机器学习学习笔记week1
week1
- 1 引言
-
- 1.1 机器学习是什么?
- 1.2 监督学习
- 1.3 无监督学习
- 2 单变量线性回归
-
- 2.1 模型表示
- 2.2 代价函数
- 2.3 代价函数的直观理解I
- 2.4 代价函数的直观理解II
- 2.5 梯度下降
- 2.6 梯度下降的直观理解
- 2.7 梯度下降的线性回归
- 3 线性代数回顾
-
- 3.1 矩阵和向量
- 3.2 加法和标量乘法
- 3.3 矩阵向量乘法
- 3.4 矩阵乘法
- 3.5 矩阵乘法的性质
- 3.6 逆、转置
1 引言
1.1 机器学习是什么?
Arthur Samuel:在进行特定编程的情况下,给予计算机学习能力的领域
Tom Mitchell:一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。我认为经验E 就是程序上万次的自我练习的经验,而任务T 就是下棋。性能度量值P,就是它在与一些新的对手比赛时,赢得比赛的概率
学习算法主要的两种类型称之为监督学习和无监督学习
监督学习是指,我们将教计算机如何去完成任务
无监督学习中,我们打算让它自己进行学习
1.2 监督学习
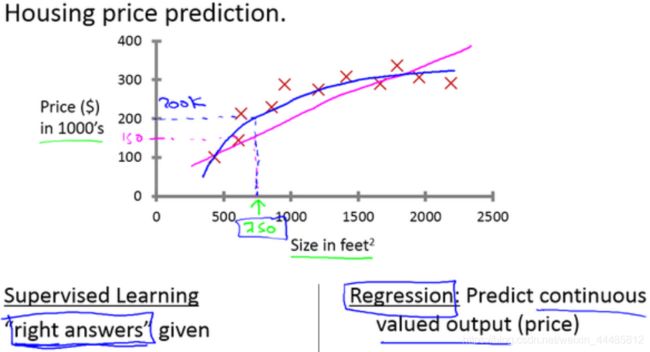
(1)预测房价
有一些房价的数据。横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。基于这组数据,假如你有一个朋友,他有一套750平方英尺房子,现在他希望把房子卖掉,他想知道这房子能卖多少钱?
监督学习:基于已有的正确结果。
回归问题:预测连续的输出值
1、应用学习算法,在这组数据中画一条直线,拟合一条直线,根据这条线我们可以推测出,这套房子可能卖$150,000
2、我们不用直线拟合这些数据,用二次方程去拟合可能效果会更好,根据二次方程的曲线,我们可以从这个点推测出,这套房子能卖接近$200,000
监督学习指的就是我们给学习算法一个数据集,这个数据集由“正确答案”组成。
在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价,然后运用学习算法,算出更多的正确答案。用术语来讲,这叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格。
回归的意思是,我们在试着推测出这一系列连续值属性。
(2)推测乳腺癌良性与否

这个数据集中,横轴表示肿瘤的大小,纵轴上,标出1和0表示是或者不是恶性肿瘤。我们之前见过的肿瘤,如果是恶性则记为1,良性记为0。
有5个良性肿瘤样本,有5个恶性肿瘤样本。假设有一个人检查出乳腺肿瘤,能否估算出肿瘤是恶性的或是良性的概率。用术语来讲,这是一个分类问题。
分类指的是,我们试着推测出离散的输出值:0或1,良性或恶性,而事实上在分类问题中,输出可能不止两个值。比如说可能有三种乳腺癌,所以你希望预测离散输出0、1、2、3。0 代表良性,1 表示第1类乳腺癌,2表示第2类癌症,3表示第3类,但这也是分类问题。
在分类问题中我们可以用另一种方式绘制这些数据点。负样本和正样本现在我们不全部画 X ,良性的肿瘤改成用 O 表示,恶性的继续用 X 表示。来预测肿瘤的恶性与否。
在其它一些机器学习问题中,可能会遇到不止一种特征。举个例子,我们不仅知道肿瘤的尺寸,还知道对应患者的年龄。在其他机器学习问题中,我们通常有更多的特征。通常采用这些特征,比如肿块密度,肿瘤细胞尺寸的一致性和形状的一致性等等,还有一些其他的特征。

