动态场景SLAM相关论文总结
参考文献:VDO-SLAM(动物判别与跟踪)、*DynaSLAM(深度学习+多视图几何分割)、*CoFusion(语义+运动分割)、Meaningful Maps With Object-Oriented Semantic Mapping(深度图上的非监督分割方法)、*Improving RGB-D SLAM in dynamic environments: A motion removal approach(基于几何的运动分割方法)、* DOT: Dynamic Object Tracking for Visual SLAM(先分割再由几何关系计算物体的实际运动)、DSP-SLAM(基于已重建对象的数据关联)、CubeSLAM(数据关联)、DymSLAM(运动分割)
Dynaslam:
GitHub - BertaBescos/DynaSLAM: DynaSLAM is a SLAM system robust in dynamic environments for monocular, stereo and RGB-D setups
关键词:RGB-D/stere、基于ORB-SLAM2 、稀疏特征点跟踪、稠密建图、实例+几何分割、主攻静态场景重建、无多目标跟踪优化
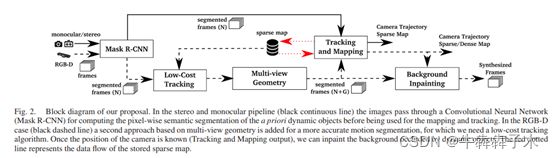
- 应该是先对图片进行特征提取。
- 实例分割:Mask R-CNN将图片分割为(潜在)动态区域和(潜在)静态区域两部分。分割之后进行低成本tracking,它是将地图点投影到当前图像帧,在图像上的静态区域寻找匹配,之后通过最小化重投影误差计算相机位姿。在这之前需要将分割轮廓上的特征点剔除。
- 多视图稀疏特征点分割:对于每一个输入帧(提取了特征点的,特征点也与地图点进行了匹配,静态特征点匹配较好,动态的特征点应该也能匹配上)由上一步得到相机位姿;考虑平移和旋转因素,选择之前与其重叠最多(看到共同地图点最多)的5个关键帧;将每个关键帧上的关键点都转换投影到当前帧(通过相机运动),得到当前帧下的关键点坐标和其深度值,计算两个视图上同一关键点的视差角,将视差角大于30°的点去除掉(因为TUM数据集上视差角大于30,物体很可能被遮挡,后续的操作中静态点也会被当作动态点)再进行以下操作:计算当前帧上投影过来的关键点的实际测量深度值,若此深度值与转换投影后的深度值相差太大则视此点是为动态点。
- 由特征点到稠密mask:在深度图像中围绕动态像素进行区域生长 [21] N. L. Gerlach, G. J. Meijer, D.-J. Kroon, E. M. Bronkhorst, S. J. Berge,´ and T. J. J. Maal, “Evaluation of the potential of automatic segmentation of the mandibular canal,” Brit. J. Oral Maxillofacial Surgery, vol. 52, no. 9, pp. 838–844, 2014
- 跟踪与建图:输入RGB、深度图、分割掩码,(重新提取特征点?还是第一次提取的特征点?)剔除分割区域边缘的ORB特征点,进行ORB-SLAM2的跟踪建图。
Co-Fusion:
GitHub - martinruenz/co-fusion: Co-Fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects
关键词:RGB-D/stere、稠密光流跟踪、稠密建图、实例+运动分割、主攻多目标重建、可多目标跟踪但无联合优化
