一、BrokerStates.scala
定义了目前一个kafka broker的7中状态 ——
1. NotRunning:未运行
2. Starting:启动中
3. RecoveringFromUncleanShutdown:从上次异常恢复中
4. RunningAsBroker:已启动
5. RunningAsController:作为Controller运行
6. PendingControlledShutdown:controlled关闭
7. BrokerShuttingDown:关闭broker
BrokerStates提供了newState方法来设定Broker的状态,它也支持传入一个字符串字节来定制化状态。
合法的状态转换包括:
Not Running ---> Starting
Starting ---> RecorveringFromUnCleanShutdown
Starting ---> RunningAsBroker
RecorveringFromUnCleanShutdown ---> RunningAsBroker
RunningAsBroker <---> RunningAsController
RunningAsController/RunningAsBroker ---> PendingControlledShutdown
PendingControlledShutdown ---> BrokerShuttingDown
BrokerShuttingDown ---> Not Running
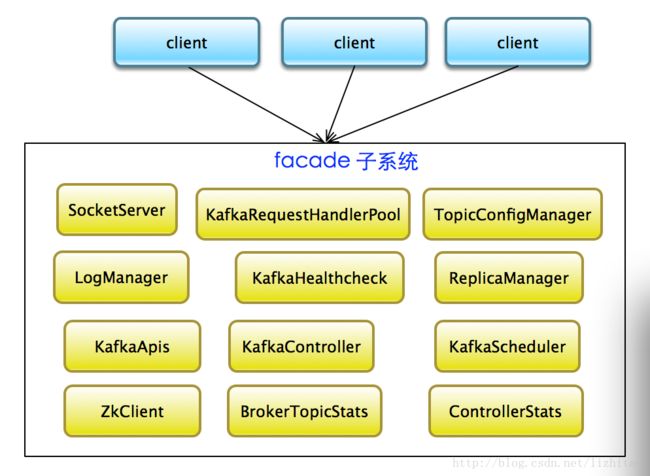
kafka中KafkaServer类,采用门面模式,是网络处理,io处理等得入口.
ReplicaManager 副本管理
KafkaApis 处理所有request的Proxy类,根据requestKey决定调用具体的handler
KafkaRequestHandlerPool 处理request的线程池,请求处理池 <-- num.io.threads io线程数量
LogManager kafka文件存储系统管理,负责处理和存储所有Kafka的topic的partiton数据
TopicConfigManager 监听此zk节点的子节点/config/changes/,通过LogManager更新topic的配置信息,topic粒度配置管理,具体请查看topic级别配置
KafkaHealthcheck 监听zk session expire,在zk上创建broker信息,便于其他broker和consumer获取其信息
KafkaController kafka集群中央控制器选举,leader选举,副本分配。
KafkaScheduler 负责副本管理和日志管理调度等等
ZkClient 负责注册zk相关信息.
