Lesson 8.3&Lesson 8.4 ID3、C4.5决策树的建模流程&CART回归树的建模流程与sklearn参数详解
Lesson 8.3 ID3、C4.5决策树的建模流程
ID3和C4.5作为的经典决策树算法,尽管无法通过sklearn来进行建模,但其基本原理仍然值得讨论与学习。接下来我们详细介绍关于ID3和C4.5这两种决策树模型的建模基本思路和原理。ID3和C4.5的基本建模流程和CART树是类似的,也是根据纯度评估指标选取最佳的数据集划分方式,只是不过ID3和C4.5是以信息熵为评估指标,而数据集的离散特征划分方式也是一次展开一列,而不是寻找切点进行切分。我们先从ID3的基本原理开始介绍,随后讨论C4.5在ID3基础上的改善措施。
import numpy as np
from ML_basic_function import *
一、ID3决策树的基本建模流程
ID3是一个只能围绕离散型变量进行分类问题建模的决策树模型,即ID3无法处理连续型特征、也无法处理回归问题,如果带入训练数据有连续型变量,则首先需要对其进行离散化处理,也就是连续变量分箱。例如如下个人消费数据,各特征都是离散型变量,能够看出,其中age和income两列就是连续型变量分箱之后的结果,例如age列就是以30、40为界进行连续变量分箱。当然,除了如下表示外,我们还可以将分箱之后的结果直接赋予一个离散的值,如1、2、3等。
更多关于连续变量的离散化的方法将在特征工程部分进行介绍。
ID3的生长过程其实和CART树基本一致,其目标都是尽可能降低数据集的不纯度,其生长的过程也就是数据集不断划分的过程。只不过ID3的数据集划分过程(规律提取过程)和CART树有所不同,CART树是在所有特征中寻找切分点、然后再从中挑选出能够最大程度降低数据集不纯度的节分方式,换而言之就是CART树是按照某切分点来展开,而ID3则是按照列来展开,即根据某列的不同取值来对数据集进行划分。例如根据上述数据集中的age列的不同取值来对原始数据集进行划分,则划分结果如下:
同样,我们可以计算在以age的不同取值为划分规则、对数据集进行划分后数据集整体不纯度下降结果,ID3中采用信息熵作为评估指标,具体计算过程如下:
首先计算父节点的信息熵
# 父节点A的信息熵
ent_A = -5/14 * np.log2(5/14) - 9/14 * np.log2(9/14)
ent_A
#0.9402859586706311
然后计算每个子节点的信息熵
# 子节点B的信息熵
ent_B1 = entropy(2/5)
ent_B2 = entropy(2/5)
ent_B3 = 0
ent_B1, ent_B2, ent_B3
#(0.9709505944546686, 0.9709505944546686, 0)
同样,子节点整体信息熵就是每个子节点的信息熵加权求和计算得出,其权重就是各子节点数据集数量占父节点总数据量的比例:
ent_B = ent_B1 * 5/14 + ent_B2 * 5/14 + ent_B3 * 4/14
ent_B
#0.6935361388961919
然后即可算出按照如此规则进行数据集划分,最终能够减少的不纯度数值:
# 不纯度下降结果
ent_A - ent_B
#0.24674981977443922
而该结果也被称为根据age列进行数据集划分后的信息增益(information gain),上述结果可写成Gain(age) = 0.247
当然,至此我们只计算了按照age列的不同取值来进行数据集划分后数据集不纯度下降结果,而按照age列进行展开只能算是树的第一步生长中的一个备选划分规则,此外我们还需要测试按照income、student或者credit_rating列展开后数据集不纯度下降情况,具体计算过程和age列展开后的计算过程类似,此处直接给出结果,Gain(income)=0.026、Gain(student)=0.151、Gain(credit_rating)=0.048。很明显,按照age列展开能够更有效的降低数据集的不纯度,因此树的第一层生长就是按照age列的不同取值对数据集进行划分。
接下来需要继续进行迭代,通过观察我们不难发现,对于数据集B1来说来说,按照student这一列来进行展开,能够让子节点的信息熵归零,而数据集B2按照如果按照credit_rating来展开,也同样可以将子节点的标签纯度提高至100%。因此该模型最终树的生长形态如下:
至此,我们就完成了ID3决策树的建模全流程,具体模型结果解读和CART树完全一样,此处不做赘述。接下来简单对比ID3和CART树之间的差异:首先,由于ID3是按照列来提取规则、每次展开一列,因此每一步生长会有几个分支,其实完全由当前列有几个分类水平决定,而CART树只能进行二叉树的生长;其次,由于ID3每次展开一列,因此建模过程中对“列的消耗”非常快,数据集中特征个数就决定了树的最大深度,相比之下CART树的备选规则就要多的多,这也使得CART树能够进行更加精细的规则提取;当然,尽管CART树和ID3存在着基本理论层面的差异,但有的时候也能通过CART树的方法来挖掘出和ID3决策树相同的规律,例如ID3中按照age列一层展开所提取出的三个分类规则,也可以在CART树中通过两层树来实现,例如第一层按照是否是<=30来进行划分、第二层围绕不满足第一层条件的数据集进一步根据是否>40来进行划分。