上图中,列举了总共5种不同的特征,坐标轴上的两种和右边的3种,但是在一些学习问题中,不只用3种或5种特征。你想用无限多种特征,好让你的算法可以利用大量的特征,或者说线索来做推测。以后会讲一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。
监督学习基本思想是数据集中的每个样本都有相应的“正确答案”。再根据这些样本作出预测。
回归问题:通过回归来推出一个连续的输出
分类问题:其目标是推出一组离散的结果。
1.3 无监督学习
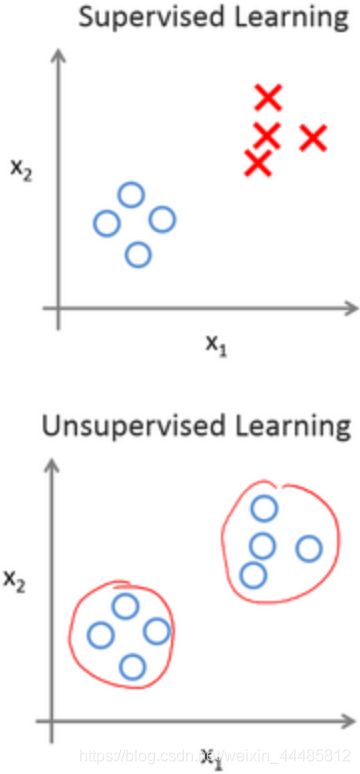
对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案
在无监督学习中,已知的数据没有任何的标签或者是有相同的标签或者就是没标签,已知数据集,却不知如何处理,也未告知每个数据点是什么。针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
聚类算法应用的一个例子就是在谷歌新闻中,搜索非常多的新闻事件,自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,所以显示到一起。
无监督学习中我们没有提前告知算法一些信息,比如,这是第一类的人,那些是第二类的人,还有第三类的人。我们只知道有一堆数据。我不知道数据里面有什么。我不知道谁是什么类型。我甚至不知道人们有哪些不同的类型,这些类型又是什么。要自动地聚类那些个体到各个类。因为我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习。
无监督学习或聚集有着大量的应用
(1)组织大型计算机集群
解决什么样的机器易于协同地工作,如果你能够让那些机器协同工作,你就能让你的数据中心工作得更高效。
(2)社交网络的分析
经常发邮件的,能否自动地识别出朋友的分组
(3)市场分割
检索顾客数据集,自动地发现市场分类,并自动地把顾客划分到不同的细分市场中
(4)天文数据分析
给出了令人惊讶、有趣、有用的理论,解释了星系是如何诞生的。
(5)鸡尾酒宴问题
区分出两个音频资源,这两个可以合成或合并成之前的录音
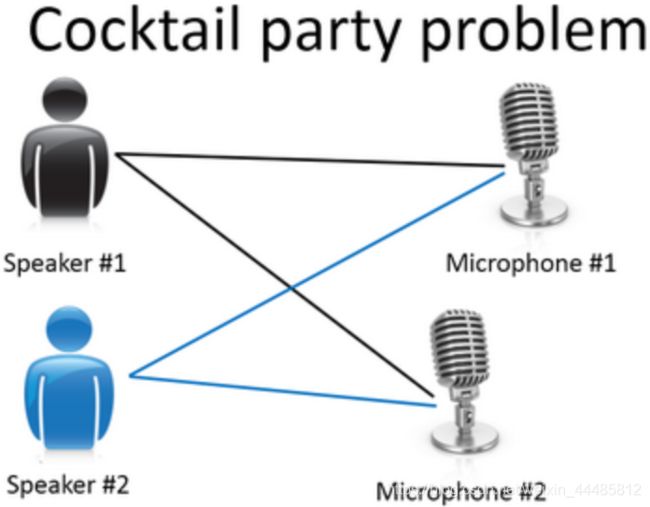
这个算法对应鸡尾酒宴问题可以就用一行代码来完成:
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
聚类只是无监督学习中的一种
1、垃圾邮件问题,如果你有标记好的数据,区别好是垃圾还是非垃圾邮件,我们把这个当作监督学习问题
2、糖尿病,改用糖尿病或没病,所以是监督学习
3、新闻事件分类,可以用一个聚类算法来聚类这些文章到一起,所以是无监督学习
4、细分市场,只是拿到算法数据,再让算法去自动地发现细分市场,所以是无监督学习问题
2 单变量线性回归
2.1 模型表示
(1)预测住房价格
使用一个数据集,数据集包含某市住房价格,根据不同房屋尺寸所售出的价格,画出数据集,可以构建一个模型,也许是条直线。如果房子是1250平方尺大小,这房子能卖多少钱?从这个数据模型上来看,能以大约220000(美元)左右的价格卖掉这个房子,就是监督学习算法的一个例子。

监督学习是因为对于每个数据来说,我们给出了“正确的答案”。根据我们的数据来说,房子实际的价格是多少,而且,更具体来说,这是一个回归问题,回归是指我们根据之前的数据预测出一个准确的输出值,对于这个例子就是价格。
还有另一种监督学习方式,叫做分类问题,当我们想要预测离散的输出值,例如,我们正在寻找癌症肿瘤,并想要确定肿瘤是良性的还是恶性的,这就是0/1离散输出的问题。
在监督学习中我们有一个数据集,这个数据集被称训练集。
用小写的m来表示训练样本的数目
假设回归问题的训练集如下表:
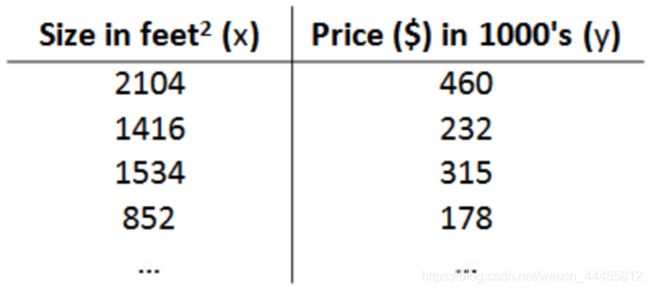
m m m:代表训练集中实例的数量
x x x:代表特征/输入变量
y y y:代表目标变量/输出变量
( x , y ) (x,y) (x,y):代表训练集中的实例
( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)):代表第 i i i个观察实例
h h h:代表学习算法的解决方案或函数也称为假设(hypothesis)