1.Surfel重建(面元重建):用面元进行表面重建。一个面元包含元素有:位置、法线、颜色、半径、初始化时间戳、最新更新时间戳(更新次数)。点的融合更新:点的位置信息,法向量和颜色信息的更新方法类似于KinectFusion 采用加权融合的方式,可以参考StaticFusion中的方法,体素面(面元)的半径通过场景表面离相机光心的距离求得,距离越大,面片的半径越大。
2.模型跟踪:本文模型分为两类:激活模型和未激活模型。此部分是对每个激活模型进行六自由度位姿跟踪。(文中说模型跟踪是第一步,那获取的新帧怎么知道哪个是激活模型,模型又对应当前帧哪部分呢?应该是ICP+直接法可以不用知道匹配部分,只要移动较慢初值准确就直接能跟踪位姿。)
- 针对每一输入帧,对每个激活模型Mm(这是一个surfel模型)进行跟踪。跟踪方法:最小化t-1与t帧的能量函数(常用RGB-D损失函数:点面ICP+光度误差)
- 点面ICP:待对齐的是t帧深度图反向投影的属于模型Mm上的点云;目标点云是已建立的激活surfel模型Mm按照t-1帧相机位姿投影到t-1帧的深度图。目的是使当前帧点到surfel模型Mm表面距离最近。
- 光度误差:类似于直接法。

3.运动分割:由上一部分得到所有激活模型的Mt个位姿变换集合{Tmt}。运动分割的任务就是一个标记问题:将当前帧的所有点赋予Mt中一个运动标签或外点标签。为了减小计算量,首先将当前帧划分为SLIC超像素,然后再对超像素进行标记算法。这个标记问题用全连接CRF算法解决:最小化以下代价函数
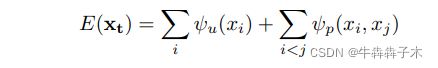
- 一元势:表示一个超像素si跟某个运动模型标签xi的关联度,也用ICP去判断,即用xi表示的运动模型将激活模型转换到当前帧时,超像素在模型表面的距离越小越有可能为xi标签。但是有可能激活模型几何不完整,导致转换过来后找不到与si对应的距离,此时给一元势赋值为当前帧深度范围的1%(属于适中值),以防标签标到物体边界外。当最佳模型都无法很好的标记si,则标记为新标签。
- 二元势:前一项是Potts模型,用来惩戒相似但标签不一致的情况;后一项是度量两点的相似度。两点的特征向量由点的2D位置、深度、颜色组成,相似度用高斯核函数度量。 这样会促使:两个超像素的特征向量距离越小,越可能标记为同一标签。
- 后续处理:将运动模型相同的连接为整体;将分割开的区域标注为不同标签:非最大值抑制。
- 新模型添加:如果一个外点块尺寸大于像素点总数的3%,则此块确定为新模型。对于原来在背景中现在开始运动的物体,需要通过在背景中去除ICP误差较大的部分来去除物体之前的残留。
4.这种先跟踪再分割的方法应该满足:动态物体占比远小于背景。因为如果动态物体过大,在物体由静转动的时候,背景模型的跟踪误差可能较大,影响分割。
5.参考:稀疏点分割也可参照此分割方法。但是会有缺点:同一背景下有两个重叠但运动方向不同的物体,一开始分割为同一个物体,由于特征点跟踪不像ICP会倾向于变化慢的物体,而会取最小二乘解,这会导致帧间跟踪结果离两个物体真实位姿变换都很大,导致模型分割不开。
MaskFusion:
http://visual.cs.ucl.ac.uk/pubs/maskfusion/
关键词:RGB-D/stere、稠密光流跟踪、稠密建图、实例+几何分割、主攻分割和多目标重建、可多目标跟踪但无联合优化
1.MaskFusion 前边跟踪与Co-Fusion相同,重点是分割方法不同:Co是运动分割(依赖于模型的运动)且让语义分割作为补充;Mask是几何分割(单帧几何分割)与语义分割融合作为分割结果
2.跟踪前的动静判断:对各模型Mm依次判断动还是静,为减少计算量只对动物跟踪。动静判断原则:运动不一致性和手拿性。运动不一致性:应该是先通过背景模型与当前帧计算相机运动,然后将各模型按照相机运动变换到当前帧,然后计算各模型的ICP误差,此误差大于阈值确定为动物。
