数据挖掘与R分析——京东某鞋类店铺售后评论
前言
电商方便、快捷、时间成本低等优势会让消费者很愿意通过电商网站来了解产品信息、购买商品并通过评价表达自己购买商品过程的感受、对购买商品的满意程度和对所购买商品的建议和要求。大数据时代背景下,电子商务领域的评论文本可以在短时间内达到极高的累计值,此时进行评论文本的人工阅读与分析不仅耗费时间和精力,也无法确保分析的准确性和全局性,所以有必要借助数据分析手段以及自然语言处理等方法来挖掘评论其潜在价值,可以帮助商家了解真实的商品商铺状态,提高自身的商业竞争力。本文通过数据挖掘和R语言分析京东某商鞋铺的商品评价,并为该店铺优化提出一些建议。
项目流程图
- 数据挖掘——爬虫
selenium
参考GitHub
import requests
import re
import time
import json
import random
from bs4 import BeautifulSoup
from selenium import webdriver
import threading
from concurrent.futures import ThreadPoolExecutor
from requests.exceptions import HTTPError,Timeout,RequestException,ProxyError,ConnectTimeout
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
from DbTools import MySQLTool
from DbTools import CsvTool
import os
def getPage_link(keyword):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
#driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
searchUrl = 'http://search.jd.com/'
driver.get(searchUrl)
time.sleep(1)
input_ = wait.until(EC.presence_of_element_located((By.ID, 'keyword')))
submit = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, "input_submit")))
input_.clear()
input_.send_keys(keyword)
submit.click()
page_ele = driver.find_element_by_css_selector('div#J_bottomPage span.p-skip > em > b') #获取商品的页数
link_list = []
goodsId = []
#url_list = driver.find_elements_by_css_selector(".gl-item .p-name [target=_blank]")
id_list = driver.find_elements_by_css_selector(".gl-item")
for id in id_list:
goodsId.append(id.get_attribute('data-sku'))
return goodsId
def getOtherLink(keyword, page):
goodsId = []
for i in range(page):
url = 'https://search.jd.com/Search?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=%d' %(keyword, 2*i+3)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
id_list = soup.select('li.gl-item')
for id in id_list:
#print(id['data-sku'])
goodsId.append(id['data-sku'])
time.sleep(random.randint(0,6))
return goodsId
def parse_comments(future):
res = future.result()
#print(res)
keyword = res[0]
responseTexts = res[1]
if responseTexts:
myLock = threading.Lock()
myLock.acquire()
dbtool = MySQLTool.DbTool()
dbtool.creataTable(keyword)
dbtool.saveComments(keyword, responseTexts)
