Hive学习:数据仓库的建立
【实验名称】:数据仓库的建立
【实验目的】:熟悉Linux系统、MySQL、Hadoop、HBase、Hive、Sqoop、R、Eclipse等系统和软件的安装和使用;
了解大数据处理的基本流程;
熟悉数据预处理方法;
熟悉在不同类型数据库之间进行数据相互导入导出。
【实验原理】:数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。Hive是一个构建于Hadoop顶层的数据仓库工具,支持大规模数据存储、分析,具有良好的可扩展性,某种程度上可以看作是用户编程接口,本身不存储和处理数据,依赖分布式文件系统HDFS存储数据,依赖分布式并行计算模型MapReduce处理数据,定义了简单的类似SQL 的查询语言——HiveQL,用户可以通过编写的HiveQL语句运行MapReduce任务,可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上,是一个可以提供有效、合理、直观组织和使用数据的分析工具。
【实验环境】
OS:Ubuntu16.04
Hadoop
Hive
【实验步骤】
题目一:本地数据集上传到数据仓库Hive
数据源:
wget http://10.90.3.2/HUP/BI/2/small_user.csv
wget http://10.90.3.2/HUP/BI/2/pre_deal.sh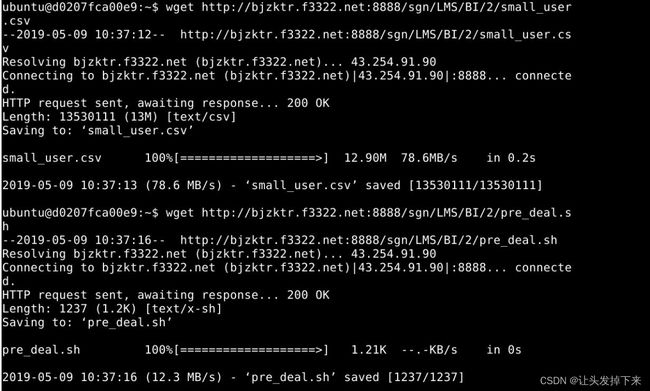
在linux界面下执行如下命令:
ls
(查看当前文件夹下所有文件)
head -5 small_user.csv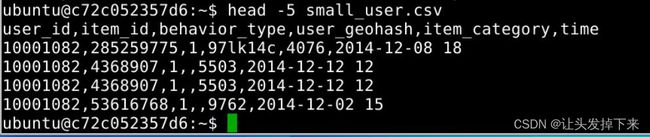
(查看small_user.csv前5行数据)
可以看出,每行记录都包括5个字段,数据集中的字段及其含义如下:
user_id(用户id)
item_id(商品id)
behaviour_type(包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4)
user_geohash(用户地理位置哈希值,有些记录中没有这个字段值,所以后面我们会用脚本做数据预处理时把这个字段全部删除)
item_category(商品分类)
time(该记录产生时间)
数据集的预处理-删除文件第一行记录,即字段名称
small_user中的第一行是字段名称,我们在文件中的数据导入到数据仓库Hive中时,不需要第一行字段名称,因此,这里在做数据预处理时,删除第一行。
删除行信息:
sed -i '1d' small_user.csv//1d表示删除第一行,同理,3d表示删除第三行,nd表示删除第n行。
运行完毕后查看是否删除成功:
head -5 small_user.csv 
接下来的操作中,我们都是用small_user.csv这个小数据集进行操作,这样可以节省时间。
数据集的预处理-对字段进行预处理
下面对数据集进行一些预处理,包括为每行记录增加一个id字段(让记录具有唯一性)、增加一个省份字段(用来后续进行可视化分析),并且丢弃user_geohash字段(后面分析不需要这个字段)。
pre_deal.sh文件解析:
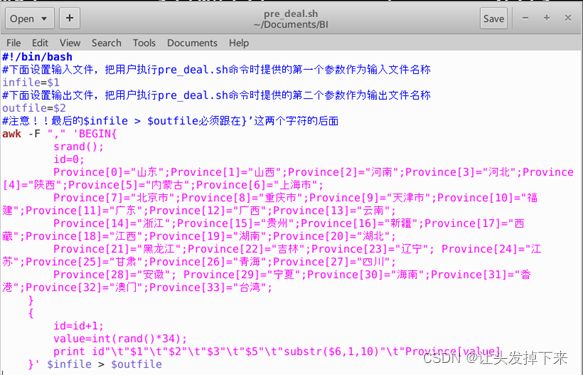
为使用awk可以逐行读取输入文件,并对逐行进行相应操作。其中,-F参数用于指出每行记录的不同字段之间用什么字符进行分割,这里是用逗号进行分割。处理逻辑代码需要用两个英文单引号引起来。 $infile是输入文件的名称,我们这里会输入small_user.csv,$outfile表示处理结束后输出的文件名称,我们后面会使用user_table.txt作为输出文件名称。