这是一个监督学习算法的工作方式,有我们的训练集里房屋价格,我们把它喂给我们的学习算法,学习算法输出一个函数,通常表示为小写h表示。 h代表hypothesis(假设),h表示一个函数,输入是房屋尺寸大小,就像你朋友想出售的房屋,因此h根据输入的x值来得出y值,y值对应房子的价格。因此,h是一个从x到y的函数映射。
选择最初的使用规则 h h h代表hypothesis,因而,要解决房价预测问题,我们实际上是要将训练集“喂”给我们的学习算法,进而学习得到一个假设,然后将我们要预测的房屋的尺寸作为输入变量输入给,预测出该房屋的交易价格作为输出变量输出为结果。
对于我们的房价预测问题,我们该如何表达 ?一种可能的表达方式为: h θ ( x ) = θ 0 + θ 1 x h_\theta(x)=\theta_0+\theta_1x hθ(x)=θ0+θ1x,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
2.2 代价函数

在线性回归中我们有一个像这样的训练集, m m m代表了训练样本的数量,比如 m = 47 m=47 m=47。而我们的假设函数,也就是用来进行预测的函数,是这样的线性函数形式: h θ ( x ) = θ 0 + θ 1 x h_\theta(x)=\theta_0+\theta_1x hθ(x)=θ0+θ1x。
我们现在要为我们的模型选择合适的参数(parameters) θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1,在房价问题这个例子中便是直线的斜率和在 y y y 轴上的截距。
选取不同的参数 θ 0 θ_0 θ0 和 θ 1 θ_1 θ1,产生的 h 不同,最终的直线也不同:
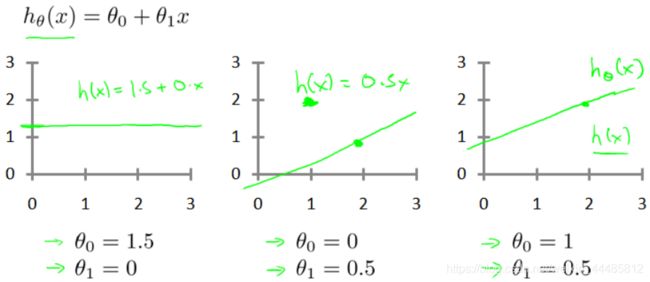
选择的参数决定了我们得到的直线相对于我们的训练集的准确程度。模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
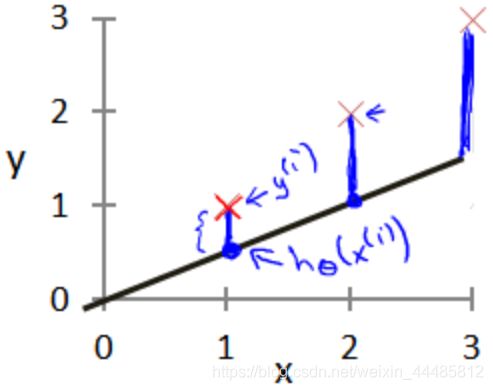
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价函数 J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2 J(θ0,θ1)=2m1∑i=1m(hθ(x(i))−y(i))2最小。