dbtool.closeConn()
myLock.release()
#CsvTool.wirte2csv(keyword, responseTexts)
time.sleep(2)
def getOneGoodComment(keyword, goodId, maxPage):
url = 'https://item.jd.com/%s.html#comment' %(goodId)
try:
print('爬取ing的商品'+goodId)
responseTexts = []
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
wait = WebDriverWait(driver, 10)
driver.get(url)
count = 0
for page in range(maxPage):
if count % 10 == 0:
time.sleep(random.randint(3, 9))
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, "#comment .comments-list [data-tab=item] .comment-con")))
soup = BeautifulSoup(driver.page_source, 'lxml')
comments = soup.select("#comment .comments-list [data-tab=item] .comment-con")
stars = soup.select('.comment-star')
for comment, stat in zip(comments, stars):
responseTexts.append([comment.text.strip(), stat['class'][1][4]])
count += 1
next_page = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#comment .ui-page .ui-pager-next")))
driver.execute_script("arguments[0].click();", next_page)
driver.quit()
time.sleep(random.randint(1, 9))
return keyword, responseTexts
except TimeoutException as err:
print(err)
return None
def getAllGoodsComments(keyword, goodsId):
pool = ThreadPoolExecutor(3)
for goodId in goodsId:
maxPage = 15
future = pool.submit(getOneGoodComment, keyword, goodId, maxPage)
future.add_done_callback(parse_comments)
pool.shutdown()
if __name__ == '__main__':
starttime = time.time()
goodsId1 = getPage_link('运动鞋')
goodsId2 = getOtherLink('运动鞋', 14)
goodsId1.extend(goodsId2)
print('id:爬取评论')
time.sleep(10)
getAllGoodsComments('运动鞋', goodsId1)
endtime = time.time()
dtime = endtime - starttime
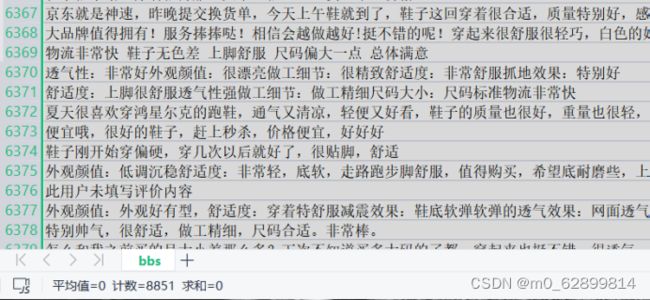
print("程序运行时间:%.8s s" % dtime)1.2数据集概览:
- 数据源及预处理
使用Rstudio,(r版本为4.0以上)
> library(tm)
载入需要的程辑包:NLP
> library(tmcn)
> library(Rwordseg)
> bbs <- readLines("C:/Users/41413/Desktop/bbs.txt",encoding = 'UTF-8')
2.1 读取评论后分词,然后向量化做成语料:
bs <- segmentCN(bbs);bs

docs <- Corpus(VectorSource(bs))
2.2 对于语料还需要进行去停用词处理,去各种特殊符号,这里我用了中文停用表:
docs <- tm_map(docs, removeNumbers)
#停用词(这个的主要用法是消除某些语气词,标点,助词等对整体词语的影响)
# 如果说停用表不用的话最终可视化词云为

发现会有很多的很,的,也,了等等,
也可以不用停词表,(它不是很全面,也需要完整做出来结果之后自己修改添加删除等)使用excel里的替换用法,把这些频繁出现的“很”,“的”,等词语和标点替换为空值。