在上面的pre_deal.sh代码的处理逻辑部分,srand()用于生成随机数的种子,id是我们为数据集新增的一个字段,它是一个自增类型,每条记录增加1,这样可以保证每条记录具有唯一性。我们会数据集新增一个省份字段,用来进行后面的数据可视化分析,为了给每条记录增加一个省份字段的值,这里,我们首先用Province[]数组用来保存全国各个省份信息,然后,在遍历数据集small_user.csv的时候,每当遍历到其中一条记录,使用value=int(rand()*34)语句随机生成一个0-33的整数,作为Province省份值,然后从Province[]数组当中获取省份名称,增加到该条记录中。
substr($6,1,10)这个语句是为了截取时间字段time的年月日,方便后续存储为date格式。awk每次遍历到一条记录时,每条记录包含了6个字段,其中,第6个字段是时间字段,substr($6,1,10)语句就表示获取第6个字段的值,截取前10个字符,第6个字段是类似"2014-12-08 18"这样的字符串(也就是表示2014年12月8日18时),substr($6,1,10)截取后,就丢弃了小时,只保留了年月日。
另外,在print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value]这行语句中,我们丢弃了每行记录的第4个字段,所以,没有出现$4。我们生成后的文件是“\t”进行分割,这样,后续我们去查看数据的时候,效果让人看上去更舒服,每个字段在排版的时候会对齐显示,如果用逗号分隔,显示效果就比较乱。
运行pre_deal.sh
chmod +x ./pre_deal.sh
./pre_deal.sh ./small_user.csv ./user_table.txt
导入数据库
下面要把user_table.txt中的数据最终导入到数据仓库Hive中。为了完成这个操作,我们会首先把user_table.txt上传到分布式文件系统HDFS中,然后,在Hive中创建一个外部表,完成数据的导入。
5.1把user_table.txt上传到HDFS中
现在,我们要把Linux本地文件系统中的user_table.txt上传到分布式文件系统HDFS中,存放在HDFS中的“/bigdatacase/dataset”目录下。
首先,请执行下面命令,启动hadoop,在/opt/hadoop/sbin目录下
cd /opt/hadoop/sbin
hadoop namenode -format
./start-all.sh启动完毕后,jps查看
jps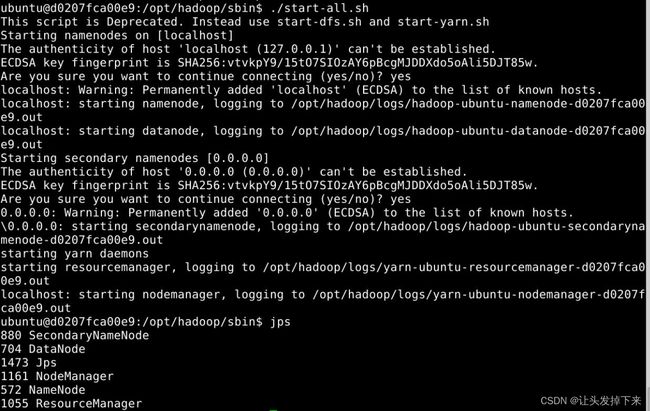
在HDFS的根目录下面创建一个新的目录bigdatacase,并在这个目录下创建一个子目录dataset,如下:
cd ~
hdfs dfs -mkdir -p /bigdata/dataset现在,我们要把Linux本地文件系统中的user_table.txt上传到分布式文件系统HDFS中,存放在HDFS中的“/bigdatacase/dataset”目录下。命令如下:
hdfs dfs -put user_table.txt /bigdata/dataset查看文件是否上传成功,命令如下:
hadoop fs -ls /
hadoop fs -ls /bigdata/dataset
下面可以查看一下HDFS中的user_table.txt的前10条记录,命令如下:
hadoop fs -cat /bigdata/dataset/user_table.txt | head -10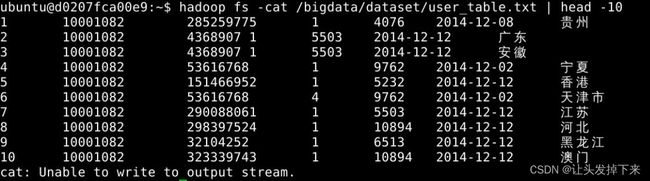
5.2在Hive上创建数据库
进入hive环境:
hive
启动成功以后,就进入了“hive>”命令提示符状态,可以输入类似SQL语句的HiveQL语句。
下面,我们要在Hive中创建一个数据库dblab,命令如下:
create database dblab;use dblab;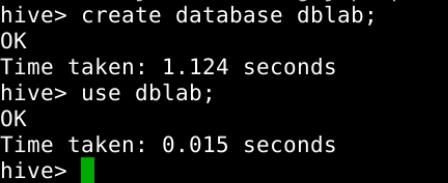
5.3创建外部表
这里我们要在数据库dblab中创建一个外部表bigdata_user,它包含字段(id, uid, item_id, behavior_type, item_category, date, province),请在hive命令提示符下输入如下命令:
create external table dblab.bigdata_user(id int,uid string,item_id string,behavior_type int,item_category string,visit_date date,province string) comment'Welcome to xmu dblab!' row format delimited fields terminated by '\t' stored as textfile location '/bigdata/dataset';
查看表格时候创建成功,命令如下:

5.4查询数据
上面已经成功把HDFS中的“/bigdatacase/dataset”目录下的数据加载到了数据仓库Hive中,我们现在可以使用下面命令查询一下:
select * from bigdata_user limit 10;
select behavior_type from bigdata_user limit 10; 
题目二:Hive数据分析
操作hive,在“hive>”命令提示符状态下执行下面命令
desc bigdata_user;
简单查询分析
先测试一下简单的指令:(查询前10位用户对商品的行为)
select behavior_type from bigdata_user limit 10;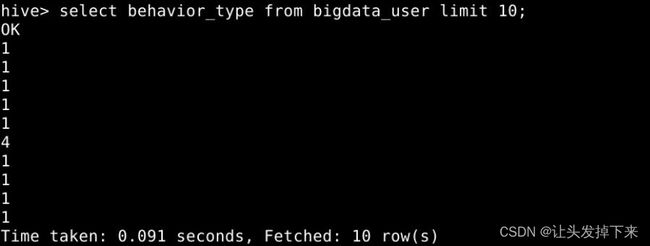
如果要查出每位用户购买商品时的多种信息,输出语句格式为 select 列1,列2,….,列n from 表名;比如我们现在查询前20位用户购买商品时的时间和商品的种类
select visit_date,item_category from bigdata_user limit 20;
有时我们在表中查询可以利用嵌套语句,如果列名太复杂可以设置该列的别名,以简化我们操作的难度,以下我们可以举个例子:
select e.bh,e.it from (select behavior_type as bh,item_category as it from bigdata_user)as e limit 20;
这里简单的做个讲解,behavior_type as bh ,item_category as it就是把behavior_type 设置别名 bh ,item_category 设置别名 it,FROM的括号里的内容我们也设置了别名e,这样调用时用e.bh,e.it,可以简化代码。
查询条数统计分析
经过简单的查询后我们同样也可以在select后加入更多的条件对表进行查询,下面可以用函数来查找我们想要的内容。
(1)用聚合函数count()计算出表内有多少条行数据
select count(*) from bigdata_user;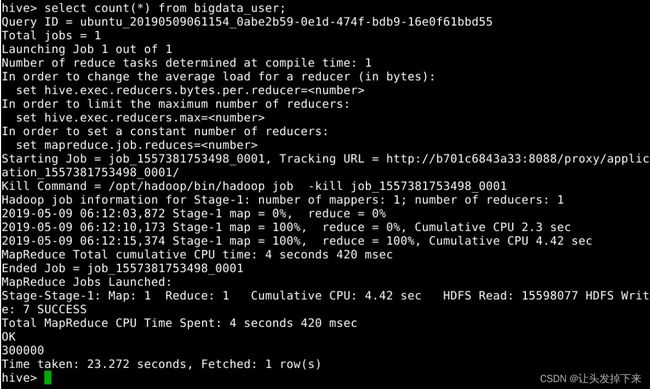
我们可以看到,得出的结果为OK下的那个数字300000(因为我们的small_user.csv中包含了300000条记录,导入到Hive中)。
(2)在函数内部加上distinct,查出uid不重复的数据有多少条
select count(distinct uid) from bigdata_user;
(3)查询不重复的数据有多少条(为了排除客户刷单情况)
select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,province from bigdata_user group by uid,item_id,behavior_type,item_category,visit_date,province having count(*)=1)a;可以看出,排除掉重复信息以后,只有284291条记录。
注意:嵌套语句最好取别名,就是上面的a
关键字条件查询分析
1.以关键字的存在区间为条件的查询
使用where可以缩小查询分析的范围和精确度,下面用实例来测试一下。
(1)查询2014年12月10日到2014年12月13日有多少人浏览了商品