3.RGBD图像上的几何分割:基于物体表面凸性和深度连续性假设。故在凹区和深度不连续区域进行分割(此方法会过分割)。常用于激光雷达数据的分割。本文定义深度不连续项φd和凹项 φc,对于一个像素点φd + λ φc > τ时就确定为边缘点。

其中vi和ni是v邻域节点位置和法向量,N为邻域大小。由此确定了边缘,再通过封装好的连通域算法由边缘进行区域标记。
4.分割融合:每帧都要进行几何分割,语义分割是偶尔的。当当前帧的语义分割可用时,将几何分割得到的标签映射到语义分割的掩码上,再将新的掩码映射到模型;当无可用语义分割结果就直接将几何标签映射到模型:
- 映射几何标签到掩码:当几何标签与某个掩码重叠超过标签65%,就被赋予到此掩码,相同掩码上的标签融合为一个新标签;
- 映射掩码到模型(即数据关联):模型渲染到当前帧,然后计算上一步的mask与模型的重叠,并检测mask与model的ID一致性(一对一),重叠大于阈值就将掩码与模型关联起来。如果没有可用掩码映射,也可直接将几何标签往模型上映射。形成最终的全局ID一致的分割标签。
5.这种分割缺点:虽然可以将语义分割与几何分割结合得到更精确的分割,但是本质上还是语义分割来识别目标,几何分割只在语义分割结果或现有模型基础上进行精修,对于未知运动目标无法分割。所以它处理动态场景还是只依靠语义分割的感知能力。如果背景中出现未知移动物体,则无法跟踪识别,还是属于背景模型中的部分。
技术疑问:新的模型如何加入、sufel模型的更新,尤其结构增加或减少后如何更新?
Meaningful Maps With Object-Oriented Semantic Mapping:ORB-SLAM2+稠密建图
- 实例分割:通过目标检测+基于深度的目标分割实现
- 基于深度图的非监督3D目标分割:先将深度图划分为超体素,构建连接超体素的邻接图。目标分割任务就变成了图分割任务。本文不是将邻接图中的边分类为1/0,而是给边赋予权重,然后用 Kruskal’s algorithm算法找到最佳图分割方法。以下是边的权重计算:
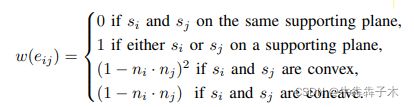
3.数据关联:将当前帧实例分割得到的结果关联到地图中已存在的目标模型或新建模型有以下方法:首先根据点云中心的欧式距离选择候选目标点云;然后再在两组点云间利用最近邻搜索,找到两两对应点对,计算点对距离(类似ICP误差)。如果百分之五十的点对距离小于阈值则进行关联。否则无法关联,故新建模型。(这一方法是要在得到相机位姿的情况下进行,因为要将俩个组点云转换到同一坐标系)
4.对象map独立维护:对象模型更新的核心是更新置信度(通过新的目标检测的置信度来累计更新);map由两部分组成:所有观测到的点云(保存的是每一关键帧观测到的点云),每个对象对应的所有分割点云(保存着指向pose graph的指针)。这种保存方式可以在位姿更新时更新map。
5.缺点:此方法类似于《动态场景下的视觉定位与语义建图技术研究_郑冰清》的3D分割方法,也是要提取拟合场景平面。
Improving RGB-D SLAM in dynamic environments: A motion removal approach:运动分割
1.关于动态物体对SLAM的影响:(主要体现在SLAM的位姿图优化过程中)
- 原始位姿图优化损失函数:

- 动态物体对位姿图的影响,针对动物进行改进的损失函数(第三章)

2.运动分割方法:单应矩阵计算相机运动、运动补偿后的差分图计算、由粒子滤波来加强运动检测结果、根据深度图进行前景分割(对深度图聚类)。
