简单实现Transformer(Pytorch)
相关文章:
- 加性注意(原理)
- 加性注意(复现)
- 乘性注意(原理)
- 乘性注意(复现)
1 理论
该模型的特点:完全基于注意力机制,完全摒弃了递归和卷积。
它是一种模型架构,避免了递归,而是完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。
self-attention:有时也被称为内部注意,是一种将单个序列的不同位置联系起来以计算序列的表示形式的注意机制。
较于传统基于RNN/CNN的网络,减少了内部特征,因此用多头注意来抵消该影响,带该模型仍采用encoder-decoder框架。
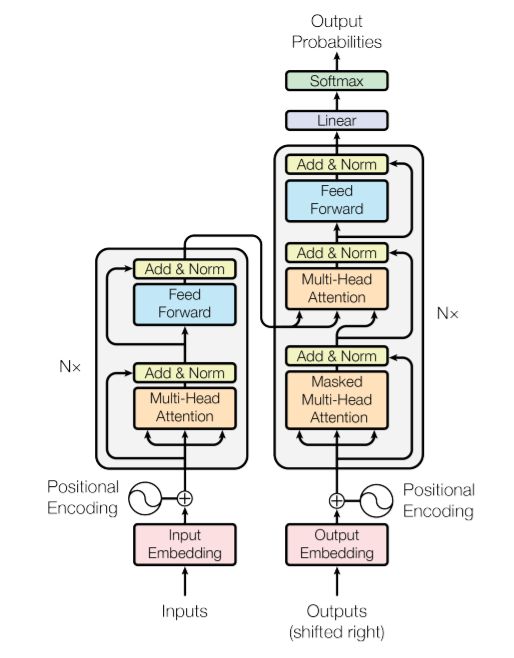
The Transformer - model architecture
2 实践
import torch
import torch.nn as nn
from torch import Tensor
from typing import Optional, Tuple
import numpy as np
import torch.nn.functional as F
import math
class ScaledDotAttention(nn.Module):
def __init__(self, d_k):
"""d_k: attention 的维度"""
super(ScaledDotAttention, self).__init__()
self.d_k = d_k
def forward(self, q: Tensor, k: Tensor, v: Tensor, mask: Optional[Tensor] = None) -> Tuple[Tensor, Tensor]:
# q:nqhd->nhqd, k:nkhd->nhkd->nhdk nhqd*nhdk->nhqk
score = torch.einsum("nqhd,nkhd->nhqk", [q, k]) / np.sqrt(self.d_k)
if mask is not None:
# 将mask为0的值,填充为负无穷,则在softmax时权重为0(被屏蔽的值不考虑)
score.masked_fill_(mask == 0, -float('Inf'))
attn = F.softmax(score, -1) # nhqk
# score:nhqk v:nkhd->nhkd nhqk*nhkd=nhqd=nqhd
context = torch.einsum("nhqk,nkhd->nqhd", [attn, v]) # nqhd
return context, attn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, num_heads=8):
"""
d_model: q/k/v 的输入维度
num_heads: attention的个数
"""
super(MultiHeadAttention, self).__init__()
self.d_model = d_model # 等于embedding_dim
self.num_heads = num_heads
assert d_model % num_heads == 0, "d_model % num_heads should be zero"
self.d_k = d_model // num_heads
self.scaled_dot_attn = ScaledDotAttention(self.d_k)
self.W_Q = nn.Linear(self.d_k, self.d_k, bias=False)
self.W_K = nn.Linear(self.d_k, self.d_k, bias=False)
self.W_V = nn.Linear(self.d_k, self.d_k, bias=False)
self.W_O = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask):
"""
query:(batch, q_len, d_model):来自前一个decoder层;来自输入;来自输出
key:(batch, k_len, d_model):来自编码器的输出;来自输入;来自输出
value:(batch, v_len, d_model):来自编码器的输出;来自输入;来自输出
"""
N = value.size(0) # batch_size
# 转化成8个注意,平行运行
query = query.view(N, -1, self.num_heads, self.d_k) # N*q_len*h*d
key = key.view(N, -1, self.num_heads, self.d_k) # N*k_len*h*d
value = value.view(N, -1, self.num_heads, self.d_k) # N*v_len*h*d ; k_len=v_len
query = self.W_Q(query)
key = self.W_K(key)
value = self.W_V(value)
context, attn = self.scaled_dot_attn(query, key, value, mask) # nhqk
context = self.W_O(context.reshape(N, query.size(1), self.num_heads * self.d_k)) # N*q_len*(h*d=d_model)
return context, attn
class PositionEncoding(nn.Module):
def __init__(self, d_model, max_len=500):
super(PositionEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
pe.requires_grad = False
for pos in range(max_len):
for i in range(d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i) / d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1)) / d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class EncoderBlock(nn.Module):
def __init__(self, d_model, d_ff, num_heads=8, dropout=0.1):
"""
dropout 应用于每一个子层
"""
super(EncoderBlock, self).__init__()
self.dropout = nn.Dropout(dropout)
self.attn = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.FFN = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)) # 前馈网络:两个线性+1个激活
def forward(self, query, key, value, mask):
context, _ = self.attn(query, key, value, mask)
# 跳跃连接
x = self.dropout(self.norm1(context + query))
forward = self.FFN(x)
out = self.dropout(self.norm2(x + forward))
return out
class DecoderBlock(nn.Module):
def __init__(self, d_model, d_ff, num_heads=8, dropout=0.1):
super(DecoderBlock, self).__init__()
self.norm = nn.LayerNorm(d_model)
self.attn = MultiHeadAttention(d_model, num_heads)
self.block = EncoderBlock(d_model, d_ff, num_heads, dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, x, key, value, src_mask, tgt_mask):
context, _ = self.attn(x, x, x, tgt_mask)
query = self.dropout(self.norm(context + x))
out = self.block(query, key, value, src_mask)
return out
完整代码:https://github.com/mengjizhiyou/pytorch_model/blob/main/Transformer