此外,需要注意的是,正因为ID3是按照列来进行展开,因此只能处理特征都是离散变量的数据集。另外,根据ID3的建模规则我们不难发现,ID3树在实际生长过程中会更倾向于挑选取值较多的分类变量展开(分类类数多),但如此一来便更加容易造成模型过拟合,而遗憾的是ID3并没有任何防止过拟合的措施。而这些ID3的缺陷,则正是C4.5算法的改进方向。接下来我们继续讨论关于C4.5决策树的建模规则。
当然,对于ID3来说,规则是和分类变量的取值一一绑定的
二、C4.5决策树的基本建模流程
作为ID3的改进版算法,C4.5在ID3的基础上进行了三个方面的优化,首先在衡量不纯度降低的数值计算过程中引入信息值(information value,也被称为划分信息度、分支度等)概念来修正信息熵的计算结果,以抑制ID3更倾向于寻找分类水平较多的列来展开的情况,从而间接抑制模型过拟合倾向;其二则是新增了连续变量的处理方法,也就是CART树中寻找相邻取值的中间值作为切分点的方法(C4.5针对离散变量依然是一次展开一列,连续变量采用寻找相邻取值的中间值作为切分点的方法);其三是加入了决策树的剪枝流程,使得模型泛化能力能够得到进一步提升。但需要注意的是,尽管有如此改进,但C4.5仍然只能解决分类问题,其本质仍然还是一种分类树。接下来我们详细讨论C4.5的具体改进策略。
- 信息值(information value)
C4.5中信息值(以下简称IV值)是一个用于衡量数据集在划分时分支个数的指标,如果划分时分支越多,IV值就越高。具体IV值的计算公式如下:
I n f o r m a t i o n V a l u e = − ∑ i = 1 K P ( v i ) l o g 2 P ( v i ) Information\ Value = -\sum^K_{i=1}P(v_i)log_2P(v_i) Information Value=−i=1∑KP(vi)log2P(vi)
IV值计算公式和信息熵的计算公式基本一致,只是具体计算的比例不再是各类样本所占比例,而是各划分后子节点的数据所占比例,或者说信息熵是计算标签不同取值的混乱程度,而IV值就是计算特征不同取值的混乱程度
其中K表示某次划分是总共分支个数, v i v_i vi表示划分后的某样本, P ( v i ) P(v_i) P(vi)表示该样本数量占父节点数据量的比例。对于如下三种数据集划分情况,简单计算IV值:
# 父节点按照50%-50%进行划分
- (1/2 * np.log2(1/2) + 1/2 * np.log2(1/2))
#1.0
# 父节点按照1/4-1/2-1/4进行划分
- (1/4 * np.log2(1/4) + 1/2 * np.log2(1/2)+ 1/4 * np.log2(1/4))
#1.5
# 父节点按照1/4-1/4-1/4-1/4进行划分
- (1/4 * np.log2(1/4) + 1/4 * np.log2(1/4) + 1/4 * np.log2(1/4) + 1/4 * np.log2(1/4))
#2.0
而在实际建模过程中,ID3是通过信息增益的计算结果挑选划分规则,而C4.5采用IV值对信息增益计算结果进行修正,构建新的数据集划分评估指标:增益比例(Gain Ratio,被称为获利比例或增益率),来指导具体的划分规则的挑选。GR的计算公式如下:
G a i n R a t i o = I n f o r m a t i o n G a i n I n f o r m a t i o n V a l u e Gain\ Ratio = \frac{Information\ Gain}{Information\ Value} Gain Ratio=Information ValueInformation Gain
也就是说,在C4.5的建模过程中,需要先计算GR,然后选择GR计算结果较大的列来执行这一次展开。例如对于上述例子来看,以age列展开后Information Gain结果为:
IG = ent_A - ent_B
IG
#0.24674981977443922
而IV值为:
IV = - (5/14 * np.log2(5/14) + 5/14 * np.log2(5/14)+ 4/14 * np.log2(4/14))
IV
#1.5774062828523454
因此计算得到GR值为:
GR = IG / IV
GR
#0.1564275624211752
然后据此进一步计算其他各列展开后的GR值,并选择GR较大者进行数据集划分。
- C4.5的连续变量处理方法