3.缺点:这里的单应矩阵适合于平面场景,针对普通场景不适合。
DOT:(稠密直接法、动静判断)
1.算法流程:分割得到掩码→按照目标掩码跟踪→直接法+匀速模型→得到Tc和To→由Tc(假设静态)将前一帧点投影当前帧→由Tc+To(实际运动)将前一帧点投影到当前帧→计算两种投影后的差值(动态视差),并得到其均值→由目标位姿估计的不确定度计算目标物的微分熵→由微分熵确定物体动静判断阈值→动态视差大于对应的阈值则视为动态→将分割掩码更新,只激活动态掩码→将掩码结果传入SLAM以避免动物影响
2.运动判断:文章首先根据分割结果计算了相机运动Tc和目标运动To(稠密直接法),简单的可以通过To大于阈值来判断目标动静。但是由于图像噪声对To的影响不同,不好设一个绝对阈值。本文选择在2D图像上进行判断:将目标的前一帧分别通过Tc和Tc+To投影到当前帧:
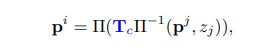
![]()
计算两者投影后对应点的差值(动态视差)。由于图像对运动的敏感度取决于:像素坐标、深度值、相机运动与目标运动方向夹角。所以,视差判断阈值与微分熵正相关(微分熵由运动估计的不确定度决定),通俗来讲:越远的物体,图片上一个像素的移动代表的实际运动就越大;反之,相同的实际运动越远的物体图像上的视差越小,判断其动静的阈值就应该越小。但是微分熵不能太小,太小的话目标的运动就不可观了。最后,通过目标上动态视差的均值大于目标阈值来判断动静。
3.掩码传播:通过将同一目标相邻几帧的点投影到当前帧来传播掩码(类似于上述的实际运动投影方法),省去了语义数据关联。到关键帧时才通过网络提取,这样可以提高分割频率。
4.参考:ICP/直接法等方法不需要匹配,可先跟踪再用跟踪的结果投影前一帧点/地图点来找到当前帧上的对应点。可以参考掩码传播。
VDO-SLAM:
GitHub - halajun/VDO_SLAM: VDO-SLAM: A Visual Dynamic Object-aware SLAM System
关键词:RGB-D/stere、稀疏+稠密光流跟踪、稀疏静态地图+稠密目标建图、实例分割、主攻多目标跟踪、可多目标跟踪+联合优化
- 实例分割+稠密光流估计→相机位姿跟踪(光流加入优化)→根据相机位姿估计结果计算各目标的场景流从而判断目标是否运动→对运动目标进行稠密跟踪→因子图局部优化(定步长滑窗内只优化相机位姿和静态结构)→因子图全局优化(优化相机位姿、静态结构、运动目标位姿、动态结构)
- 缺点:运行慢,由于光流跟踪对目标的旋转运动估计差,不是以目标为方向的目标级SLAM,没有3D bounding box估计。
- 参考:对环境利用稀疏特征点方法,对于目标的跟踪可以用稀疏点初始化,用ICP+直接法的稠密方法计算。
DynaSLAM2:基于ORB-SLAM2的稀疏特征点+3D bounding box法
1.数据关联:对输入的每一帧都要进行
(1)像素级实例分割,ORB特征点提取。假设分割之后属于先验动态实例的特征点是动态特征,不考虑这些先验是否真的在动。
(2)静态特征-地图静态点关联:首先将静态特征与之前帧和地图中的特征相关联,以初步估计相机姿势,就跟ORB-SLAM中一样。
(3)相邻帧间的实例-实例关联:以2Dbounding box的IOU作为代价的Munkres算法实现。
(4)动态特征-局部地图动态点关联:动态特征与局部地图中的动态点匹配关联,通过两种方法:地图中目标速度已知,就用匀速假设投影地图动态目标上的动态点到当前帧来寻找匹配,如果匹配点对不满足上边的实例匹配,则设为外点;如果目标速度未知,或上一方式匹配点不够,就在相邻帧中重叠最多的实例上暴力匹配。
