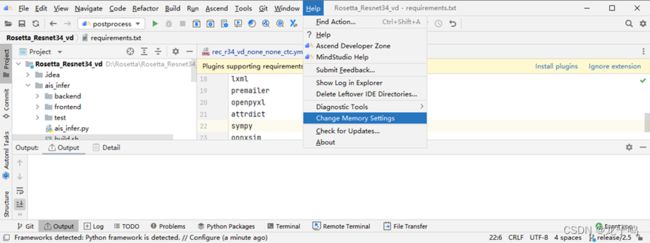
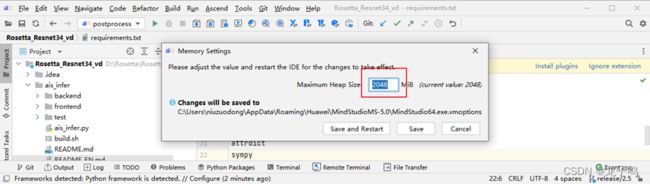
点击项目界面右上角设置图标,选择“Project Structure”,如上图所示。
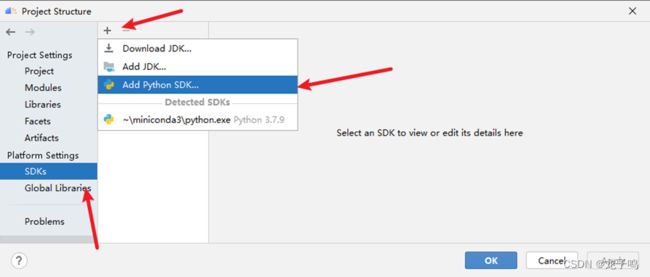
点击“SDKs”、+号图标,选择“Add Python SDK”。
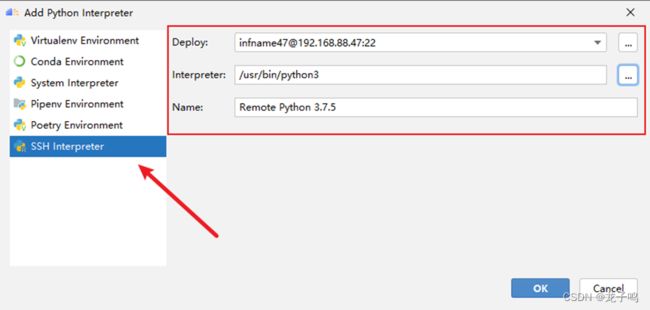
选择SSH Interprter,配置相应信息,点击“OK”。
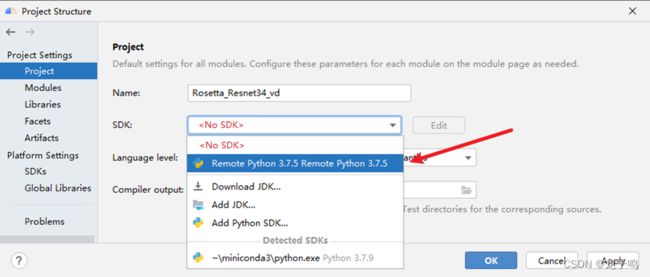
选择Project,配置SDK,如上图。
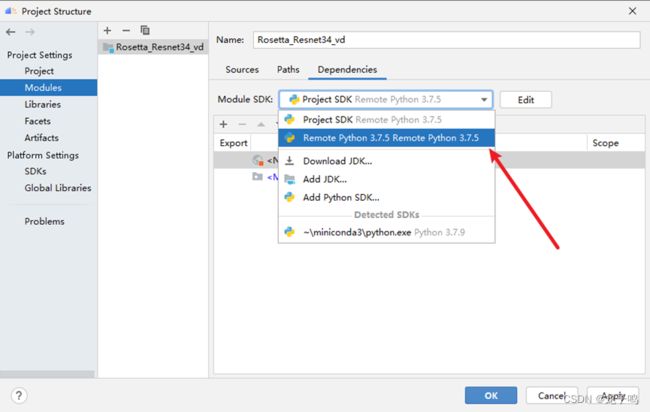
选择Moduls,选择Module SDK,如上图,点击“OK”。
三、获取模型代码
3.1 获取源码
在本地终端中使用如下命令获取源码:
git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
git reset --hard a40f64a70b8d290b74557a41d869c0f9ce4959d5
rm .\applications\
cd ..