停用词表链接:GitHub - goto456/stopwords: 中文常用停用词表(哈工大停用词表、百度停用词表等)
myStopwords <- readLines("C:/Users/41413/Desktop/stopwords1.txt",encoding = 'UTF-8')
> myStopwords<-myStopwords[Encoding(myStopwords)!="unknown"]
> docs <- tm_map(docs, removeWords, myStopwords)
myStopwords<-myStopwords[Encoding(myStopwords)!="unknown"]
docs <- tm_map(docs, removeWords, myStopwords)
toSpace <- content_transformer(function(x, pattern) { return (gsub(pattern, " ", x))})
2.3 语料处理之后将其转化为词文档矩阵
tdm <- createTDM(docs, language = "zh") #创建词文档矩阵,中文
- 进行聚类。
3.1 建立好的词文档矩阵有很多的0如图:是一个系数矩阵,因此需要剔除部分,只留下重要的行和列:
tdm_removed<-removeSparseTerms(tdm, 0.9) #去掉低于90%的的稀疏条数
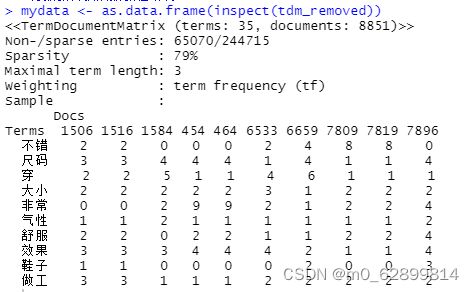
inspect(tdm_removed)
3.2 计算距离,层次聚类:
#将数据转换成数据框结构
mydata <- as.data.frame(inspect(tdm_removed))
#开始聚类分析-层次聚类
mydata.scale<-scale(mydata) #数据标准化和中心和变换
d<-dist(mydata.scale,method="euclidean") #计算矩阵距离
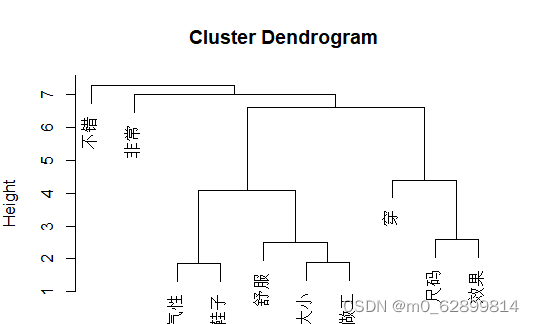
fit <- hclust(d, method="ward.D") #层次聚类算法
plot(fit)
3.3 Kmeans聚类
kfit <- kmeans(d, 2, nstart=100) # 两类
#plot – need library cluster
library(cluster)
clusplot(as.matrix(d), kfit$cluster, color=T, shade=T, labels=2, lines=0)
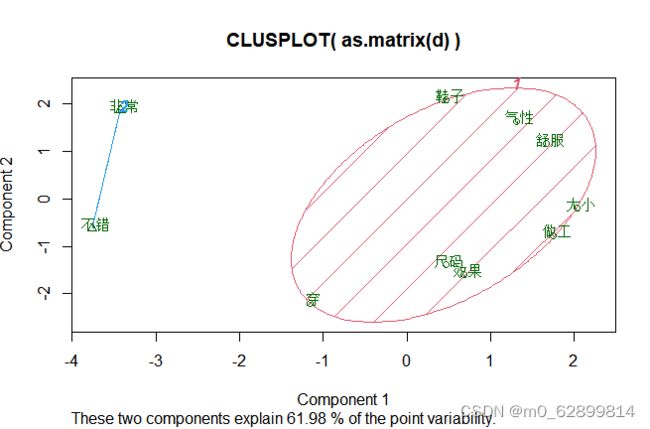
3.4 K-means聚类:
3.5 聚类分析评价:
层次聚类的结果基本可以得到评论的内容可以分为评价的部分和感受的部分以及穿之后的感受部分,通过层次聚类可以快速了解文本内容。
Kmeans设置聚成2类,可以解释为:一类是对鞋的属性细节评价,一类为肯定的评价语气词,对于文本的聚类更多的考虑其可解释性并非过分追求聚类的精准。
- 词云图
4.1 词云图优点和作用
视觉上更有冲击力。词云图比条形图、直方图和词频统计表格等更有吸引力,视觉冲击力更强,一定程度上迎合了人们快节奏阅读的习惯内容上更直接。图本身是对文本内容的高度浓缩和精简处理,能更直观的反映特定文本的内容,在一定程度上能节省读者时间,让读者在短时间内对文本数据的主要信息做到一目了然。词云图可以作为一种分析工具应用到用户画像、舆情分析等场景下,还可以直接嵌入到报告、数据分析类产品、可视化大屏中,是对文本数据价值变现的一种手段。
4.2 词云图制作
df = data
library(tm);library(Rwordseg);library (RColorBrewer);library(wordcloud);library(tmcn);
载入需要的程辑包:NLP
> basketshoes = readLines("bbs11.txt")
> basketshoes.seg = unlist(lapply(X = basketshoes,FUN = segmentCN));
> library(wordcloud2)
> wordcloud2(basketshoes.seg, size = 1,fontFamily = "微软雅黑",color = "black")

但是显示的效果不是很好,原因可能是中文停用表有自身的缺陷,在停用表的处理上不够细致,之后对停用表增改了一些图片里高频的词汇,最终得到上图(黑白)词云的效果。
如上操作之后,我们得到的词云图,根据之前对该词文档评论的聚类,提取出关键词直观显示我们发现:舒服,做工,外观,透气,这四大鞋本身属性出现的频率高,因此推测:口碑是否与这四大因素有直接或间接的联系,想要提高销量,那么企业设计、营销运营时需要从这四个方面考虑。
提出思考:为什么“价格”的因素不是很直观呢?