C4.5允许带入连续变量进行建模,并且围绕连续变量的规则提取方式和此前介绍的CART树一致。即在连续变量中寻找相邻的取值的中间点作为备选切分点,通过计算切分后的GR值来挑选最终数据集划分方式。当然,基于连续变量的备选切分方式也要和离散变量的切分方式进行横向比较,到底是一次展开一个离散列还是按照连续变量的某个切点展开,要根据最终GR的计算结果来决定。
例如,如果将上述数据集的age列换成连续变量,则我们需要计算的GR情况就变成了GR(income)、GR(student)、GR(credit_rating)、GR(age<=26.5)、GR(age<=27.5)…
当然,由于C4.5的离散变量和连续变量提取规则方式不同,离散变量是一次消耗一列来进行展开(有可能多分叉),而连续变量则一次消耗一个切分点,因此和CART树一样、同一个连续变量可以多次指导数据集进行划分。
在sklearn的树模型介绍文档中,有一段关于sklearn的决策树不支持离散变量建模的说明,其意为不支持按照类似ID3或C4.5的方式直接将离散变量按列来进行展开,而是根据sklearn中集成的CART树自身的建模规则,使得sklearn中的决策树实际上在处理特征时都是按照C4.5中连续变量的处理方式在进行处理,并非指的是带入离散变量就无法建模。
Lesson 8.4 CART回归树的建模流程与sklearn参数详解
接下来,我们继续讨论关于CART回归树的相关内容。 根据此前介绍,CART树能同时解决分类问题和回归问题,但由于两类问题的性质还是存在一定的差异,因此CART树在处理不同类型问题时相应建模流程也略有不同,当然对应的sklearn中的评估器也是不同的。并且值得一提的是,尽管回归树单独来看是解决回归类问题的模型,但实际上回归树其实是构建梯度提升树(GBDT,一种集成算法)的基础分类器,并且无论是解决回归类问题还是分类问题,CART回归树都是唯一的基础分类器,因此哪怕单独利用回归树解决问题的场景并不多见,但对于CART回归树的相关方法仍然需要重点掌握,从而为后续集成算法的学习奠定基础。
本节我们将在CART分类树的基础之上详细讨论CART树在处理回归问题时的基本流程,并详细介绍关于CART回归树在sklearn中评估器的的相关参数与使用方法。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
# Scikit-Learn相关模块
# 评估器类
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor
# 实用函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据准备
from sklearn.datasets import load_iris
一、CART回归树的基本建模流程
同样,我们先从一个极简的例子来了解CART回归树的基本建模流程,然后再介绍通过数学语言描述得更加严谨的建模流程。
- 数据准备
首先我们创建一个简单的回归数据集如下,该数据集只包含一个特征和一个连续型标签:
data = np.array([[1, 1], [2, 3], [3, 3], [4, 6], [5, 6]])
plt.scatter(data[:, 0], data[:, 1])

其中横坐标代表数据集特征,纵坐标代表数据集标签。
- 生成备选规则
CART回归树和分类树流程类似,从具体操作步骤来看,首先都是寻找切分点对数据集进行切分,或者说需要确定备选划分规则。
回归树中寻找切分点的方式和分类树的方式相同,都是逐特征寻找不同取值的中间点作为切分点。对于上述数据集来说,由于只有一个特征,并且总共有5个不同的取值,因此切分点有4个。而根据此前介绍,有几个切分点就有几种数据集划分方式、即有同等数量的备选划分规则、或有同等数量的树的生长方式。初始数据集的4个不同的划分方式,可以通过如下方式进行呈现:
y_range = np.arange(1, 6, 0.1)
plt.subplot(221)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
plt.subplot(222)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 2.5), y_range, 'r--')
plt.subplot(223)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 3.5), y_range, 'r--')
plt.subplot(224)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 4.5), y_range, 'r--')

- 挑选规则
