【论文笔记+代码解读】《The Transformer Network for the Traveling Salesman Problem》
介绍
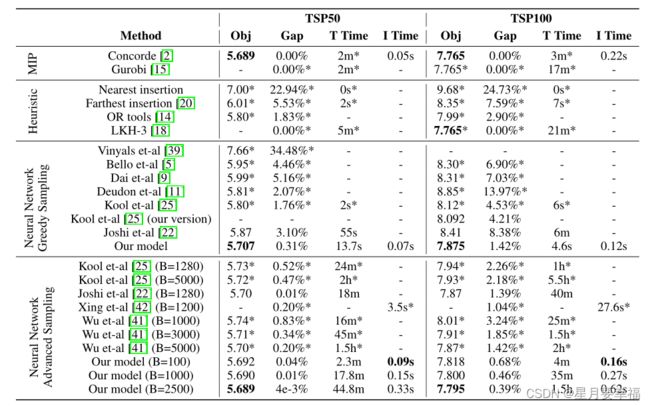
本文采用Transformer架构解决TSP问题,通过强化学习完成训练。在TSP50和TSP100中都有良好表现,与启发式算法对比,TSP50的最佳差距为0.004%,TSP100为0.39%。
模型结构
文中采用了编码器-解码器结构,首先对全部输入结点进行编码,在解码过程中依次“翻译”出每个结点。
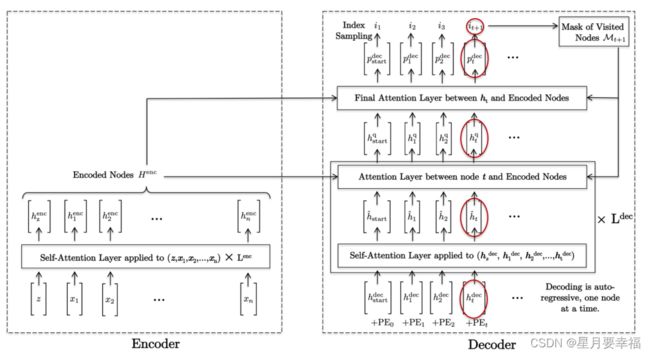
编码器
编码过程是一个标准的Transformer编码器,由 L 个多头注意力层组成。每个子层是由一个多头注意力模块和批归一化模块组成,二者之间采用残差连接。这里多定义一个 z 结点作为开始标志结点,采用随机初始化方式。
输入:
x (bsz, nb_nodes+1, dim_emb)
输出:
h (bsz, nb_nodes+1, dim_emb)
score (bsz, nb_nodes+1, nb_nodes+1)
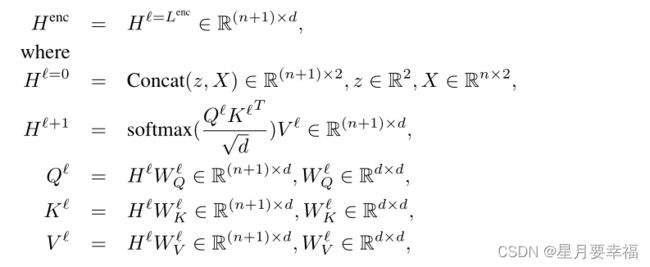 class Transformer_encoder_net(nn.Module)类是编码器实现类,forward函数中定义了整个编码器结构,输出为编码后结点特征和attention分数
class Transformer_encoder_net(nn.Module)类是编码器实现类,forward函数中定义了整个编码器结构,输出为编码后结点特征和attention分数
class Transformer_encoder_net(nn.Module):
"""
Encoder network based on self-attention transformer
Inputs :
h of size (bsz, nb_nodes+1, dim_emb) batch of input cities
Outputs :
h of size (bsz, nb_nodes+1, dim_emb) batch of encoded cities
score of size (bsz, nb_nodes+1, nb_nodes+1) batch of attention scores
"""
def __init__(self, nb_layers, dim_emb, nb_heads, dim_ff, batchnorm):
super(Transformer_encoder_net, self).__init__()
assert dim_emb == nb_heads* (dim_emb//nb_heads) # check if dim_emb is divisible by nb_heads
self.MHA_layers = nn.ModuleList( [nn.MultiheadAttention(dim_emb, nb_heads) for _ in range(nb_layers)] )
self.linear1_layers = nn.ModuleList( [nn.Linear(dim_emb, dim_ff) for _ in range(nb_layers)] )
self.linear2_layers = nn.ModuleList( [nn.Linear(dim_ff, dim_emb) for _ in range(nb_layers)] )
if batchnorm:
self.norm1_layers = nn.ModuleList( [nn.BatchNorm1d(dim_emb) for _ in range(nb_layers)] )
self.norm2_layers = nn.ModuleList( [nn.BatchNorm1d(dim_emb) for _ in range(nb_layers)] )
else:
self.norm1_layers = nn.ModuleList( [nn.LayerNorm(dim_emb) for _ in range(nb_layers)] )
self.norm2_layers = nn.ModuleList( [nn.LayerNorm(dim_emb) for _ in range(nb_layers)] )
self.nb_layers = nb_layers
self.nb_heads = nb_heads
self.batchnorm = batchnorm
def forward(self, h):
# PyTorch nn.MultiheadAttention requires input size (seq_len, bsz, dim_emb)
h = h.transpose(0,1) # size(h)=(nb_nodes, bsz, dim_emb)
# L layers
for i in range(self.nb_layers):
h_rc = h # residual connection, size(h_rc)=(nb_nodes, bsz, dim_emb)
h, score = self.MHA_layers[i](h, h, h) # size(h)=(nb_nodes, bsz, dim_emb), size(score)=(bsz, nb_nodes, nb_nodes)
# add residual connection
h = h_rc + h # size(h)=(nb_nodes, bsz, dim_emb)
if self.batchnorm:
# Pytorch nn.BatchNorm1d requires input size (bsz, dim, seq_len)
h = h.permute(1,2,0).contiguous() # size(h)=(bsz, dim_emb, nb_nodes)