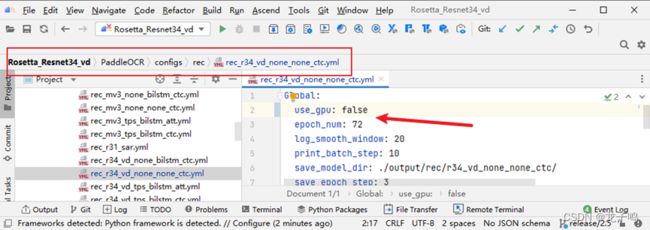
修改配置文件,将use_gpu设置成false,如上图。
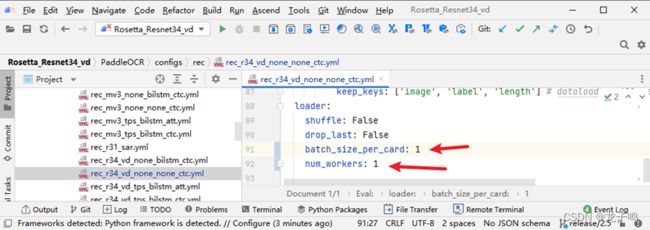
同时将batch和num_workers设置为1,如上图。
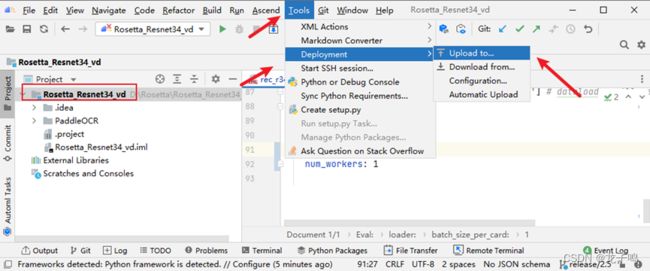
修改完成后将模型代码上传到远程服务器,如上图,依次点击Toos->Deployment->Upload to...。
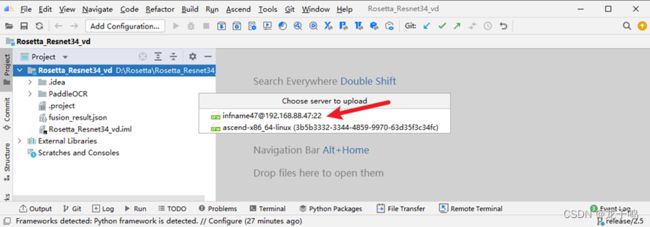
如上图所示,在弹出的对话框中选择上传的服务器。
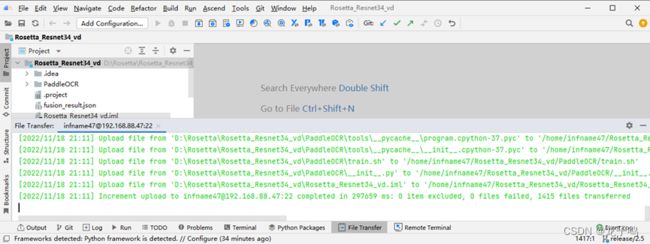
上传成功,如上图所示。
3.2 安装依赖
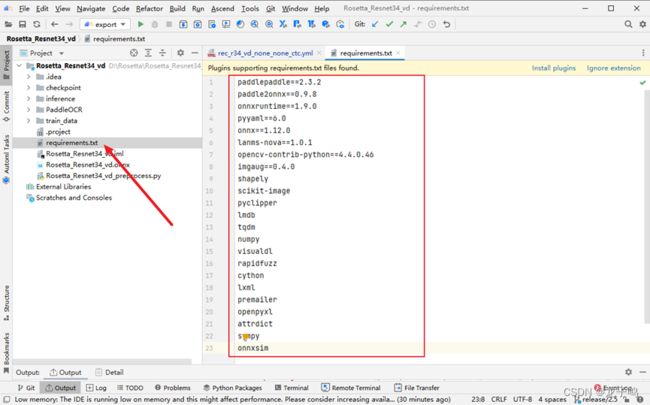
创建依赖文件requirments.txt,如上图所示,并针依赖文件上传的远程服务器。
requirments.txt的内容为:
paddlepaddle==2.3.2
paddle2onnx==0.9.8
onnxruntime==1.9.0
pyyaml==6.0
onnx==1.12.0
lanms-nova==1.0.1
opencv-contrib-python==4.4.0.46
imgaug==0.4.0
shapely
scikit-image
pyclipper
lmdb
tqdm
numpy
visualdl
rapidfuzz
cython
lxml
