EMNLP 2022 | 基于全局句向量的分布外文本检测

©PaperWeekly 原创 · 作者 | 陈思硕
单位 | 北京大学
研究方向 | 自然语言处理
本文为北京大学的研究者提出的从句向量(Sentence Embedding)角度改进分布外文本检测的工作,其核心思想是从所有中间层、所有 token 的隐状态提取全局句向量(Holistic Sentence Embeddings)来加强句向量中的通用语义信息,从而提升基于特征空间距离的分布外文本检测算法的表现。日前,该论文被 Findings of EMNLP 2022 接收。

论文标题:
Holistic Sentence Embeddings for Better Out-of-Distribution Detection
论文链接:
https://arxiv.org/pdf/2210.07485.pdf
收录会议:
Findings of EMNLP 2022

背景与动机
1.1 问题背景
预训练-微调已经成为自然语言理解任务的通用范式,但微调后的预训练语言模型在面对与训练集分布不同的分布外数据(OOD data)时,容易给出过高的置信度 [1],威胁到开放世界中模型部署的安全性。因此,基于预训练模型的文本分布外检测(textual ODD detection)近年来颇受关注。该问题的本质是一个二分类问题,分类模型除了给出分布内的类别标签预测外,还需要对测试样本 给出置信度分数 以进行 OOD detection 的决策:

其中 越高,表示检测器 越倾向于认为 是分布内(in-distribution,ID)样本; 则为用户选定的阈值。
1.2 研究动机
OOD detection 的实质即如何得到置信度分数 ,以区分测试数据中的 ID 和 OOD 样本。目前在 NLP 领域中,基于特征空间的系列方法(distance-based methods)取得了最优的表现并受到了诸多研究者关注 [2][3][4]。其核心思想是估计分布内数据在神经网络特征空间中的分布,以测试样本 到该分布的距离(取负数)作为置信度分数 。
其中一个经典的强 baseline 是基于马氏距离(Mahalanobis Distance)的算法,即将分布内数据建模型为类别条件高斯分布,以到最近的类中心的马氏距离取负作为 ,形式如下:
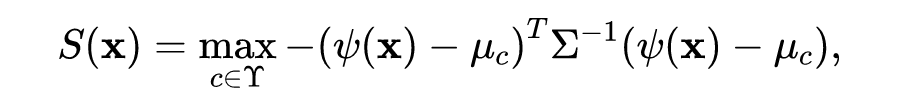
其中 为 对应的句向量, 为类别标签集合, 为类别 的均值向量, 为全局的协方差矩阵( 和 可以在分布内的验证集上估计)。在之前的工作中 [3][4],默认取 为 BERT 最后一个 Transformer 层之后、分类头之前的 CLS token 对应的向量(last-cls),忽略了其他中间层和其他 token 嵌入中蕴含的语义信息。显然,last-cls 是为分布内分类任务优化的,它对 OOD detection 不一定是最优的嵌入空间。
受到无监督句向量领域中利用中间层表示的工作 WhiteningBERT [5] 的启发,本文意在探究的问题是:给定一个微调后的预训练语言模型,如何利用所有中间层特征得到一个合适的特征空间 ,使 ID 和 OOD 样本在其中尽可能分开。

方法
2.1 层内与层间的pooling操作
给定一个输入句子 ,一个 层的 Transformer 模型产生的中间层隐状态集合为 ,其中 为第 层之后 中每个 token 对应的嵌入, 则表示嵌入层静态的词向量。考虑默认的 last-cls 没有利用 中蕴含的语义信息,我们引入两项简单的 pooling 操作:
层内平均 Intra-Layer Token Averaging:在第 层,将所有 token 对应的嵌入取平均,即 pooling 操作后的表示为:(默认的 CLS pooling 为 );
层间混合 Inter-Layer Combination:对各层 pooling 后的嵌入序列 ,取一个下标子集 ,对 中的各层对应的嵌入取平均得到最后的句向量: 。
2.2 初步探索
我们首先在 SST-2 v.s. 20 Newsgroups 这个 benchmark 上进行了初步实验(在 SST-2 情感分析任务上微调,20 Newsgroups 新闻文本作为 OOD 测试数据),以探究不同 pooling 方式对基于马氏距离的 OOD detection 算法性能的影响:
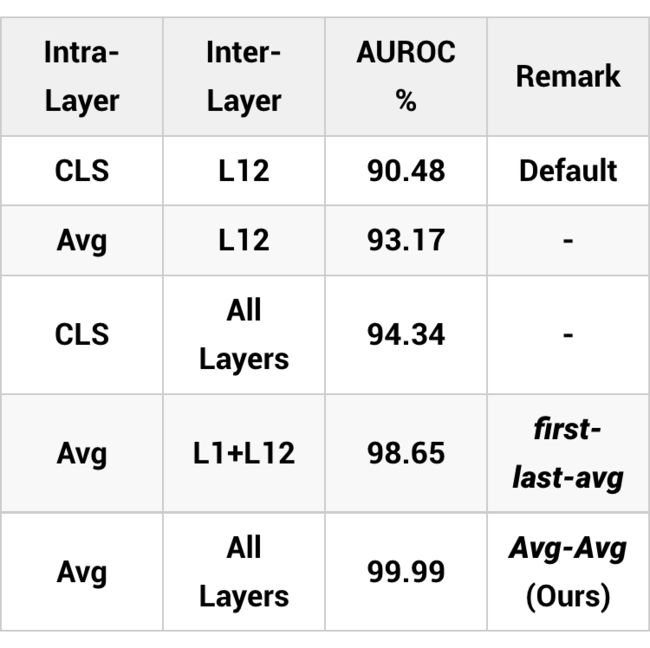
其中 L12 表示 RoBERTa-base 模型的最后一层,Avg 表示对同一层的各 token 嵌入取平均,从结果可以看出,层内平均和层间混合(使用所有层)都能带来明显的提升,而这两个 pooling 操作一起作用时,即对所有中间层后的所有 token 嵌入取平均作为最后的句向量 时 OOD 检测性能最好。我们将其命名为 Avg-Avg,并在下文进一步展示它在 OOD detection 上的优越性。
注意:训练时我们依然使用 last-cls 嵌入输入分类头,即我们的方法使用的就是普通的交叉熵损失 fine-tune 后的模型,特殊的 pooling 操作只在测试时使用以得到用于 OOD detection 的嵌入,因此我们的方法不需要修改训练过程,基本不带来额外的计算开销。

