深度学习入门(六十一)循环神经网络——长短期记忆网络LSTM
深度学习入门(六十一)循环神经网络——长短期记忆网络LSTM
- 前言
- 循环神经网络——长短期记忆网络LSTM
-
- 课件
-
- 长短期记忆网络
- 门
- 候选记忆单元
- 记忆单元
- 隐状态
- 总结
- 教材
-
- 1 门控记忆元
-
- 1.1 输入门、忘记门和输出门
- 1.2 候选记忆元
- 1.3 记忆元
- 1.4 隐状态
- 2 从零开始实现
-
- 2.1 初始化模型参数
- 2.2 定义模型
- 2.3 训练和预测
- 3 简洁实现
- 4 小结
- 参考文献
前言
核心内容来自博客链接1博客连接2希望大家多多支持作者
本文记录用,防止遗忘
循环神经网络——长短期记忆网络LSTM
课件
长短期记忆网络
忘记门:将值朝0减少
输入门:决定不是忽略掉输入数据
输出门:决定是不是使用隐状态
门

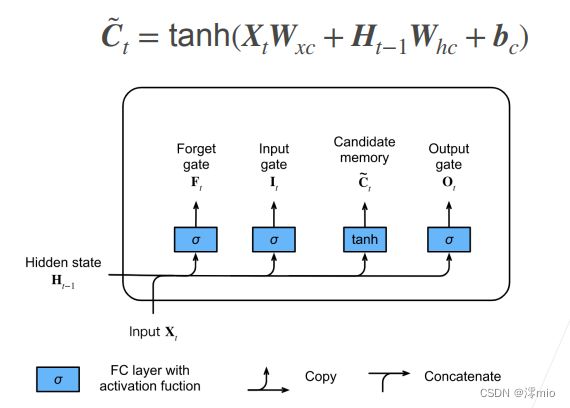
候选记忆单元
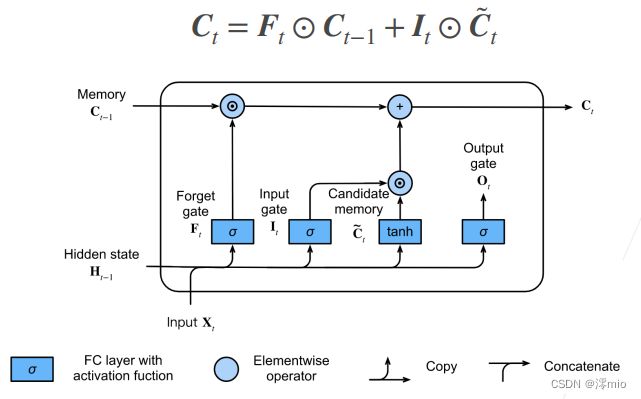
记忆单元
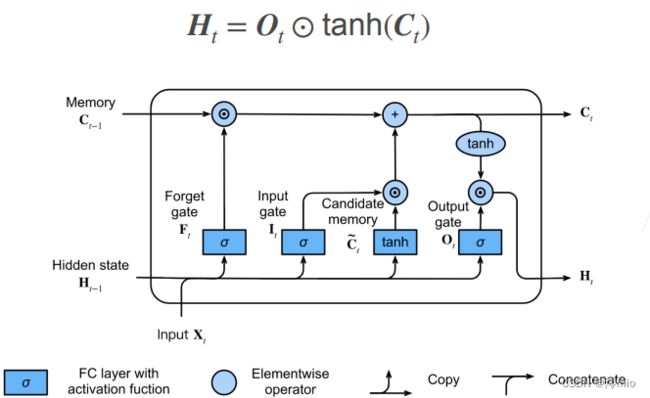
隐状态
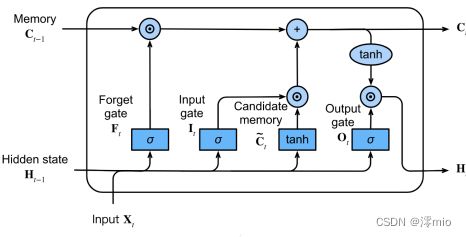
总结
I t = σ ( X t W x i + H t − 1 W h i + b i ) , F t = σ ( X t W x f + H t − 1 W h f + b f ) , O t = σ ( X t W x o + H t − 1 W h o + b o ) , \begin{aligned}\begin{aligned} \mathbf{I}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i),\\ \mathbf{F}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f),\\ \mathbf{O}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o),\\ \end{aligned}\end{aligned} ItFtOt=σ(XtWxi+Ht−1Whi+bi),=σ(XtWxf+Ht−1Whf+bf),=σ(XtWxo+Ht−1Who+bo),
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) , C t = F t ⊙ C t − 1 + I t ⊙ C ~ t . H t = O t ⊙ tanh ( C t ) . \tilde{\mathbf{C}}_t = \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c),\\ \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t.\\ \mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t). C~t=tanh(XtWxc+Ht−1Whc+bc),Ct=Ft⊙Ct−1+It⊙C~t.Ht=Ot⊙tanh(Ct).