h = self.norm1_layers[i](h) # size(h)=(bsz, dim_emb, nb_nodes)
h = h.permute(2,0,1).contiguous() # size(h)=(nb_nodes, bsz, dim_emb)
else:
h = self.norm1_layers[i](h) # size(h)=(nb_nodes, bsz, dim_emb)
# feedforward
h_rc = h # residual connection
h = self.linear2_layers[i](torch.relu(self.linear1_layers[i](h)))
h = h_rc + h # size(h)=(nb_nodes, bsz, dim_emb)
if self.batchnorm:
h = h.permute(1,2,0).contiguous() # size(h)=(bsz, dim_emb, nb_nodes)
h = self.norm2_layers[i](h) # size(h)=(bsz, dim_emb, nb_nodes)
h = h.permute(2,0,1).contiguous() # size(h)=(nb_nodes, bsz, dim_emb)
else:
h = self.norm2_layers[i](h) # size(h)=(nb_nodes, bsz, dim_emb)
# Transpose h
h = h.transpose(0,1) # size(h)=(bsz, nb_nodes, dim_emb)
return h, score
解码器
解码器一次只输出一个结点,假设已经解码了旅游中的前 t 个城市,我们想预测下一个城市。解码区别于《ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!》中只采用第一个结点和第 t 个结点以及图嵌入作为上下文结点,本文充分考虑了已解码的每一个结点进行Attention,解码过程由以下四步组成,其中第二三步为 L 层:
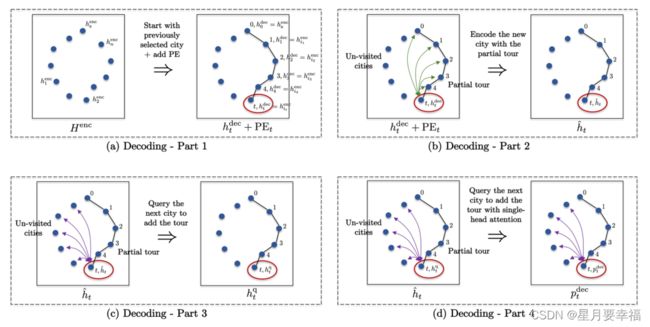
-
编码信息+位置嵌入(PE)

-
L层已解码结点Attention获取query
Attention聚集已输出结点的信息,为下一步准备query。这里的Attention采用多头,包含残差连接与批归一化。query取自 t 结点嵌入,key、value分别取自已解码的每一个结点嵌入。
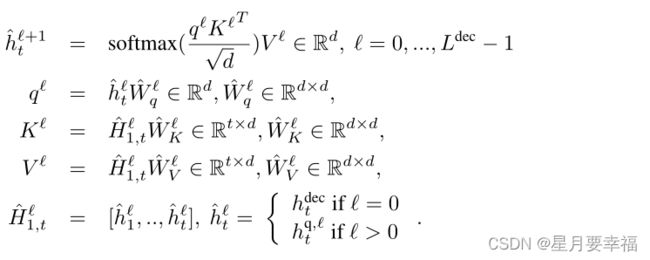
-
L层,,未解码结点Attention
此步骤使用多头注意层查询未访问城市中的下一个可能城市。query取自上一层输出嵌入,key、value取自未访问的结点嵌入,这里需要一个mask来判断结点是否已访问。
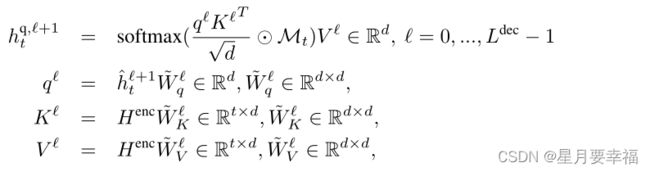
-
输出概率
最后一步采用单头注意力机制,输出结点概率。其中query取自上一层输出嵌入,key、value取自未访问的结点嵌入。
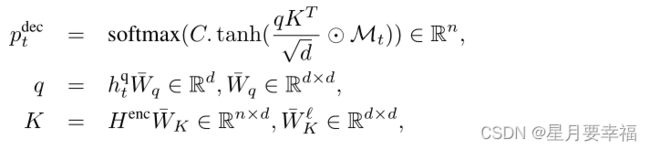 代码中class AutoRegressiveDecoderLayer类定义了单层上述二三步实现,输出结点 t 经过与以访问结点和未访问结点attention后的嵌入(bsz, nb_nodes+1)
代码中class AutoRegressiveDecoderLayer类定义了单层上述二三步实现,输出结点 t 经过与以访问结点和未访问结点attention后的嵌入(bsz, nb_nodes+1)
class AutoRegressiveDecoderLayer
class AutoRegressiveDecoderLayer(nn.Module):
"""
Single decoder layer based on self-attention and query-attention
Inputs :
h_t of size (bsz, 1, dim_emb) batch of input queries
K_att of size (bsz, nb_nodes+1, dim_emb) batch of query-attention keys
V_att of size (bsz, nb_nodes+1, dim_emb) batch of query-attention values
mask of size (bsz, nb_nodes+1) batch of masks of visited cities
Output :
h_t of size (bsz, nb_nodes+1) batch of transformed queries
"""
def __init__(self, dim_emb, nb_heads):
super(AutoRegressiveDecoderLayer, self).__init__()
self.dim_emb = dim_emb
self.nb_heads = nb_heads
self.Wq_selfatt = nn.Linear(dim_emb, dim_emb)
self.Wk_selfatt = nn.Linear(dim_emb, dim_emb)
self.Wv_selfatt = nn.Linear(dim_emb, dim_emb)
self.W0_selfatt = nn.Linear(dim_emb, dim_emb)
self.W0_att = nn.Linear(dim_emb, dim_emb)
self.Wq_att = nn.Linear(dim_emb, dim_emb)
self.W1_MLP = nn.Linear(dim_emb, dim_emb)