实验与分析
3.1 实验设定
数据:我们以 SST-2(情感分析)、IMDB(情感分析)、TREC(问题分类)、20 Newsgroups(新闻分类)作为分布内数据,它们中任何一对来自不同任务的数据集都可以互为 ID/OOD,另外取 WMT-16、Multi30k、RTE、SNLI 作为额外的 OOD 测试数据。
模型:RoBERTa-base 为主干网络,普通的交叉熵损失微调。
指标:AUROC(即 ID/OOD 二分类的 AUC,越高越好)与 FAR95(95% 的 ID 样本被召回时,被误认为 ID 的 OOD 样本的比例,越低越好)。
3.2 主实验结果
如下表所示,层内平均和层间混合都能在 last-cls(即 Podolskiy et al., AAAI2021 [3])的基础上带来明显的提升,而两者共同作用得到的全局句向量 Avg-Avg 取得了最佳的性能,与微调时需要额外的对比学习正则项的之前 SOTA Zhou et al. , EMNLP 2021 [4] 相比,AUROC 平均提升 1.46 个百分点,FAR95 平均减少 9.33 个百分点。

▲ 主实验结果
除了 RoBERT-base 之外,在更大的 RoBERT-large、使用更少预训练数据的 BERT-base、轻量级的 ALBERT 和 DistillRoBERTa-base 等主干上都能取得一致的涨点(括号中为相比使用 last-cls):

3.3 中间层的选择
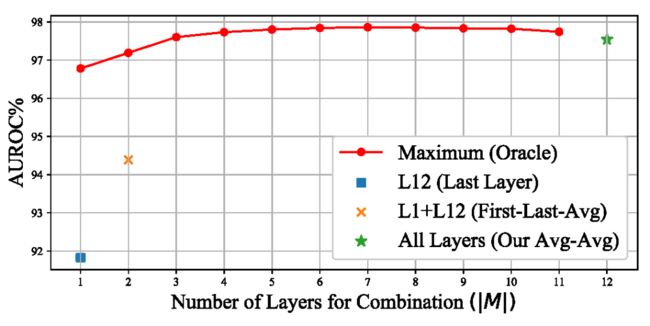
Avg-Avg 使用了所有层取平均,即 ,我们给出了一个经验性分析证实其合理性:在 SST-2 v.s. 20 Newsgroups 上,对每个可能 的大小(1 到 12),即所取的层数,在测试数据上暴力搜索最优的(对应最高 AUROC)的 (层内都使用 average pooling),将结果展示在下图中。可以看出, 达到5后对应的最优值就基本保持稳定,而峰值与取所有层的 Avg-Avg 相差很小。考虑到现实中 OOD 数据是未知的,不可能搜索最优的 ,对所有层取平均是合理的选择。
3.4 Probing分析
考虑到预训练语言模型的中间层蕴含着丰富的通用语义信息 [6],对 Avg-Avg 嵌入带来的性能提升的一个可能解释是它更好地保留了底层和中层含有的通用语义知识,得到一个更能区分 ID 和 OOD 数据的嵌入空间。为了验证这个猜想,我们在十个 probing 任务 [7] 上探究了不同 pooling 方式对通用语义信息的影响(模型为在 SST-2 上微调后的 RoBERTa-base)。
如下表所示,层内平均和层间混合都能对各 probing 任务的性能带来明显提升,而 Avg-Avg 的在各项语言属性上的 probing accuracy 都是最高的,初步解释了其在 OOD detection 任务上的性能提升。