BrokerTopicStats topic信息统计和监控
ControllerStats 中央控制器统计和监控
二、LeaderElector.scala
leader选举的trait,这个类会自动处理重选举,一旦成功它会调用leader状态变更回调方法。该trait定义了三个抽象方法:startup、amIleader和elect。该trait只有一个实现类:ZookeeperLeaderElector
三、ZookeeperLeaderElector.scala
这个类继承了LeaderElector trait,用于处理基于zookeeper的选举(通过监听临时节点的存在性)。该选举并不负责处理会话超时的问题,它只是假设调用者通过重试自己来处理。如果当前leader已死,这个类会处理自动重选举,一旦成功,代码会调用leader状态变更回调。
该类的构造函数会首先确保要选举的path在zookeeper中存在,然后构造一个leader变更监听器——该监听器是由嵌套类LeaderChangeListener实现的。
LeaderChangeListener类继承了IZKDataListener接口,用于监听leader的状态,但并不处理会话过期的问题,而是假设调用者自己来处理这些事情。该嵌套类主要实现了两个方法:
1. handleDataChange:当保存在zookeeper中的leader信息发生变更时会调用这个方法,并在内存中记录这个心的leader
2. handleDataDeleted:当保存在zookeeper中的leader信息被删除时调用这个方法,该方法会尝试着选举leader
ZookeeperLeaderElector类既然继承了LeaderElector,也就实现了三个方法:
1. amILeader:判断leader的id是否和传入的broker id一样,一样的话说明该broker当前就是leader
2. getControllerID:从Zookeeper中获取controller id
3. elect:所谓选举就是选举controller。具体逻辑如下:
- 获取当前时间戳并用于构造待写入zookeeper的JSON串
- 获取controller ID
- 检查leader是否已选举出来,如果是-》调用amILeader方法判断给定的broker是否就是controller,如果是直接返回true;否则返回false
- 如果leader未选举出来,尝试在在zookeeper上创建临时节点。如果创建成功表明broker被选举为leader,调用onBecomeLeader;若节点以存在,再次获取controller ID,若不是-1说明已有其他broker被选举为leader;若是的话表明虽有leader被选出但其放弃了leader角色,还需要开启下一轮的leader选举
- 最后调用amILeader方法返回结果
4. startup:启动方法,在kafka controller启动时会调用它。主要就是在zookeeper的controller选举路径上注册一个leader变更监听器,然后调用elect方法开启选举
5. close:关闭方法,仅仅是将leader ID设置为-1,表明无leader被选出
6. resign:放弃leader的方法,也是将leader id设置为-1, 然后删除zookeeper中对应的节点路径
四、TopicConfigManager.scala
该类管理topic配置的变更。工作原理如下:
- 配置信息保存在/config/topics/[topic]节点下。这个zookeeper节点保存了topic的非默认配置信息
- Kafka并不监控所有的topic的配置变更。相反,它只是在zookeeper上创建了一个统一的消息通知节点:/config/changes。Topic配置管理器会在该路径下注册一个子节点变更监听器
- 如果要更新一个topic配置时,kafka首先会更新topic的配置属性,然后在刚才的路径上创建包含topic名称的顺序节点,比如/config/changes/topic_1234。该节点只是一个消息通知的标志,真正的topic配置信息还是保存在/config/topics/[topic]节点下的。
- 这可以在所有broker上都触发一个watch。该watch工作原理如下:它会读取所有配置变更消息,然后保存并追踪最新的配置变更后缀号。遍历每个以前应用的变更时,如果这个变更超时了就删除这个通知。对于watch读取新配置信息对应的变更,watch会结合默认的配置值,并为该topic所有日志更新日志配置。
- 需要注意的是,配置信息总是保存在zookeeper的配置路径上,而消息通知只是一个触发器而已。因此如果一个broker宕机了也没关系,因为在其重启后它会加载所有的配置信息,还有就是有可能两个连续的配置变更发生但只有后一个变更被应用。这种情况下broker没有必要刷新两次配置。
