NLP学习—10.循环神经网络RNN与LSTM、GRU、双向LSTM以及基于PyTorch的代码实现
文章目录
-
-
- 一、为什么需要循环神经网络?
- 二、RNN的原理
- 三、RNN的类型
- 四、RNN存在的问题
- 五、LSTM/GRU
- 六、Gated Recurrent Unit—GRU
- 七、BI-LSTM
-
- 1.双向LSTM的模型代码实现
- 2.双向LSTM+Attention的模型代码实现
- 八、Deep-BILSTM
-
一、为什么需要循环神经网络?
虽然全连接神经网络理论上只要训练数据足够,给定特定的x,就能得到希望的y,但是全连接神经网络只能处理独立的输入,前一个输入和后一个输入是完全没有关系的。针对某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的情况,此时,就需要用到循环神经网络RNN,该神经网络能够很好的处理序列信息。
标准的全连接神经网络(fully connected neural network)处理序列数据会有两个问题:
1)全连接神经网络输入层和输出层长度固定,而不同序列的输入、输出可能有不同的长度,选择最大长度并对短序列进行填充(pad)不是一种很好的方式;
2)全连接神经网络同一层的节点之间是无连接的,当需要用到序列之前时刻的信息时,全连接神经网络无法做到,一个序列的不同位置之间无法共享特征。
二、RNN的原理
参考于一文搞懂RNN(循环神经网络)基础篇
一个简单的循环神经网络,它由输入层、隐藏层(单个)、输出层构成。
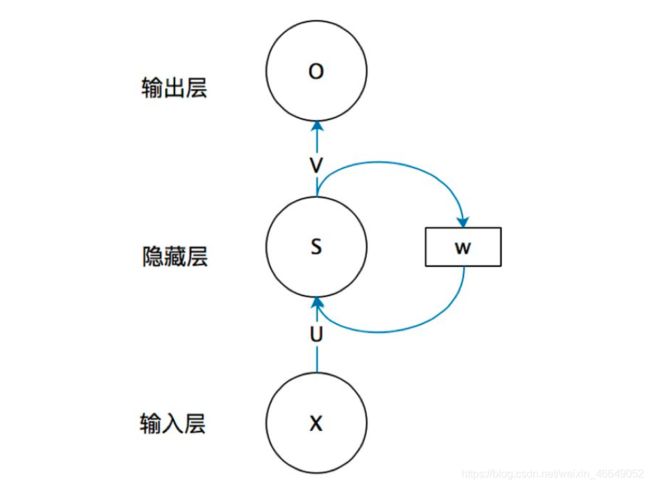
x是输入层的值
U是输入层到隐藏层的权重矩阵
s是隐藏层的值
权重矩阵 W就是上一个时刻隐藏层的值作为这一时刻的输入的权重。循环神经网络的隐藏层的值s不仅仅取决于当前时刻的输入x,还取决于前一时刻隐藏层的值s。
V是隐藏层到输出层的权重矩阵
注意事项:参数 U 、 V 、 W U、V、W U、V、W在RNN中是共享的。
下图展示了上一时刻的隐藏层是如何影响当前时刻的隐藏层的。
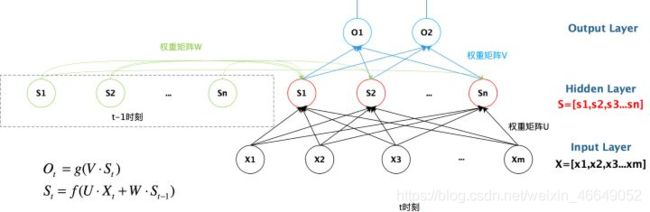
循环神经网络时间线展开图为:
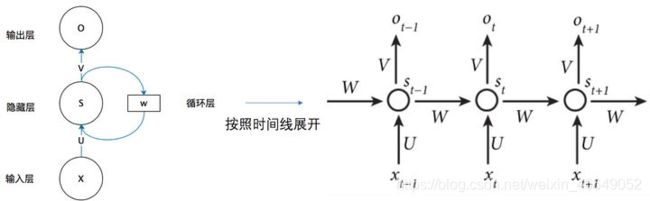
这个网络在t时刻接收到输入 x t x_t xt 之后,隐藏层的值是 s t s_t st ,输出值是 o t o_t ot 。 s t s_t st的值不仅仅取决于 x t x_t xt,还取决于 s t − 1 s_{t-1} st−1。
循环神经网络计算方法用公式表示为:
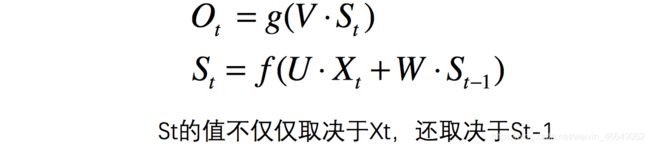
此处的 g g g在分类中为softmax函数。
下图展示了一个最简单的使用单个全连接层作为循环体 A 的 RNN。图中黄色的 tanh 小方框表示一个使用 tanh 作为激活函数的全连接层。
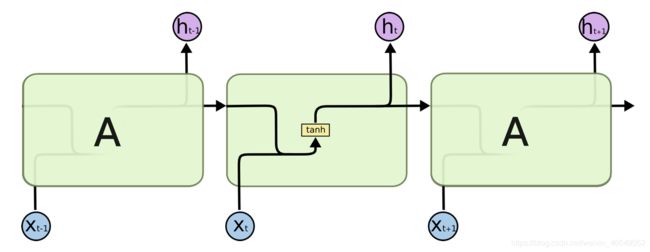