select count(*) from bigdata_user where behavior_type='1' and visit_date<'2014-12-13' and visit_date>'2014-12-10';
(2)以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数
select count(distinct uid), day(visit_date) from bigdata_user where behavior_type='4' group by day(visit_date); 
2.关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定地点,求当天发出到该地点的货物的数量
注意:剪贴板不支持中文输入,所以请手动输入省会:江西
select count(*) from bigdata_user where province='江西' and visit_date='2014-12-12' and behavior_type='4';根据用户行为分析
(1)查询一件商品在某天的购买比例或浏览比例
select count(*) from bigdata_user where visit_date='2014-12-11'and behavior_type='4';语句说明:查询有多少用户在2014-12-11购买了商品

select count(*) from bigdata_user where visit_date ='2014-12-11'; 语句说明:查询有多少用户在
2014-12-11
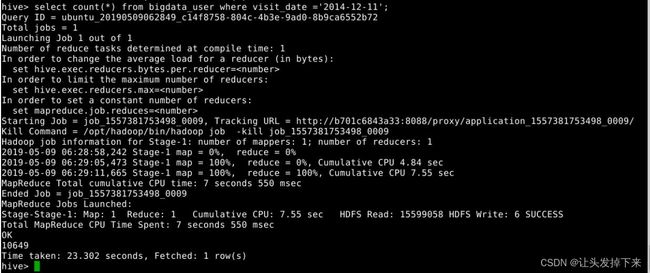
点击了该店
根据上面语句得到购买数量和点击数量,两个数相除即可得出当天该商品的购买率。
(2)查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买)
select count(*) from bigdata_user where uid=10001082 and visit_date='2014-12-12';语句说明:查询用户10001082在2014-12-12点击网站的次数
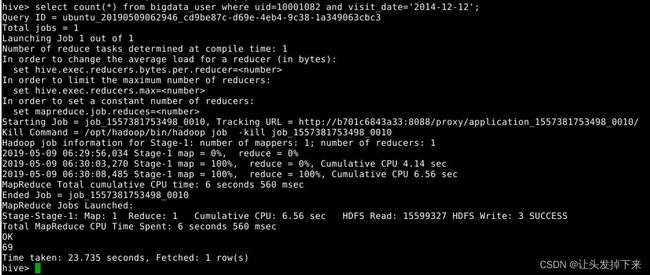
select count(*) from bigdata_user where visit_date='2014-12-12';语句说明:查询所有用户在这一天点击该网站的次数

上面两条语句的结果相除,就得到了要要求的比例。
(3)给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
select uid from bigdata_user where behavior_type='4' and visit_date='2014-12-12' group by uid having count(behavior_type='4')>5;语句说明:查询某一天在该网站购买商品超过5次的用户id

用户实时查询分析
某个地区的用户当天浏览网站的次数
create table scan(province STRING,scan INT) COMMENT 'This is the search of bigdataday' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;语句说明:创建新的数据表进行存储
![]()
insert overwrite table scan select province,count(behavior_type) from bigdata_user where behavior_type='1' group by province;语句说明:导入数据
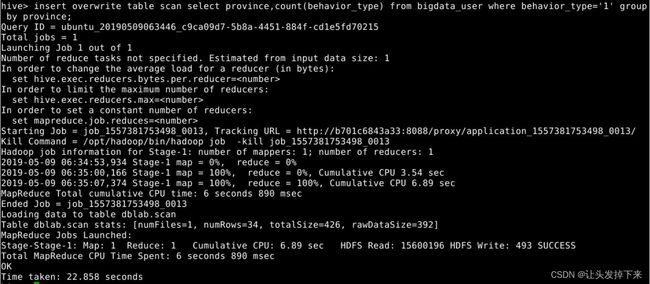
select * from scan;语句说明:显示结果