绘制一个等高线图,三个坐标分别为 θ 0 \theta_0 θ0、 θ 1 \theta_1 θ1和 J ( θ 0 , θ 1 ) J(\theta_0,\theta_1) J(θ0,θ1)
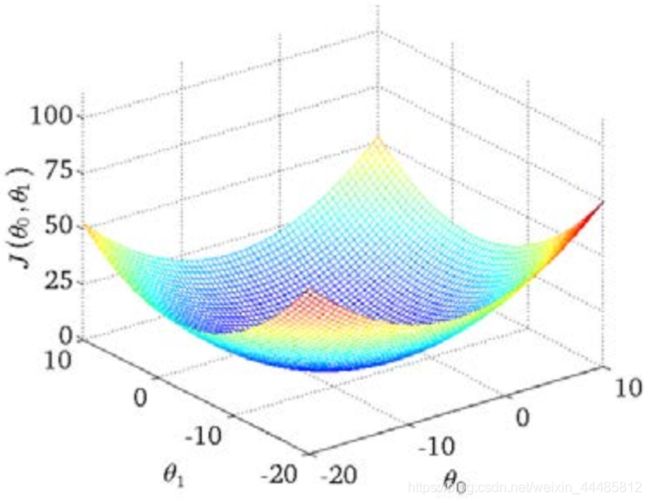 可以看出在三维空间中存在一个使得 J ( θ 0 , θ 1 ) J(\theta_0,\theta_1) J(θ0,θ1)最小的点
可以看出在三维空间中存在一个使得 J ( θ 0 , θ 1 ) J(\theta_0,\theta_1) J(θ0,θ1)最小的点
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
2.3 代价函数的直观理解I
线性回归模型的假设、参数、代价函数、目标如下:
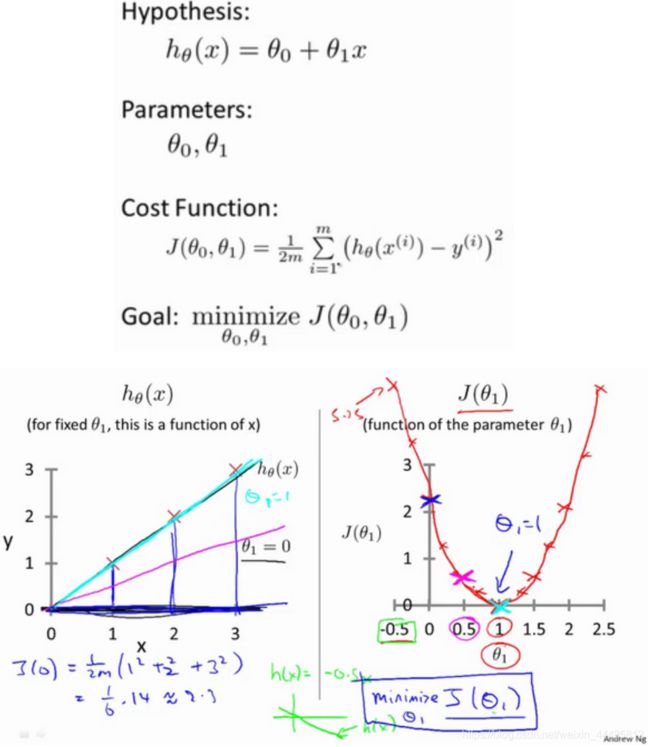
取将 θ 0 θ_0 θ0 固定为 0 时,代价函数简化为只关于 θ 1 θ_1 θ1 的函数:
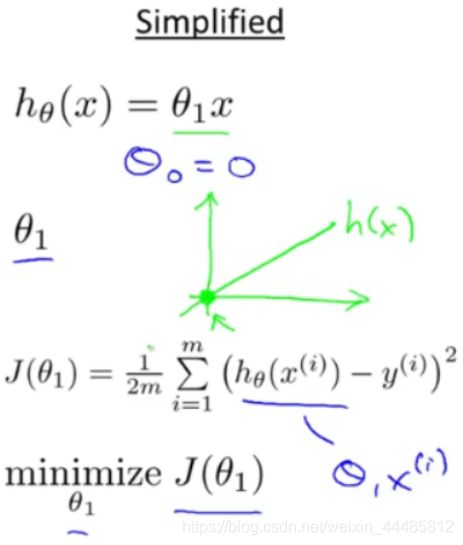
下面的例子里,三个数据点的坐标是(1,1)(2,2)(3,3)。当将 θ 0 θ_0 θ0 固定为 0,只变化 θ 1 θ_1 θ1时,代价函数是一条二次曲线。
当 θ 1 θ_1 θ1 分别取值 1,0.5,0 的时候,对应左边从上到下三条曲线。
当 θ 1 θ_1 θ1 取1时, J ( θ 1 ) J(θ_1) J(θ1) = 0 , 此时 J ( θ 1 ) J(θ_1) J(θ1) 最小,处于曲线最低点,是我们想要的结果。
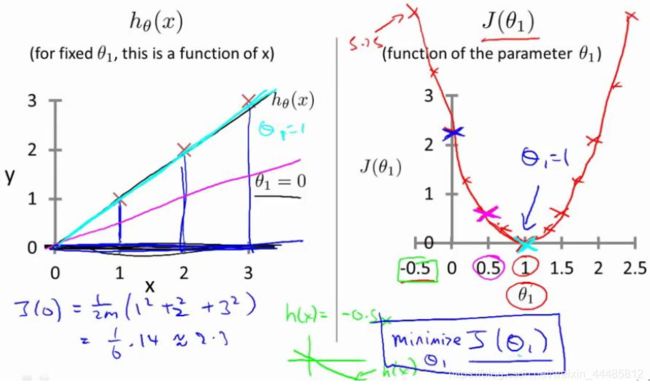
2.4 代价函数的直观理解II
当 θ0 和 θ1 都发生变化时,代价函数 J(θ0 , θ1) 在三维空间中图形如下:
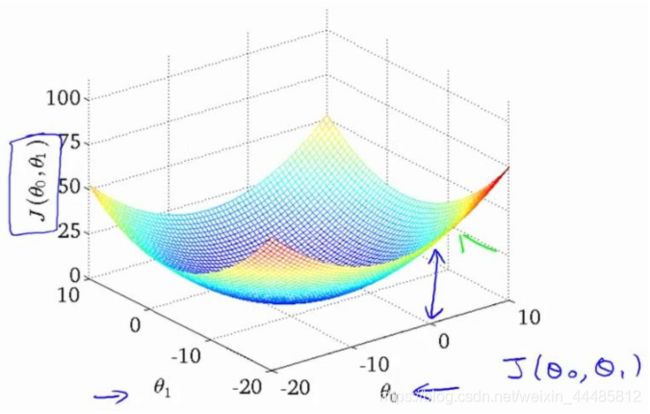
因为三维图像看起来太复杂, 将它投射到二维平面。引入等高线(contour plot)的概念,也叫contour figure。等高线上的点,对应的代价函数 J ( θ 0 , θ 1 ) J(θ_0 , θ_1) J(θ0,θ1) 取值相同。
下面两个图,右边红点对应的直线如左图,可以看出拟合的都不好。