t t t时刻循环体 A 的输入包括 X t X_t Xt和从 t − 1 t-1 t−1时刻传递来的隐藏状态 h t − 1 h_{t-1} ht−1。循环体 A 的两部分输入如何处理呢?将 X t X_t Xt和 h t − 1 h_{t-1} ht−1直接拼接起来,成为一个更大的矩阵/向量 [ X t X_t Xt, h t − 1 h_{t-1} ht−1]。假设 X t X_t Xt 和 h t − 1 h_{t-1} ht−1的形状分别为 [1, 3] 和 [1, 4],则最后循环体 A 中全连接层输入向量的形状为 [1, 7]。拼接完后按照全连接层的方式进行处理即可。
RNN前向传播如图所示:
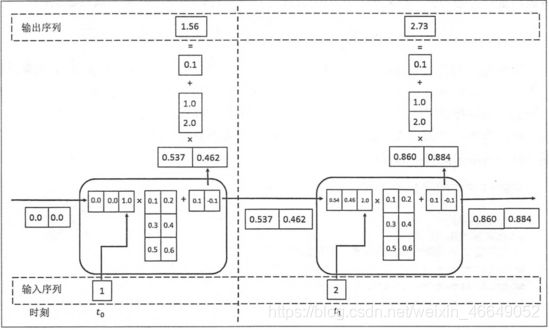
- RNN可以用于训练语言模型 ,一个词预测下一个词的概率(非常稀疏的高维向量,和为1)并可以经过交叉熵进行优化。已经训练好的RNN模型,可以生成一些文本。这个可以称为decoding。
三、RNN的类型
使用RNN解决特定的问题,根据不同的问题,我们可以定义出不同类型的RNN。
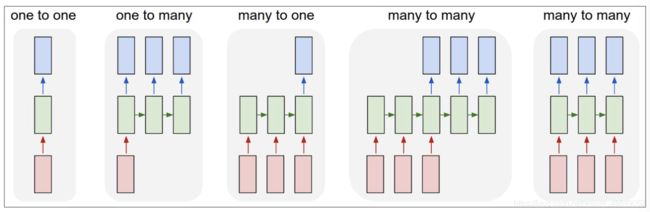
- one to one:其实和全连接神经网络并没有什么区别,这一类别算不得是 RNN。
- one to many:输入不是序列,输出是序列。输入是静态的数据,输出是动态的数据,这种模型可以用于输入图片根据RNN模型生成图片表示内容,即文本生成。
- many to one:输入是序列,输出不是序列。这种模型适用于文本分类(情感分析)任务或者图片生成任务。
- many to many:输入和输出都是序列,但两者长度可以不一样,这种模型可以用于机器翻译,文案生成,自动生成摘要。
- many to many:输出和输出都是序列,两者长度一样,这种模型可以用于词性标注或者股票预测。
四、RNN存在的问题
单向 RNN 的缺点是在 t t t 时刻,无法使用 t + 1 t+1 t+1 及之后时刻的序列信息,所以就有了双向循环神经网络。理论上循环神经网络可以支持任意长度的序列,然而在实际中,如果序列过长会导致优化时出现梯度消散的问题(the vanishing gradient problem),所以实际中一般会规定一个最大长度,当序列长度超过规定长度之后会对序列进行截断。RNN 面临的一个技术挑战是长期依赖(long-term dependencies)问题,即当前时刻无法从序列中间隔较大的那个时刻获得需要的信息。在理论上,RNN 完全可以处理长期依赖问题,但实际处理过程中,RNN 表现得并不好。但是 GRU 和 LSTM 可以处理梯度消散问题和长期依赖问题。
RNN纵向维度可能出现梯度消散与梯度爆炸问题,RNN在时间维度可能产生长期依赖问题(本质上也是梯度消散与梯度爆炸问题,梯度的问题导致了长期依赖问题)。针对于RNN的梯度问题,

可抽象为 W R W_R WR的 k k k次方,当 W R W_R WR较小时,梯度弥散。当 W R W_R WR较大时,梯度爆炸。针对梯度爆炸问题,解决方案是引入Gradient Clipping(梯度裁剪)。通过Gradient Clipping,将梯度约束在一个范围内,这样不会使得梯度过大。针对梯度消失与长期依赖问题,GRU 和 LSTM 可以处理梯度消散问题和长期依赖问题。GRU 和 LSTM只能缓解梯度消失问题。
