spider-flow初步使用
spider-flow初步使用
- 1、爬虫简介
- 2、spider-flow简介
- 3、spider-flow的简单使用
-
- 3.1、源码拉取
- 3.2、sql文件执行
- 3.3、修改配置文件
- 3.4、启动测试
- 4、用例测试
-
- 4.1、爬取站点分析
- 4.2、确定爬取信息
- 4.3、爬取信息
-
- 4.3.1、新建爬取任务
- 4.3.2、配置爬取url
- 4.3.3、配置页码和提取页面信息
- 4.3.4、遍历
- 4.3.5、所需信息提取
- 4.3.6、输出项测试
- 4.3.7、信息入库
1、爬虫简介
在介绍spider-flow之前,先大概了解什么是爬虫。借用百度百科的说法:网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫。
一句话小结:爬虫是一种用于获取网络数据的程序,这些数据可能来源于各个渠道,比如网页。
2、spider-flow简介
spider-flow是由国内开源的一款用Java开发的爬虫程序,简单好用。官方的介绍文档如下:

这个开源项目的源码已经被托管到了github和gitee中,我们可以直接在gitee上面进行搜索:


可以看到这是个GVP的项目,而且已经被Watch和Star了多次,是个非常有价值的开源项目。
3、spider-flow的简单使用
3.1、源码拉取
先从gitee上拉取项目源码:
这里选择master主分支拉取:
从eclipse中拉取项目,拉取下来的项目是这样的:

是一个聚合工程,里面有三个子模块,主要跑的是web模块。db里是建库及建表sql文件:

spiderflow.sql详细内容如下:
SET FOREIGN_KEY_CHECKS=0;
CREATE DATABASE spiderflow;
USE spiderflow;
DROP TABLE IF EXISTS `sp_flow`;
CREATE TABLE `sp_flow` (
`id` varchar(32) NOT NULL,
`name` varchar(64) DEFAULT NULL COMMENT '任务名字',
`xml` longtext DEFAULT NULL COMMENT 'xml表达式',
`cron` varchar(255) DEFAULT NULL COMMENT 'corn表达式',
`enabled` char(1) DEFAULT '0' COMMENT '任务是否启动,默认未启动',
`create_date` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`last_execute_time` datetime DEFAULT NULL COMMENT '上一次执行时间',
`next_execute_time` datetime DEFAULT NULL COMMENT '下一次执行时间',
`execute_count` int(8) DEFAULT NULL COMMENT '定时执行的已执行次数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '爬虫任务表';
INSERT INTO `sp_flow` VALUES ('b45fb98d2a564c23ba623a377d5e12e9', '爬取码云GVP', '\n \n \n \n {"spiderName":"爬取码云GVP","threadCount":""}\n \n \n \n \n \n \n {"shape":"start"}\n \n \n \n \n \n {"value":"抓取首页","loopVariableName":"","sleep":"","timeout":"","response-charset":"","method":"GET","body-type":"none","body-content-type":"text/plain","loopCount":"","url":"https://gitee.com/gvp/all","proxy":"","request-body":[""],"follow-redirect":"1","shape":"request"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"提取项目名、地址","loopVariableName":"","variable-name":["projectUrls","projectNames"],"loopCount":"","variable-value":["${extract.selectors(resp.html,'.categorical-project-card a','attr','href')}","${extract.selectors(resp.html,'.project-name')}"],"shape":"variable"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"抓取详情页","loopVariableName":"projectIndex","sleep":"","timeout":"","response-charset":"","method":"GET","body-type":"none","body-content-type":"text/plain","loopCount":"10","url":"https://gitee.com/${projectUrls[projectIndex]}","proxy":"","request-body":[""],"follow-redirect":"1","shape":"request"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"提取项目描述","loopVariableName":"","variable-name":["projectDesc"],"loopCount":"","variable-value":["${extract.selector(resp.html,'.git-project-desc-text')}"],"shape":"variable"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"输出","output-name":["项目名","项目地址","项目描述"],"output-value":["${projectNames[projectIndex]}","https://gitee.com${projectUrls[projectIndex]}","${projectDesc}"],"shape":"output"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n', null, '0', '2019-08-22 13:46:54', null, null, null);
INSERT INTO `sp_flow` VALUES ('f0a67f17ee1a498a9b2f4ca30556f3c3', '抓取每日菜价', '\n \n \n \n {"spiderName":"抓取每日菜价","threadCount":""}\n \n \n \n \n \n \n {"shape":"start"}\n \n \n \n \n \n {"value":"开始抓取","loopVariableName":"","sleep":"","timeout":"","response-charset":"","method":"GET","body-type":"none","body-content-type":"text/plain","loopCount":"","url":"http://www.beijingprice.cn:8086/price/priceToday/PageLoad/LoadPrice?jsoncallback=1","proxy":"","request-body":[""],"follow-redirect":"1","shape":"request"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"解析JSON","loopVariableName":"","variable-name":["jsonstr","jsondata","data"],"loopCount":"","variable-value":["${string.substring(resp.html,2,resp.html.length()-1)}","${json.parse(jsonstr)}","${extract.jsonpath(jsondata[0],'data')}"],"shape":"variable"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"输出","loopVariableName":"i","output-name":["菜名","菜价","单位"],"loopCount":"${list.length(data)}","output-value":["${data[i].ItemName}","${data[i].Price04}","${data[i].ItemUnit}"],"shape":"output"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n', null, '0', '2019-08-22 13:48:22', null, null, null);
INSERT INTO `sp_flow` VALUES ('b4430885ba8349588d1220d37eac831d', '爬取开源中国动弹', '\n \n \n \n {"spiderName":"爬取开源中国动弹","threadCount":""}\n \n \n \n \n \n \n {"shape":"start"}\n \n \n \n \n \n {"value":"爬取动弹","loopVariableName":"","sleep":"","timeout":"","response-charset":"","method":"GET","parameter-name":["type","lastLogId"],"body-type":"none","body-content-type":"text/plain","loopCount":"","url":"https://www.oschina.net/tweets/widgets/_tweet_index_list ","proxy":"","parameter-value":["ajax","${lastLogId}"],"request-body":"","follow-redirect":"1","tls-validate":"1","shape":"request"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"提取lastLogId以及tweets","loopVariableName":"","variable-name":["lastLogId","tweets","fetchCount"],"loopCount":"","variable-value":["${resp.selector('.tweet-item:last-child').attr('data-tweet-id')}","${resp.selectors('.tweet-item[data-tweet-id]')}","${fetchCount == null ? 