pytorch 深度学习最简单的分类预测
用pytorch写一个最基本的分类模型,这里分类的数据是二维的[x1,x2],假设![]() 为一类,
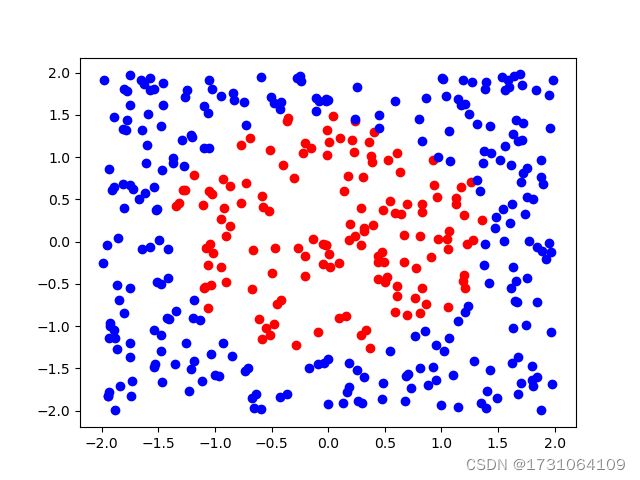
为一类,![]() 为第二类。其实就是用一个圆将平面上的数据分为两类,圆内一类,圆外一类。预测时候给任意一个数据,判断是哪一类。
为第二类。其实就是用一个圆将平面上的数据分为两类,圆内一类,圆外一类。预测时候给任意一个数据,判断是哪一类。
第一步,搭建网络
输入层由于每个数据的维度是2,所以输入层为2,设置一个隐藏层,隐藏层单元数为10个,输出层为2,因为是2分类。那么最后得到[0,1]是一类,[1,0]又是另一类。在前向传播的时候,经过隐藏层后需要用激活函数,但是最后一层不需要激活。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = nn.Linear(2, 10)
self.pre = nn.Linear(10, 2)
def forward(self, x):
x = self.hidden(x)
x = torch.sigmoid(x)
x = self.pre(x)
return x第二步,开始产生训练数据
训练数据其实就是平面上的点,也就是每个数据都是两个坐标。随机产生x坐标点和y坐标点,然后将x和y在第一个通道进行拼接。这里得到的数据还没有标签,因此需要获得每个数据的标签。最后由于标签和数据都是numpy类型,因此需要转成tensor类型。
获得训练数据的标签一定要注意,第一个类不是[0,1],第二个类也是不[1,0],这里在存标签的时候第一个类用的是0表示,第二个类用的是1表示。这样做的主要原因是因为等会训练用交叉熵损失函数的时候要求输入的类就是0,1这样表示,而不是01,10。
x = np.random.uniform(-2.,2.,(800,1))
y = np.random.uniform(-2.,2.,(800,1))
data = np.concatenate((x, y), axis=1)
a1 = []
a2 = []
label = []
for num in data:
if(num[0]**2+num[1]**2<2):
a1.append(num)
label.append(0)
else:
a2.append(num)
label.append(1)
label = np.array(label)
label1 = np.copy(label)
data = torch.from_numpy(data)
label = torch.from_numpy(label)
label = label.long()第三步,开始进行训练
1、确定网络、优化器和损失函数三个重要参数,这里损失函数用交叉熵损失
2、设置训练周期,这里设置epoch为400
3、将数据送入网络开始训练,注意这里没有用小批训练
4、将网络的预测值和真是标签送入损失函数求损失
5、优化器参数情况,进行反向传播
6、优化器迭代
7、计算训练集准确度,这里一定要注意,每个数据送入网络后,网络的输出是二维的,而标签是一维的,因此需要将网络的输出值进行softmax和onehot编码,最终才能变成一维的类别标签。而argmax()其实就是做了这两个操作。这样只需要用预测值-标签值,结果为0就表示预测正确,不为0表示预测错误。另外还要注意的是,在将预测值和标签值送入损失函数的时候,不需要将预测值进行softmax和onehot编码,因为nn.CrossEntropyLoss()函数会自动进行这两个操作,所以你可以看到,再送入交叉熵损失函数的时候,预测值和标签值的维度是不一样的。
8、保存模型,根据训练集样本预测准确度保存模型
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
loss_func = nn.CrossEntropyLoss()
best_acc = 0
for epoch in range(1,401):
out = net(data)
optimizer.zero_grad()
loss = loss_func(out, label)
loss.backward()
optimizer.step()
out = out.argmax(dim=1)
out = out.numpy()
res = label1-out
res = np.sum(res==0)
acc = res/len(label) # 计算训练集准确率
if(acc>best_acc):
torch.save(net, 'Classify.pkl') # 保存整个模型
# torch.save(net.state_dict(), 'Classify.pkl') # 保存模型参数第四步,进行模型测试
在测试集上测试训练好的模型
1、加载模型参数
2、生成测试数据
3、获得测试结果,这里的测试结果没有进行softmax和onehot,为了能够判断是否预测正确,因此需要进行转换。切记,真实的类别只有0和1这两类。
4、可视化测试结果