五、LSTM/GRU
在实际建模中,RNN 经常出现梯度爆炸或梯度消失等问题,因此我们一般使用长短期记忆单元或门控循环单元代替基本的 RNN 循环体。它们引入了门控机制以遗忘或保留特定的信息而加强模型对长期依赖关系的捕捉,它们同时也大大缓解了梯度爆炸或梯度消失的问题。循环网络的每一个隐藏层都有多个循环单元,隐藏层 h t − 1 h_{t-1} ht−1的向量储存了所有该层神经元在 t − 1 t-1 t−1步的激活值。一般标准的循环网络会将该向量通过一个仿射变换并添加到下一层的输入中,即 W ∗ h t − 1 + U ∗ X t W* h_{t-1}+U* X_t W∗ht−1+U∗Xt。而这个简单的计算过程由于重复使用 W W W 和 U U U 而会造成梯度爆炸或梯度消失。因此我们可以使用门控机制控制前一时间步隐藏层保留的信息和当前时间步输入的信息,并选择性地输出一些值而作为该单元的激活值。 之所以叫“门”结构,是因为使用 s i g m o i d sigmoid sigmoid作为激活函数的全连接神经网络层会输出一个 0 到 1 之间的数值,描述当前输入有多少信息量可以通过这个结构。于是这个结构的功能就类似于一扇门,当门打开时(sigmoid 全连接层输出为 1 时),全部信息可以通过;当门关上时(sigmoid 神经网络层输出为 0 时),任何信息都无法通过。
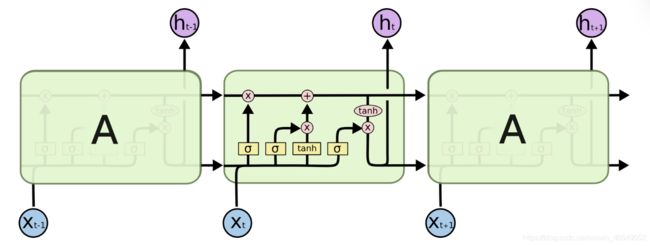
LSTM 有三个门,分别是“遗忘门”(forget gate)、“输入门”(input gate)和“输出门”(output gate)。
“遗忘门”的作用是让循环神经网络“忘记”之前没有用的信息,控制以前记忆的信息到底需要保留多少
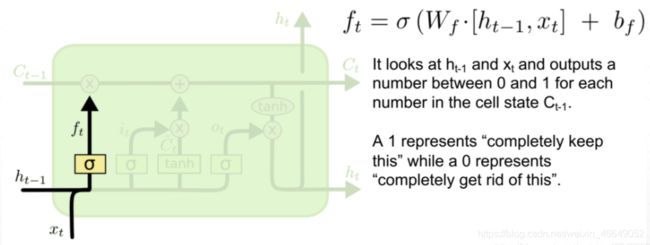
“输入门”决定哪些信息进入当前时刻的状态,分为以前保留的信息加上当前输入有意义的信息
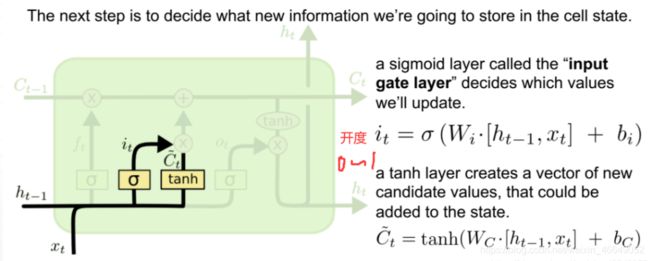
通过“遗忘门”和“输入门”,LSTM 结构可以很有效地决定哪些信息应该被遗忘,哪些信息应该得到保留。且更新当前时刻状态Ct,输入与输入门对应元素相乘表示当前时刻需要添加到Ct的记忆,前一时间步的记忆 Ct-1 与遗忘门 ft 对应元素相乘就表示了需要保留或遗忘的历史信息是多少,最后将这两部分的信息相加在一起就更新了记忆Ct的信息。
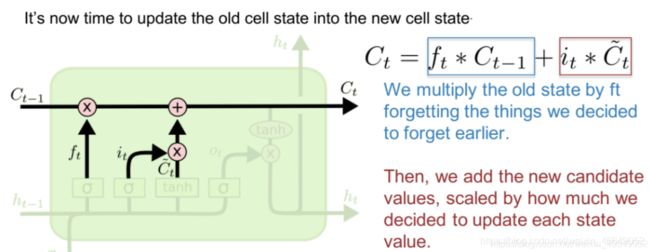
LSTM 在得到当前时刻状态 Ct 之后,需要产生当前时刻的输出,该过程通过“输出门”完成。
LSTM 的内部状态向量并不会直接用于输出,这一点和基础的RNN 不一样。基础的RNN 网络的状态向量 既用于记忆,又用于输出,所以基础的RNN 可以理解为状态向量和输出向量 是同一个对象。在LSTM 内部,状态向量并不会全部输出,而是在输出门的作用下有选择地输出。
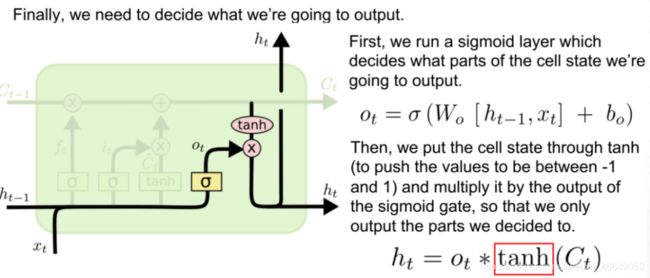
LSTM计算公式总结如下:
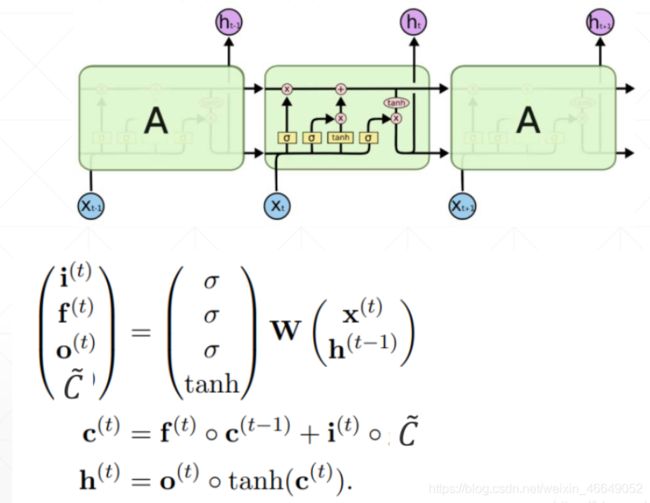
三个门总结:遗忘门控制以前的输入,输入门控制当前的输入,输出门产生当前时刻的输出。