3.5 对不同类型OOD文本的作用
NLP 领域对 OOD 文本的定义存在分歧,在主实验中,我们对标部分前人工作 [1] [4],使用的是 cross-task 设定,即 ID 和 OOD 数据来自于不同的任务;另外一个流派使用的是 novel-class 设定 [3],即 OOD 数据也属于分布内的任务,但属于未见过的新类别(类似于 open set recognition),他们主要在对话意图分类数据上进行实验,也称为 unknown intent detection。Arora et al., EMNLP 2021 [8] 针对这一分歧,将文本数据中的分布变化分为两类:
语义迁移 Semantic Shift:即同一个任务中类别信息的变化,同novel-classs 设定;
背景迁移 Background Shift:OOD 数据属于分布内的任务,类别也和 ID 数据相同,但类别无关的背景信息(如长度、语言风格)发生变化,典型是情感分类任务中,非职业的短影评 SST-2 作为分布内数据,专家所写的长影评 IMDB 作为 OOD 数据。
而 cross-task 设定中,OOD 数据来自于不同任务,两种 shift 兼有。为了进一步探究 Avg-Avg 带来的提升之来源,我们分别在 semantic shift 和 background shift 设定下做了实验,结果如下表:
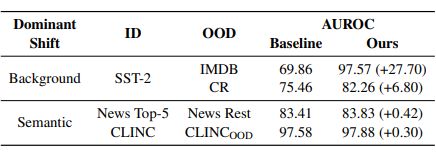
可以看出,相比于使用 last-cls 的 baseline,Avg-Avg 在 background shift 设定下提升非常显著,而在以新类别为 OOD 数据的 semantic shift(novel class)设定下提升比较微弱,这说明主实验中的性能提升主要来源于 Avg-Avg 所保留的类别无关的通用语义特征,这也与上文 probing 分析的结果相符
3.6 其他
此外,我们还讨论了 Avg-Avg 与 SimCSE 等通用的句向量模型的比较、与 score-level combination(集成各层得到的距离分数而不是特征)的比较,详见论文。

结语与展望
我们从挖掘中间层蕴含的语义信息这一角度出发,在 OOD detection 这个涉及模型安全的重要任务上探究了如何得到能将 ID 和 OOD 样本区分开的嵌入空间,提出了 Avg-Avg 这一简单而有效的嵌入方式,可以直接插入微调好的模型,对 OOD detection 无缝涨点,并详尽地分析了其提升的来源。
我们注意到有一篇同期工作(也被 Findings of EMNLP 2022 录用)Enhancing Out-of-Distribution Detection in Natural Language Understanding via Implicit Layer Ensemble [9] 使用了类似的思想,它的核心思路是在训练时即加入对中间层特征的聚合模块,鼓励不同层特征之间的 diversity,最后聚合得到全局句向量用于 OOD detection,在 novel-class 设定下(对话意图识别)数据上取得了明显的提升。
相较下,本文提出的 Avg-Avg 是一个即插即用的测试时 post-processing 方法,不需要额外参数或对训练过程的修改,在 cross-task 和 background shift 设定下带来显著提升。未来,我们会继续从表示学习的角度探究如何得到对 OOD detection 最优的句向量空间。

参考文献
[1]: Hendrycks, Dan, Xiaoyuan Liu, Eric Wallace, Adam Dziedzic, Rishabh Krishnan, and Dawn Song. "Pretrained Transformers Improve Out-of-Distribution Robustness." In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 2744-2751. 2020.
[2]: Lee, Kimin, Kibok Lee, Honglak Lee, and Jinwoo Shin. "A simple unified framework for detecting out-of-distribution samples and adversarial attacks." Advances in neural information processing systems 31 (2018).
[3]: Podolskiy, Alexander, Dmitry Lipin, Andrey Bout, Ekaterina Artemova, and Irina Piontkovskaya. "Revisiting mahalanobis distance for transformer-based out-of-domain detection." In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 15, pp. 13675-13682. 2021.
[4]: Zhou, Wenxuan, Fangyu Liu, and Muhao Chen. "Contrastive Out-of-Distribution Detection for Pretrained Transformers." In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 1100-1111. 2021.
[5]: Su, Jianlin, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. "Whitening sentence representations for better semantics and faster retrieval." arXiv preprint arXiv:2103.15316 (2021).
[6]: Jawahar, Ganesh, Benoît Sagot, and Djamé Seddah. "What does BERT learn about the structure of language?." In ACL 2019-57th Annual Meeting of the Association for Computational Linguistics. 2019.
[7]: Conneau, Alexis, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. "What you can cram into a single$ &!#* vector: Probing sentence embeddings for linguistic properties." In ACL 2018-56th Annual Meeting of the Association for Computational Linguistics, vol. 1, pp. 2126-2136. Association for Computational Linguistics, 2018.
[8]: Arora, Udit, William Huang, and He He. "Types of Out-of-Distribution Texts and How to Detect Them." In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 10687-10701. 2021.
[9]: Cho, Hyunsoo, Choonghyun Park, Jaewook Kang, Kang Min Yoo, Taeuk Kim, and Sang-goo Lee. "Enhancing Out-of-Distribution Detection in Natural Language Understanding via Implicit Layer Ensemble." arXiv preprint arXiv:2210.11034 (2022).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