下图取值位于三维图形的最低点,在二维图形上位于等高线的中心。对应的假设函数 h(x) 直线如左图。虽然拟合数据有一些误差(蓝色竖线),但是已经很接近最小值了。
2.5 梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数 J ( θ 0 , θ 1 ) J(θ_0 , θ_1) J(θ0,θ1)的最小值。
梯度下降的思想是:开始时我们随机选择一个参数的组合 ( θ 0 , θ 1 , ⋯ , θ n ) (θ_0,θ_1,\cdots,θ_n) (θ0,θ1,⋯,θn) ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
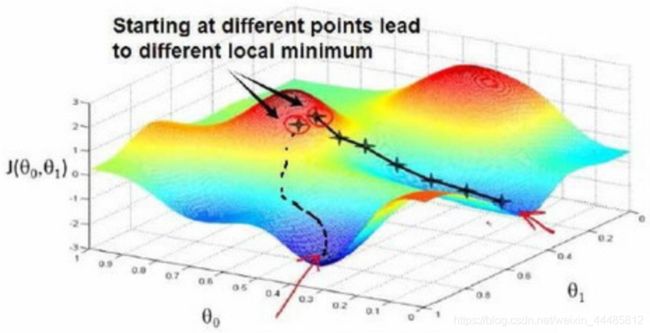
想象一下你站立在公园这座红色山上,在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。
已有一个代价函数,我们的目的是使其最小化。通常情况下,始于 θ 0 = 0 , θ 1 = 0 θ_0=0 , θ_1=0 θ0=0,θ1=0,调整 θ 0 , θ 1 θ_0 , θ_1 θ0,θ1,止于 J ( θ 0 , θ 1 ) J(θ_0 , θ_1) J(θ0,θ1)的最小值。

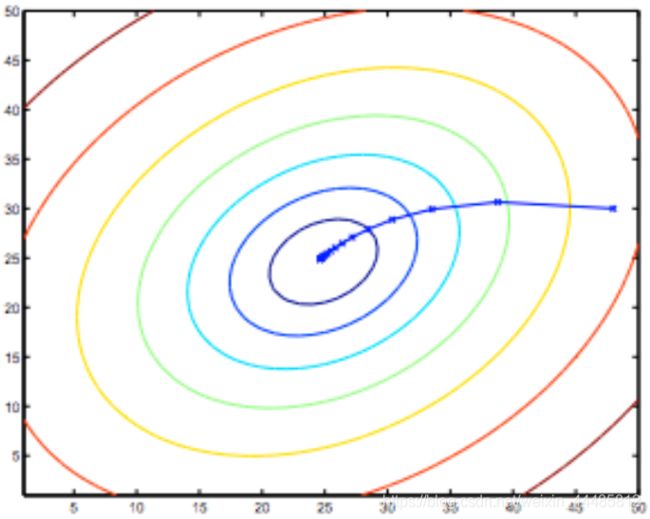
下面这个例子, θ 0 θ_0 θ0 和 θ 1 θ_1 θ1 没有开始于 ( 0 , 0 ) (0,0) (0,0) 。当选取两个不同的起始点,并向着不同方向进行梯度下降时,到达两个不同的最优解,它们称为局部最优解(local optimum)。

梯度下降算法对 θ 赋值, 使得 J(θ) 按梯度下降最快方向进行, 一直迭代下去, 最终得到局部最小值,即收敛 (convergence)。梯度下降算法不只用于线性回归, 可以用来最小化任何代价函数 J。公式如下:
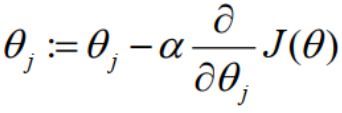
批量梯度下降(batch gradient descent)算法的公式为:
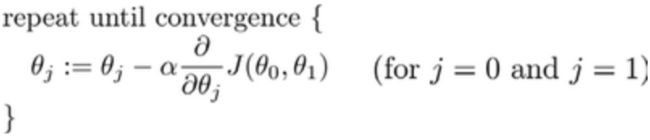
其中 α \alpha α 是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
a : = b a := b a:=b 是赋值操作 assignment ,将 b 的值赋值给 a。
a = b a = b a=b 是真假判断Truth assertion,判断 a 和 b 是否相等。

在这个表达式中,如果你要更新这个等式,你需要同时更新 θ 0 \theta_0 θ0 和 θ 1 \theta_1 θ1
θ 0 : = θ 0 \theta_0 := \theta_0 θ0:=θ0,并更新 θ 1 : = θ 1 \theta_1 := \theta_1 θ1:=θ1
计算公式右边的部分,通过那一部分计算出 θ 0 \theta_0 θ0 和 θ 1 \theta_1 θ1 的值,然后同时更新 θ 0 \theta_0 θ0 和 θ 1 \theta_1 θ1
同时更新是梯度下降中的一种常用方法,
梯度下降算法中,两个参数 同步更新 simultaneous update(左下)。如果是非同步更新 non-simultaneous update (右下),则不是梯度下降。