- 配置管理器重启时会重新处理所有的消息通知。这通常都会带来一些没必要的浪费,但确实可以避免race condition
下面具体分析代码结构。该类保存了一个私有变量表示最新执行变更时的变更号。该类定义的方法如下:
1. changeNumber:从zookeeper的消息通知节点下获取变更号。格式固定为config_change_xxx,该方法就返回最后的xxx数字
2. purgeObsoleteNotifications:根据给定时间戳清除一组过期通知。具体逻辑如下:
- 首先将给定过期通知列表按照变更号排序
- 遍历每一个消息通知,读取zookeeper中/config/changes/该消息通知 节点的数据,如果无数据什么都不做,否则判断该节点的ctime与给定时间相比是否超过了默认的过期时间(默认15分钟)。如果没有直接返回——说明没有过期;否则删除zookeeper中对应的节点:/config/changes/该消息通知
3. processConfigChanges:处理给定的一组配置变更。具体逻辑如下:
- 获取当前时间以及所有分区的log记录
- 将log记录按照topic分组
- 遍历消息列表中的每一个消息通知,首先获取该通知的变更号,如果变更号大于上一次执行的变更号则从zookeeper中读取通知包含的topic信息
- 如果该topic在按topic分组的日志中有记录的话,则合并默认配置值和zookeeper节点/config/topics/[topic]下的覆盖值一起更新对应的日志配置,并删除那些过期的通知
- 同时更新上一次执行的变更号
4. processAllConfigChanges:一次处理/config/changes下所有的通知
5. startup:开启对于配置变更的监听,监听器由嵌套object:ConfigChangeListener来实现。具体逻辑就是在/config/changes节点下注册监听器用于监听配置的变更,然后处理该节点下所有的通知
6. 嵌套object——ConfigChangeListener:主要监听/config/changes下子节点的变更
五、KafkaConfig.scala
Kafka服务器的配置设置,可通过加载一个Properties文件加载配置,封装了官网上能查到的所有配置及默认值,就不一一赘述了
六、KafkaHealthcheck.scala
这是检测broker健康度的一个类,目前Kafka定义一个broker是健康的标准非常简单——如果在zookeer上有注册信息就是健康的,否则就是"已死"的,即如果在zookeeper上对应的路径是/brokers/ids下创建了临时节点就是健康的。
在检测zookeeper节点的时候该类还定义了一个嵌套类SessionExpireListener用于监听zookeeper客户端会话超时。一旦会话超时引发SessionExpired事件发出,zookeeper上所有的临时节点都将被删除,zkClient就需要重建zookeeper的连接。因此代码需要重新注册broker——注册方法就是调用register方法(后面会说到)
该类定义的方法如下:
1. register:在zookeeper中注册该broker。具体方法就是在zk的/brokers/ids下创建一个以broker id为名字的临时节点,具体的数据包括:jmx_port,timestamp,host,port和version
2. starup:注册会话过期监听器并创建临时节点注册broker
七、LogOffsetMetadata.scala
该scala文件时一组伴生对象,定义了日志位移的元数据信息。先说LogOffsetMetadata类。该类定义了kafka的位移元数据结构,它包括:
1. 消息位移
2. 位移所在日志段的基础位移(起始位移)
3. 所在段的物理位置
该类定义了一些方法用于获取这些信息以及使用这些信息执行一些判断操作:
1. messageOffsetOnly:判断位移元数据信息是否只包括消息位移部分的数据,而其他两部分为空
2. offsetOnOlderSegment:与给定的位移元数据实例相比较判断这个位移是否是在一个比较旧的日志段上。
3. offsetOnSameSegment:与上个方法类似,只是这次比较两个位移元数据信息是否在同一个日志段上
4. precedes:比较这个位移是否在给定位移之前
5. offsetDiff:计算此位移与给定位移之间所含的消息数
6. positionDiff:计算此位移与给定位移之间所差的字节数——前提是两个位移位于同一日志段且此位移在给定位移之前出现。实现方法就是元数据信息中的段内相对物理位置相减。