在确定了备选划分规则之后,接下来需要根据某种评估标准来寻找最佳划分方式。回归树的该步骤和分类树差异较大,分类树中我们是采用基尼系数或者信息熵来衡量划分后数据集标签不纯度下降情况来挑选最佳划分方式,而在回归树中,则是根据划分之后子数据集MSE下降情况来进行最佳划分方式的挑选。在该过程中,子数据集整体的MSE计算方法也和CART分类树类似,都是先计算每个子集单独的MSE,然后再通过加权求和的方法来进行计算两个子集整体的MSE。
此处MSE的计算虽然不复杂,但我们知道,但凡需要计算MSE,就必须给出一个预测值,然后我们才能根据预测值和真实值计算MSE。而CART回归树在进行子数据集的划分之后,会针对每个子数据集给出一个预测值(注意是针对一个子数据集中所有数据给出一个预测值,而不是针对每一个数给出一个预测值),而该预测值会依照让对应子数据集MSE最小的目标进行计算得出。
让MSE取值最小这一目标其实等价于让SSE取值最小,而用一个数对一组数进行预测并且要求SSE最小,其实就相当于K-Means快速聚类过程中所要求的寻找组内误差平方和最小的点作为中心点,我们曾在Lesson 7中进行过相关数学推导,此时选取这组数的质心能够让组内误差平方和计算结果最小。而此时情况也是类似,只不过我们针对一组一维的数据去寻找一个能够使得组内误差平方和的最小的点,这个点仍然是这组数据的质心,而一维数据的质心,其实就是这组数据的均值。那么也就是说,在围绕让每一个子数据集MSE取值最小这一目标下,每个子数据集的最佳预测值就是这个子数据集真实标签的均值。
具体计算过程如下,例如对上述第一种划分数据集的情况来说,每个子数据集的预测值和MSE计算结果如下:
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')

对应划分情况也可以通过如下形式进行表示:
此时可计算子数据集B1和B2的MSE,首先是两个数据集的预测值,也就是两个数据集的均值:
data[0, 1]
#1
# B1数据集的预测值
y_1 = np.mean(data[0, 0])
y_1
#1.0
data[1: , 1]
#array([3, 3, 6, 6])
# B2数据集的预测值
y_2 = np.mean(data[1: , 1])
y_2
#4.5
# 模型预测结果
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
plt.plot(np.arange(0, 1.5, 0.1), np.full_like(np.arange(0, 1.5, 0.1), y_1), 'r-')
plt.plot(np.arange(1.7, 5.1, 0.1), np.full_like(np.arange(1.7, 5.1, 0.1), y_2), 'r-')
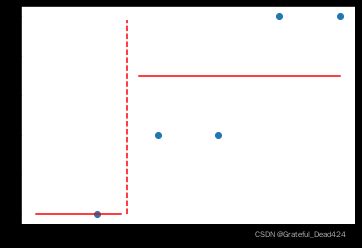
然后计算两个子集的MSE:
# B1的MSE
mse_b1 = 0
# B2的MSE
mse_b2 = np.power(data[1: , 1] - 4.5, 2).sum() / 4
mse_b2
#2.25
然后和CART分类树一样,以各子集所占全集的样本比例为权重,通过加权求和的方式计算两个子集整体的MSE:
mse_b = 1/5 * mse_b1 + 4/5 * mse_b2
mse_b
#1.8
而父节点的MSE为:
data[: , 1].mean()
#3.8
mse_a = np.power(data[: , 1] - data[: , 1].mean(), 2).sum() / data[: , 1].size
mse_a
#3.7599999999999993
因此,本次划分所降低的MSE为:
mse_a - mse_b
#1.9599999999999993
即为该种划分方式的最终评分。当然,我们要以相似的流程计算其他几种划分方式的评分,然后从中挑选能够最大程度降低MSE的划分方式,基本流程如下:
impurity_decrease = []
for i in range(4):
# 寻找切分点
splitting_point = data[i: i+2 , 0].mean()
# 进行数据集切分
data_b1 = data[data[:, 0] <= splitting_point]
data_b2 = data[data[:, 0] > splitting_point]
# 分别计算两个子数据集的MSE
mse_b1 = np.power(data_b1[: , 1] - data_b1[: , 1].mean(), 2).sum() / data_b1[: , 1].size
mse_b2 = np.power(data_b2[: , 1] - data_b2[: , 1].mean(), 2).sum() / data_b2[: , 1].size
# 计算两个子数据集整体的MSE
mse_b = data_b1[: , 1].size/data[: , 1].size * mse_b1 + data_b2[: , 1].size/data[: , 1].size * mse_b2