2.6 梯度下降的直观理解
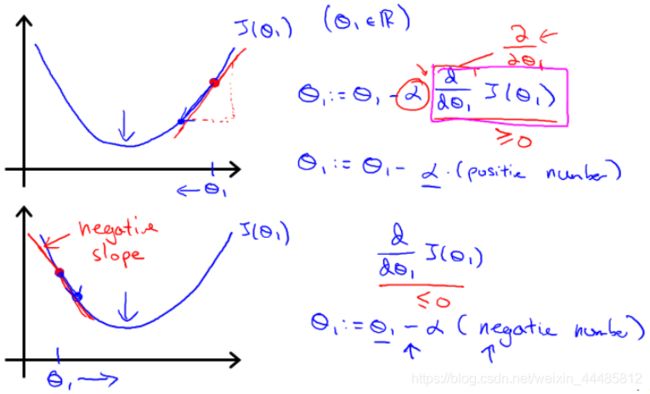
梯度下降算法如下: θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j:=\theta_j-\alpha\frac{∂}{∂\theta_j}J(\theta) θj:=θj−α∂θj∂J(θ)
对 θ \theta θ 赋值,使得 J ( θ ) J(\theta) J(θ) 按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。其中 α \alpha α 是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。
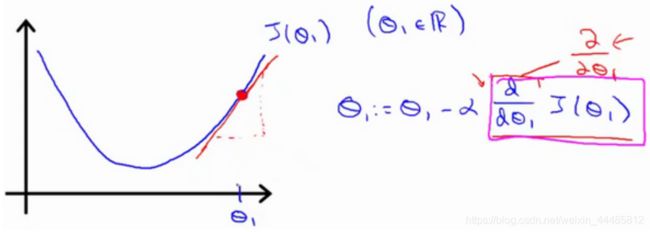
求导的目的是取这个红点的切线,这条线有一个正斜率,也就是说它有正导数,因此,我得到的新的 θ 1 \theta_1 θ1, θ 1 \theta_1 θ1 更新后等于 θ 1 \theta_1 θ1 减去一个正数乘以 α \alpha α 。
曲线右侧斜率为正,导数为正。 因此,θ1 减去一个正数乘以 α,值变小。
曲线左侧斜率为负,导数为负。 因此,θ1 减去一个负数乘以 α,值变大。
这就是梯度下降法的更新规则: θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j:=\theta_j-\alpha\frac{∂}{∂\theta_j}J(\theta) θj:=θj−α∂θj∂J(θ)
如果 α \alpha α太小,即我的学习速率太小,结果就是只能这样像小宝宝一样一点点地挪动,去努力接近最低点,这样就需要很多步才能到达最低点,所以如果 α \alpha α太小的话,可能会很慢,因为它会一点点挪动,它会需要很多步才能到达全局最低点。
如果 α \alpha α太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果 α \alpha α太大,它会导致无法收敛,甚至发散。

如果我们预先把 θ 1 \theta_1 θ1 放在一个局部的最低点,它已经在一个局部的最优处或局部最低点。结果是局部最优点的导数将等于零,因为它是那条切线的斜率。这意味着你已经在局部最优点,它使得不再改变,也就是新的等于原来的,因此,如果你的参数已经处于局部最低点,那么梯度下降法更新其实什么都没做,它不会改变参数的值。这也解释了为什么即使学习速率保持不变时,梯度下降也可以收敛到局部最低点。
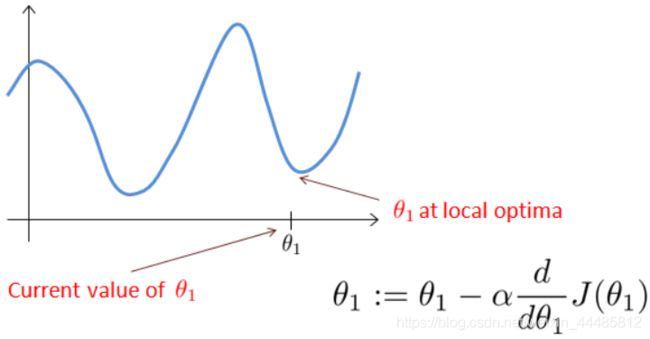
来看一个例子,这是代价函数 J ( θ ) J(\theta) J(θ)