再说说LogOffsetMetadata object。它定义了三个常量分别代表未知位移的元数据、未知的段起始位移和位置的段内物理文件位置。最后该object还定义了一个OffsetOrdering嵌套类实现了scala的Ordering接口因而支持两个位移元数据实例的比较。compare方法就是调用两个元数据的offsetDiff方法获取两个元数据之间的消息差值。
八、OffsetCheckpoint.scala
这个类保存topic分区信息与对应offset的映射信息到一个传入的检查点文件中。主要定义了两个方法read和write分别用于读写:
1. write:将给定的map写入到检查点文件中。该map主要保存topic分区到offset的映射。以同步的方式先往临时文件中写,然后与现有的检查点文件进行交换。具体逻辑如下:
- 创建以.tmp结尾的临时文件以及对应的输出流
- 依次写入版本信息0、map的项数以及每一项中topic信息、分区以及offset(这三项以空格分割)。每个都是一行
- 最后保存输出流并写入临时文件
- 重命名临时文件去掉.tmp完成检查点文件的写入
2. read:从检查点文件中读取topic分区与对应位移的记录,封装成一个map返回。具体逻辑如下:
- 读取检查点文件,创建输入流
- 依次读出版本信息、总项数以及每项中对应的topic、分区和位移信息
九、OffsetManager.scala
Kafka位移的管理器类,提供了两组伴生对象:OffsetManagerConfig和OffsetManager以及一个case类:GroupTopicPartition。我们先说位移管理器的配置类:OffsetManagerConfig。
OffsetManagerConfig包括了内置位移管理器定义的配置设置信息,具体配置如下:
1. maxMetadataSize: 所允许的位移元数据的最大字节数,默认是4KB,由属性offset.metadata.max.bytes指定
2. loadBufferSize: 从日志段读取位移加载到位移管理器缓存时的批次字节数,默认是5MB,由属性offsets.load.buffer.size指定
3. offsetsRetentionMs: 任何位移如果比这个时间还旧就标记为可删除。真正的删除实际上是由log cleaner压缩日志时完成的。默认是1天,代码中说由"offsets.retention.minutes"指定,但官网中没有找到对应的属性名,官网可能误写成offsets.topic.retention.minutes属性了
4. offsetsRetentionCheckIntervalMs: 定时任务中定期检查位移的时间间隔, 代码中写死为10分钟,也就是说属性offsets.retention.check.intervals.ms貌似没有被使用
5. offsetsTopicNumPartition: Kafka0.8.1之后默认将offset保存在kafka中而不是zookeeper中。具体的方法就是把offset提交作为一个topic保存起来。而这个字段就是设定该topic的分区数的,默认是50,由属性offsets.topic.num.partitions指定。由于目前Kafka并不支持动态修改此值,因此推荐在生产环境下一次性地调大该值,比如100~200
6. offsetsTopicSegmentBytes: offsets topic日志段大小字节数。因为offset topic是启用了日志压缩的,所以该值最好设置得小一点以便更快地进行日志压缩和加载。默认值100MB,在程序里面硬编码为100MB,官网中的offsets.topic.segment.bytes似乎没用上
7. offsetsTopicReplicationFactor:offsets topic的备份因子,默认是3,由属性offsets.topic.replication.factor指定。推荐设置高一些以确保高可用
8. offsetsTopicCompressionCodec:用于offsets topic的编码/解码器,默认是NoCompressCodec,但对于offsets topic而言,必须启用压缩以达到原子提交的效果
9. offsetsCommitTimeoutMs:位移提交操作会等待规定数目的副本都接收到offset提交申请,但等待不会超过这个值设定的时间间隔。这类似于producer请求超时。默认值是5秒,由属性offsets.commit.timeout.ms指定
10. offsetCommitRequiredAcks:在offset提交操作被正式接受之前需要获取的应答数,类似于producer的应答设置。默认值是-1,提供了最大程度的持久化保证。该值由属性offsets.commit.required.acks指定,通常情况下不要修改此值。
