MOSSE到KCF
Table of Contents
正文开始
MOSSE
相关滤波跟踪(MOSSE)
1 MOSSE与其他算法的具体比较
2 背景
3 基于追踪的相关性滤波器。
3.1 预处理
3.2 MOSSE过滤器
3.3 ASEF的正则化
3.4 过滤器初始化和在线更新
3.5 失败检测和PSR
4 评估
4.1 过滤器比较
4.2 与其他追踪器的比较
4.3 实时性能
5 结论
相关文献
KCF
相关滤波跟踪在跟踪领域的突破(MOSSE)
算法产生
算法块建立
线性回归
循环转换
循环矩阵
组合以上部分
和相关滤波器的关系
5 线性回归
5.1 Kernel trick(核方法) 简要概述
5.2 快速核回归
5.3 快速检测
6 快速核相关
6.1 点积和多项式核
6.2 径向基函数和高斯粒
6.3 其他核函数
7 多通道
7.1 通常情况
7.2线性内核
8 实验部分
8.1 追踪部分
8.2 推理
8.3 对全数据集的实验
8.4 序列属性实验
9 总结与展望
其他:
算法衍生过程:看下图(取自foolwood的维护图)。

学习目的:为学习C-COT和其衍生的ECO打基础。
ECO论文地址:http://www.robots.ox.ac.uk/~joao/publications/henriques_tpami2015.pdf
Table of Contents
正文开始
MOSSE
相关滤波跟踪(MOSSE)
1 MOSSE与其他算法的具体比较
2 背景
3 基于追踪的相关性滤波器。
3.1 预处理
3.2 MOSSE过滤器
3.3 ASEF的正则化
3.4 过滤器初始化和在线更新
3.5 失败检测和PSR
4 评估
4.1 过滤器比较
4.2 与其他追踪器的比较
4.3 实时性能
5 结论
相关文献
正文开始
MOSSE
算法作者:David S. Bolme J. Ross Beveridge Bruce A. Draper Yui Man Lui
算法提出时间:
算法论文地址:http://www.cs.colostate.edu/~vision/publications/bolme_cvpr10.pdf
相关滤波跟踪(MOSSE)
相关滤波器在跟踪领域在之前并没有被很好地应用,但是相关性滤波器够追踪发生旋转、遮蔽、和其他干扰的复杂物体,并且速度是当时技术的20倍以上,这这种特性正是优秀的目标跟踪所需要的。
一开始,最简单的相关性滤波器用简单的模板,在应用于追踪领域的时候通常以失败告终。之后出现了更加先进的方法如:ASEF、UMACE等则表现较好,但是这些算法的训练需求和追踪是很不匹配的。视觉追踪需要从一个单个的帧训练稳定而强健的滤波器,并能够随着物体外表发生变化而自适应。
作者一开始在论文中提了一下大环境,并举出几个当时表现不错的几个例子,指出其训练需求难满足,算法结构复杂等缺点。然后提出了他自己的算法————————最小输出平方误差(MOSSE)滤波器。MOSSE能够在初始化单个帧的时候产生稳健的滤波器。作者提到,基于MOSSE过滤器的跟踪器对照明、缩放、姿态和非刚性变形的变化非常有效,同时运行速度为669帧/秒。根据峰值-托旁比的比率(PSR)检测到遮挡,这使得跟踪器能够暂停并当对象重新出现时的位置重新开始追踪。
算法在当时诸如:增量视觉跟踪(IVT)[17],基于健壮的碎片跟踪(FragTrack)[1],基于图形的鉴别学习(GBDL)[19],以及多个实例学习(MILTrack)[2],虽然表现很好,但是这些算法本身或者包含的技术都十分复杂,它们通常包含复杂的外观模型和算法结构,因此,这些算法的帧率就显得有些差强人意了——25~30FPS。
对比很明显————在相同或者类似的准确度地情况下,MOSSE比其他算法更简洁,更加高速。
1 MOSSE与其他算法的具体比较