premailer
openpyxl
attrdict
sympy
onnxsim
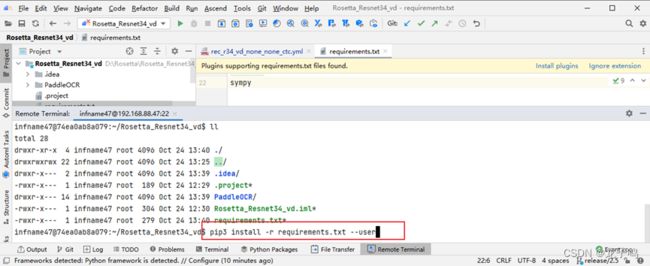
在远程终端中通过以上pip命令安装依赖,如上图所示。
四、获取数据集
4.1 数据集下载
该模型在以LMDB格式(LMDBDataSet)存储的IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,共计12067个评估数据,数据介绍参考DTRB:
https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here
数据集下载链接:
https://www.dropbox.com/sh/i39abvnefllx2si/AAAbAYRvxzRp3cIE5HzqUw3ra?dl=0
下载后将其中的evaluation.zip压缩包解压到Rosetta_Resnet34_vd\train_data\data_lmdb_release\validation目录下,并上传到远程服务器,如上图所示。
4.2 数据集预处理
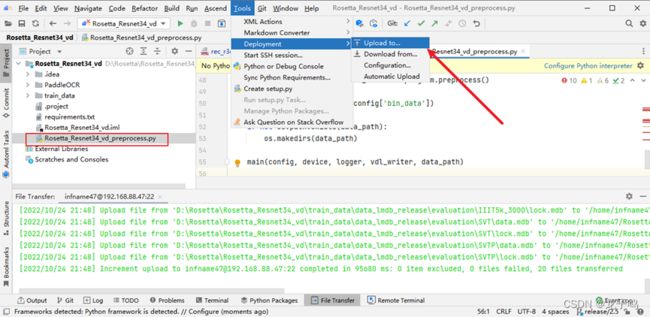
创建数据预处理脚本,并上传到远程服务器,如上图。
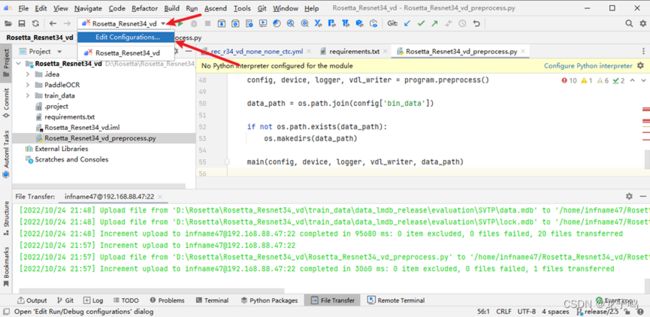
通过上图方式,创建可执行命令。
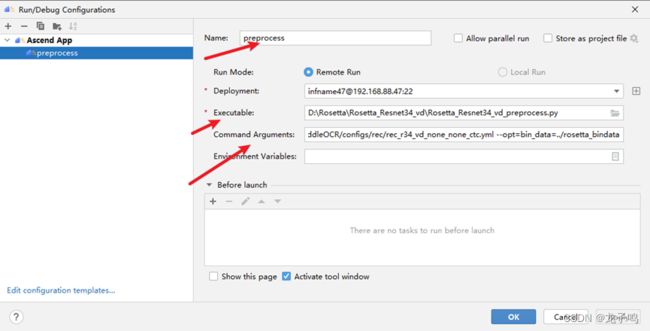