self.W2_MLP = nn.Linear(dim_emb, dim_emb)
self.BN_selfatt = nn.LayerNorm(dim_emb)
self.BN_att = nn.LayerNorm(dim_emb)
self.BN_MLP = nn.LayerNorm(dim_emb)
self.K_sa = None
self.V_sa = None
def reset_selfatt_keys_values(self):
self.K_sa = None
self.V_sa = None
def forward(self, h_t, K_att, V_att, mask):
bsz = h_t.size(0)
h_t = h_t.view(bsz,1,self.dim_emb) # size(h_t)=(bsz, 1, dim_emb)
# embed the query for self-attention
q_sa = self.Wq_selfatt(h_t) # size(q_sa)=(bsz, 1, dim_emb)
k_sa = self.Wk_selfatt(h_t) # size(k_sa)=(bsz, 1, dim_emb)
v_sa = self.Wv_selfatt(h_t) # size(v_sa)=(bsz, 1, dim_emb)
# concatenate the new self-attention key and value to the previous keys and values
if self.K_sa is None:
self.K_sa = k_sa # size(self.K_sa)=(bsz, 1, dim_emb)
self.V_sa = v_sa # size(self.V_sa)=(bsz, 1, dim_emb)
else:
self.K_sa = torch.cat([self.K_sa, k_sa], dim=1)
self.V_sa = torch.cat([self.V_sa, v_sa], dim=1)
# compute self-attention between nodes in the partial tour
h_t = h_t + self.W0_selfatt( myMHA(q_sa, self.K_sa, self.V_sa, self.nb_heads)[0] ) # size(h_t)=(bsz, 1, dim_emb)
h_t = self.BN_selfatt(h_t.squeeze()) # size(h_t)=(bsz, dim_emb)
h_t = h_t.view(bsz, 1, self.dim_emb) # size(h_t)=(bsz, 1, dim_emb)
# compute attention between self-attention nodes and encoding nodes in the partial tour (translation process)
q_a = self.Wq_att(h_t) # size(q_a)=(bsz, 1, dim_emb)
h_t = h_t + self.W0_att( myMHA(q_a, K_att, V_att, self.nb_heads, mask)[0] ) # size(h_t)=(bsz, 1, dim_emb)
h_t = self.BN_att(h_t.squeeze()) # size(h_t)=(bsz, dim_emb)
h_t = h_t.view(bsz, 1, self.dim_emb) # size(h_t)=(bsz, 1, dim_emb)
# MLP
h_t = h_t + self.W2_MLP(torch.relu(self.W1_MLP(h_t)))
h_t = self.BN_MLP(h_t.squeeze(1)) # size(h_t)=(bsz, dim_emb)
return h_t
*class Transformer_decoder_net定义了整个解码器类,输出为选取下一个结点的概率(bsz, nb_nodes+1) *
class Transformer_decoder_net(nn.Module):
"""
Decoder network based on self-attention and query-attention transformers
Inputs :
h_t of size (bsz, 1, dim_emb) batch of input queries
K_att of size (bsz, nb_nodes+1, dim_emb*nb_layers_decoder) batch of query-attention keys for all decoding layers
V_att of size (bsz, nb_nodes+1, dim_emb*nb_layers_decoder) batch of query-attention values for all decoding layers
mask of size (bsz, nb_nodes+1) batch of masks of visited cities
Output :
prob_next_node of size (bsz, nb_nodes+1) batch of probabilities of next node
"""
def __init__(self, dim_emb, nb_heads, nb_layers_decoder):
super(Transformer_decoder_net, self).__init__()
self.dim_emb = dim_emb
self.nb_heads = nb_heads
self.nb_layers_decoder = nb_layers_decoder