MOSSE以一种更简单的跟踪策略实现。它对目标的外观用自适应相关性滤波器来建模,并用卷积来追踪。而以往简单的创建过滤器的方法,例如从图像中裁剪模板,为目标生成强大的峰值,却也会对背景产生错误的响应。因此,他们对目标外观的变化并没有特别的鲁棒性,并且在具有挑战性的跟踪问题上失败了。合成精确滤波器(ASEF)的平均值,不受约束的最小平均相关能(UMACE),以及最小输出平方误差(MOSSE)(本文介绍)产生的滤波器对外观变化更有弹性,并且更好地区分目标和背景

如上图2所示,结果显示,以上提到的三种方法(ASEF、YMACE、MOSSE)比老套的过滤器在峰值上更高,换句话说,出现了更少的漂移和更少的掉落轨道。通常,ASEF和UMACE的过滤器都是离线训练的,并用于对象检测或者目标识别。作者在这些技术的基础上做了在线训练和自适应的改进,来用于视觉追踪。结果,用改进后的算法的追中保留了很多底层相关性方法的速度和简单性。

尽管这种方法很简单,但是基于修改后的ASEF、UMACE或者MOSSE过滤器在旋转,刻度,照明,和部分遮挡方面的变化表现很好(看Figure 1)。主副峰比(PSR)用于测量相关性峰值的强度,能够被用于遮挡或者追踪失败的检测,来停止在线更新,并在目标重新以类似的外观出现时重新开始追踪。更一般地说,这些高级相关过滤器实现了与前面提到的更复杂的跟踪器的性能一致;然而,基于过滤器的方法速度快了20倍,每秒可以处理669帧。
2 背景
20世纪80年代和90年代,出现了很多相关性滤波器的变种,包括合成判别函数(SDF)[7,6]、最小方差合成判别函数(MVSDF)[9]、最小平均相关能(MACE)[11]、最优权衡滤波器(OTF)[16]和最小平方误差合成判别函数(MSESDF)[10]。这些过滤器是根据不同外观的物体和强制的硬约束的例子来进行训练的,这样过滤器就会产生同样高的峰值。而MACE能产生高峰和高的PSRs,更具这种特性。
在[12]中,研究发现,像MACE这样的基于SDF的硬约束的过滤器会导致失真容限的问题。该问题的解决办法是通过消除硬约束,而不是要求过滤器去产生一个高平均相关性回应。这种新型的无约束相关性滤波器称为称为最大平均相关高度(MACH),这种滤波器也导致了一种叫做UMACE的MACE变体的产生。
一种称为ASEF [3]的新类型的关联过滤器引入了一种针对特定任务调优过滤器的方法。以前的方法只指定一个峰值值,ASEF指定每个训练图像的整个相关性输出。ASEF在眼睛定位[3]和行人检测[4]方面都表现良好。不幸的是,在这两项研究中,ASEF需要大量的训练图像,这使得视觉跟踪的速度太慢。
于是,作者开始通过引入一种适合于视觉跟踪的ASEF的正则化变体来减少这种数据需求。
3 基于追踪的相关性滤波器。
基于追踪器的过滤器通过在例样图片上训练过的过滤器来对物体外形进行建模。目标最初是基于一个以第一帧中的对象为中心的小型跟踪窗口来选择的。从这一点开始,跟踪和过滤训练一起工作。在下一帧中,通过将过滤器与搜索窗口关联起来,跟踪目标。在相关输出中对应于最大值的位置表示目标的新位置。然后根据这个新位置进行在线更新。
为了创建一个快速跟踪器,在傅里叶域快速傅里叶变换(FFT)[15]中计算出相关性。首先,输入图像的二维傅里叶变换: 和滤波器:
和滤波器: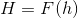 。卷积定理说,相关性成为傅里叶域的一个元素乘法。通俗地说,卷积定理中,图像在时域上的卷积等于图像在频域上的乘法。使用这个符号⊙来显式地表示元素的乘法并用∗表示复共轭,相关性如下形式表达:
。卷积定理说,相关性成为傅里叶域的一个元素乘法。通俗地说,卷积定理中,图像在时域上的卷积等于图像在频域上的乘法。使用这个符号⊙来显式地表示元素的乘法并用∗表示复共轭,相关性如下形式表达:
 (1)
(1)
然后通过反FFT将相关输出从傅里叶域转换回空间域。这个过程的瓶颈是前向计算和逆FFTs,这样整个过程就有一个O(P log P)的上限时间P,P就是跟踪窗口中像素的数量