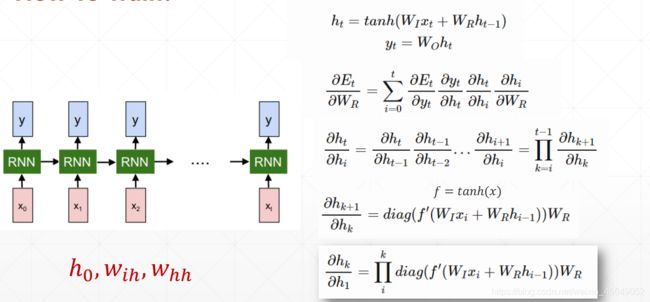
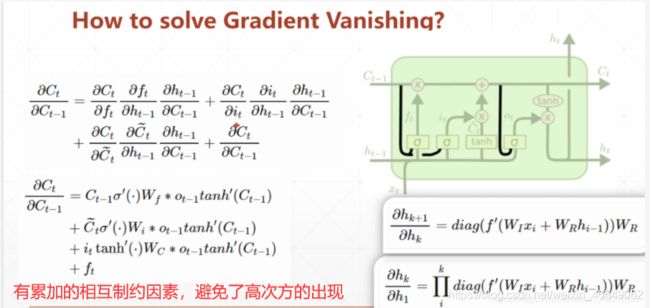
直观比较LSTM与RNN的梯度求导,会发现
RNN中有权重的n次方,易出现梯度弥散与梯度爆炸
而LSTM中是权重的累加,几个门的相互制约不会出现梯度弥散与梯度爆炸现象
六、Gated Recurrent Unit—GRU
LSTM 具有更长的记忆能力,在大部分序列任务上面都取得了比基础的RNN 模型更好的性能表现,更重要的是,LSTM 不容易出现梯度弥散现象。但是LSTM 结构相对较复杂,计算代价较高,模型参数量较大。因此,科学家们尝试简化LSTM 内部的计算流程,特别是减少门控数量。研究发现,遗忘门是LSTM 中最重要的门控 ,甚至发现只有遗忘门的简化版网络在多个基准数据集上面优于标准LSTM 网络。在众多的简化版LSTM中,门控循环网络(Gated Recurrent Unit,简称GRU)是应用最广泛的RNN 变种之一。GRU把内部状态向量和输出向量合并,统一为状态向量 ,门控数量也减少到2 个:复位门(Reset Gate)和更新门(Update Gate)。
GRU 的两个门:一个是“更新门”(update gate),它将 LSTM 的“遗忘门”和“输入门”融合成了一个“门”结构;另一个是“重置门”(reset gate)。
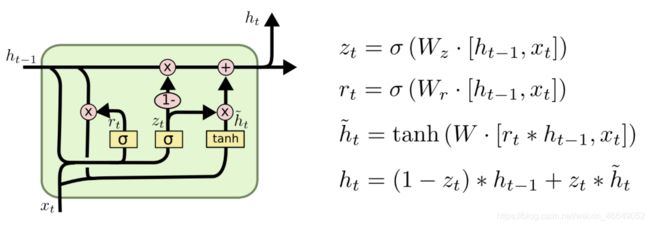
这两个门控机制的特殊之处在于,它们能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。使用门控机制学习长期依赖关系的基本思想和 LSTM 一致,但还是有一些关键区别:
- GRU 有两个门(重置门与更新门),而 LSTM 有三个门(输入门、遗忘门和输出门)。
- GRU 并不会控制并保留内部记忆 ( c t ) (c_t) (ct),且没有 LSTM 中的输出门。
- LSTM 中的输入与遗忘门对应于 GRU 的更新门,重置门直接作用于前面的隐藏状态。
重置门强制隐藏状态遗忘一些历史信息,并利用当前输入的信息。这可以令隐藏状态遗忘任何在未来发现与预测不相关的信息,同时也允许构建更加紧致的表征。而更新门将控制前面隐藏状态的信息有多少会传递到当前隐藏状态,这与 LSTM 网络中的记忆单元非常相似,它可以帮助 RNN 记住长期信息。由于每个单元都有独立的重置门与更新门,每个隐藏单元将学习不同尺度上的依赖关系。那些学习捕捉短期依赖关系的单元将趋向于激活重置门,而那些捕获长期依赖关系的单元将常常激活更新门。
七、BI-LSTM
诸如在词性标注下游任务中,我们不仅考虑上文信息,而且还要考虑下文信息,此时,就需要双向LSTM。双向LSTM可以理解为同时训练两个LSTM,两个LSTM的方向、参数都不同。当前时刻的 h t h_t ht就是将两个方向不同的LSTM得到的两个 h t h_t ht向量拼接到一起。我们使用双向LSTM捕捉到当前时刻 t t t的过去和未来的特征。通过反向传播来训练双向LSTM网络。
如果是双向LSTM+Attention,这里是静态的Attention,则网络结构如下:
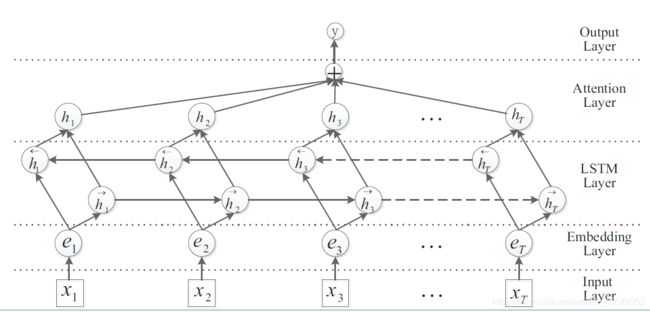 h t h_t ht是每一个词的hidden state,而 h s ‾ \overline{h_s} hs是向量,开始是随机生成的,后面经过反向传播可以得到 ∂ L o s s ∂ h s ‾ \frac{\partial{Loss}}{\partial{\overline{h_s}}} ∂hs∂Loss,通过梯度不断迭代更新,得到标准。
h t h_t ht是每一个词的hidden state,而 h s ‾ \overline{h_s} hs是向量,开始是随机生成的,后面经过反向传播可以得到 ∂ L o s s ∂ h s ‾ \frac{\partial{Loss}}{\partial{\overline{h_s}}} ∂hs∂Loss,通过梯度不断迭代更新,得到标准。
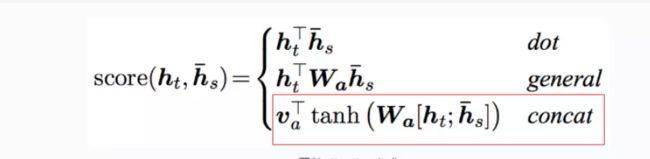
score是标量。每句话进行拼接,然后做softmax得到概率,然后对hidden state进行加权平均,得到总向量,然后经过一个分类层,经softmax得到每一个类别的得分。
1.双向LSTM的模型代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, pretrained_weight, update_w2v, hidden_dim,
num_layers, drop_keep_prob, n_class, bidirectional, **kwargs):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim # 隐藏层节点数
self.num_layers = num_layers # 神经元层数
self.n_class = n_class # 类别数
self.bidirectional = bidirectional # 控制是否为双向LSTM
self.embedding = nn.Embedding.from_pretrained(pretrained_weight) # 读取预训练好的参数
self.embedding.weight.requires_grad = update_w2v # 控制加载的预训练模型在训练中参数是否更新
# LSTM
self.encoder = nn.LSTM(input_size=embedding_dim, hidden_size=self.hidden_dim,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=drop_keep_prob)
# 解码部分
if self.bidirectional:
self.decoder1 = nn.Linear(hidden_dim * 4, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
else:
self.decoder1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
def forward(self, inputs):
"""
前向传播
