【三】头歌平台实验-规则分词法
规则分词是通过设立词典并不断地对词典进行维护以确保分词准确性的分词技术。基于规则分词是一种匹配式的分词技术,要进行分词的时候通过在词典中寻找相应的匹配,找到则进行切分,否则不切分。传统的规则式分词主要有三种:正向最大匹配法、逆向最大匹配法以及双向最大匹配。
第1关:正向最大匹配法
要求:实现正向最大匹配算法,基于所输入的词典,完成对 sentence 的分词并输出分词结果。
def cutA(sentence, dictA):
# sentence:要分词的句子
result = []
sentenceLen = len(sentence)
n = 0
maxDictA = max([len(word) for word in dictA])
# 任务:完成正向匹配算法的代码描述,并将结果保存到result变量中
# result变量为分词结果
# ********** Begin *********#
while sentenceLen>0:
word=sentence[0:maxDictA]
while word not in dictA:
if len(word)==1:
break
word=word[0:len(word)-1]
result.append(word)
sentence=sentence[len(word):]
sentenceLen=len(sentence)
# ********** End **********#
print(result) # 输出分词结果相关知识:
1、中文分词简介
在语言理解中,词是最小的能够独立活动的有意义的语言成分。将词确定下来是理解自然语言的第一步,只有跨越了这一步,中文才能像英文那样过渡到短语划分、概念抽取以及主题分析,以至自然语言理解,最终达到智能计算的最高境界。因此,每个 NLP 工作者都应掌握分词技术。
在汉语中,词以字为基本单位的,但是一篇文章的语义表达却仍然是以词来划分的。因此,在处理中文文本时,需要进行分词处理,将句子转化为词的表示。这个切词处理过程就是中文分词,它通过计算机自动识别出句子的词,在词间加入边界标记符,分隔出各个词汇。整个过程看似简单,然而实践起来却很复杂,最主要的困难就在于分词歧义。
现有的分词算法可分为三大类:
-
基于规则的分词方法;
-
基于统计的分词方法;
-
基于理解的分词方法。
什么是规则分词
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不予切分。
按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法,接下来我们将依次介绍这三种算法。
2、正向最大匹配法( MM 法)
a、算法描述 如图所示,
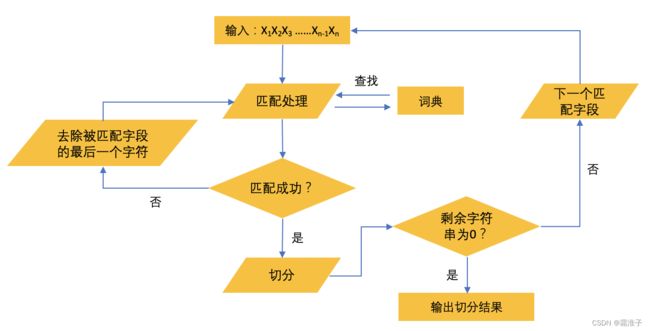
正向最大匹配算法的具体步骤为:
- 从左向右取待切分汉语句的 m 个字符作为匹配字段, m 是机器词典中最长词条的字符数;
- 查找机器词典并进行匹配。匹配成功则将匹配字段作为一个词切分出来,匹配失败则将匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再匹配,一直重复上述过程直到切分出所有词。
b、主要思想
假定分词词典中最长词有 i 个汉字字符,则用被处理文档的当前字符串中的前 i 个字作为匹配字段,查找字典,从而得出分词结果。
c、范例
我们现有的分词词典中最长的长度为5,词典中有南京市、长江、大桥三词,现采用 MM 法对句子南京市长江大桥进行分词,那么首先从句子中取出前5个字南京市长江,发现词典中没有该词,于是缩小长度,取前4个字南京市长,发现词典中还是没有该词,于是继续缩小长度,取前3个字南京市,词典中存在该词,于是该词被确认切分。再将剩下的长江大桥按照同样方式进行切分,得到长江和大桥,最终切分为南京市/长江/大桥3个词。
第2关:逆向最大匹配法
要求:实现逆向最大匹配算法,基于所输入的词典,完成对 sentence 的分词并输出分词结果。
def cutB(sentence,dictB):
result = []
sentenceLen = len(sentence)
maxDictB = max([len(word) for word in dictB])
# 任务:完成逆向最大匹配算法的代码描述
# ********** Begin *********#
while sentenceLen>0:
word=sentence[-maxDictB:]
while word not in dictB:
if len(word)==1:
break
word=word[1:]
result.append(word)