我想找到它的最小值,首先初始化我的梯度下降算法,在那个品红色的点初始化,如果我更新一步梯度下降,也许它会带我到这个点,因为这个点的导数是相当陡的。现在,在这个绿色的点,如果我再更新一步,你会发现我的导数,也即斜率,是没那么陡的。随着我接近最低点,我的导数越来越接近零,所以,梯度下降一步后,新的导数会变小一点点。然后我想再梯度下降一步,在这个绿点,我自然会用一个稍微跟刚才在那个品红点时比,再小一点的一步,到了新的红色点,更接近全局最低点了,因此这点的导数会比在绿点时更小。所以,我再进行一步梯度下降时,我的导数项是更小的, θ 1 \theta_1 θ1 更新的幅度就会更小。所以随着梯度下降法的运行,你移动的幅度会自动变得越来越小,直到最终移动幅度非常小,你会发现,已经收敛到局部极小值。
在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是梯度下降的做法。所以实际上没有必要再另外减小 α \alpha α 。
梯度下降算法,可以用它来最小化任何代价函数 J J J ,不只是线性回归中的代价函数 J J J 。
用代价函数 J J J ,线性回归中的代价函数。也就是我们前面得出的平方误差函数,结合梯度下降法,以及平方代价函数,我们会得出第一个机器学习算法,即线性回归算法。
2.7 梯度下降的线性回归
梯度下降是很常用的算法,它不仅被用在线性回归上和线性回归模型、平方误差代价函数。在这段视频中,我们要将梯度下降和代价函数结合。我们将用到此算法,并将其应用于具体的拟合直线的线性回归算法里。
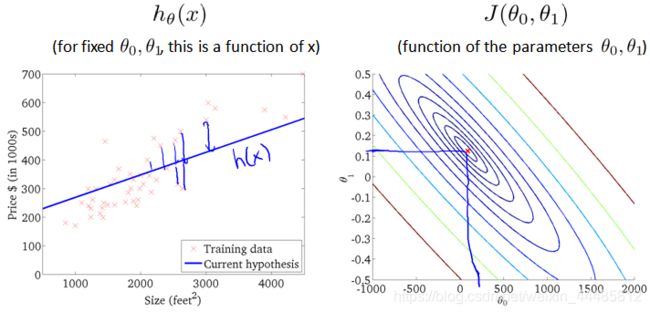
梯度下降算法和线性回归算法比较如图:

对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
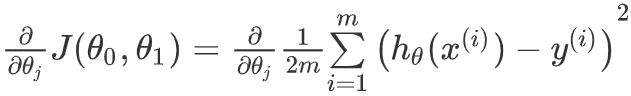
j 分别取 0 和 1 时,其导数如下:
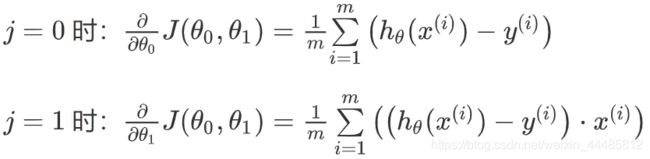
将上面两个导数带入梯度下降算法中,替代原来的 ∂ ∂ θ j J ( θ 0 , θ 1 ) \frac{\partial}{\partial\theta_j}J(\theta_0,\theta_1) ∂θj∂J(θ0,θ1) 。梯度下降算法变为:

虽然梯度下降一般易受局部最小值影响(susceptible to local minima),但我们在线性回归中提出的优化问题只有一个全局最优解,而没有其他局部最优解,代价函数是凸二次函数。因此,梯度下降总是收敛到全局最小值(假设学习率α不是太大)。
这个算法,有时也称批量梯度下降。在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有 m m m 个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本。有时也有其他类型的梯度下降法,不是这种"批量"型的,不考虑整个的训练集,而是每次只关注训练集中的一些小的子集。
掌握批量梯度算法,并且能把它应用到线性回归中,这就是用于线性回归的梯度下降法。
3 线性代数回顾
3.1 矩阵和向量
这个是4×2矩阵,即4行2列,如为 m m m 行, n n n 为列,那么 m × n m\times n m×n即 4×2

矩阵的维数即 行数×列数
矩阵元素(矩阵项):
A = [ 1402 191 1371 821 949 1437 147 1448 ] A=\left[ \begin{matrix} 1402 & 191 \\ 1371 & 821 \\ 949 & 1437 \\ 147 & 1448 \\ \end{matrix} \right] A=⎣⎢⎢⎡1402137194914719182114371448⎦⎥⎥⎤
A i j A_{ij} Aij 指第 i i i 行,第 j j j 列的元素
向量是一种特殊的矩阵,讲义中的向量一般都是列向量,如:
A = [ 460 232 315 178 ] A=\left[ \begin{matrix} 460 \\ 232 \\ 315 \\ 178 \\ \end{matrix} \right] A=⎣⎢⎢⎡460232315178⎦⎥⎥⎤
为四维列向量(4×1)。
如下图为1索引向量和0索引向量,左图为1索引向量,右图为0索引向量,一般我们用1索引向量。
y = [ y 1 y 2 y 3 y 4 ] y=\left[ \begin{matrix} y_1 \\ y_2 \\ y_3 \\ y_4 \\ \end{matrix} \right] y=⎣⎢⎢⎡y1y2y3y4⎦⎥⎥⎤ y = [ y 0 y 1 y 2 y 3 ] y=\left[ \begin{matrix} y_0 \\ y_1 \\ y_2 \\ y_3 \\ \end{matrix} \right] y=⎣⎢⎢⎡y0y1y2y3⎦⎥⎥⎤
3.2 加法和标量乘法
矩阵的加法:行列数相等的可以加。
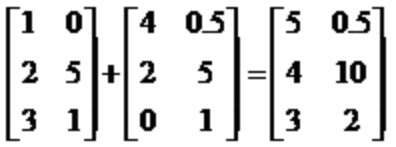
矩阵的乘法:每个元素都要乘