在弹出的对话框中填入命令名称(Name)、可执行脚本(Excutable)、和参数(Command Arguments),如上图,点击“OK”,具体参数为:
--config=PaddleOCR/configs/rec/rec_r34_vd_none_none_ctc.yml
--opt=bin_data=../rosetta_bindata
参数说明:
--config:模型配置文件
--opt=bin_data:预处理数据
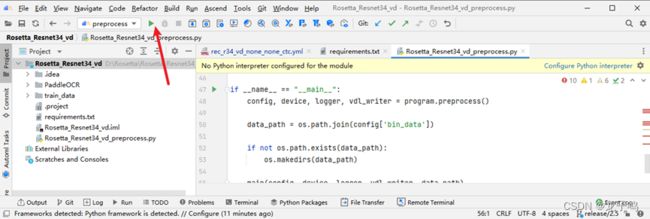
如上图所示,点击执行按钮,开始执行数据预处理命令。
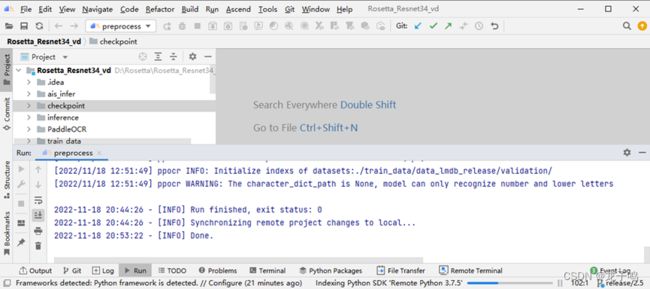
如上图所示,数据预处理命令执行完成。
五、模型转换
使用paddle2onnx将模型权重文件转换为.onnx文件,再使用MindStudio的Model Converter工具将onnx文件转为离线推理模型文件om文件。
5.1 转onnx模型
训练权重链接为:.
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r34_vd_none_none_ctc_v2.0_train.tar
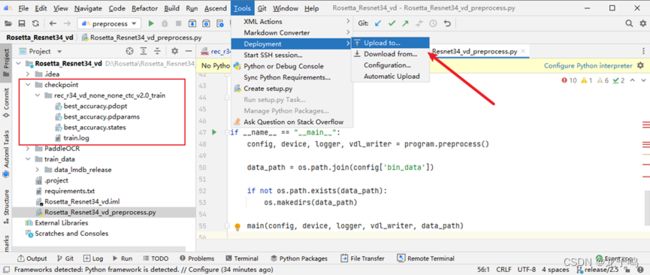
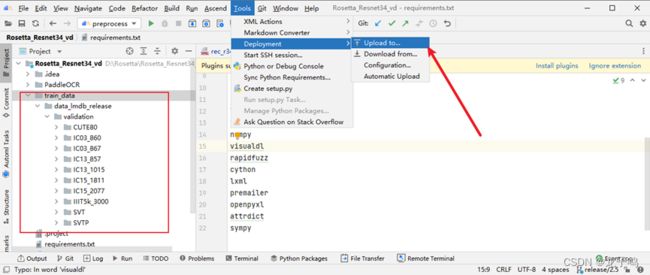
下载后将rec_r34_vd_none_none_ctc_v2.0_train.tar解压到Rosetta_Resnet34_vd目录下,点击Tools->Deployment->Upload to...上传到远程服务器,如上图所示。