#mse_b = mse_b1 + mse_b2
# 计算当前划分情况下MSE下降结果
impurity_decrease.append(mse_a - mse_b)
impurity_decrease
#[1.9599999999999993, 2.1599999999999993, 3.226666666666666, 1.209999999999999]
plt.subplot(221)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
plt.subplot(222)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 2.5), y_range, 'r--')
plt.subplot(223)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 3.5), y_range, 'r--')
plt.subplot(224)
plt.scatter(data[:, 0], data[:, 1])
plt.plot(np.full_like(y_range, 4.5), y_range, 'r--')
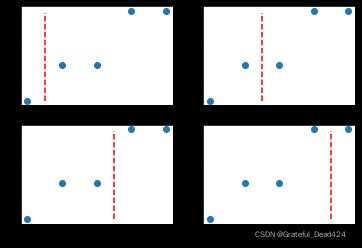
根据最终结果能够看出,第三种划分情况能够最大程度降低MSE,即此时树模型的第一次生长情况如下:
- 进行多轮迭代
当然,和CART分类树一样,接下来,我们就能够进一步围绕B1和B2进行进一步划分。此时B2的MSE已经为0,因此无需再进行划分,而B1的MSE为0.88,还可以进一步进行划分。当然B1的划分过程也和A数据集的划分过程一致,寻找能够令子集MSE下降最多的方式进行切分。不过由于B1数据集本身较为简单,通过观察不难发现,我们可以以x<= 1.5作为划分条件对其进行切分,进一步切分出来的子集的MSE都将取值为0。
此外,我们也可以观察当回归树生长了两层之后,相关规则对原始数据集的划分情况:
# 数据分布
plt.scatter(data[:, 0], data[:, 1])
# 两次划分
plt.plot(np.full_like(y_range, 3.5), y_range, 'r--')
plt.plot(np.full_like(y_range, 1.5), y_range, 'r--')
# 预测结果
plt.plot(np.arange(1, 1.5, 0.1), np.full_like(np.arange(1, 1.5, 0.1), 1), 'r-')
plt.plot(np.arange(1.5, 3.5, 0.1), np.full_like(np.arange(1.5, 3.5, 0.1), 3), 'r-')
plt.plot(np.arange(3.5, 5, 0.1), np.full_like(np.arange(3.5, 5, 0.1), 6), 'r-')

不难发现,回归树的对标签的预测,实际上是一种“分区定值”的预测,建模过程的实际表现是对样本进行划分、然后每个区间给定一个预测值,并且树的深度越深、对样本空间的划分次数就越多、样本空间就会被分割成更多的子空间。在sklearn的说明文档中也有相关例子:

- 回归树的预测过程
而一旦当模型已经构建完成后,回归树的预测过程其实和分类树非常类似,新数据只要根据划分规则分配到所属样本空间,则该空间模型的预测结果就是该数据的预测结果。
至此,我们就在一个极简的数据集上完成了CART回归树的构建。不难发现,回归树和分类树的构建过程大致相同、迭代过程也基本一致,我们可以将其视作同一种建模思想的两种不同实现形式。
二、CART回归树的Scikit-Learn实现方法
1.CART回归树的sklearn快速实现
接下来,我们尝试在sklearn中调用回归树评估器围绕上述数据集进行建模,并对上述过程进行简单验证。回归树也是在tree模块下,我们可以通过如下方式进行导入:
from sklearn.tree import DecisionTreeRegressor
然后进行模型训练:
clf = DecisionTreeRegressor().fit(data[:, 0].reshape(-1, 1), data[:, 1])
# 同样可以借助tree.plot_tree进行结果的可视化呈现
plt.figure(figsize=(6, 2), dpi=150)
tree.plot_tree(clf)

发现和我们手动实现过程一致。
2.CART回归树评估器的参数解释
接下来,详细讨论关于CART回归树评估器中的相关参数。尽管CART回归树和分类树是由不同评估器实现相关过程,但由于两种模型基本理论一致,因此两种不同评估器的参数也大都一致。
DecisionTreeRegressor?
