sklearn决策树
决策树
决策树是一种非参数的有监督学习方法,它能从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。
决策树的核心
- 如何让数据表中找出最佳节点和最佳分枝
- 如何让决策树停止生长,防止过拟合
sklearn中的决策树
- 模块sklearn.tree
sklearn中决策树的类都在“tree”这个模块之下,该模块包含五个类
| tree.DecisionTreeClassifier | 分类树 |
|---|---|
| tree.DecisionTreeRegressor | 回归树 |
| tree.export_graphviz | 将生成的决策树导出为DOT格式,画图专用 |
| tree.ExtraTreeClassifier | 高随机版本的分类树 |
| tree.ExtraTreeRegressor | 高随机版本的回归树 |
sklearn基本建模流程
- 实例化,建立模型对象
- 通过模型接口训练模型
- 通过导入测试集,从接口中提取需要的信息
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf = clf.fit(x_train, y_train) #通过fit接口训练模型
result = clf.score(x_test, y_test) #通过score获得信息
重要参数
criterion参数
决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个最佳的指标叫做**“不纯度”**。
通常不纯度越低,决策树对训练集的拟合越好。不纯度基于节点计算,树中的每一个节点都有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是在同一棵树上,叶子节点的不纯度一定是最低的。
- criterion参数正是用来决定不纯度计算方法的(默认使用gini)
- 输入**“entropy”**,使用信息熵
- 输入**“gini”**,使用基尼系数
信息熵与基尼系数的选择
- 通常就使用基尼系数
- 数据维度很大,噪声很大时使用基尼系数
- 维度较低,数据比较清晰时,信息熵与基尼系数没区别
- 当决策树的拟合程度不够时,使用信息熵(信息熵很容易导致过拟合)
- 两个都试一试,不好就换另一个
决策树的基本流程
- 计算全部特征的不纯度指标
- 选取不纯度最优的特征来分枝
- 在第一个特征的分枝下计算全部特征的不纯度指标
- 选取不纯度指标最优的特征继续分枝
- (直到没有更多的特征可用,或整体的不纯度指标已经最优,决策树就会停止生长)
如何建立一棵树
-
导入需要的算法库和模块
from sklearn import tree from sklearn.datasets import load_wine #红酒数据集 from sklearn.model_selection import train_test_split -
探索数据集
wine = load.wine() #将数据集赋值给wine wine #查看数据集中的所有数据 wine.data #查看数据集中的数据部分 wine.target #查看数据集的标签 wine.data.shape #查看数据有几行几列组成 wine.feature_names #特征名 wine.target_names #标签名#将数据与标签组合为一张表进行对应 import pandas as pd pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)], axis=1) --------------------------------------------------- 0 1 2 3 4 5 6 7 8 9 10 11 12 0 14.23 1.71 2.43 15.6 127.0 2.80 3.06 0.28 2.29 5.64 1.04 3.92 1065.0 0 13.20 1.78 2.14 11.2 100.0 2.65 2.76 0.26 1.28 4.38 1.05 3.40 1050.0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 2 13.71 5.65 2.45 20.5 95.0 1.68 0.61 0.52 1.06 7.70 0.64 1.74 740.0 2 13.40 3.91 2.48 23.0 102.0 1.80 0.75 0.43 1.41 7.30 0.70 1.56 750.0 178 rows × 13 columns -
将数据集分为训练集与测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3) -
基本建模三部曲
