搭建CNN卷积神经网络(用pytorch搭建)
手撕卷积神经网络—CNN
卷积:提取特征
池化:压缩特征
heigh X weigh X depth
长度 宽度。深度(也就是特征图个数)
例如输入32x32x3 hxwxc
卷积就是取某个小区域进行特征计算用此处的 特征值x权重特征 进而得到最终数据输出
filter相当于助手可以有一个 但是也可以有多个 可以定义f1 f2 f3…当然得到特征图越丰富越是我们想要的结果但是多个卷积核的容积必须是相同 否则则无法相加。
移动步长 可以大一点也可以小一点用1就可以
卷积核尺寸 可以大一点 也可以小一点 大的话就比较粗糙 小的话提取特征就相对比较精细。3x3最好
边界尺寸 就是可以命名为0
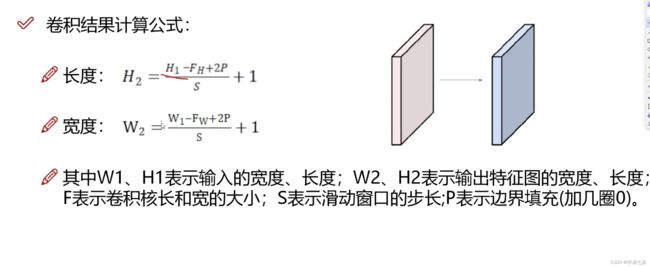
计算方法
池化 (也是特征压缩)
也可以称为下采样 就是选取特征最大的部分就是最大池化Maxpooling和卷积一样就是筛选而已没有矩阵的计算。
基本正常的卷积神经网络都是两次卷积一次池化 进而进行压缩和筛选
全连接层
其实在最后还需要有一个拉长的过程 将立体的图形拉长为特征向量。
只有带计算的才可以称为层 如图就是七层的卷积神经网络。
经典卷积神经网络
1.Alexnet
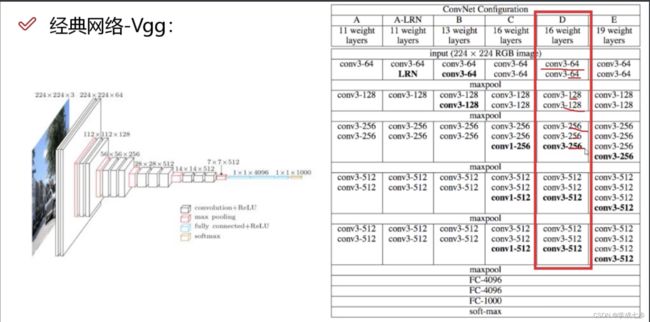
2.VGG
3.resnet
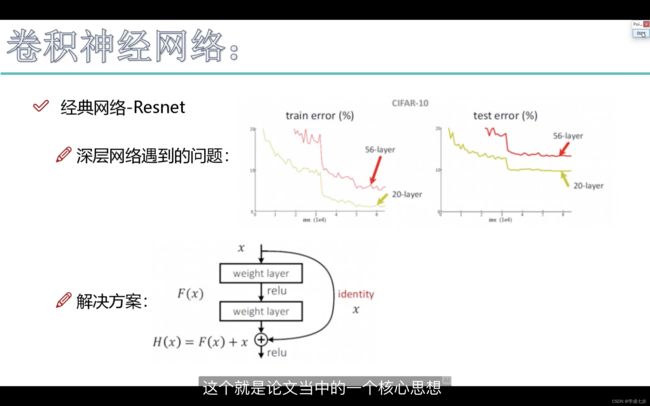
resnet核心思想就是加一个同等映射如果学习无法使loss下降 那么我们有一个保底的卷积 就直接把上面的拿过来。那么也就称为其为残差网络。
无论将来做什么 做残差网络是一个首选项
因为resnet以出色的表现完全可以证明深度学习卷积的层数是完全可以继续往下堆叠的 尽管他的提升比较少 。
resnet不属于分类 属于一个特征提取的问题。属于一个万能网络
实例
import torch
import torch.nn as nn
from torchvision import datasets
from torchvision import transforms
#定义超参数
inputsize = 228
num_classes = 2
num_epoche = 3
batch_size = 64
#构建训练数据
train_dateset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True
)
#构建测试数据
test_dateset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor(),
)
#构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dateset,
batch_size = batch_size,
shuffle=True
)
test_loader = torch.utils.data.DataLoader(dataset=test_dateset,
batch_size = batch_size,
shuffle=True
)
#定义CNN 卷积神经网络组合一般组合为 卷积+激活函数(relu)+池化 大概什么网络都是这样的顺序
#我们可以设计一次卷积+relu 就直接maxpooling 或者两次三次都可以
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__() #意思是初始化继承CNN的类
#第一层卷积的构建nn下面的Sequential函数一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
#第一个卷积模块
self.conv1= nn.Sequential(
nn.Conv2d(
in_channels=1, #输入的特征图像 传入为灰度图
out_channels=16, #输出 要得到多少个特征图
kernel_size=5, #卷积核的大小
stride=1, #步长
padding=2, #边缘填充1就是加一圈0 2就是加两圈0 #如何希望卷积后大小和原来一样,需设置 TODO padding=(kernel_size-1)/2 如果步长为1的情况下
),
nn.ReLU(), #relu层 激活函数
nn.MaxPool2d(kernel_size=2), #进行池化操作(2x2区域),输出结果为:(16,14,14)
)