3.1 预处理
FFT卷积算法的一个问题是图像和滤波器被映射到一个环面的拓扑结构。换句话说,它将图像的左边缘连接到右边缘,并将顶部与底部连接起来。在卷积的过程中,图像在环形空间中旋转,而不是像在空间域中那样进行转换。人为地连接图像的边界会引入一个工件,它会影响相关输出。
通过遵循Average of synthetic exact filters. In CVPR, 2009(可以参考这篇博客简单了解)中列出的预处理步骤,可以减少这种效果。首先,像素值是使用对数函数进行转换的,这有助于低对比度的照明情况。像素值被规范化为0.0的平均值和1.0的范数。最后,图像乘以一个余弦窗口,它会逐渐减少边缘附近的像素值为0。这也有好处它将更多的重点放在目标中心附近
3.2 MOSSE过滤器
MOSSE是一种从较少的训练图像中产生类似于ASEF相似的过滤器的算法。首先,它需要一组训练图像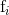 和训练输出
和训练输出 ,一般而言能够取任何形状。在这种情况下,是由正确的标注数据(即我们常说的label)产生的,它有一个紧凑的(
,一般而言能够取任何形状。在这种情况下,是由正确的标注数据(即我们常说的label)产生的,它有一个紧凑的( =2.0)的二维高斯形状的峰在训练图像的目标上。训练是在傅里叶域进行的,以利用输入和输出之间简单的元素之间的关系。和前一节一样,我们定义大写的变量
=2.0)的二维高斯形状的峰在训练图像的目标上。训练是在傅里叶域进行的,以利用输入和输出之间简单的元素之间的关系。和前一节一样,我们定义大写的变量 ,
,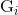 和过滤器
和过滤器 是它们小写字母的傅里叶变换.
是它们小写字母的傅里叶变换.

 (2)
(2)
在这里,除法是由元素来执行的
为了找到一个将训练输入映射到所需训练输出的过滤器,MOSSE找到一个滤波器H,它最小化了卷积的实际输出和卷积的期望输出之间的平方误差之和。这个最小化问题的形式
 (3)
(3)
将平方误差(SSE)与输出最小化的想法并不新鲜。实际上,方程(3)中的优化问题与Minimum squared error synthetic discriminant functions. Optical Engineering, 31:915, 1992. 2和Unconstrained correlation filters. Applied Optics, 33(17):3751–3759, 1994中给出的优化问题几乎相同。不同之处在于,在这些作品中,我们假设目标总是在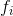 中心处,而输出(
中心处,而输出(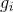 )是固定在整个训练集上的,而定制每个是ASEF和MOSSE背后的基本思想。在跟踪问题中,目标并不总是以中心为中心,而的峰值则在
)是固定在整个训练集上的,而定制每个是ASEF和MOSSE背后的基本思想。在跟踪问题中,目标并不总是以中心为中心,而的峰值则在 中跟随目标。在更一般的情况下,
中跟随目标。在更一般的情况下, 可以取任何shape。
可以取任何shape。

解决这个优化问题并不是特别困难,但是确实需要一些注意,因为优化的函数是一个复杂变量的实值函数。首先,H的每个元素(索引 和
和 )都可以独立地解决,因为傅里叶域中的所有运算都是由元素来执行的。这涉及到从
)都可以独立地解决,因为傅里叶域中的所有运算都是由元素来执行的。这涉及到从 和