:param inputs: [batch, seq_len]
:return:
"""
# [batch, seq_len] => [batch, seq_len, embed_dim][64,75,50]
embeddings = self.embedding(inputs)
# [batch, seq_len, embed_dim] = >[seq_len, batch, embed_dim]
# 这里要结合batch_first参数的设置
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
# 张量拼接[32,512]
encoding = torch.cat([states[0], states[-1]], dim=1)
# 解码
outputs = self.decoder1(encoding)
# outputs = F.softmax(outputs, dim=1)
outputs = self.decoder2(outputs)
return outputs
2.双向LSTM+Attention的模型代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTM_attention(nn.Module):
def __init__(self, vocab_size, embedding_dim, pretrained_weight, update_w2v, hidden_dim,
num_layers, drop_keep_prob, n_class, bidirectional, **kwargs):
super(LSTM_attention, self).__init__()
self.hidden_dim = hidden_dim # 隐藏层节点数
self.num_layers = num_layers # 神经元层数
self.n_class = n_class # 类别数
self.bidirectional = bidirectional # 控制是否双向LSTM
self.embedding = nn.Embedding.from_pretrained(pretrained_weight) # 读取预训练好的参数
self.embedding.weight.requires_grad = update_w2v # 控制加载的预训练模型在训练中参数是否更新
# LSTM
self.encoder = nn.LSTM(input_size=embedding_dim, hidden_size=self.hidden_dim,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=drop_keep_prob,batch_first=True)
# weiht_w即为公式中的h_s(参考系)
# nn. Parameter的作用是参数是需要梯度的
self.weight_W = nn.Parameter(torch.Tensor(2 * hidden_dim, 2 * hidden_dim))
self.weight_proj = nn.Parameter(torch.Tensor(2 * hidden_dim, 1))