#定义第二个卷积核 下面的Sequential函数定义重新一个容器
self.conv2 = nn.Sequential( #下一个输出(16,14,14)
#要前后对应 前面输入特征为1 输出为16 那这边就要继承前面的16 变成输入层 所以就是16个特征值喽 那么后面就是输出
nn.Conv2d(16,32,5,1,2), #输出 (32,14,14)
nn.ReLU(), #relu层 激活函数
nn.MaxPool2d(2), #输出(32,7,7)
)
#最终得到一个32x7x7一个立体的转为一个大矩阵所以转换成全连接层
self.out=nn.Linear(32*7*7,10) #全连接层得到的结果
##@总结----------------------------------------------------
##输入图像 28x28x1===> 长度-卷积核+2*边缘/步长 +1= 28-5+2x2/1+1=28
## 第一层conv1 ====>28x28x16经过pooling层====>14x14x16
## 第二层conv2 ====> 14-5+2x2/1+1=14 ====> 14x14x32经过pooling层=====>7x7x32
##@----------------------------------------------------
#前向传播
def forward(self,x):
x= self.conv1(x)
x= self.conv2(x)
x= x.view(x.size(0),-1) #flatten操作 结果为(batch_size,32*7*7)
output = self.out(x)
#转成向量的格式
return output
#准确率作为评估标准
def accuracy(predictions,labels):
pred = torch.max(predictions.data,1)[1]
rights=pred.eq(labels.data.view_as(pred)).sum()
return rights,len(labels)
#实例化
net=CNN()
#损失函数
critertion=nn.CrossEntropyLoss()
#优化器
optimizer =torch.optim.Adam(net.parameters(),lr=0.001) #定义优化器,普通的随机梯度下降算法
#开始循环训练
for epoch in range(num_epoche):
#保存当前epoch结果
train_rights=[]
for batch_idx,(data,target) in enumerate(train_loader):#针对容器中的每一个批进行循环
net.train() #更新权重参数
output=net(data)
loss=critertion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right =accuracy(output,target)
train_rights.append(right)
if batch_idx %100==0:
net.eval()
val_rights=[]
for (data,target) in test_loader:
output=net(data)
right=accuracy(output,target)
val_rights.append(right)
#准确率计算
train_r=(sum([tup[0]for tup in train_rights]),sum([tup[1] for tup in train_rights]))
val_r=(sum([tup[0]for tup in val_rights]),sum([tup[1] for tup in val_rights]))
print('当前epoch:{}[{}/{}({:.0f}%)]\t损失:{:.6f}\t训练集准确率:{:.2f}\t测试集正确率:{:.2f}%'
.format(epoch,batch_idx*batch_size,len(train_loader.dataset),100.*batch_idx/len(train_loader),
loss.data,
100.*train_r[0].numpy()/train_r[1],
100.*val_r[0].numpy()/val_r[1]))
训练结果:
结果相对来说还可以