self.decoder_layers = nn.ModuleList( [AutoRegressiveDecoderLayer(dim_emb, nb_heads) for _ in range(nb_layers_decoder-1)] )
self.Wq_final = nn.Linear(dim_emb, dim_emb)
# Reset to None self-attention keys and values when decoding starts
def reset_selfatt_keys_values(self):
for l in range(self.nb_layers_decoder-1):
self.decoder_layers[l].reset_selfatt_keys_values()
def forward(self, h_t, K_att, V_att, mask):
for l in range(self.nb_layers_decoder):
K_att_l = K_att[:,:,l*self.dim_emb:(l+1)*self.dim_emb].contiguous() # size(K_att_l)=(bsz, nb_nodes+1, dim_emb)
V_att_l = V_att[:,:,l*self.dim_emb:(l+1)*self.dim_emb].contiguous() # size(V_att_l)=(bsz, nb_nodes+1, dim_emb)
if l<self.nb_layers_decoder-1: # decoder layers with multiple heads (intermediate layers)
h_t = self.decoder_layers[l](h_t, K_att_l, V_att_l, mask)
else: # decoder layers with single head (final layer)
q_final = self.Wq_final(h_t)
bsz = h_t.size(0)
q_final = q_final.view(bsz, 1, self.dim_emb)
attn_weights = myMHA(q_final, K_att_l, V_att_l, 1, mask, 10)[1]
prob_next_node = attn_weights.squeeze(1)
return prob_next_node
模型定义
集成了编码、解码模块,模型定义在class TSP_net中,其中输入为每个结点的特征表示 x (bsz, nb_nodes, dim_emb) ,输出为访问顺序序列tours (bsz, nb_nodes)、整个序列的选取的概率sumLogProbOfActions (bsz,)
class TSP_net(nn.Module):
"""
The TSP network is composed of two steps :
Step 1. Encoder step : Take a set of 2D points representing a fully connected graph
and encode the set with self-transformer.
Step 2. Decoder step : Build the TSP tour recursively/autoregressively,
i.e. one node at a time, with a self-transformer and query-transformer.
Inputs :
x of size (bsz, nb_nodes, dim_emb) Euclidian coordinates of the nodes/cities
deterministic is a boolean : If True the salesman will chose the city with highest probability.
If False the salesman will chose the city with Bernouilli sampling.
Outputs :
tours of size (bsz, nb_nodes) : batch of tours, i.e. sequences of ordered cities
tours[b,t] contains the idx of the city visited at step t in batch b
sumLogProbOfActions of size (bsz,) : batch of sum_t log prob( pi_t | pi_(t-1),...,pi_0 )
"""
def __init__(self, dim_input_nodes, dim_emb, dim_ff, nb_layers_encoder, nb_layers_decoder, nb_heads, max_len_PE,
batchnorm=True):
super(TSP_net, self).__init__()
self.dim_emb = dim_emb
# input embedding layer
self.input_emb = nn.Linear(dim_input_nodes, dim_emb)
# encoder layer
self.encoder = Transformer_encoder_net(nb_layers_encoder, dim_emb, nb_heads, dim_ff, batchnorm)
# vector to start decoding
self.start_placeholder = nn.Parameter(torch.randn(dim_emb))