而OffsetManagerConfig object则为上面的配置定义了一些默认值常量, 这里就不赘述了。
下面重点说说OffsetManager类——它的主要作用就是管理位移信息。作为位移管理器,它需要接收一个管理器配置类、一个副本管理器实例用于获取分区信息以及日志信息,同时它还接收一个调度器用来执行调度任务。
在类的内部,它维护了4个私有常量:
1. offsetCache:位移元数据缓存池,key就是消息的key,value是位移元数据信息
2. followerTransitionLock:状态转换锁,保护对于缓存的读操作使用
3. loadingPartitions:保存正在加载offset的分区
4. shuttingDown:原子变量标识表明加载是否完成
在构造函数中还开启了一个定时调度任务用于压缩位移缓存。
该类定义的方法有:
1. partitionFor:计算给定的consumer group对应的分区。大致思想就是计算group的hashCode然后与offset topic的分区数求模
2. compact:压缩位移缓存。具体逻辑如下:
- 找出那些已经过期的位移
- 对于每一条这样的位移,计算出它所属的offset commit topic的分区——根据哈希值与分区数求模计算而得
- 将该位移从内存缓存中移除
- 然后创建一个元组(分区,带key的消息)——消息的key是根据consumer group、topic和分区计算出来的
- 为每条过期消息都创建这样的元组,最后作为元组集合返回,之后按照分区进行分组
- 遍历上一步分组后的map,将map中每个元组包含的消息追加写入对应分区的leader中
3. offsetsTopicConfig:返回offset commit topic的配置类,主要配置了两个参数:该topic的段大小为100MB和启用日志压缩
4. getOffset:根据给定的group/topic/分区信息从底层的offset存储中获取最新的位移信息,具体做法就是从缓存中获取
5. putOffset:为给定的group/topic/分区对应的位移信息(必须是已提交的)放入缓存中
6. putOffsets:在位移被持久化地追加到提交日志之后才会调用该方法,因此没有必要检查当前leader是谁。该方法就是为某个consumer group批量地缓存位移信息
7. getHighWatermark:获取某个分区的高水位offset
8. leaderIsLocal:判断这个本地分区是否就是leader,方法就是判断其高水位是否是-1
9. clearOffsetsInPartition:清理一个分区的位移。 如果一个broker成为了offsets topic的一个分区的follower,那么要清理属于该分区的所有consumer group对应的缓存
10. shutdown:关闭位移管理器,设置关闭标识位为false
11. getOffsets:这个方法最值得注意的就是它永远不应该返回一个过期位移,要么返回当前位移,要么就开始从日志中同步缓存并返回错误码。具体逻辑如下:
- 获取这个consumer group对应的topic分区
- 使用followerTransitionLock锁来保证从空缓存或清理过(在leader到follower转换之后)的缓存中获取位移。
- 如果该分区就是leader,判断一下正在进行缓存加载的分区中是否包含该分区,如果包含返回一个错误码表示正在进行加载;如果不包含的话,还要看一下传入的目标分区集合是否为空,如果为空那就获取该consumer group拥有的所有分区的位移——当然,这只对在Kafka中保存offset的消费者有效——如果不为空,当然就只返回传入的那些topic分区了
- 如果该分区不是leader,自然也没法获取位移信息,因为不是位移的协调者,返回相应的错误码
12. loadOffsetsFromLog:异步读取offsets topic中的分区信息并加载其位移信息到缓存中——创建调度任务来完成异步加载
13. loadOffsets:加载位移到缓存中。具体逻辑如下:
- 获取分区的第一个日志段的基础位移值,在内存中申请一段offsets.topic.segment.bytes指定的缓冲区
- 不断地读取日志文件中的消息到缓冲区中,如果消息没有payload信息,说明是已被标记为“过期”的位移,否则的话将offset信息加入到缓存中
- 不断地循环上面的过程直至超过高水位或leader发生变更导致高水位被清空
- 最后完成位移加载工作,从正在加载的分区集合中将该分区移除
OffsetManager object定义了很多常量和一些方法供其他类使用。值得一提的是OffsetsTopicName,也就是说Kafka使用这个topic来保存位移信息。这个topic被固定为"__consumer_offsets"。该object还定义了很多Schema对象以及一个schemaFor方法用于定义offset的模式,包括key的模式和value的模式。它定义的方法如下:
- offsetCommitKey:为给定的group、topic和分区产生对应位移消息的key,包括group、topic、分区和版本号0
- offsetCommitValue:为给定的group、topic和分区产生对应位移消息的value,包括offset、一些元数据信息、时间戳和版本号0
- readMessageKey/readMessageValue:对应的解码方法,解析消息的key和value为对应的类实例
十、MetadataCache.scala
缓存每个分区的状态。这部分缓存会由controller发出的UpdateMetadataRequest请求来刷新。每个broker自己都异步地维护了相同的缓存。既然是缓存,该类定义了两个缓存Map:cache和aliveBrokers,分别缓存topic对应的分区状态信息以及当前可用的broker列表。该类定义的方法如下:
1. removePartitionInfo:把给定的topic分区状态信息从缓存中移除,如果缓存中该分区是给定topic的唯一分区,把topic记录也从缓存中移除
2. getAliveBrokers:获取当前可用的broker集合
3. getPartitionInfo:获取给定topic分区对应的缓存状态信息
4. updateCache:根据UpdateMetadataRequest请求更新给定broker上的缓存信息,包括更新可用broker列表和分区状态缓存。根据请求中的leader值来决定是往缓存中添加信息还是删除信息
5. addOrUpdatePartitionInfo:将给定的topic分区状态信息加入到缓存中或更新缓存中的记录
6. getTopicMetadata:获取给定topic的元数据列表。如果不指定参数则返回缓存中所有topic对应的元数据信息。具体逻辑如下:
- 确定目标topic集合
- 遍历该集合的每一个topic,如果缓存中没有该topic的记录并且也不是要获取所有记录,那么什么都不做
- 否则,从缓存中获取该topic的分区状态信息map,从map中找出每个分区的leader、ISR、AR信息封装成PartitionMetadata并与topic封装成TopicMetadata信息加入到最后的返回值列表中
十一、MessageSetSend.scala
使用零拷贝技术(zero-copy)实现的消息响应,将消息字节直接从文件写入内核空间。不过貌似代码中也没有用到。它集成了Send trait,因此也就必须要实现一个writeTo方法。该类定义了一个header表示消息的头部信息,共占有6个字节=1个int表示消息大小+1个short表示错误代码。而writeTo方法也没什么特别之处,就是调用MessageSet的writeTo方法发送消息。
十二、KafkaServerStartable.scala
根据跟定的kafka配置信息创建一个kafka服务器,并提供了startup和shutdown方法分别用于启动和关闭Kafka服务器。另外还提供了一个setServerState可以设置该Broker的状态。
十三、AbstractFetcherThread.scala
从同一个broker上的多个分区获取数据的抽象线程类。另外该scala还定义了三个其他类:
1. ClientIdTopicPartition:封装了clientId、topic和分区的数据结构
2. FetcherStats:fetcher状态类,创建了两个统计度量指标:每秒请求数和每秒字节数
3. FetcherLagMetrics:每个follower副本滞后的消息数度量元
4. FetcherLagStats:提供一个工厂方法获取上一个度量元
既然是线程类就继承了Kafka编写的ShutdownableThread类,并且是可中断的线程。因为需要同一个broker上的多个分区中读取数据,因此AbstractFetcherThread定义了一个map专门保存(topic, 分区)=>位移的映射,同时它还创建了一个SimpleConsumer实例用于获取某个请求对应的响应。我们具体来看一下它提供的方法:
1. processPartitionData:抽象方法,需要子类自己实现。主用用于处理获取到的给定分区的数据
2. handleOffsetOutOfRange:抽象方法,需要子类自己实现。处理某个分区的位移不在指定范围内的情况,需要返回一个新的位移
3. handlePartitionsWithErrors:抽象方法,需要子类自己实现。处理有错误的分区,该错误可能是因为leader变更导致的