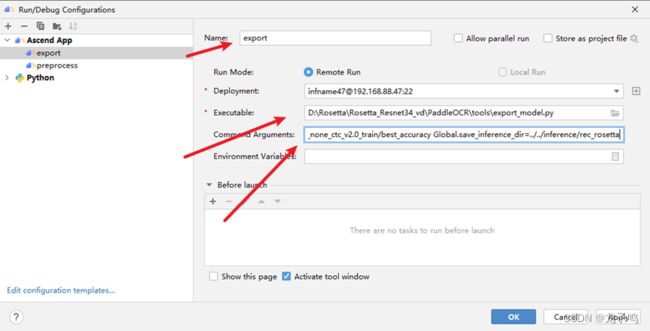
创建export命令,如上图所示,并执行,将训练权重转为推理模型,export具体参数如下:
-c ../../PaddleOCR/configs/rec/rec_r34_vd_none_none_ctc.yml
-o Global.pretrained_model=../../checkpoint/rec_r34_vd_none_none_ctc_v2.0_train/best_accuracy
Global.save_inference_dir=../../inference/rec_rosetta
参数说明:
-c:模型配置文件
-o:用户可选参数,包括Global.pretrained_model表示训练模型,Global.save_inference_dir表示推理模型保存路径
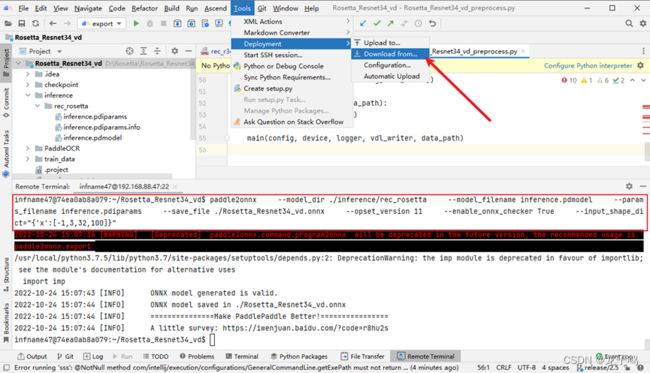
在远程终端使用paddle2onnx命令导出onnx模型,如上图所示,并点击Tools->Deployment->Download from...将onnx模型同步到本地。
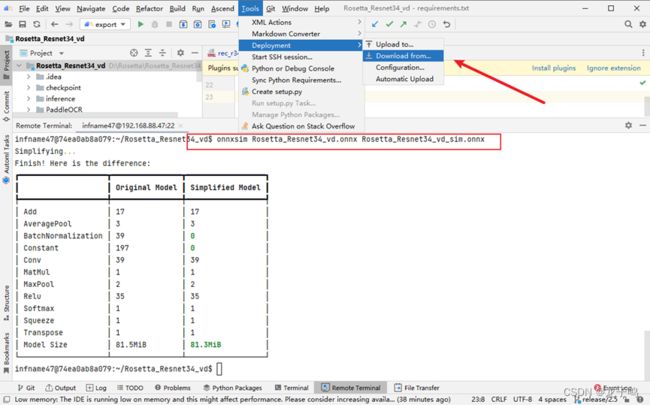
在远程终端使用onnxsim命令优化onnx模型,如上图所示,同时可点击Tools->Deployment->Download from...将优化后的onnx模型同步到本地。
5.2 转om模型
MindStudio的Model Converter工具按钮如上图所示。