(5)实例-目标关联:一个新的实例上的大多数特征点都能与地图中属于同一目标的点匹配关联上,就将此目标ID赋予这个实例。
(6)新目标创建:如果一个先验类别是动态的实例,其上有至少七个未曾被观测到的关键点,且这些点距离相机较近,则此实例就创建为新的目标,这些关键点与新目标绑定。
2.对象建模方式(跟踪参考坐标系设定):
- 以第一次得到的目标点云质心建立物体坐标,之后就按这个坐标系估计目标轨迹,此方式可以对所有目标运动进行建模,但这个坐标系是随机的没有具体的物理意义,eg:ClusterSLAM、VDO-SALM
- 先发现目标3D bounding box建立坐标系,再跟踪目标运动,对于只能看到部分视图不能估计出3D bounding box的物体不会进行跟踪,eg:CubeSLA
3.解耦的3D bounding box估计:目标的跟踪是用上述(1)的目标跟踪参考坐标系,这样可以对动态物体一开始就能跟踪上;但是要想对目标的尺寸和空间占有率进行感知就必须解耦估计3Dbounding box。所以,在(1)完成后,对目标点云估计3D bounding box(初始化:找到两个能够拟合大多数特征点的相互垂直的面来初始化3D bounding box),然后在窗口内优化3Dbounding box的尺寸和相对于跟踪参考坐标系的位姿(优化原理:最小化3D bounding box的图像投影与2D bounding box的距离)。
4.参考:动态特征点的匹配方法;针对目标的运动建模;联合BA优化和3Dbounding box的解耦估计与优化。
CubeSLAM:基于ORB-SLAM2的单目对象级SLAM+3D bounding box
https://github.com/shichaoy/cube_slam
关键词:单目、基于ORB-SLAM2、稀疏特征+光流跟踪+目标跟踪、稀疏建图+目标3D bounding box、目标检测无分割、主攻单目目标3Dbounding box估计+对象级slam、可多目标跟踪且联合优化
1.对象建模:对于静态目标上的点表示在世界坐标系下;对于动态目标上的点表示在目标坐标系下(因为此时的点是与目标绑定的,在目标坐标系下点的坐标不变)
2.数据关联:
- 首先根据ORB-SLAM2的特征点匹配和极线检测方法,进行特征点跟踪。由于动态物体的运动不一致性,故其上特征点不满足极线检测,匹配时静态点会成功跟踪,动态点无法跟踪。故经此之后,其上无匹配特征点的object设为动态目标。
- 静态目标数据关联:先将当前帧的特征点与各object关联起来(至少连续两帧位于目标的2D bounding box 和3D bounding box上);然后不同帧上目标进行关联(将共享特征点最多的目标进行关联)
- 动态目标数据关联:特征点跟踪用2D KLT稀疏光流法;特征点与object关联应该与上述一致;不同帧上的目标关联直接用视觉目标跟踪算法(光流法大移动时无法跟踪所以用共享特征点法不行)。上述关联完成后,可计算两帧间的目标运动,因此可以用目标运动补偿的三角化方法计算特征点坐标(当前帧下)。
3.参考:对象的建模方法,目标级SLAM的因子图设计,动态SLAM因子图设计。
ClusterVO:基于目标检测的运动分割+特征点稀疏法
1.流程:目标检测→多层次概率关联(对于动态目标)→特征点与landmark关联、当前帧object与已存在clusters关联→利用异构CRF方法对当前帧生成的新的landmarks聚类标记→匈牙利算法匹配聚类与实例关联结果→新的运动聚类结果形成并更新每个landmark标记权重→双跟踪框架进行状态估计
2.参考:
- 对于每帧新的landmarks进行新的聚类,此方法的前提是:完成第一步的实例关联,进而可以计算当前帧下cluster的位姿。在有了此位姿后,才可以将运动一致性加入聚类CRF的能量函数。
