CVPR 2022 | HorNet:递归门控卷积的高效高阶空间相互作用

论文:
https://arxiv.org/abs/2207.14284
源码:
https://github.com/raoyongming/HorNet
本文提出了递归门控卷积 g n C o n v g_{n}Conv gnConv, g n C o n v g_{n}Conv gnConv通过门控卷积和递归设计执行高效的、可扩展的、平移等效的高阶空间相互作用。
在此基础上,作者构建了一个新的通用视觉骨架网络HorNet,并且使用大量的实验证明了 g n C o n v gnConv gnConv和HorNet在常用的视觉识别baseline上的有效性。
1 Motivation
在深度学习领域,CNN的引入大幅推动了计算机视觉的发展。由于CNN本身固有的一些特性,使得其能够自然地应用到广泛的视觉任务中,例如translation equivariance为视觉任务引入了有效的归纳偏置(inductive biases),实现了不同分辨率特征图之间的可转移性;例如从VGG到ResNet及其以后的各类骨干网络进一步促进了CNN在视觉任务中的普及程度。
但是Vision Transformer通过结合CNN一些成功的经验,在各类视觉任务中都表现出了不错的性能,极大的挑战了CNN在视觉领域的主导地位。于是我们不禁思考:是什么让Vision Transformer有如此强大性能?我们能否借鉴Vision Transformer中的成功经验,重新设计新的CNN架构?
ConvNeXt通过对ViT的元架构(meta architecture)分析,提出使用 7 ∗ 7 7*7 7∗7的卷积核来加强长距离(long-range)关系的学习,更有部分文献直接采用高达 31 ∗ 31 31*31 31∗31的卷积核来学习长距离依赖;[1]则表明权值输入自适应(input-adaptive weights)也在Vision Transformer中起着重要作用,像SwinTransformer就是利用动态卷积在一系列下游任务中取得较好效果的。以上两点其实都是Transformer成功的原因,但是作者指出:由于非线性的原因,深层模型中两个空间位置之间往往存在复杂的高阶交互作用,并且self-attention等动态网络的成功表明,模型架构设计中引入的显式的高阶空间交互作用有利于提高视觉模型的建模能力,于是作者指出了第三点同样重要的特性:高阶空间交互(high-order spatial interaction)作用。
2 Intro
所谓的空间交互作用,大体意思就是在特征图采样过程中通过额外的或者自身的某种计算,将空间的相互性加入到生成的特征中,例如Transformer中就利用不同的变换生成Q和K进而进行空间位置相关性的计算。那如何理解这里的高阶空间交互作用?我们来看一下原文中的示意图。
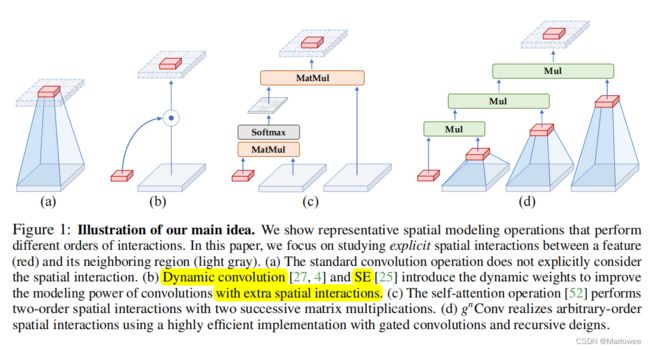
如上图所示,(a)所代表的普通卷积没有显示考虑空间位置(红色特征区域)与其相邻区域(灰色区域)之间的空间交互;(b)代表的是动态卷积或者以SE为代表的视觉注意力方法,通过额外的特征计算生成动态权值引入显式的空间交互;(c)则表示Transformer中self-attention机制的过程,此过程在Q、K、V之间执行矩阵乘法,整体过程是二阶空间交互(Q与K交互后再与V交互);(d)则是本文所提出的 g n C o n v g_{n}Conv gnConv模块,通过增加通道宽度的设计实现了具有有限复杂性的高阶空间交互。
在本文中,作者总结了Vision Transformer成功的三大法宝是通过self-attention实现输入自适应(input-adaptive)、远距离(long-range)和高阶空间交互(hige-order spatial interaction)的空间建模新方法。虽然之前的工作已经成功地将Vision Transformer的元架构、输入自适应权值生成策略和大范围建模能力迁移到CNN模型中,但尚未对高阶空间交互机制进行研究。
作者指出三个关键因素都可以使用基于卷积的框架有效地实现,并提出了用门控卷积和递归设计执行高阶空间相互作用的递归门控卷积 ( g n C o n v ) (g_{n}Conv) (gnConv)。 g n C o n v g_{n}Conv gnConv模块不是简单地模仿自我注意方面的成功设计,并且具有自身的优点:
1)高效。基于卷积的实现避免了self-attention的二次复杂度,在执行空间交互过程中逐步增加通道宽度的设计也使其能够实现具有有限复杂性的高阶交互;
2)可扩展。将自注意中的二阶相互作用扩展到任意阶,进一步提高了建模能力,并且 g n C o n v g_{n}Conv gnConv兼容各种内核大小和空间混合策略;
3))Translation-equivariant。 g n C o n v g_{n}Conv gnConv充分继承了标准卷积的Translation-equivariant特性,为主要视觉任务引入了有益的归纳偏差,避免了局部注意带来的不对称。
3 Method
g n C o n v g_{n}Conv gnConv是用标准卷积、线性投影和元素乘法(哈达玛积)构建的,但具有与自我注意类似的输入自适应空间混合功能,接下来主要从公式演绎、模块结构及源码两个方面描述一下我对 g n C o n v g_{n}Conv gnConv的理解。
3.1 g n C o n v g_{n}Conv gnConv:Recursive Gated Convolutions
一阶空间交互:在CNN中,网络主要使用静态的卷积核来聚合相邻特征,而Vision Transformer则使用multi-head self-attention(MSA)动态聚合空间的token权重,但是过程中的平方复杂度和self-attention的输入大小很大程度上限制了Vision Transformer的应用,作者则通过使用卷积核全连接层这样的简单操作实现了同等效力的空间交互,该方法的基本模块是门控卷积( g n C o n v g_{n}Conv gnConv)。设 x ∈ R H W × C x\in\mathbb{R}^{HW\times C} x∈RHW×C是门控卷积的输入特征,那么其输出 y = g n C o n v ( x ) y=g_{n}Conv(x) y=gnConv(x)可表示为: [ p 0 H W × C , q 0 H W × C ] = ϕ ( x ) ∈ R H W × 2 C , p 1 = f ( q 0 ) ⊙ p 0 ∈ R H W × C , y = ϕ ( p 1 ) ∈ R H W × C (3.1) \begin{split}[p_{0}^{HW\times C},q_{0}^{HW×C}]=\phi(x)\in\mathbb{R}^{HW\times 2C},\\ p_{1}=f(q_{0})\odot p_{0}\in\mathbb{R}^{HW\times C},\\y=\phi(p_{1})\in\mathbb{R}^{HW\times C}\end{split}\tag{3.1} [p0HW×C,q0HW×C]=ϕ(x)∈RHW×2C,p1=f(q0)⊙p0∈RHW×C,y=ϕ(p1)∈RHW×C(3.1)公式 ( 3.1 ) (3.1) (3.1)是将输入 x x x经过线性投影后按照channel切分得到 p 0 p_{0} p0和 q 0 q_{0} q0,然后经过深度卷积计算后的 q 0 q_{0} q0再与 p 0 p_{0} p0做点积得到 p 1 p_{1} p1, p 1 p_{1} p1会经过另一个线性投影得到输出 y y y,上述过程演示的就是一阶空间交互,通过元素乘法显式引入了相邻特征 p 0 p_{0} p0和 q 0 q_{0} q0之间的相互作用。
高阶空间交互:上述过程演示了一阶空间交互,其实高阶的空间交互也是同理:首先使用线性投影函数 ϕ \phi ϕ得到一组投影特征 p 0 p_{0} p0和 { q k } k = 0 n − 1 \{q_{k}\}_{k=0}^{n-1} {qk}k=0n−1: [ p 0 H W × C 0 , q 0 H W × C 0 , . . . , q n − 1 H W × C n − 1 ] = ϕ i n ( x ) ∈ R H W × ( C 0 + ∑ 0 ≤ k ≤ n − 1 C k ) (3.2) \begin{split} [p_{0}^{HW\times C_{0}},q_{0}^{HW\times C_{0}},...,q_{n-1}^{HW\times C_{n-1}}]=\phi_{in}(x)\in \mathbb{R}^{HW\times (C_{0}+\sum_{0\leq k\leq n-1}C_{k})}\end{split}\tag{3.2} [p0HW×C0,q0HW×C0,...,qn−1HW×Cn−1]=ϕin(x)∈RHW×(C0+∑0≤k≤n−1Ck)(3.2)这个公式主要是将输入特征按照通道进行切分,解释起来确实很抽象,这里先按下不表,等到后面讲代码的时候再仔细说说。利用公式 ( 3.2 ) (3.2) (3.2)得到切分的特征后,我们就可以将其依次输入到门控卷积中进行递归运算: p k + 1 = f k ( q k ) ⊙ g k ( p k ) / α k = 0 , 1 , . . . , n − 1 (3.3) p_{k+1}=f_{k}(q_{k})\odot g_{k}(p_{k})/\alpha \qquad k=0,1,...,n-1\tag{3.3} pk+1=fk(qk)⊙gk(pk)/αk=0,1,...,n−1(3.3)公式 ( 3.3 ) (3.3) (3.3)将每次运算中的输出特征按照 1 / α 1/\alpha 1/α进行缩放来使训练更平稳,由于进行空间交互作用的过程中要保证二者维度相同,所以 g k g_{k} gk是运算过程中的维度映射函数: g k = { I d e n t i t y , k = 0 , L i n e a r ( C k − 1 , C k ) 1 ≤ k ≤ n − 1. (3.4) g_{k}=\begin{cases} Identity ,\qquad \qquad \qquad \qquad k=0,\\ Linear(C_{k-1},C_{k}) \qquad 1\leq k\leq n-1.\end{cases}\tag{3.4} gk={Identity,k=0,Linear(Ck−1,Ck)1≤k≤n−1.(3.4)最后,网络将最终的递归输出 q n q_{n} qn输入到投影层 ϕ ( o u t ) \phi(out) ϕ(out),得到 g n C o n v g_{n}Conv gnConv的最终结果。由递归公式 ( 3.3 ) (3.3) (3.3)可以看出,每一步 p k p_{k} pk的交互顺序都会增加1,这其实也是 g n C o n v g_{n}Conv gnConv实现n阶空间交互的主要方式。值得注意的是,这里只需要一个 f f f将 { q k } k = 0 n − 1 \{q_{k}\}_{k=0}^{n-1} {qk}k=0n−1的特征串在一起进行深度卷积,而不是像式 ( 3.3 ) (3.3) (3.3)那样在每个递归步骤中计算卷积,并且这可以进一步简化实现,提高gpu上的效率。此外,为了确保高阶交互运算不会引入太多的运算消耗,作者也对每一阶的通道数进行的约束: C k = C 2 n − k − 1 0 ≤ k ≤ n − 1 (3.5) C_{k}=\frac{C}{2^{n-k-1}}\qquad 0\leq k \leq n-1 \tag{3.5} Ck=2n−k−1C0≤k≤n−1(3.5)这种设计促使网络进行coarse-to-fine的交互,其中较低阶数的特征用更少的通道进行计算,高阶的特征则需要映射到高纬度的特征上去学习更丰富的模式。并且,这里将输入特征的通道映射到了 2 C 2C 2C,即使 n n n(阶数,下文源码中的参数order)增加,总运算量也是有上界的(相关证明细节见附录A),即: F L O P s ( g n C o n v ) < H W C ( 2 K 2 + 11 / 3 × C + 2 ) (3.6) FLOPs(g_{n}Conv)
3.2 Code and Architecture for g n C o n v g_{n}Conv gnConv
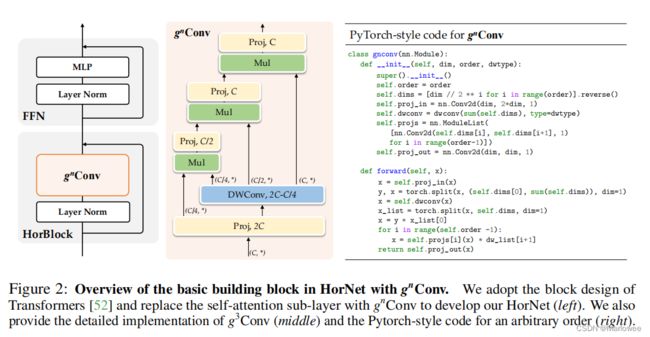
上图所代表的模块是三阶空间交互的图示,即 g 3 C o n v g^{3}Conv g3Conv,其实就把 g n C o n v g_{n}Conv gnConv的模块细节和源码完整地展示出来了,接下来具体展开介绍一下。首先,我们来看构造函数init()内部定义的几个重要参数和模块:
| Para | Meaning |
|---|---|
| oder | 空间交互的最大阶数,即n |
| dim | 将2C在不同阶的空间上进行切分后的维度,对应公式3.2 |
| proj_in | 输入x的线性映射层,对应 ϕ ( i n ) \phi(in) ϕ(in) |
| dwconv | 深度可分离卷积模块,用于特征提取 |
| projs | 高阶空间交互过程中使用的卷积模块,对应公式3.4 |
| proj_out | 输出y的线性映射层,对应 ϕ ( o u t ) \phi(out) ϕ(out) |
这里贴一下作者在Github上放出的源码,内部相关细节我都做了注释,并且已经调试好了 g n C o n v g_{n}Conv gnConv模块的demo,读者可自行运行探究具体参数的意义。
import torch
import torch.nn as nn
def get_dwconv(dim, kernel, bias):
return nn.Conv2d(dim, dim, kernel_size=kernel, padding=(kernel-1)//2 ,bias=bias, groups=dim)
class gnconv(nn.Module):
def __init__(self, dim, order=3, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order# 空间交互的阶数,即n
self.dims = [dim // 2 ** i for i in range(order)]# 将2C在不同阶的空间上进行切分,对应公式3.2
self.dims.reverse()# 反序,使低层通道少,高层通道多
self.proj_in = nn.Conv2d(dim, 2* dim, 1)# 输入x的线性映射层,对应$\phi(in)$
if gflayer is None:# 是否使用Global Filter
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:# 在全特征上进行卷积,多在后期使用
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)# 输出y的线性映射层,对应$\phi(out)$
self.pws = nn.ModuleList(# 高阶空间交互过程中使用的卷积模块,对应公式3.4
[nn.Conv2d(self.dims[i], self.dims[i + 1], 1) for i in range(order - 1)]
)
self.scale = s# 缩放系数,对应公式3.3中的$\alpha$
print('[gnconv]', order, 'order with dims=', self.dims, 'scale=%.4f' % self.scale)
def forward(self, x, mask=None, dummy=False):
print(self.dims)
fused_x = self.proj_in(x)# channel double
print("fused_x:",fused_x.shape)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)# split channel to c/2**order and c(1-2**oder)
print("pwa:{} abc:{}".format(pwa.shape,abc.shape))
dw_abc = self.dwconv(abc) * self.scale
print('dw_abc:{}'.format(dw_abc.shape))
dw_list = torch.split(dw_abc, self.dims, dim=1)
# 两个相同尺寸的张量相乘,对应元素的相乘就是这个哈达玛积(mul)
x = pwa * dw_list[0]
print("x:{}".format(x.shape))
for i in range(self.order - 1):
x = self.pws[i](x) * dw_list[i + 1]
print('conv[{}]:{} * dw_list[{}]:{} = x:{}'.format(i,self.pws[i],
i+1,dw_list[i+1].shape,
x.shape))
x = self.proj_out(x)
return x
if __name__ == '__main__':
x=torch.randn((2,64,20,20))
gn=gnconv(64)
out=gn(x)
print(out.shape)
Output:
[gnconv] 3 order with dims= [16, 32, 64] scale=1.0000
[16, 32, 64]
fused_x: torch.Size([2, 128, 20, 20])
pwa:torch.Size([2, 16, 20, 20]) abc:torch.Size([2, 112, 20, 20])
dw_abc:torch.Size([2, 112, 20, 20])
x:torch.Size([2, 16, 20, 20])
conv[0]:Conv2d(16, 32, kernel_size=(1, 1), stride=(1, 1)) * dw_list[1]:torch.Size([2, 32, 20, 20]) = x:torch.Size([2, 32, 20, 20])
conv[1]:Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1)) * dw_list[2]:torch.Size([2, 64, 20, 20]) = x:torch.Size([2, 64, 20, 20])
torch.Size([2, 64, 20, 20])
4 Experiment
HorNet这篇文章虽然只有14页,但其实大部分内容都在介绍主流任务的对比实验,下面简要介绍两个实验结果:分类和检测。
ImageNet分类实验结果如表1所示。可以看出,HorNet模型与SOTA的Vision Transformer和CNN相比仍非常有竞争力的性能,并且HorNet超越了Swin transformer和ConvNeXt。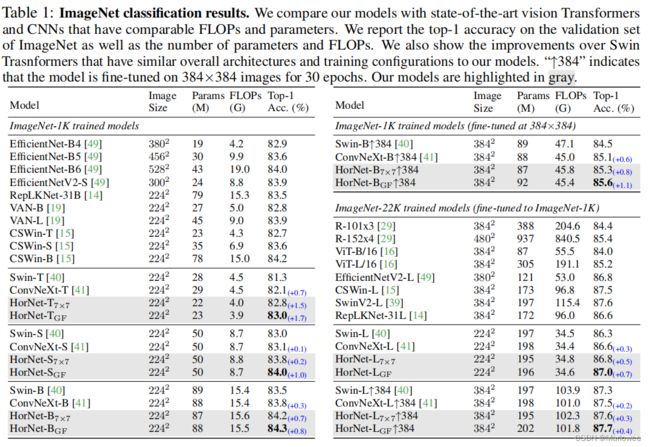
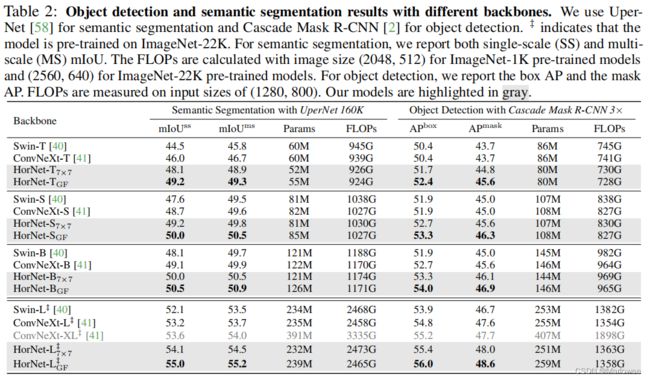
作者同样在COCO上评估了模型,采用Cascade Mask R-CNN框架,使用HorNet-T/S/B/L主干进行对象检测和实例分割。同样,HorNet模型在box AP和mask AP方面都比Swin/ConvNeXt所表现地要优越不少。
Conclusion
总的来说,作者团队提出了递归门控卷积( g n C o n v g_{n}Conv gnConv),它通过门控卷积和递归设计执行高效的、可扩展的、平移等效的高阶空间相互作用。
在各种Vision Transformer和基convolution-based的模型中, g n C o n v g_{n}Conv gnConv可以替代空间混合层。在此基础上,作者构建了一个新的通用视觉骨架网络HorNet,并通过大量的实验证明了 g n C o n v g_{n}Conv gnConv和HorNet在常用的视觉识别基准上的有效性。作者希望他们的尝试可以启发未来的工作,以进一步探索视觉模型中的高阶空间相互作用。
A FLOPs of g n C o n v g_{n}Conv gnConv

[1] On the Connection between Local Attention and Dynamic Depth-wise Convolution