clf = tree.DecisionTreeClassifier(criterion="entropy" ,random_state=20 #用来设置分枝中的随机数量(默认为None) ,splitter="random" #用来控制决策树中的随机选项(best,random) ) clf = clf.fit(x_train, y_train) score = clf.score(x_test, y_test) score ---------------------------------------------------- 0.9629629629629629 -
画出一棵树
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸'] #由于原数据集特征名是英文在此进行了中文赋值 import graphviz dot_data = tree.export_graphviz(clf ,feature_names = feature_name ,class_names = ["琴酒","雪莉","贝尔摩德"] #原数据集中类名有三种,对类名进行重新赋值 ,filled=True #进行颜色填充 ,rounded=True #将树中方形改为圆形 ,max_depth=3 ) graph = graphviz.Source(dot_data) #从dot_data中获取生成树的代码并赋值给graph graph #输出树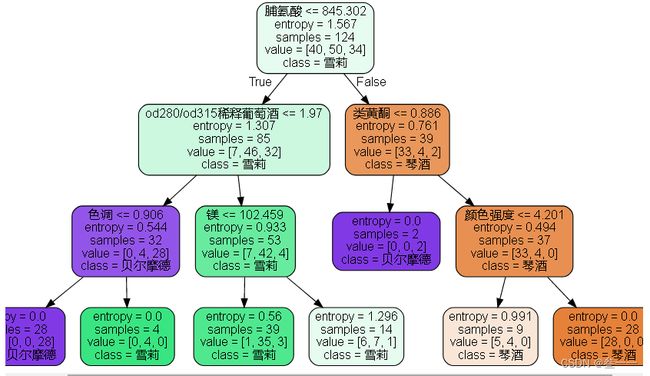
-
特征重要性
clf.feature_importances_ --------------------------------------------------- array([0.0707359 , 0. , 0. , 0. , 0.07183574, 0.0102946 , 0.12588086, 0. , 0. , 0. , 0.1544854 , 0.22760254, 0.33916497])#通过zip将特征名与特征重要性结合 clf.feature_importances_ [*zip(feature_name, clf.feature_importances_)]
剪枝参数
为了使决策树有更好的泛化性,我们要对决策树进行剪枝,剪枝策略对决策树的影响巨大,正确的剪枝策略是优化决策树的算法核心
- max_depth:限制树的最大深度,超过设定深度的树枝全部剪掉
- min_samples_leaf & min_samples_split:min_samples_leaf 限定一个节点在分枝后每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝不会产生(一般从=5开始使用); min_samples_split 限定一个节点必须要包含至少min_samples_split个训练样本,这个节点才被允许分枝
- max_features & min_impurity_decrease:max_features与max_depth用法相同;min_impurity_decrease 限制信息增益的大小,信息增益小于设定数值的分枝不会发生
重要属性和接口
对决策树来说最重要的是feature_importances_,能够查看各个特征对模型的重要性。
sklearn中许多算法的接口都是相似的,比如fit、score,几乎对每个算法都适用。决策树常用的接口还有apply、predict。
- apply:输入测试集返回每个测试样本所在的叶子节点的索引
- predict:输入测试集返回每个测试样本的标签
注:所有接口中要求输入X_train和X_test的部分,输入的特征矩阵必须是一个二维矩阵。sklearn不接受任何一维矩阵作为特征矩阵被输入。若数据只有一个特征,必须用reshape(-1,1)来给矩阵增维;若数据只有一个特征和一个样本,使用reshape(1,-1)来给矩阵增维。
clf.apply(Xtest)
clf.predict(Xtest)
-------------------------------------------------------
array([11, 11, 3, 10, 4, 11, 11, 7, 4, 3, 6, 7, 6, 4, 6, 6, 4,
10, 10, 6, 7, 11, 6, 7, 6, 12, 11, 4, 7, 10, 4, 3, 10, 4,
11, 4, 11, 4, 3, 12, 7, 3, 4, 7, 7, 10, 4, 11, 12, 4, 10,
3, 4, 3], dtype=int64)
array([0, 0, 1, 0, 1, 0, 0, 2, 1, 1, 2, 2, 2, 1, 2, 2, 1, 0, 0, 2, 2, 0,
2, 2, 2, 0, 0, 1, 2, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 2, 1, 1, 2,
2, 0, 1, 0, 0, 1, 0, 1, 1, 1])