2019-10-8 opencv机器学习1-KNN1-理解kNN(k近邻)
官网https://docs.opencv.org/3.4.1/d5/d26/tutorial_py_knn_understanding.html
关于kNN可以参考https://zhuanlan.zhihu.com/p/31747901
KNN是有监督机器学习中最简单的分类算法。它的想法就是在特征空间中找到距离测试数据最近的匹配。
观察下图
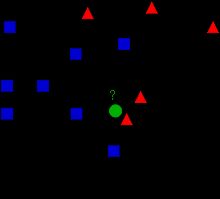
在图中有2组数据,蓝色方块和红色三角。我们把每一组数据称为类(Class)。可以把把蓝色和红色标记想象成在城镇地图中的一栋栋房子,这个城镇地图就称为特征空间(feature space)。你可以把一个特征空间看成是投影所有数据的空间。例如:在2D坐标空间中,所有数据都有2个特征,x坐标和y坐标。这样你就可以在2D空间中表示数据了。如果数据有3个特征,那我们就需要一个3D空间。N个特征的数据,那就需要N维度空间,这个N维度空间就是特征空间。在上图中,可以把它看成有2个特征的2D空间。
现在有一个新成员进入的城镇(特征空间)并创建了一栋新房子,也就是图中绿色的圆。它需要被归入蓝色或者红色类中,这个过程我们称为分类。那么我们应该怎么做呢?下面就来看看怎么用kNN算法来实现吧。
一个方法就是检查它最近的邻居是谁。在图中,它最近的邻居是红色三角。所以可以把它加入红色类。这种方法被称为简单近邻法,因为分类仅依靠最近邻居。
但是这里有个问题。红色三角确实是最近的,但是如果它周围还有很多蓝色方块呢?此时蓝色方块比红色三角(对它)的影响力更大。所以仅仅检测最近的一个邻居是不够的,我们需要检测k个最近的邻居。绿色圆应该属于在k个邻居中占多数的邻居类。
在图中如果k=3,它的最近邻居就是2个红色三角和1个蓝色方块(其实有2个蓝色方块距离它是相等的,但是因为k=3,所以我们只取蓝色方块中的1个)。所以最终绿色圆还是属于了红色三角类(因为3个邻居中占了2个)。
如果k=7,邻居就是5个蓝色和2个红色,此时绿色圆就属于蓝色类了。你已经发现了,分类会随着k值变化而变化。
更有趣的是,如果k=4,邻居是2个蓝色和2个红色,这是一个死结。所以k值最好是奇数。而这个方法最终被称为k近邻(k-Nearest Neighbour,简称kNN),因为它依靠最近的k个邻居。
接着再考虑一下,在kNN中我们需要观察k个邻居,但是这个k个邻居对于绿色圆来说都是同等重要吗?这样公平吗?例如,k=4,有2个红色和2个蓝色,是死结。但是2个红色比2个蓝色距离绿色圆都要近。所以它更加应该被分入红色。我们应该怎么用数据来表达这个情况呢?我们可以根据每个房子和新成员的距离来分配权重。距离近的权重就高,距离远的权重就低。然后我们分别统计2类房子的权重,新成员就是属于权重之和大的那个分类。这个被称为修改版kNN。
那么你在这里(上面叙述的过程中)看到了什么重要的东西?