0 : fetchCount + 1}"],"shape":"variable"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"循环","loopVariableName":"index","loopCount":"${list.length(tweets)}","shape":"loop"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"提取详细信息","loopVariableName":"","variable-name":["content","author","like","reply","publishTime"],"loopCount":"","variable-value":["${tweets[index].selector('.text').text()}","${tweets[index].selector('.user').text()}","${tweets[index].selector('.like span').text()}","${tweets[index].selector('.reply span').text()}","${tweets[index].selector('.date').regx('(.*?) ')}"],"shape":"variable"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"输出","loopVariableName":"","output-name":["作者","内容","点赞数","评论数","发布时间"],"loopCount":"","output-value":["${author}","${content}","${like}","${reply}","${publishTime}"],"shape":"output"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n \n \n \n \n \n \n {"value":"爬取5页","condition":"${fetchCount < 3}"}\n \n \n \n \n', '', '0', '2019-11-03 17:02:49', '2019-11-04 10:11:31', '2019-11-03 17:30:56', '3');
INSERT INTO `sp_flow` VALUES ('663aaa5e36a84c9594ef3cfd6738e9a7', '百度热点', '\n \n \n \n {"spiderName":"百度热点","threadCount":""}\n \n \n \n \n \n \n {"shape":"start"}\n \n \n \n \n \n {"value":"开始抓取","loopVariableName":"","sleep":"","timeout":"","response-charset":"gbk","method":"GET","body-type":"none","body-content-type":"text/plain","loopCount":"","url":"https://top.baidu.com/buzz?b=1&fr=topindex","proxy":"","request-body":"","follow-redirect":"1","tls-validate":"1","shape":"request"}\n \n \n \n \n \n {"value":"定义变量","loopVariableName":"","variable-name":["elementbd"],"loopCount":"","variable-value":["${resp.xpaths('//*[@id=\\"main\\"]/div[2]/div/table/tbody/tr')}"],"shape":"variable"}\n \n \n \n \n \n {"value":"输出","loopVariableName":"i","output-name":["名称","地址","百度指数","2"],"loopCount":"${elementbd.size()-1}","output-value":["${elementbd[i+1].xpath('//td[2]/a[1]/text()')}","${elementbd[i+1].xpath('//td[2]/a[1]/@href')}","${elementbd[i+1].xpath('//td[4]/span/text()')}","${elementbd[i+1].xpath('//td[3]/a[2]/text()')}"],"shape":"output"}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n \n {"value":"","condition":""}\n \n \n \n \n', '0 0/30 * * * ? *', '1', '2019-10-20 17:24:21', '2019-11-04 08:52:05', '2019-10-30 14:52:39', '45');
DROP TABLE IF EXISTS `sp_datasource`;
CREATE TABLE `sp_datasource` (
`id` varchar(32) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`driver_class_name` varchar(255) DEFAULT NULL,
`jdbc_url` varchar(255) DEFAULT NULL,
`username` varchar(64) DEFAULT NULL,
`password` varchar(32) DEFAULT NULL,
`create_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
DROP TABLE IF EXISTS `sp_variable`;
CREATE TABLE `sp_variable` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL COMMENT '变量名',
`value` varchar(512) DEFAULT NULL COMMENT '变量值',
`description` varchar(255) DEFAULT NULL COMMENT '变量描述',
`create_date` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
/* v0.3.0 新增 */
DROP TABLE IF EXISTS `sp_task`;
CREATE TABLE `sp_task` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`flow_id` varchar(32) NOT NULL,
`begin_time` datetime DEFAULT NULL,
`end_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4;
/* v0.4.0 新增 */
DROP TABLE IF EXISTS `sp_function`;
CREATE TABLE `sp_function` (
`id` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '函数名',
`parameter` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '参数',
`script` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT 'js脚本',
`create_date` datetime(0) NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
/* v0.5.0 新增 */
DROP TABLE IF EXISTS `sp_flow_notice`;
CREATE TABLE `sp_flow_notice` (
`id` varchar(32) NOT NULL,
`recipients` varchar(200) DEFAULT NULL COMMENT '收件人',
`notice_way` char(10) DEFAULT NULL COMMENT '通知方式',
`start_notice` char(1) DEFAULT '0' COMMENT '流程开始通知:1:开启通知,0:关闭通知',
`exception_notice` char(1) DEFAULT '0' COMMENT '流程异常通知:1:开启通知,0:关闭通知',
`end_notice` char(1) DEFAULT '0' COMMENT '流程结束通知:1:开启通知,0:关闭通知',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '爬虫任务通知表';
3.2、sql文件执行
执行上面的sql文件,会生成一个数据库,数据库里会建好6张表:

sp_datasource表存的是数据源信息:

sp_flow表存的是爬虫任务:


sp_flow_notice表存的是爬虫任务通知信息:

sp_function表存的是函数信息:

sp_task表存的是任务:

sp_variable是变量表,存的是变量相关信息:

3.3、修改配置文件
修改全局配置文件application.properties里的一些信息,如下:

将日志文件产生的根目录改为绝对路径。

然后是数据源连接信息改成自己的。
3.4、启动测试
启动web项目下的SpiderApplication.java来启动项目:
![]()
访问8088端口:

显示这样的页面说明项目启动成功了。可以看看官方提供的例子,比如第4个爬取码云的:

点击测试按钮:
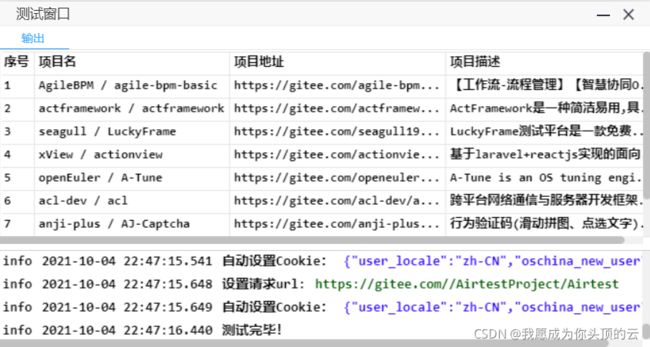
测试窗口有输出,说明爬取成功了。下面将自己写一个简单的例子来测试简单数据爬取。
4、用例测试
下面将使用spider-flow爬取一个电影网站里的电影信息。
4.1、爬取站点分析

我想爬取的是这种电影网站信息,首先查看网页源代码,看获取信息能否直接从网页中拿到,因为有的信息是js动态加载的。

可以直接从网页中获取,那么这种信息是可以拿到的。看最后一页:

那么这里可以获取的页数一共是2859页。然后看分析url:
![]()
假设当前页码为$ {page},那么获取页面的url为:https://www.80dytta.com/movie/0-0-0-0-0-$ {page}。
4.2、确定爬取信息

我想获取的信息有5条:电影名称、所属类型、清晰度、评分、封面图片地址。
4.3、爬取信息
4.3.1、新建爬取任务

![]()
4.3.2、配置爬取url

4.3.3、配置页码和提取页面信息

page参数直接用三元表达式,而movieList参数用选择器来选取,这里提取出来的是一个list集合信息,需要遍历提取所需信息。
4.3.4、遍历
上面的movieList是一个集合,需要遍历这个集合:

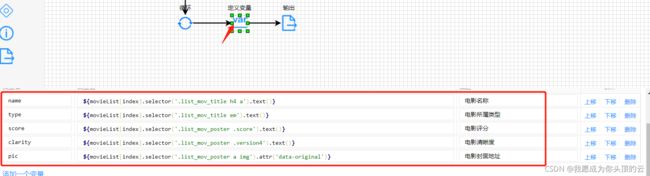
4.3.5、所需信息提取
遍历以上集合movieList,需要从集合中提取所需信息,使用选择器实现,如下:
4.3.6、输出项测试
先设定一个循环爬取次数,输出以上提取的信息来进行测试:

进行循环爬取的条件是当前页码小于10。配置输出项信息:

点击测试:

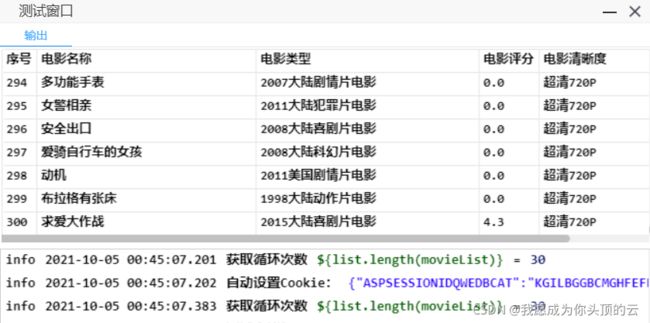
测试窗口输出了300条信息,刚好爬取的是前10页的数据,没问题。
4.3.7、信息入库
先创建一个数据源:


并且测试连接数据库,然后建表movie_datas准备存爬取的信息:

最后写SQL语句向数据库保存信息就行了。

还需要修改循环爬取的次数,改为2830次。

保存,然后运行该这个任务:
![]()
执行这个任务稍久,大概需要15分钟,运行完毕后查看数据库表:

一共是拿到了84899条数据,并且全部保存到了数据库中。来看一下9.0以上评分的电影有哪些:

479条,也就是0.56%的概率,哈哈,果然可以的。