- 双跟踪框架解决基线长度问题和快速目标跟踪问题。
ClusterSLAM:批量运动聚类SLAM
1、介绍:此方法是离线批量方法,需要输入一批图片,通过判断整批图片上不同特征点间运动距离一致性来分割运动。首先构建运动距离一致性矩阵,作为之后的聚类标准。运动距离一致性矩阵是整批图片上所有特征点两两之间的距离一致性表征,运动距离一致性矩阵构建步骤有:
(1)距离计算。由两部分组成:一是3D几何距离的平均值,用来描述一对点在3D空间的距离一致性;一是一对点在图像空间的距离的最大值,用来描述视觉先验。

(2)元素剔除。由于观测不足会影响观测精度,所以将观测次数少于阈值的点剔除,此时运动距离矩阵就是一个稀疏矩阵。
聚类运用HAC(层次聚合聚类方法);通过多块一致聚类方法将帧分块单独进行HAC然后进行一致聚类,以加速HAC的进行。
在聚类将所有场景中出现的物体分类成功后进行考虑噪声的聚类形状估计:
- 当cluster q第一次被提取后,就将此时的相机坐标系设为q的自身坐标系,此后其他时刻用带正则项的加权ICP算法计算q相对于当前相机的坐标变换矩阵Tqc(是目标运动与相机运动的叠加结果,即:相对运动是两个绝对运动的叠加);
- 每当一新的观测帧加入时,更新cluster q中的结构点坐标。
然后进行解耦的因子图优化:先解q!=0,将(Pct)'Pqt看成一个变量Tqc;再解q=0得到相机运动Pct;结合Tqc和Pct得到目标运动Pqt。以下是能量函数构建

2、特点:利用运动中同一物体上的特征点间距不变原理,构建整个批次上的运动距离一致性矩阵来表示两两特征点在运动中的运动距离一致性。
3、参考:利用运动一致性检测原理实现运动聚类。
Permutation Preference Based Alternate Sampling and Clustering for Motion Segmentation:运动分割
1.原理:在多模型拟合中用permutation preference(排序偏好)表示点,迭代的交替进行模型采样与基于permutation preference的点聚类。单模型拟合方法用RANSAC,用来剔除外点和噪声。但运动分割是多空间问题,本文采用多模型拟合方法[41]-[43]。
2.疑问:
- permutation preference是什么:根据假设的m个模型(对于RGBD和立体视觉用3D-2D模型,对于2D-2D的单目用基础矩阵或单应矩阵模型)分别对n个点对计算残差,建立残差矩阵R,对R的每一行按由小到大排序,只排前k,排序后每一行的模型的秩按照排序后的顺序作为向量组成排序偏好矩阵。
- 聚类方法:上述的排序偏好矩阵表征所有n个点分别对假设模型适应度的排序。两两点之间的排序偏好向量的相似度通过Spearman footrule distance(斯皮尔曼尺距,两个排序列表间的绝对距离)评价。计算所有点两两之间的斯皮尔曼尺距离,组成矩阵。对此距离矩阵进行连接聚类(linkage clustering),得到聚类结果。
DymSLAM:基于ORB-SLAM2的稀疏定位+稠密建图
- 特点:不依赖语义信息或语义先验,采用多运动分割方法对不同运动的未知刚体对象进行分割。
- 多运动分割:类似上文原理,不过本文有所改进,改为对残差矩阵的量化矩阵进行截断偏好计算。在偏好矩阵上计算每个假设模型的点集相似度,构成M*M的距离矩阵。对此距离矩阵运用谱聚类,得到模型数量m1。然后用层次聚类对点实现聚类,聚类为m1类。如此交替迭代着采样和聚类。
- 标签关联:为实现当前帧的多运动分割结果与已有的运动目标关联,使用基于滑窗的联合标签关联方法[29]。在滑窗内通过特征匹配将窗内之前关键帧的标签传给当前帧。应该是取窗口内n帧与当前cluster匹配最多的object作为标签。