教材
长期以来,隐变量模型存在着长期信息保存和短期输入缺失的问题。 解决这一问题的最早方法之一是长短期存储器(long short-term memory,LSTM)。 它有许多与门控循环单元一样的属性。 有趣的是,长短期记忆网络的设计比门控循环单元稍微复杂一些, 却比门控循环单元早诞生了近20年。
1 门控记忆元
可以说,长短期记忆网络的设计灵感来自于计算机的逻辑门。 长短期记忆网络引入了记忆元(memory cell),或简称为单元(cell)。 有些文献认为记忆元是隐状态的一种特殊类型, 它们与隐状态具有相同的形状,其设计目的是用于记录附加的信息。 为了控制记忆元,我们需要许多门。 其中一个门用来从单元中输出条目,我们将其称为输出门(output gate)。 另外一个门用来决定何时将数据读入单元,我们将其称为输入门(input gate)。 我们还需要一种机制来重置单元的内容,由遗忘门(forget gate)来管理, 这种设计的动机与门控循环单元相同, 能够通过专用机制决定什么时候记忆或忽略隐状态中的输入。 让我们看看这在实践中是如何运作的。
1.1 输入门、忘记门和输出门
就如在门控循环单元中一样, 当前时间步的输入和前一个时间步的隐状态作为数据送入长短期记忆网络的门中, 如图所示。 它们由三个具有sigmoid激活函数的全连接层处理, 以计算输入门、遗忘门和输出门的值。 因此,这三个门的值都在 ( 0 , 1 ) (0, 1) (0,1)的范围内。
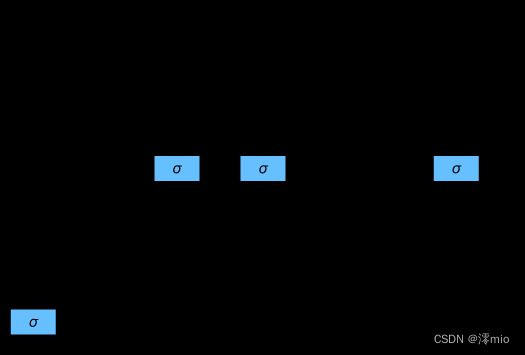
我们来细化一下长短期记忆网络的数学表达。 假设有 h h h个隐藏单元,批量大小为 n n n,输入数为 d d d。 因此,输入为 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d, 前一时间步的隐状态为 H t − 1 ∈ R n × h \mathbf{H}_{t-1} \in \mathbb{R}^{n \times h} Ht−1∈Rn×h。 相应地,时间步 t t t的门被定义如下: 输入门是 I t ∈ R n × h \mathbf{I}_t \in \mathbb{R}^{n \times h} It∈Rn×h, 遗忘门是 F t ∈ R n × h \mathbf{F}_t \in \mathbb{R}^{n \times h} Ft∈Rn×h, 输出门是 O t ∈ R n × h \mathbf{O}_t \in \mathbb{R}^{n \times h} Ot∈Rn×h。 它们的计算方法如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) , F t = σ ( X t W x f + H t − 1 W h f + b f ) , O t = σ ( X t W x o + H t − 1 W h o + b o ) , \begin{split}\begin{aligned} \mathbf{I}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i),\\ \mathbf{F}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f),\\ \mathbf{O}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o), \end{aligned}\end{split} ItFtOt=σ(XtWxi+Ht−1Whi+bi),=σ(XtWxf+Ht−1Whf+bf),=σ(XtWxo+Ht−1Who+bo),
其中 W x i , W x f , W x o ∈ R d × h \mathbf{W}_{xi}, \mathbf{W}_{xf}, \mathbf{W}_{xo} \in \mathbb{R}^{d \times h} Wxi,Wxf,Wxo∈Rd×h和 W h i , W h f , W h o ∈ R h × h \mathbf{W}_{hi}, \mathbf{W}_{hf}, \mathbf{W}_{ho} \in \mathbb{R}^{h \times h} Whi,Whf,Who∈Rh×h是权重参数, b i , b f , b o ∈ R 1 × h \mathbf{b}_i, \mathbf{b}_f, \mathbf{b}_o \in \mathbb{R}^{1 \times h} bi,bf,bo∈R1×h是偏置参数。
1.2 候选记忆元
由于还没有指定各种门的操作,所以先介绍候选记忆元(candidate memory cell) C ~ t ∈ R n × h \tilde{\mathbf{C}}_t \in \mathbb{R}^{n \times h} C~t∈Rn×h。 它的计算与上面描述的三个门的计算类似, 但是使用tanh函数作为激活函数,函数的值范围为 ( − 1 , 1 ) (-1, 1) (−1,1)。 下面导出在时间步处的方程:
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) , \tilde{\mathbf{C}}_t = \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c), C~t=tanh(XtWxc+Ht−1Whc+bc),
其中 W x c ∈ R d × h \mathbf{W}_{xc} \in \mathbb{R}^{d \times h} Wxc∈Rd×h和 W h c ∈ R h × h \mathbf{W}_{hc} \in \mathbb{R}^{h \times h} Whc∈Rh×h是权重参数, b c ∈ R 1 × h \mathbf{b}_c \in \mathbb{R}^{1 \times h} bc∈R1×h是偏置参数。
候选记忆元的如图所示。

1.3 记忆元
在门控循环单元中,有一种机制来控制输入和遗忘(或跳过)。 类似地,在长短期记忆网络中,也有两个门用于这样的目的: 输入门 I t \mathbf{I}_t It控制采用多少来自 C ~ t \tilde{\mathbf{C}}_t C~t的新数据, 而遗忘门 F t \mathbf{F}_t Ft控制保留多少过去的 记忆元 C t − 1 ∈ R n × h \mathbf{C}_{t-1} \in \mathbb{R}^{n \times h} Ct−1∈Rn×h的内容。 使用按元素乘法,得出:
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t . \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t. Ct=Ft⊙Ct−1+It⊙C~t.