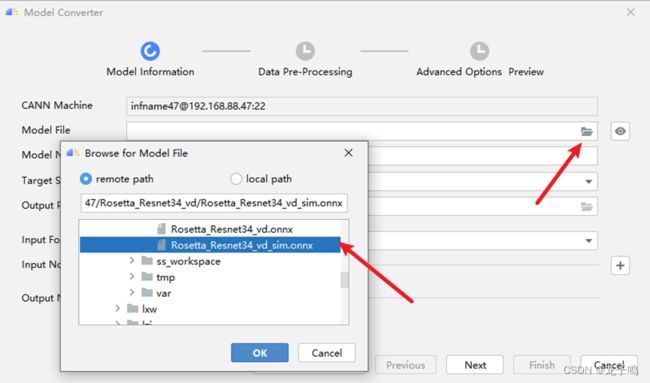
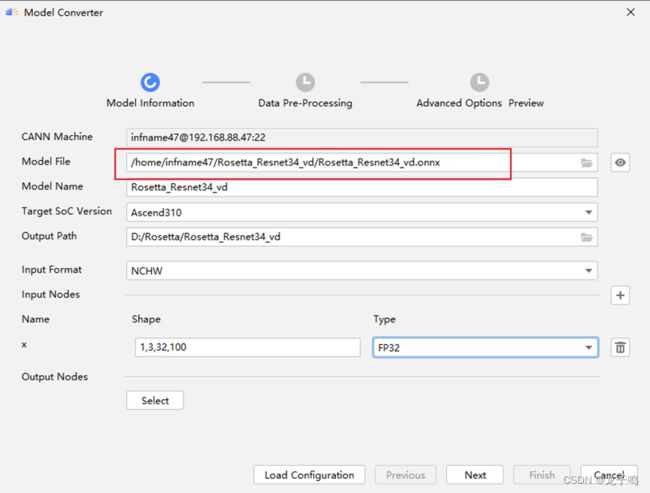
点击Model Converter工具按钮,首先选择onnx的Model File,如上图所示,点击“OK”后会自动进行模型解析。
模型解析如上图。
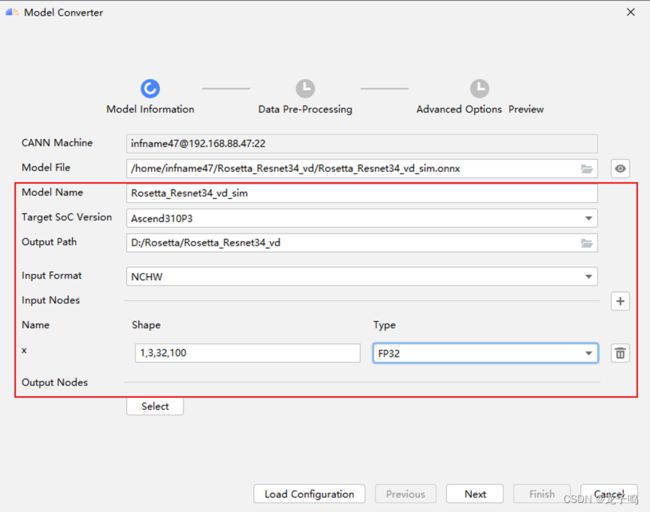
模型解析完成后,设置上图中的模型转换信息,点击“Next”继续。模型转换信息说明:
Model Name:保存模型名称
Target Soc Version:部署芯片型号,本文使用的是Ascend310P3
Output Path:om模型保存路径
Input Format:模型输入数据格式,本文是对图片数据进行推理,因此数据格式为NCHW。
Input Nodes:输入节点信息,本文模型有1个输入,Name为x,Shape为1,3,32,100,Type为FP32
Output Nodes:本文使用默认输出节点,不需要进行配置
MindStudio会进行命令检查,如上图所示。
检查完成后点击“Next”。
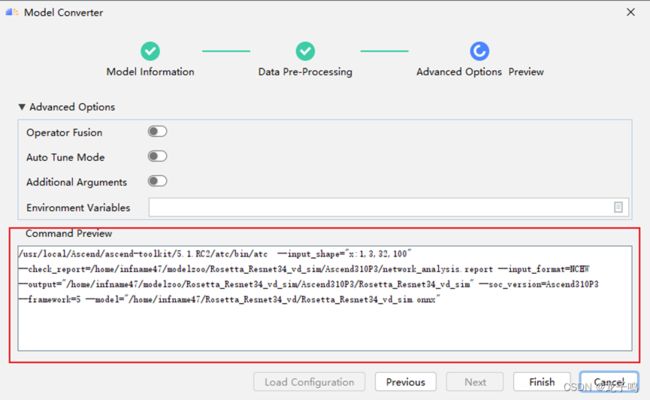
检查ATC命令后,点击“Finish”开始进行模型转换。
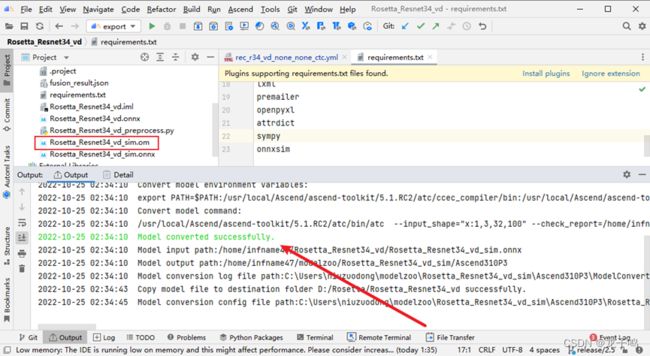
模型转换成功如上图所示,生成Rosetta_Resnet34_vd_sim.om模型。
六、模型推理
6.1 获取推理工具