3.3 矩阵向量乘法
矩阵和向量的乘法如图: m × n m\times n m×n 的矩阵乘以 n × 1 n\times 1 n×1 的向量,得到的是 m × 1 m\times 1 m×1 的向量
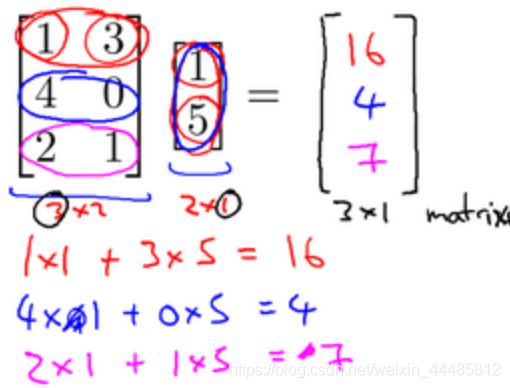
算法举例:

3.4 矩阵乘法
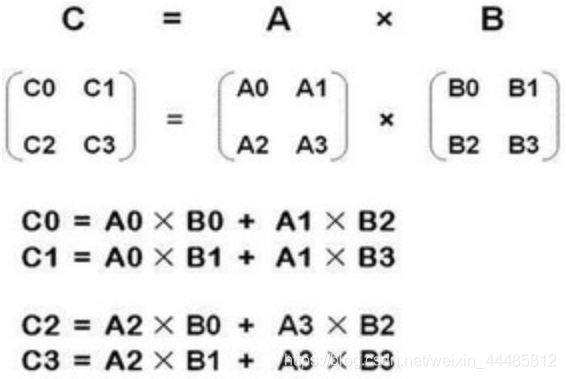
矩阵乘法:
m × n m\times n m×n 矩阵乘以 n × o n\times o n×o 矩阵,变成 m × o m\times o m×o 矩阵。
比如说现在有两个矩阵 A A A 和 B B B ,那么它们的乘积就可以表示为图中所示的形式。
3.5 矩阵乘法的性质
矩阵乘法的性质:
矩阵的乘法不满足交换律: A × B ≠ B × A A\times B\neq B\times A A×B=B×A
矩阵的乘法满足结合律。即: A × ( B × C ) = ( A × B ) × C A\times (B\times C)=(A\times B)\times C A×(B×C)=(A×B)×C
单位矩阵:在矩阵的乘法中,有一种矩阵起着特殊的作用,如同数的乘法中的1,我们称这种矩阵为单位矩阵.它是个方阵,一般用 I I I 或者 E E E 表示,本讲义都用 I I I 代表单位矩阵,从左上角到右下角的对角线(称为主对角线)上的元素均为1以外全都为0。如:
A A − 1 = A − 1 A = I AA^{-1}=A^{-1}A=I AA−1=A−1A=I
对于单位矩阵,有 A I = I A = A AI=IA=A AI=IA=A
3.6 逆、转置
矩阵的逆:如矩阵 A A A 是一个矩阵(方阵),如果有逆矩阵,则: A A − 1 = A − 1 A = I AA^{-1}=A^{-1}A=I AA−1=A−1A=I
没有逆矩阵的矩阵称为奇异矩阵(singular matrix) 或者退化矩阵(degenerate matrix)。
规则:
1、只有方阵有逆矩阵。
2、零矩阵没有逆矩阵 (还有其他一些矩阵没有逆矩阵,可以想成是一些特别接近零矩阵的矩阵)
matlab中逆矩阵: p i n v ( A ) pinv(A) pinv(A)
矩阵的转置:设 A A A 为 m × n m\times n m×n 阶矩阵(即 m m m 行 n n n 列),第 i i i 行 j j j 列的元素是 a ( i , j ) a(i,j) a(i,j),即: A = a ( i , j ) A=a(i,j) A=a(i,j)
定义 A A A 的转置为这样一个 n × m n\times m n×m 阶矩阵 B B B ,满足 B = a ( j , i ) B=a(j,i) B=a(j,i),即 b ( i , j ) = a ( j , i ) b(i,j)=a(j,i) b(i,j)=a(j,i)( B B B 的第 i i i 行第 j j j 列元素是 A A A 的第 j j j 行第 i i i 列元素),记 A T = B A^T=B AT=B 。(有些书记为 A ′ = B A'=B A′=B)
直观来看,将 A A A 的所有元素绕着一条从第1行第1列元素出发的右下方45度的射线作镜面反转,即得到 A A A 的转置。
例:
[ a b c d e f ] T = [ a c e b d f ] \left[ \begin{matrix} a & b \\ c & d \\ e & f \\ \end{matrix} \right]^T=\left[ \begin{matrix} a & c & e \\ b & d & f \\ \end{matrix} \right] ⎣⎡acebdf⎦⎤T=[abcdef]
矩阵的转置基本性质:
![]()
matlab中矩阵转置:直接打一撇, B = A ′ B=A' B=A′。