#Init signature:
#DecisionTreeRegressor(
# *,
# criterion='mse',
# splitter='best',
# max_depth=None,
# min_samples_split=2,
# min_samples_leaf=1,
# min_weight_fraction_leaf=0.0,
# max_features=None,
# random_state=None,
# max_leaf_nodes=None,
# min_impurity_decrease=0.0,
# min_impurity_split=None,
# presort='deprecated',
# ccp_alpha=0.0,
)
不难发现,其中大多数参数我们在Lesson 8.2中都进行了详细的讲解,此处重点讲解criterion参数取值。criterion是备选划分规则的选取指标,对于CART分类树来说默认基尼系数、可选信息熵,而对于CART回归树来说默认mse,同时可选mae和friedman_mse,同时在新版sklearn中,还加入了poisson作为可选参数取值。接下来我们就这几个参数不同取值进行介绍:
- criterion='mse’情况
当criterion取值为mse时当然是计算误差平方和再除以样本总数,其基本计算流程与上述手动实现过程层类似。但有一点可能会对阅读源码的同学造成困扰,那就是在源码中子节点整体的MSE计算公式描述如下:
尽管上述公式看起来像是子节点的整体MSE就等于左右两个节点的方差只和,但实际上是经过加权之后的方差只和。我们可以通过在手动实现过程中灵活调整min_impurity_decrease参数来进行验证。
需要注意的是,CART回归树的子节点整体MSE的计算方式是加权求和还是简单求和,不同的材料中有不同的描述,例如由Aurélien Géron等人所著《机器学习实战,基于Scikit-Learn、Keras和TensorFlow》一书中表示是通过加权求和方式算得(sklearn中也是这样),而在《统计学习方法》一书中则表示是根据子节点的MSE直接求和得到。
- criterion='mae’情况
和MSE不同,MAE实际上计算的是预测值和真实值的差值的绝对值再除以样本总数,即可以通过如下公式计算得出: M A E = 1 m ∑ i = 1 m ∣ ( y i − y ^ i ) ∣ MAE = \frac{1}{m}\sum^m_{i=1}|(y_i-\hat y _i)| MAE=m1i=1∑m∣(yi−y^i)∣
也就是说,MSE是基于预测值和真实值之间的欧式距离进行的计算,而MAE则是基于二者的街道距离进行的计算,很多时候,MSE也被称为L2损失,而MAE则被称为L1损失。
需要注意的是,当criterion取值为mae时,为了让每一次划分时子集内的MAE值最小,此时每个子集的模型预测值就不再是均值,而是中位数。此时中位数的选取其实和Lesson 7中介绍的K-Means快速聚类的质心选取过程类似,当距离衡量方法改为街道距离时,能够让组内误差平方和最小的质心其实就是这一组数的中位数。
再次强调,CART回归树的criterion不仅是划分方式挑选时的评估标准,同时也是划分子数据集后选取预测值的决定因素。也就是说,对于回归树来说,criterion的取值其实决定了两个方面,其一是决定了损失值的计算方式、其二是决定了每一个数据集的预测值的计算方式——数据集的预测值要求criterion取值最小,如果criterion=mse,则数据集的预测值要求在当前数据情况下mse取值最小,此时应该以数据集的标签的均值作为预测值;而如果criterion=mse,则数据集的预测值要求在当前数据情况下mae取值最小,此时应该以数据集标签的中位数作为预测值。
并且一般来说,如果希望模型对极端值(非常大或者非常小的值,也被称为离群值)的忍耐程度比较高,整体建模过程不受极端值影响,可以考虑使用mae参数(就类似于中位数会更少的受到极端值的影响),此时模型一般不会为极端值单独设置规则。而如果希望模型具备较好的识别极端值的能力,则可以考虑使用mse参数,此时模型会更大程度受到极端值影响(就类似于均值更容易受到极端值影响),更大概率会围绕极端值单独设置规则,从而帮助建模者对极端值进行识别。
为什么需要用模型来识别离群点?主要是因为对于高维空间中的样本点,我们很难通过简单的大小比较将离群点挑选出来。
- criterion='friedman_mse’情况
friedman_mse是一种基于mse的改进型指标,是由GBDT(梯度提升树,一种集成算法)的提出者friedman所设计的一种残差计算方法,是sklearn中树梯度提树默认的criterion取值,对于单独的树决策树模型一般不推荐使用,关于friedman_mse的计算方法我们将在集成算法中进行详细介绍。