- 目标自身坐标系:移动目标的坐标系是由目标上的3D点在世界坐标系(第一帧相机坐标)下的重心确定的。这个重心由于看到的目标越来越全会一直变化,那目标的自身坐标系也会一直调整。
- 参考:多运动分割方法,和SLAM的因子图构成
动态场景下定位与建图-郑冰清
1.几何一致性的静态区域提取:
3D物体分割识别
1.三角剖分表示3D点云:有拓扑分解法、节点连接法、基于栅格法、Delaunay三角剖分(德劳内法),其中Delaunay三角剖分非常常用。
(1)Delaunay三角剖分原理:
- 定义:有一条边经过其两个端点存在一个经过两端点的圆,圆内不含点集中的任何其他点,则这边为Delaunay边;若一个三角剖分只包含Delaunay边则为Delaunay三角剖分。
- 特性:空圆特性(任意三角形的外接圆内不会有其他点存在);最大化最小角特性。
- Voronoi图(泰森多边形):将点集划分为多边形区域,每个区域只有一个点,且这个区域到这个点距离最近(比到其他区域都近)。Voronoi图中点的连线组成的就是Delaunay三角剖分
- 其他特性:唯一性(从哪一点开始生成的结果都一样);最接近(每个三角形三点距离最近);外凸性(三角网最外边界是凸多边形)
(2)2D空间的Delaunay三角剖分:常用算法有,翻边算法、逐点插入算法、分割合并法、Bowyer-Waston算法;用的最多的是逐点插入法(找一个超级三角形将所有点包起来,从任一点开始连接到外层三角形三个顶点,形成新的三个三角形,每个三角形做外接圆,如果外接圆内有点就连接点到这个三角形的三个顶点,如此迭代插入)。
(3)3D空间的Delaunay三角剖分:分割归并法(快但占内存)、逐点插入法(慢但不占内存)、三角网生长法。前两种合并形成合成算法。
合成算法步骤:
- 超过阈值数量的点集一分为二,左右继续划分直到点集数量小于阈值
- 左右两个点集分别用插入法生成基本三角网(方法类似2D插入法,不多三角形变为四面体)
- 找出连接左右凸包的底线和顶线
- 在底线和顶线之间,生成连接两个凸包的三角网
- 逐层合并即可
2.目标分割
(1)基于深度图的阈值分割:根据背景与前景的深度值差异进行分割,一般有三种方法:
- 双峰法:将整个深度图看作前景和背景两个部分,通过深度图直方图特性得到直方图峰值,选择两峰之间的波谷作为阈值
- 迭代法:给定初始阈值,分割为两类,取两类像素均值的平均数,迭代直到阈值满足要求
- 大津法:给一个初始阈值,分为两类,计算类间方差,更新阈值
(2)基于点云的平面检测:通过RANSAC算法将点云拟合至最佳平面
3.几何形状识别
对于3D物体,可以通过点云旋转变换使得待测物体表面平行于XY平面进行投影,这样就将3D曲面形状检测转化为2D平面形状检测。因此需要设计区分不同目标物体的描述子来表征目标物,传统目标识别一般用人工设计特征:SIFT、3D点云自旋转图像、几何特征等。
(1)几何不变矩:通过轮廓特征区分不同类物体,用几何不变矩定量表示轮廓特征。又称Hu矩,描述3D物体轮廓的特征向量,适用于深度图平面形状识别。在深度图上(x,y)为随机变量,深度值f(x,y)为密度函数,根据阶数不同组成各阶不变矩:零阶中心矩表征目标区域面积;一阶中心矩表征目标区域质心坐标;二阶中心矩表征目标区域旋转半径;三阶中心矩表征目标区域方位和斜度,反映目标扭曲程度。各阶中心矩通过零阶中心矩进行尺度归一化,最终利用二阶和三阶归一化中心矩构造7个不变矩组表征几何形状,具有平移、旋转和尺度不变性。提取几何不变矩特征后,训练SVM分类器,识别3D物体形状。
(2)3D关键点检测:
投影到深度图,进行2D图像上的关键点检测。
(3)其他3D特征: