论文笔记:联邦学习——Federated Learning: Strategies for Improving Communication Efficiency
Federated Learning: Strategies for Improving Communication Efficiency
文章目录
- Federated Learning: Strategies for Improving Communication Efficiency
-
- 论文结构
- 一、摘要核心
- 二、 Introduction
- 三、Structured Update
-
- low rank
- random mask
- 四、 Sketched Update
-
- 过程
- 多种进行sketching的工具
-
- ① Subsampling
- ② Probabilistic quantization
- ③ Improving the quantization by structured random rotations
- 五、Experiments
-
- (1)基于CIFAR-10数据集的卷积模型实验
- (2)LSTM对REDDIT数据集的预测下一个单词
论文链接: link
论文结构
Abstract
1. Introduction
2. Structured Update
3. Sketched Update
4. Experiments
一、摘要核心
背景介绍:
介绍联邦学习的思想、算法,说明通信效率的重要性。
文章亮点:
提出两种降低上行通信成本的方法: structured updates 和 sketched updates
① structured updates:直接从一个有限的空间学习更新,可以使用更少的变量参数化。
②sketched updates :学习一个完整的模型更新,压缩后发给服务器。
优势:
在卷积网络和递归网络上的实验表明,该方法可以将通信成本降低两个数量级。
二、 Introduction
- 现有机器学习算法环境需要数据平衡和独立同分布i.i.d.的,和可用的高通量的网络;
而联邦学习的限制是客户数量众多,高度不平衡和non-i.i.d.的数据,以及相对较差的网络连接。 - 联邦学习的同步算法,其中典型的一轮学习包括以下步骤:
(1)客户端的子集都下载现有的模型
(2)每个子集的客户基于本地数据计算模型更新
(3)将模型更新发送到服务器
(4)服务器聚合模型更新,构建一个改进的全局模型 - 说明降低通信成本的重要性
(1)联邦学习的瓶颈:需要客户端向服务器发送一个完整的模型
(2)因素:
网络连接速度的不对称性;
现有的模型压缩方案可以减少下载当前模型所需的带宽并建立加密协议,进一步增加需要上传的比特量。 - 描述问题
① 假设所有的参数都在一个矩阵W中, W ∈ R d 1 × d 2 W\in\mathbb{R}^{d1×d2} W∈Rd1×d2
② 第t轮时,服务器将当前模型 W t W_t Wt分配到 s t s_t st客户端的一个子集 s t s_t st中,客户端基于本地数据独立更新模型。
③ client i 的更新为 H t i H{_t^i} Hti= W t i W{_t^i} Wti- W t {W_t} Wt
④ 客户端将更新传给服务器,服务器进行全局更新。 学习率设为1
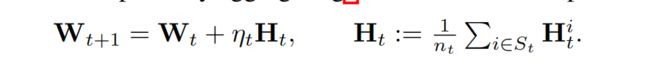
- 论文在描述神经网络时,使用二维矩阵 W表示每一层的参数。而卷积核的结构是四维的张量#input × width × height × #output,用二维矩阵 来表达是(# input × width × height)× #output。
三、Structured Update
直接训练结构的更新
限制更新 H t i H{_t^i} Hti有是指定的结构,文中考虑两种结构:low rank and random mask.
low rank
强制使更新矩阵 H t i H{_t^i} Hti的秩不超过k,
将更新矩阵写成乘积的形式 H t i H{_t^i} Hti= A t i A{_t^i} Ati B t i B{_t^i} Bti, A ∈ R d 1 × k A\in\mathbb{R}^{d1×k} A∈Rd1×k, B ∈ R k × d 2 B\in\mathbb{R}^{k×d2} B∈Rk×d2。
本地训练时,随机生成 A t i A{_t^i} Ati看成一个常数,只优化 B t i B{_t^i} Bti。实际情况 A t i A{_t^i} Ati可以用随机种子的形式压缩,客户端质只要向服务器发送训练好了的 B t i B{_t^i} Bti。
这种方法节省了 d 1 / k d1/k d1/k的通信成本。
random mask
将更新矩阵 H t i H{_t^i} Hti限制成稀疏矩阵,遵循一个预定义的随机稀疏性模式(random mask),在每一轮中都会对每个客户端独立生成。这种稀疏模式也可以由一个随机种子表示。
这种方法客户端只需要将 H t i H{_t^i} Hti中的非零元素的值、随机种子发送给服务器。
四、 Sketched Update
过程
先通过无约束的本地训练计算出全部更新矩阵 H t i H{_t^i} Hti,然后进行编码,对更新矩阵进行有损的压缩后发给服务器,服务器收到后,先解码然后再聚合。
多种进行sketching的工具
① Subsampling
不用上传更新矩阵 H t i H{_t^i} Hti,每个客户端只上传 H t i H{_t^i} Hti的随机子集矩阵 H t i ˆ \^{H{_t^i}} Htiˆ。服务器对子集的更新取平均,得到全局更新 H t ˆ \^{H{_t}} Htˆ。
这样做可以使采样更新的平均值是真实平均值的无偏估计量: E \mathbb{E} E[ H t ˆ \^{H{_t}} Htˆ]= H t ˆ \^{H{_t}} Htˆ。
② Probabilistic quantization
另一种压缩更新的方法是通过量化权重。
将 H t i H{_t^i} Hti的元素量化到1bit,令 h h h=( h 1 h_1 h1, … , h d 1 × d 2 h_{d_1×d_2} hd1×d2),然后压缩 h h h
更新,表示为 更新,表示为 更新,表示为 h ~ \tilde{h} h~
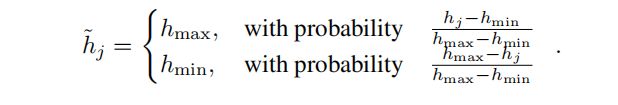
与4字节的浮点数相比,该方法提供了32×的压缩。
同时也可以将1bit量化泛化成b bit,先将[ h m i n h_{min} hmin, h m a x h_{max} hmax]等分为 2 b 2^b 2b个区间。假设 h i h_i hi落在以 h ′ h' h′, h ′ ′ h'' h′′ 为界的区间内,将上述方程的 h m i n h_{min} hmin和 h m a x h_{max} hmax分别替换为 h ′ h' h′和 h ′ ′ h'' h′′。
参数b允许以简单的方式平衡精度和通信成本。
另一种量化方法也是基于减少通信,同时平均向量。
增量、随机和分布式优化算法可以在量化更新设置中进行类似的分析。
③ Improving the quantization by structured random rotations
当在不同维度上的尺度近似相等时,第②种效果最好。
不然会有错误,解决方法:在量化之前对h应用一个随机旋转(将h乘以一个随机正交矩阵)
五、Experiments
使用联邦学习来训练深度神经网络来完成两种不同的任务:图像分类任务、单词预测。
FedAvg算法:可以减少通信轮数。在每一轮中,我们均匀地随机选择多个客户端,每个客户端在其本地数据集上以η的学习速率执行多个SGD的epoch。
实验目的:在所有情况下,使用一系列学习速率的选择进行实验,并报告最佳结果。
(1)基于CIFAR-10数据集的卷积模型实验
研究了我们所提出的方法作为联邦平均算法的一部分的性质。
目标:评估压缩方法,并不是实现最好的精度
数据集:CTFAR-10
随机将500个训练数据分给100个客户,
结构:使用全卷积模型,9个卷积层,第一层和最后一层的参数远少于其他7层,因此只压缩中间7层。每一层都有相同的参数。
(作者也曾尝试对全部 9 层都进行压缩,但是发现这样对通信量的节省效果微乎其微,还会轻微减慢收敛速度。)
mode是控制更新的比例,越小代表更新的量越少。
对于random mask或sketching,这是指除mode值以外的所有参数被归零。
实验一:在CIFAR-10上进行structure update的实验
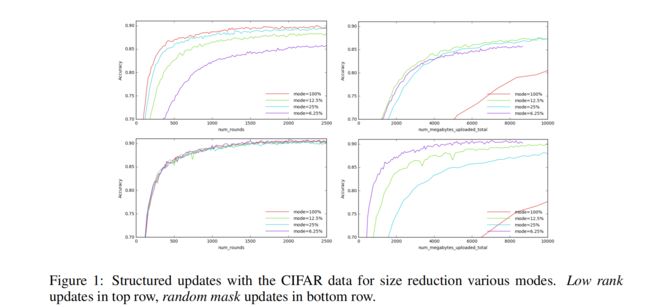
random mask 明显要比 low rank 表现得更好。
左下角的图:训练轮数增加时,random mask 收敛速度几乎没有受到 mode 减小的影响。
右边的图:如果目标仅仅是只最小化上传大小,mode越小越好,减少更新大小的版本将明显是赢家。
实验二:比较structured updates(random mask) 和 sketched updates(subsampling) 的表现
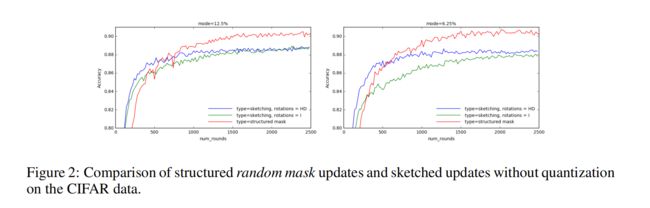
直接学习得到一个 structured random mask updates 要好于学习一个 unstructured update,然后再sketch 得到一个相同参数量的表示。
因为在 sketching 的过程中会丢掉一些在训练中学习到的信息。sketching the updates 会导致准确率稍微低一些,会直接增加收敛性分析中的方差。
实验三:sketched updates的比较(结合了随机旋转、量化和下采样。)
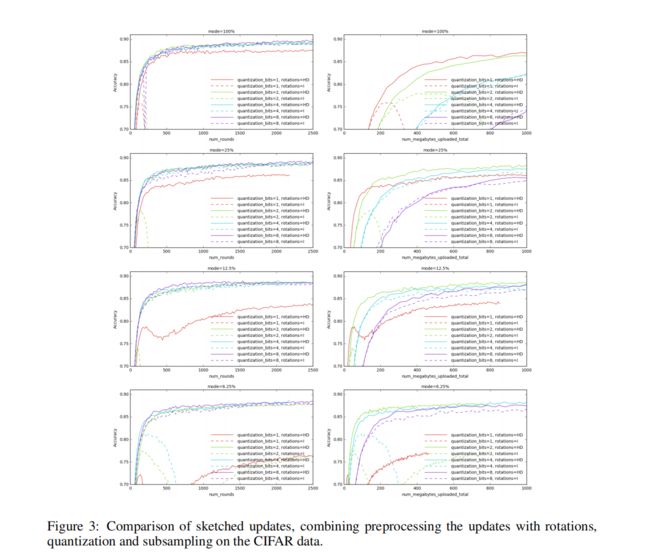
压缩率是所有实验中最高的。
随机旋转的表现最好;
在没有旋转的情况下,算法的行为不太稳定,特别是在量化比特数少和模式小的模式下。
使用随机旋转的预处理,mode=6.25%,并使用2 bits进行量化 ,在收敛性上只得到了一个轻微的下降,而在表示对单个层的updates需要的位数节省了256倍。( 2 8 b i t − 2 b i t 2^{8bit-2bit} 28bit−2bit)
(2)LSTM对REDDIT数据集的预测下一个单词
基于包含在Reddit上公开发布的帖子/评论的数据,构建了用于模拟联邦学习的数据集
训练的LSTM预测单词模型:
通过在字典中查找单词,将单词 s t s_t st映射到一个嵌入式向量 e t ∈ R 96 e_t\in\mathbb{R}^{96} et∈R96中, e t e_t et与在前一个时间步长 s t 1 ∈ R 256 s_{t1}\in\mathbb{R}^{256} st1∈R256的模型发出的状态结合,发出一个新的状态向量 s t s_t st,和一个“输出嵌入” o t ∈ R 96 o_t\in\mathbb{R}^{96} ot∈R96。输出嵌入通过内积对单词的每个项进行评分,再通过softmax进行归一化,以计算词汇表中的概率分布。
实验一:比较sketched updates
在每次迭代中,随机抽取50个用户,根据本地可用的数据计算更新并绘制,并取所有更新的平均值。每轮对10、20和100个客户进行抽样实验。
“sketch_fraction”设置为0.1或1,表示被下采样的更新元素的比例。
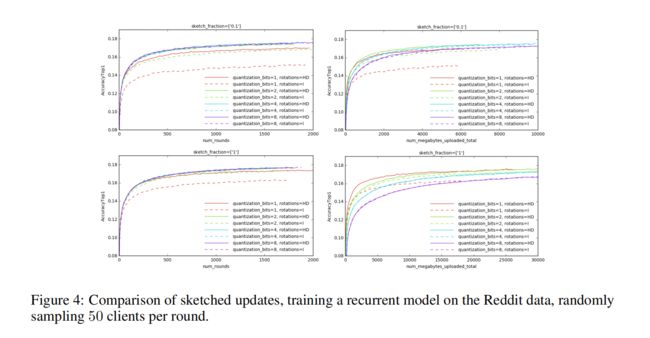
左边一列:
随机旋转的预处理效果有显著的正效应,尤其在量化的位数比较少的时候。
对于所有的下采样比例的选择,rotations=HD和量化为2位不会造成任何性能损失。
实验二:研究在单轮中使用的客户数量对收敛的影响
对固定的轮数(500和2500轮)运行FedAvg算法,每轮的客户端数量不同,将更新量化到1位,并绘制得到的精度。
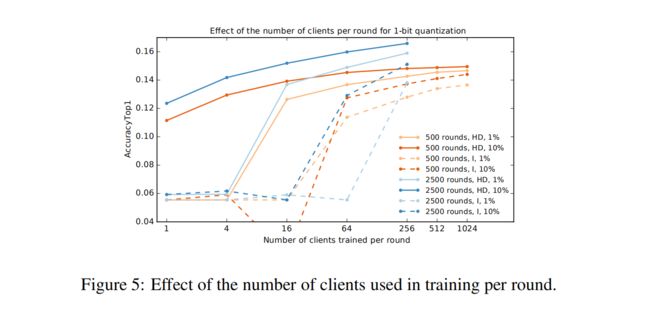
如果每轮有足够数量的客户,在这种情况下是1024,我们可以将下采样元素的比例降低到1%,与10%相比,准确性只有轻微的下降。
这表明在联邦设置中一个重要实用的权衡:
可以在每一轮中选择更多的客户,同时每个客户通信更少(例如,更aggressive的下采样),获得与使用更少客户端相同的准确性,但让每个客户端通信更多。当每个客户端都可用时,前者可能更好,但每个都有非常有限的上传带宽。(这在实验中是一个常见的设置)