# decoder layer
self.decoder = Transformer_decoder_net(dim_emb, nb_heads, nb_layers_decoder)
self.WK_att_decoder = nn.Linear(dim_emb, nb_layers_decoder* dim_emb)
self.WV_att_decoder = nn.Linear(dim_emb, nb_layers_decoder* dim_emb)
self.PE = generate_positional_encoding(dim_emb, max_len_PE)
def forward(self, x, deterministic=False):
# some parameters
bsz = x.shape[0]
nb_nodes = x.shape[1]
zero_to_bsz = torch.arange(bsz, device=x.device) # [0,1,...,bsz-1]
# input embedding layer
h = self.input_emb(x) # size(h)=(bsz, nb_nodes, dim_emb)
# concat the nodes and the input placeholder that starts the decoding
h = torch.cat([h, self.start_placeholder.repeat(bsz, 1, 1)], dim=1) # size(start_placeholder)=(bsz, nb_nodes+1, dim_emb)
# encoder layer
h_encoder, _ = self.encoder(h) # size(h)=(bsz, nb_nodes+1, dim_emb)
# list that will contain Long tensors of shape (bsz,) that gives the idx of the cities chosen at time t
tours = []
# list that will contain Float tensors of shape (bsz,) that gives the neg log probs of the choices made at time t
sumLogProbOfActions = []
# key and value for decoder
K_att_decoder = self.WK_att_decoder(h_encoder) # size(K_att)=(bsz, nb_nodes+1, dim_emb*nb_layers_decoder)
V_att_decoder = self.WV_att_decoder(h_encoder) # size(V_att)=(bsz, nb_nodes+1, dim_emb*nb_layers_decoder)
# input placeholder that starts the decoding
self.PE = self.PE.to(x.device)
idx_start_placeholder = torch.Tensor([nb_nodes]).long().repeat(bsz).to(x.device)
h_start = h_encoder[zero_to_bsz, idx_start_placeholder, :] + self.PE[0].repeat(bsz,1) # size(h_start)=(bsz, dim_emb)
# initialize mask of visited cities
mask_visited_nodes = torch.zeros(bsz, nb_nodes+1, device=x.device).bool() # False
mask_visited_nodes[zero_to_bsz, idx_start_placeholder] = True
# clear key and val stored in the decoder
self.decoder.reset_selfatt_keys_values()
# construct tour recursively
h_t = h_start
for t in range(nb_nodes):
# compute probability over the next node in the tour
prob_next_node = self.decoder(h_t, K_att_decoder, V_att_decoder, mask_visited_nodes) # size(prob_next_node)=(bsz, nb_nodes+1)
# choose node with highest probability or sample with Bernouilli
if deterministic:
idx = torch.argmax(prob_next_node, dim=1) # size(query)=(bsz,)
else:
idx = Categorical(prob_next_node).sample() # size(query)=(bsz,)
# compute logprobs of the action items in the list sumLogProbOfActions
ProbOfChoices = prob_next_node[zero_to_bsz, idx]
sumLogProbOfActions.append( torch.log(ProbOfChoices) ) # size(query)=(bsz,)
# update embedding of the current visited node
h_t = h_encoder[zero_to_bsz, idx, :] # size(h_start)=(bsz, dim_emb)