- 你需要城镇中所有房子的信息。因为我们检查每个房子距离新房子的距离,以发现最近的邻居。如果房子数量很多,那显然要花更多内存保存数据,更多时间计算。
- 任何训练和准备几乎都不需要时间
下面我们来看看opencv中如何实现kNN
opencv中的kNN
这里我们先做一个简单的例子,和上面介绍的一样也有2个类。在下一节,我们会有一个更好的例子。
我们把红色分类标记为Class-0,蓝色分类标记为Class-1。然后再准备25个训练数据,它们的分类为Class-0或者Class-1。我们用numpy的随机数产生器来获得25个数据。
最后我们用Matplotlib把它们画出来。红色分类用红色三角表示,蓝色分类用蓝色方块表示。
代码如下
# -*- coding: cp936 -*-
import cv2
import numpy as np
import glob
from matplotlib import pyplot as plt
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# Labels each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# Take Red families and plot them
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# Take Blue families and plot them
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
plt.show()
运行后显示如下
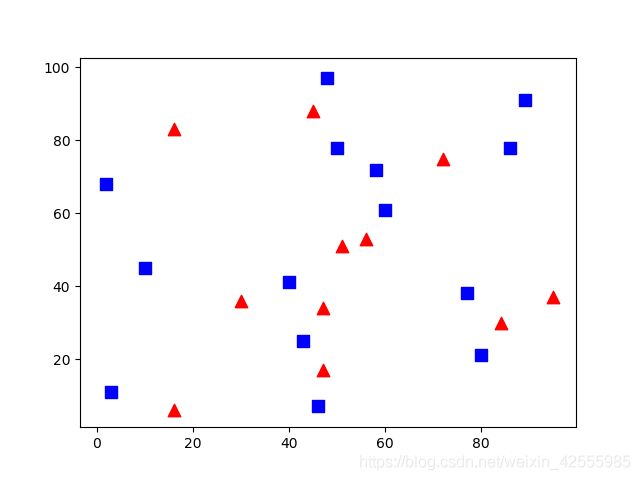
你可以返现这个图和本节最初展示的那个图非常相似。因为使用的是随机数生成器,所以每次运行结果都不一样。
下一步就是kNN算法的初始化。我们要传入训练数据和它们对应的分类来训练kNN(分类器)-构建搜索树。
现在我们就可以用opencv的kNN来对新的测试数据进行分类了。在使用kNN之前,我们需要对新的测试数据有所了解。测试数据是一个浮点型数组,大小是测试数据数量 x 特征数量。然后我们就可以找到测试数据的最近邻居了。
我们可以定义我们需要多少个邻居,kNN算法会返回:
- kNN算法得到的测试数据的分类。
- 假设定义k个邻居,会返回k个最近邻居的分类
- 每个邻居和测试数据的距离
现在我们引入测试数据,用绿色标记。
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours ,dist = knn.findNearest(newcomer, 3)
print( "result: {}\n".format(results) )
print( "neighbours: {}\n".format(neighbours) )
print( "distance: {}\n".format(dist) )
plt.show()
运行后,图片如下

运行结果如下;
result: [[1.]]
neighbours: [[0. 1. 1.]]
distance: [[205. 425. 586.]]
代码中设置了邻居数量为3,返回结果可以发现其中2个邻居分类是Class-1蓝色,1个邻居分类是Class-0红色,距离分别是205.,425, 586。最终的分类结果是Class-1。
如果你有大量的数据要进行测试,可以直接传入一个数组。对应的结果同样也是数组。
假设一组测试数据10个,kNN分类实现代码如下
# -*- coding: cp936 -*-
import cv2
import numpy as np
import glob
from matplotlib import pyplot as plt
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# Labels each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# Take Red families and plot them
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# Take Blue families and plot them
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
# 10 new comers
newcomers = np.random.randint(0,100,(10,2)).astype(np.float32)
# The results also will contain 10 labels.
#newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
#plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
plt.scatter(newcomers[:,0],newcomers[:,1],80,'g','o')
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results,neighbours,dist = knn.findNearest(newcomers, 3)
#ret, results, neighbours ,dist = knn.findNearest(newcomer, 3)
print( "result: {}\n".format(results) )
print( "neighbours: {}\n".format(neighbours) )
print( "distance: {}\n".format(dist) )
plt.show()
运行后,图片如下

结果如下,10个测试数据kNN分类结果,它们最近的3个邻居和距离分别如下。
result: [[1.]
[0.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]
[1.]]
neighbours: [[0. 1. 1.]
[1. 0. 0.]
[1. 0. 1.]
[1. 0. 1.]
[1. 0. 1.]
[0. 1. 1.]
[1. 1. 1.]
[0. 1. 1.]
[1. 1. 0.]
[1. 1. 0.]]
distance: [[ 74. 100. 153.]
[ 101. 565. 1117.]
[ 232. 290. 320.]
[ 17. 157. 265.]
[ 2. 72. 130.]
[ 149. 325. 365.]
[ 68. 180. 405.]
[ 457. 530. 865.]
[ 52. 260. 466.]
[ 81. 533. 613.]]