Om模型的推理工具采用ais_infer,链接为:
tools: Ascend tools - Gitee.com。
本地下载后将ais_infer文件夹放到项目中,并上传到远程服务器,如上图所示。
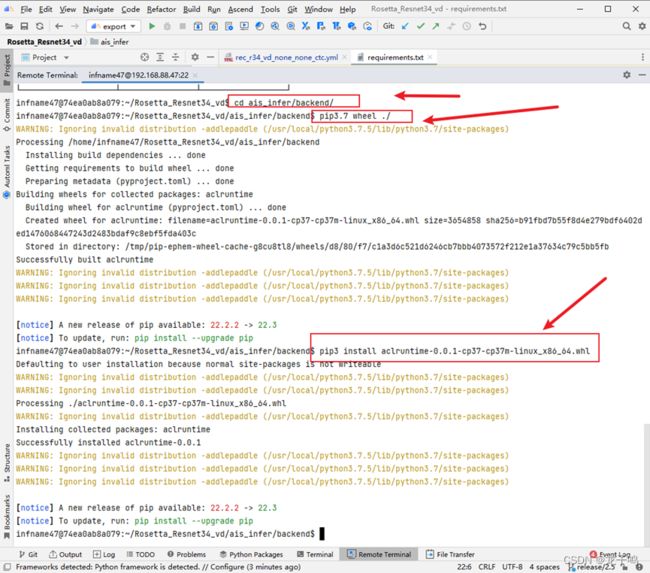
通过远程终端编译并安装aclruntime。
6.2 进行推理
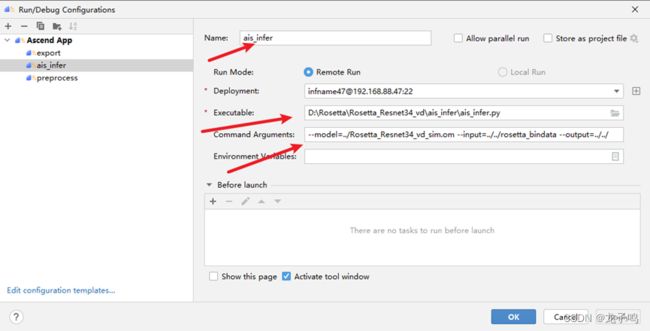
创建ais_infer推理命令,如上图,参数说明:--model表示om模型,--input表示输入数据路径,--output表示输出数据路径。
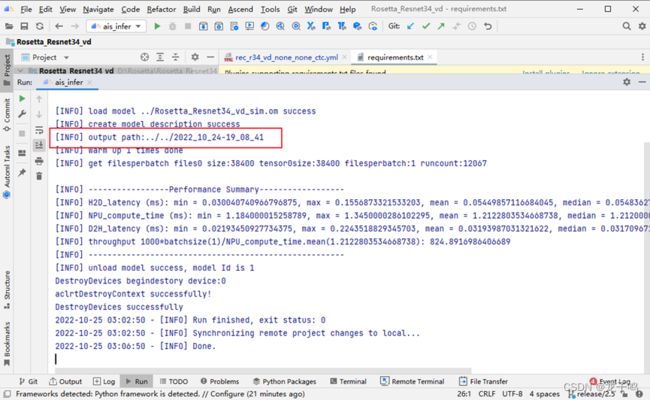
执行ais_infer命令,开始进行推理,推理成功如上图所示,推理结果保存在output path下,这里需要记住推理结果的目录2022_10_24-19_08_41,在下一步精度验证时会用到。
6.3 精度验证
创建后处理脚本,如上图所示。
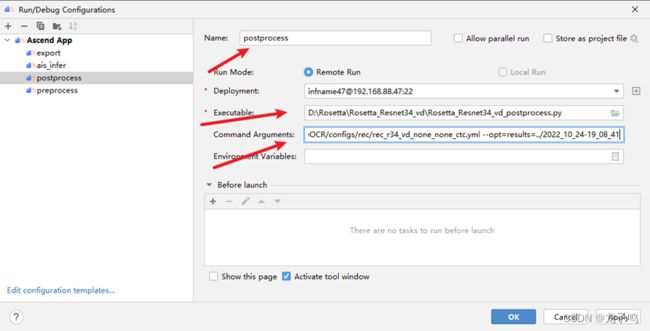
创建后处理命令,如上图所示,Command Arguments为:
--config=PaddleOCR/configs/rec/rec_r34_vd_none_none_ctc.yml --opt=results=../2022_10_24-19_08_41
参数说明:--config表示模型配置文件,--opt=results表示推理结果路径。
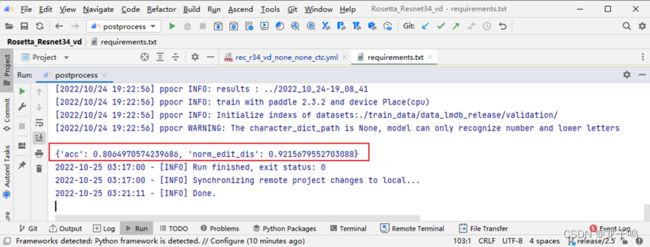