h_t = h_t + self.PE[t+1].expand(bsz, self.dim_emb)
# update tour
tours.append(idx)
# update masks with visited nodes
mask_visited_nodes = mask_visited_nodes.clone()
mask_visited_nodes[zero_to_bsz, idx] = True
# logprob_of_choices = sum_t log prob( pi_t | pi_(t-1),...,pi_0 )
sumLogProbOfActions = torch.stack(sumLogProbOfActions,dim=1).sum(dim=1) # size(sumLogProbOfActions)=(bsz,)
# convert the list of nodes into a tensor of shape (bsz,num_cities)
tours = torch.stack(tours,dim=1) # size(col_index)=(bsz, nb_nodes)
return tours, sumLogProbOfActions
训练
本文采用强化学习的方式进行训练,baseline采用贪心算法,训练模型采用概率采样,思路类似于《ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!》
训练步骤:
for epoch in range(0,args.nb_epochs):
----for step in range(1,args.nb_batch_per_epoch+1)
--------随机生成数据集(bsz, nb_nodes, 2)
--------得到baseline和训练模型在该数据集上的结果
--------计算二者路径总和得到 loss,优化训练参数
----评价模型:for step in range(0,args.nb_batch_eval):
--------随机生成数据集(bsz, nb_nodes, 2)
--------得到baseline和训练模型在该数据集上的结果
--------计算二者路径总和相对比,如果训练模型优于baseline,用训练的参数代替baseline现有参数
for epoch in range(0,args.nb_epochs):
# re-start training with saved checkpoint
epoch += epoch_ckpt
###################
# Train model for one epoch
###################
start = time.time()
model_train.train()
for step in range(1,args.nb_batch_per_epoch+1):
# generate a batch of random TSP instances
x = torch.rand(args.bsz, args.nb_nodes, args.dim_input_nodes, device=device) # size(x)=(bsz, nb_nodes, dim_input_nodes)
# compute tours for model
tour_train, sumLogProbOfActions = model_train(x, deterministic=False) # size(tour_train)=(bsz, nb_nodes), size(sumLogProbOfActions)=(bsz)
# compute tours for baseline
with torch.no_grad():
tour_baseline, _ = model_baseline(x, deterministic=True)
# get the lengths of the tours
L_train = compute_tour_length(x, tour_train) # size(L_train)=(bsz)
L_baseline = compute_tour_length(x, tour_baseline) # size(L_baseline)=(bsz)
# backprop
loss = torch.mean( (L_train - L_baseline)* sumLogProbOfActions )
optimizer.zero_grad()
loss.backward()
optimizer.step()
time_one_epoch = time.time()-start
time_tot = time.time()-start_training_time + tot_time_ckpt
###################
# Evaluate train model and baseline on 10k random TSP instances
###################
model_train.eval()
mean_tour_length_train = 0
mean_tour_length_baseline = 0
for step in range(0,args.nb_batch_eval):
# generate a batch of random tsp instances
x = torch.rand(args.bsz, args.nb_nodes, args.dim_input_nodes, device=device)
# compute tour for model and baseline
with torch.no_grad():
tour_train, _ = model_train(x, deterministic=True)