如果遗忘门始终为1且输入门始终为0, 则过去的记忆元 C t − 1 \mathbf{C}_{t-1} Ct−1将随时间被保存并传递到当前时间步。 引入这种设计是为了缓解梯度消失问题, 并更好地捕获序列中的长距离依赖关系。
这样我们就得到了计算记忆元的流程图,如图
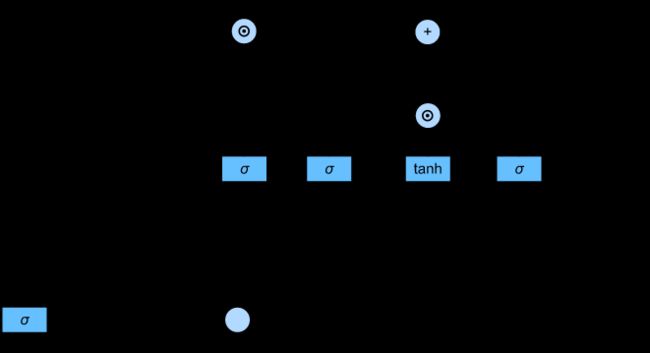
1.4 隐状态
最后,我们需要定义如何计算隐状态 H t ∈ R n × h \mathbf{H}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h , 这就是输出门发挥作用的地方。 在长短期记忆网络中,它仅仅是记忆元的tanh的门控版本。 这就确保了 H t \mathbf{H}_t Ht的值始终在区间 ( − 1 , 1 ) (-1, 1) (−1,1)内:
H t = O t ⊙ tanh ( C t ) . \mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t). Ht=Ot⊙tanh(Ct).
只要输出门接近1,我们就能够有效地将所有记忆信息传递给预测部分, 而对于输出门接近0,我们只保留记忆元内的所有信息,而不需要更新隐状态。
下图提供了数据流的图形化演示

2 从零开始实现
现在,我们从零开始实现长短期记忆网络。我们首先加载时光机器数据集。
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
2.1 初始化模型参数
接下来,我们需要定义和初始化模型参数。 如前所述,超参数num_hiddens定义隐藏单元的数量。 我们按照标准差0.01的高斯分布初始化权重,并将偏置项设为0。
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
2.2 定义模型
在初始化函数中, 长短期记忆网络的隐状态需要返回一个额外的记忆元, 单元的值为0,形状为(批量大小,隐藏单元数)。 因此,我们得到以下的状态初始化。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
实际模型的定义与我们前面讨论的一样: 提供三个门和一个额外的记忆元。 请注意,只有隐状态才会传递到输出层, 而记忆元 C t \mathbf{C}_t Ct不直接参与输出计算。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
2.3 训练和预测
让我们通过实例化RNN实现一节中引入的RNNModelScratch类来训练一个长短期记忆网络, 就如我们在GRU一节中所做的一样。
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
输出
perplexity 1.4, 22462.5 tokens/sec on cuda:0
time traveller for the brow henint it aneles a overrecured aback
travellerifilby freenotin s dof nous be and the filing and
3 简洁实现
使用高级API,我们可以直接实例化LSTM模型。 高级API封装了前文介绍的所有配置细节。 这段代码的运行速度要快得多, 因为它使用的是编译好的运算符而不是Python来处理之前阐述的许多细节。
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
输出:
perplexity 1.1, 330289.2 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
长短期记忆网络是典型的具有重要状态控制的隐变量自回归模型。 多年来已经提出了其许多变体,例如,多层、残差连接、不同类型的正则化。 然而,由于序列的长距离依赖性,训练长短期记忆网络 和其他序列模型(例如门控循环单元)的成本是相当高的。 在后面的内容中,我们将讲述更高级的替代模型,如Transformer。
4 小结
-
长短期记忆网络有三种类型的门:输入门、遗忘门和输出门。
-
长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
-
长短期记忆网络可以缓解梯度消失和梯度爆炸。
参考文献
[1] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.