猜测一:可能是因为在前期选购商品时,大部分人在心中有一个价格预期或者说是隐形的心理规定,就比如消费能力较低人群很少会去超过预期的购买运动鞋,高消费人群也较少的关注于价格,消费中等的人群可能因为内心也有一个价格区间,所以并不会在购买后想到价格的这一影响因素。
猜测二:就是这款鞋本身可能不是一件物超所值的商品,价格这一因素的优势不是很明显。对于一些高端的运动鞋或收藏品,由于电商销售无法直接接触产品,很多消费者不会选择在网上购买价格过高的产品。
- 客观数据的回归分析:
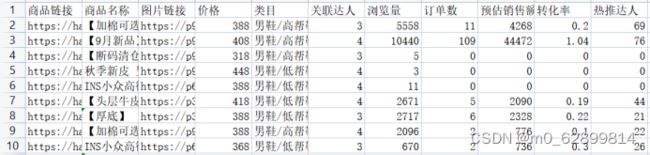
除了这些主观因素,尝试从某分析网站爬取的近三十日的销售数据分析影响销售和评价的客观因素。
数据前十行展示:
# 版本问题不能使用mvstatas,所以再次使用R3.0.0
> library(mvstats)
> xz=read.table("clipboard",header=T)
> cor(xz)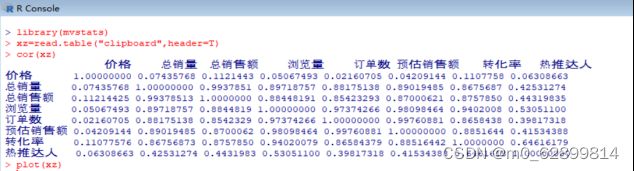
>.Plot(xz)
> corr.test(xz) #多元数据相关系数检验
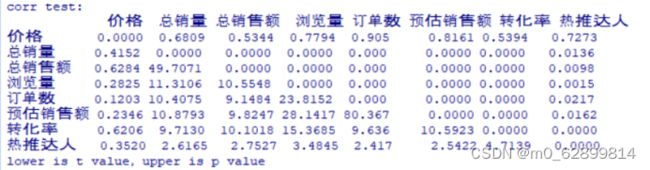
由结果可知,总销量与销售额关系紧密,这是常识;
总销量与浏览量的相关性较强,p值小于0.01
> xzfm=lm(总销量~.,data=xz) # 线性回归
> summary(xzfm)

> R2=summary(xzfm)$r.sq # 多元线性回归模型决定系数
> R=sqrt(R) # 多元回归数据复相关系数
![]()
线性回归分析思路总结!简单易懂又全面! - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/91994336
https://zhuanlan.zhihu.com/p/91994336
多元线性回归分析主要解决以下几方面的问题。
(1)确定几个特定的变量之间是否存在相关关系,如果存在的话,找出它们之间合适的数学表达式;
(2)根据一个或几个变量的值,预测或控制另一个变量的取值,并且可以知道这种预测或控制能达到什么样的精确度;
(3)进行因素分析。例如在对于共同影响一个变量的许多变量(因素)之间,找出哪些是重要因素,哪些是次要因素,这些因素之间又有什么关系等等。
再结合数据网站对该关键字相关联的“用户画像,点击率,搜索时段,消费分布,相关产品”等数据
因此本次报告为该商铺如下建议:
- 由回归模型我们可以得知,用户的点击率和转换率有强相关关系,在晚间18:00-23:00以发放优惠券、引流小视频集中发布或者采用直播带货的方式来吸引流量,进而提高销量。
- 在出售运动鞋类商品时多注重上文提到的四大特性--“舒服,做工,外观,透气”。注重顾客体验提高服务质量和产品质量,以提高店铺长久稳定的客源。
- 店铺内可以上架或链接相关性强的商品,提高收益。
- 避免商品的两极化分布,适当调整价格,数据显示转换率前两位为价格去去0-300,与1750元以上的商品,说明商品的极化差异较大,适当调整价格有利于商品的出售,避免积货。
- 因此综上请注重以下三类人群。
| 人群 |
点击率 |
转换率 |
| 年龄:50岁及以上_月均消费额度:1750元及以上 |
5.15% |
8.64% |
| 年龄:25-29岁_月均消费额度:1750元及以上_性别:女 |
5.21% |
7.23% |
| 类目笔单价:300-500_月均消费额度:1750元及以上 |
5.25% |
7.59% |
写到最后,R语言处理量大的数据非常不合理,本来是有三万条数据,我在执行分词时,耗费了近十几分钟,最后在调用rJava计算词频时直接卡崩,因此我不得不放弃很多东西;我们专业学的知识感觉很局限。希望大数据管理与应用的同学们能多多学习python等,搭配一些库处理起来非常流畅。