tour_baseline, _ = model_baseline(x, deterministic=True)
# get the lengths of the tours
L_train = compute_tour_length(x, tour_train)
L_baseline = compute_tour_length(x, tour_baseline)
# L_tr and L_bl are tensors of shape (bsz,). Compute the mean tour length
mean_tour_length_train += L_train.mean().item()
mean_tour_length_baseline += L_baseline.mean().item()
mean_tour_length_train = mean_tour_length_train/ args.nb_batch_eval
mean_tour_length_baseline = mean_tour_length_baseline/ args.nb_batch_eval
# evaluate train model and baseline and update if train model is better
update_baseline = mean_tour_length_train+args.tol < mean_tour_length_baseline
if update_baseline:
model_baseline.load_state_dict( model_train.state_dict() )
# Compute TSPs for small test set
# Note : this can be removed
with torch.no_grad():
tour_baseline, _ = model_baseline(x_1000tsp, deterministic=True)
mean_tour_length_test = compute_tour_length(x_1000tsp, tour_baseline).mean().item()
# For checkpoint
plot_performance_train.append([ (epoch+1), mean_tour_length_train])
plot_performance_baseline.append([ (epoch+1), mean_tour_length_baseline])
# Compute optimality gap
if args.nb_nodes==50: gap_train = mean_tour_length_train/5.692- 1.0
elif args.nb_nodes==100: gap_train = mean_tour_length_train/7.765- 1.0
else: gap_train = -1.0
# Print and save in txt file
mystring_min = 'Epoch: {:d}, epoch time: {:.3f}min, tot time: {:.3f}day, L_train: {:.3f}, L_base: {:.3f}, L_test: {:.3f}, gap_train(%): {:.3f}, update: {}'.format(
epoch, time_one_epoch/60, time_tot/86400, mean_tour_length_train, mean_tour_length_baseline, mean_tour_length_test, 100*gap_train, update_baseline)
print(mystring_min) # Comment if plot display
file.write(mystring_min+'\n')
# all_strings.append(mystring_min) # Uncomment if plot display
# for string in all_strings:
# print(string)
# Saving checkpoint
checkpoint_dir = os.path.join("checkpoint")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
torch.save({
'epoch': epoch,
'time': time_one_epoch,
'tot_time': time_tot,
'loss': loss.item(),
'TSP_length': [torch.mean(L_train).item(), torch.mean(L_baseline).item(), mean_tour_length_test],
'plot_performance_train': plot_performance_train,
'plot_performance_baseline': plot_performance_baseline,
'mean_tour_length_test': mean_tour_length_test,
'model_baseline': model_baseline.state_dict(),
'model_train': model_train.state_dict(),
'optimizer': optimizer.state_dict(),
}, '{}.pkl'.format(checkpoint_dir + "/checkpoint_" + time_stamp + "-n{}".format(args.nb_nodes) + "-gpu{}".format(args.gpu_id)))
实验
测试过程中采用的是beam search搜索,相较于其它算法,文中的模型效果最佳,误差最小。