# 对weight_W、weight_proj进行初始化
nn.init.uniform_(self.weight_W, -0.1, 0.1)
nn.init.uniform_(self.weight_proj, -0.1, 0.1)
if self.bidirectional:
# self.decoder1 = nn.Linear(hidden_dim * 2, n_class)
self.decoder1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
else:
self.decoder1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
def forward(self, inputs):
"""
前向传播
:param inputs: [batch, seq_len]
:return:
"""
# 编码
embeddings = self.embedding(inputs) # [batch, seq_len] => [batch, seq_len, embed_dim][64,75,50]
# 经过LSTM得到输出,state是一个输出序列
states, hidden = self.encoder(embeddings.permute([0, 1, 2])) # [batch, seq_len, embed_dim]
# attention
# states与self.weight_W矩阵相乘,然后做tanh
u = torch.tanh(torch.matmul(states, self.weight_W))
# u与self.weight_proj矩阵相乘,得到score
att = torch.matmul(u, self.weight_proj)
# softmax
att_score = F.softmax(att, dim=1)
# 加权求和
scored_x = states * att_score
encoding = torch.sum(scored_x, dim=1)
# 线性层
outputs = self.decoder1(encoding)
outputs = self.decoder2(outputs)
return outputs
其中代码实现中的score与上述公式略有不同:
s c o r e ( h t , h s ‾ ) = w p r o j T t a n h ( h t T h s ‾ ) score(h_t,\overline{h_s})=w_{proj}^Ttanh(h_t^T\overline{h_s}) score(ht,hs)=wprojTtanh(htThs)
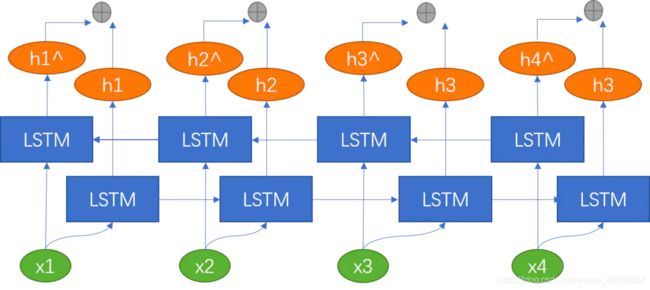
八、Deep-BILSTM
Deep-BILSTM可以理解为同时训练两个深度的LSTM,然后将两个深度的LSTM拼接到一起。在词性标注领域、命名实体识别领域用的较多。
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!