运行后处理命令,进行精度验证,命令执行完成后如上图所示,模型的精度acc为0.8064,官网给定的模型精度acc为0.7911,模型精度正常。
到此使用MindStudio完成了Rosetta_Resnet34_vd模型的离线推理开发。
七、问题总结

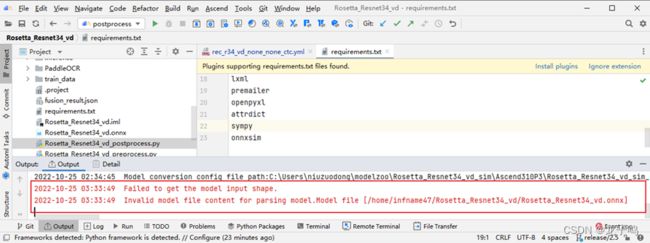
在使用MindStudio的Model Converter工具转om模型的时候,如果选择paddle2onnx生成的onnx模型,则会解析失败,报错如上图所示,经过尝试使用onnxsim工具优化onnx后可以正常解析。
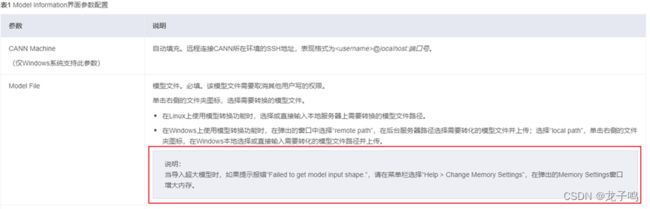
最后通过查看用户指导手册,该报错的原因如上图所示,按照手册指导说明进行配置后,可以正常解析paddle2onnx生成的onnx模型,如下图所示。
八、参考资料
使用MindStudio进行Rosetta_Resnet34_vd模型离线推理开发过程中参考很资料和文档,最后给大家推荐一些比较有用的资料,大家可以先通过官网了解MindStudio的一些功能,然后按照用户手册进行安装、和基本使用方法,最后可以在开发者社区参考一些案例,或者遇到问题进行求助,可以帮助自己快速使用MindStudio进行项目开发。
1.MindStudio官网
昇腾社区-官网丨昇腾万里 让智能无所不及
2.MindStudio开发者社区
华为云论坛_云计算论坛_开发者论坛_技术论坛-华为云
3.MindStudio用户手册
昇腾社区-官网丨昇腾万里 让智能无所不及