sentence=sentence[0:len(sentence)-len(word)]
sentenceLen=len(sentence)
# ********** End **********#
print(result[::-1],end="")
相关知识:
1、逆向最大匹配法( RMM 法)
a、算法描述
逆向最大匹配( RMM 法)法的基本思想与 MM 法相同,不同的是分词切分的方向与 MM 法相反。逆向最大匹配法从右到左来进行切分。每次取最右边(末端)的 m 个字符作为匹配字段, 若匹配失败,则去掉匹配字段最左边(前面)的一个字,继续匹配。
b、范例
eg:南京市长江大桥,按照逆向最大匹配,分词词典中最长词条的字符数长度为5,分词词典中有南京市长和长江大桥两词,现采用 RMM 法对句子南京市长江大桥进行分词,那么首先从句子中从右到左取出前5个字市长江大桥,发现词典中没有该词,于是缩小长度,取前4个字长江大桥,词典中存在该词,于是该词被确认切分。再将剩下的南京市按照同样方式进行切分,得到南京市,最终切分为南京市/长江大桥2个词。当然,如此切分并不代表完全正确,可能有个叫江大桥的南京市长也说不定。
由于汉语中偏正结构偏多,逆向最大匹配分词更多时候比正向最大匹配分词准确率高。
第3关:双向最大匹配算法
要求:实现双向最大匹配算法,基于所输入的词典,完成对 sentence 的分词并输出分词结果。
class BiMM():
def __init__(self):
self.window_size = 3 # 字典中最长词数
def MMseg(self, text, dict): # 正向最大匹配算法
result = []
index = 0
text_length = len(text)
while text_length > index:
for size in range(self.window_size + index, index, -1):
piece = text[index:size]
if piece in dict:
index = size - 1
break
index += 1
result.append(piece)
return result
def RMMseg(self, text, dict): # 逆向最大匹配算法
result = []
index = len(text)
while index > 0:
for size in range(index - self.window_size, index):
piece = text[size:index]
if piece in dict:
index = size + 1
break
index = index - 1
result.append(piece)
result.reverse()
return result
def main(self, text, r1, r2):
# 任务:完成双向最大匹配算法的代码描述
# ********** Begin *********#
r1_count=0
r2_count=0
if len(r1)>len(r2):
print(r2,end="")
elif len(r1)r2_count:
print(r2,end="")
else:
print(r1,end="")
# ********** End **********#
相关知识:
1、双向最大匹配法
a、算法描述
双向最大匹配的基本思想是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的分词结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。
该匹配算法的具体描述如下:
-
比较正向最大匹配和逆向最大匹配结果;
-
如果分词数量结果不同,那么取分词数量较少的那个;
-
在分词数量结果相同的情况下,如果分词结果相同,则可以返回任何一个;如果分词结果不同,则返回单字数比较少的那个。
b、范例
比如北京大学生前来应聘这个句子,如果通过正向最大匹配算法得到的结果为北京大学 / 生前 / 来 / 应聘,其中分词数量为4,单字数为 1;而通过逆向最大匹配算法所得到的结果为北京/ 大学生/ 前来 / 应聘,其中分词数量为4,单字数为0。则根据双向最大匹配算法,逆向匹配单字数少,因此返回逆向匹配的结果。
经研究表明,90%的中文使用正向最大匹配分词和逆向最大匹配分词能得到相同的结果,而且保证分词正确;9%的句子是正向最大匹配分词和逆向最大匹配分词切分有分歧的,但是其中一定有一个是正确的;不到1%的句子是正向和逆向同时犯相同的错误:给出相同的结果但都是错的。因此,在实际的中文处理中,双向最大匹配分词能够胜任几乎全部的场景。
-END-![]()