pytorch以图搜图作业
测验名称:以图搜图
测验内容:使用已有网络模型(vgg,resnet等)对图像进行特征提取(不要分类),根据获得的特征对图像的相似度进行排序。
例:给出一张图像后,在整个数据集中(至少100个样本)找到与这张图像相似的图像(至少5张),并把图像有顺序的展示。
首先, 看一下数据集。在val下有两个文件夹, imges_20下面有100张图片, 分别从5个类别中随机抽取一些组成, images_1文件夹下有一张图片,是向日葵图片。 也就是说,用这一张图片, 去images_20文件夹中选出最相似的5张图片。
下面是用到的一些库。
import torch
import torch.nn as nn
from torchvision.transforms import transforms
import torch.optim as optim
from torchvision import models
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
from PIL import Image
import os
import torch.nn.functional as F
import matplotlib.pyplot as plt1) 搞定数据集。 如果不知道pytorch怎么制作数据集,移步pytorch加载自己的图片数据集的两种方法 https://blog.csdn.net/qq_53345829/article/details/124308515
https://blog.csdn.net/qq_53345829/article/details/124308515
在这里, 我使用的是定义自己的类来构建数据集, 并且只返回图片信息, 不返回label。会在对应文件夹里面生成一个txt文件,txt文件包含图片的路径。
#用来生成对应txt文件
def mak_txt(root, file_name):
path = os.path.join(root, file_name)
data = os.listdir(path)
f = open(path + '\\' + 'f.txt', 'w')
for line in data:
if line=='f.txt':
continue
f.write(line+'\n')
f.close()
#加载数据集
train_path_20 = r'D:\dataset_deep_learning\image2image_datasets\train\100'
train_path_1 = r'D:\dataset_deep_learning\image2image_datasets\train\1'
path = r'D:\dataset_deep_learning\image2image_datasets\train'
mak_txt(path, '100')
mak_txt(path, '1')
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
class MyDataset(Dataset):
def __init__(self, img_path, transform=None):
super(MyDataset, self).__init__()
self.img_path = img_path
self.txt_root = img_path + r'\f.txt'
f = open(self.txt_root, 'r')
data = f.readlines()
imgs = []
for line in data:
line.strip()
word = line.split()
imgs.append(os.path.join(self.img_path, word[0]))
self.img = imgs
self.transform = transform
def __len__(self):
return len(self.img)
def __getitem__(self, item):
img = self.img[item]
img = Image.open(img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img
#加载数据集
dataset_1 = MyDataset(train_path_1, transform=transform)
dataset_20 = MyDataset(train_path_20, transform=transform)
data_loader_1 = DataLoader(dataset=dataset_1, batch_size=1, shuffle=False)
data_loader_20 = DataLoader(dataset=dataset_20, batch_size=100, shuffle=False)2) 开始预训练模型, 加载vgg11网络 , 如果不知道pytorch如何修改网络结构,移步:vgg网络层的增, 删, 改 https://blog.csdn.net/qq_53345829/article/details/124641236
https://blog.csdn.net/qq_53345829/article/details/124641236
#加载 vgg11网络
net = models.vgg11(pretrained=True)
#去除全连接层和 avgpool层, 并且给最后一个卷积层改成通道数为1的
net.classifier = nn.Sequential()
net.features[18] = nn.Conv2d(512, 1, kernel_size=3, stride=1, padding=1)
net.avgpool = nn.Sequential()修改网络结构前的vgg11:
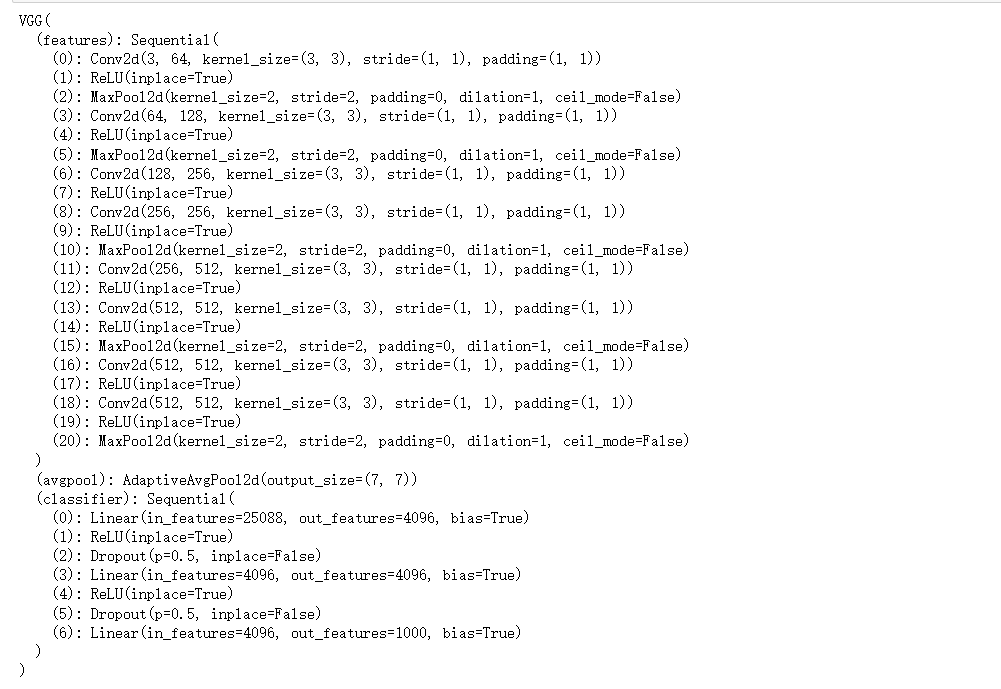
修改网络结构后vgg11:

3)开始使用vgg11网络, 这里不再训练了, 因为加载的是已经训练过的模型,直接使用就好。
#开始输入数据
for i, data in enumerate(data_loader_1):
output_1 = net(data)
for i, data in enumerate(data_loader_20):
output_20 = net(data)
print(output_1.shape)
print(output_20.shape)
#调用F库中的欧氏距离方法
dist2 = F.pairwise_distance(output_1,output_20, p=2)
print(dist2.shape) #torch.Size([100])现在我们已经有了网络的输出, 我们获得损失值最小的5个值的索引。并且之前已经创建过100张图片的txt文件, 现在获得了索引, 利用索引, 找到这些索引对应的图片, 显示图片即可
max_list = []
for i in range(5):
max_n = torch.argmin(dist2)
max_list.append(int(max_n))
dist2[max_n] = 9999999.9
print(max_list) #[24, 84, 37, 39, 14]
#打开图片路劲的txt文件
path_dir = train_path_20 + r'\f.txt'
f = open(path_dir, 'r')
data = f.readlines()
train_path_20 = r'D:\dataset_deep_learning\image2image_datasets\train\100'
data_img = []
for i in range(5):
img_path = os.path.join(train_path_20, data[max_list[i]])
data_img.append(img_path)接下来使用matplotlib显示5张图片:
fig = plt.figure(figsize=(10,10)) #创建画布,每个画布10*10大小
for i in range(1,6):
ax = fig.add_subplot(5,1,i) #创建一个5行1列的画布, 遍历依次为第1个,第2个画布
img = Image.open(data_img[i-1].strip()) #因为图片是从0开始, 画布需要从1开始
ax.imshow(img)
pass
plt.show()看一下预测结果吧:(结果还行, 有一张预测错误了)