4. shutdown:关闭该fetcher线程,除了调用父类的关闭方法之外还要额外关闭simpleConsumer
5. processFetcherRequest:处理给定的FetchRequest,具体逻辑如下:
- 发送FetchRequest请求并获取对应的response,若这个过程有错的话且线程在运行过程中,那么就把该线程缓存的所有分区都加入到错误分区集合中等待后续处理
- 如果response不为空,遍历reponse的数据部分,找出每个topic分区在线程中缓存的当前offset记录
- 如果存在当前offset记录且与请求中的offset值相同,判断一下response中的错误码
- 如果没有错误,则计算出该分区下一个位移的值——包含在response中,若没有直接使用当前位移值——并把它更新到线程缓存中,同时更新一些统计信息。之后调用子类的processPartitionData方法来处理分区数据
- 如果是OutOfRange错误,交由子类的handelOutOfRange方法来计算下一个位移的值并更新到缓存中
- 如果是其他错误的话,记录下这个错误,并把该分区加入到错误分区集合中
- 遍历完之后调用子类的handlePartitionsWithErrors来处理这些错误分区
6. addPartitions:为线程缓存的分区位移信息增加新的记录。注意只是增加,如果给定的分区已经在map中了则不能更新offset的值
7. removePartitions:把给定的分区集合从线程缓存map中移除
8. partitionCount:计算当前缓存map的分区数
9. doWork:执行fetcher线程逻辑,具体逻辑如下:
- 如果线程缓存map为空的话等待200毫秒
- 遍历缓存map,为每个分区都在请求队列中增加一条记录(TopicAndPartition->PartitionFetchInfo)
- 然后使用请求队列构建一个FetchRequest请求
- 调用processFetchRequest发送该请求并处理response
Broker主要由SocketServer(Socket服务层),KafkaRequestHandlerPool(请求转发层),Kafka api(业务逻辑层),Control(集群状态控制层),KafkaHealthcheck Broker (Broker健康检测层),TopicConfigManager(topic配置信息监控层)组成。
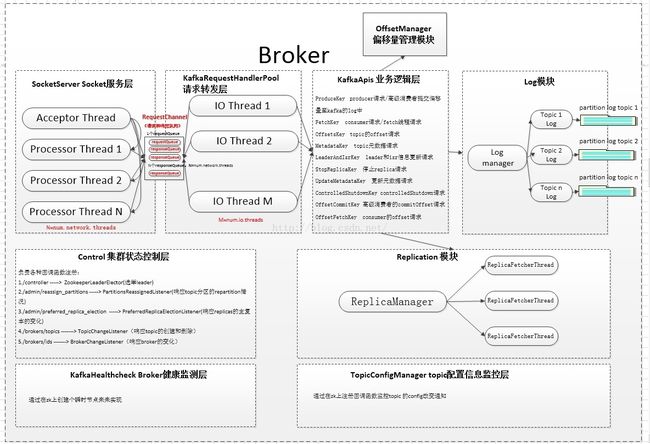
SocketServer内部开启1个Acceptor线程接受对外的sock链接,然后转发给N个处理线程Processor,其中N=num.network.threads
● N个Processor将接受到的request存放至阻塞队列requestQueue
● M个处理线程 IO Thread从RequestChannel的请求阻塞队列requestQueue获取请求,调用kafkaApis处理不同的请求,M=num.io.threads
● Broker共处理10种不同的request,分别为RequestKeys.ProduceKey、RequestKeys.FetchKey、RequestKeys.OffsetsKey、RequestKeys.MetadataKey 、RequestKeys.LeaderAndIsrKey、RequestKeys.StopReplicaKey、
RequestKeys.UpdateMetadataKey、RequestKeys.ControlledShutdownKey、RequestKeys.OffsetCommitKey、RequestKeys.OffsetFetchKey。
● KafkaApis(业务逻辑处理层)通过ReplicaManager(副本管理模块),logManager(日志模块),OffsetManager(偏移量管理模块)共同实现正常的业务逻辑
● IO Thread将request处理过的response存放进RequestChannel的响应阻塞队列responseQueues[i]
● Processor Thread从对应的RequestChannel的响应阻塞队列responseQueues[i]获取之前自己发送的request,然后发送给客户端
● Control(集群状态控制层)通过ZK选举改变自身的状态,集群中只有1台broker成为leader,主要负责应对topic的创建和删除,topic的分区变化,topic的分区内部的复本变化,broker的上下线。
● KafkaHealthcheck(Broker 健康状态监测层)通过在ZK上注册EphemeralPath来实现
● TopicConfigManager(topic配置信息监控层)主要响应topic的配置信息的变化