和 来重写函数。然后,W.R.T. 的部分被设定为零,同时把当作一个独立的变量(D. Messerschmitt. Stationary points of a real-valued function of a complex variable. Technical report, EECS, U.C. Berkeley, 2006. 4, 10)
来重写函数。然后,W.R.T. 的部分被设定为零,同时把当作一个独立的变量(D. Messerschmitt. Stationary points of a real-valued function of a complex variable. Technical report, EECS, U.C. Berkeley, 2006. 4, 10)
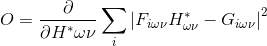 (4)
(4)
通过求解MOSSE滤波器的封闭形式表达式 ,得到:
,得到:
 (5)
(5)
一个完整的推导是在附录A中,方程式5中的术语有一个有趣的解释。分子是输入和期望输出之间的关系,分母是输入的能量谱
从方程5中,我们可以很容易地看出UMACE是一个特殊的MOSSE案例。UMACE被定义为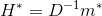 其中m是一个包含平均中心裁剪训练图像FFT的矢量,D是一个对角矩阵包含训练图像的平均能量谱.因为D是一个对角矩阵,乘以它的逆本质上是一个元素的除法。当用当前的符号重写时,UMACE会采用这种形式:
其中m是一个包含平均中心裁剪训练图像FFT的矢量,D是一个对角矩阵包含训练图像的平均能量谱.因为D是一个对角矩阵,乘以它的逆本质上是一个元素的除法。当用当前的符号重写时,UMACE会采用这种形式:
 (6)
(6)
然而,UMACE要求目标以 为中心。重新进入可以使用相关性进行。如果我们将
为中心。重新进入可以使用相关性进行。如果我们将 定义为克罗尼克三角洲(在目标中心有一个峰值,而在其他地方则为0),这将本质上重新进入目标并计算一个UMACE过滤器。这个和传统的实现的区别在于我们在这里裁剪然后转换,传统的方法是先转换后裁剪。
定义为克罗尼克三角洲(在目标中心有一个峰值,而在其他地方则为0),这将本质上重新进入目标并计算一个UMACE过滤器。这个和传统的实现的区别在于我们在这里裁剪然后转换,传统的方法是先转换后裁剪。
为了证明MOSSE能产生比ASEF更好的过滤器,我们进行了一个实验,它改变了用于训练过滤器的图像的数量。通过对视频的第一帧的跟踪窗口应用随机小的仿射干扰来初始化过滤器。第二帧的PSR被用作过滤质量的一种测量方法。图3显示,在对少量图像窗口进行训练时,MOSSE会产生更好的过滤器。原因将在下一节中讨论。
3.3 ASEF的正则化
ASEF采用了一种稍微不同的方法来最小化相关转换中的错误。事实证明,当只有一个训练图像和一个输出图像时,有一个过滤器可以产生零错误。这个过滤器被称为精确滤波器可以通过求解方程1来找到:
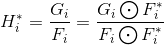 (7)
(7)
在一个图像上训练的精确过滤器几乎总是超出了这个图像。当应用到一个新图像时,这个过滤器通常会失败。平均用于产生更一般的过滤器。平均的动机来自于Bootstrap Aggregation(出自L. Breiman. Bagging Predictors. Machine Learning, 24(2):123–140, 1996. 5),其中弱分类器的输出可以被平均地产生一个更强的分类器。通过一些操作,ASEF过滤器的方程可以显示为:
 (8)
(8)
如果只使用一个图像进行训练,MOSSE和ASEF都能产生精确的过滤器
ASEF过滤器在对少量图像进行训练时是不稳定的,因为当训练图像中的频率几乎没有能量时(或者分母接近于零)时,方程8中的元素的划分就变得不稳定了。平均大量的精确过滤器弥补了这个问题,并产生了健壮的ASEF过滤器。因为MOSSE的分母是能量除以更多图像的总和,它很少会产生小的数字因此更稳定。
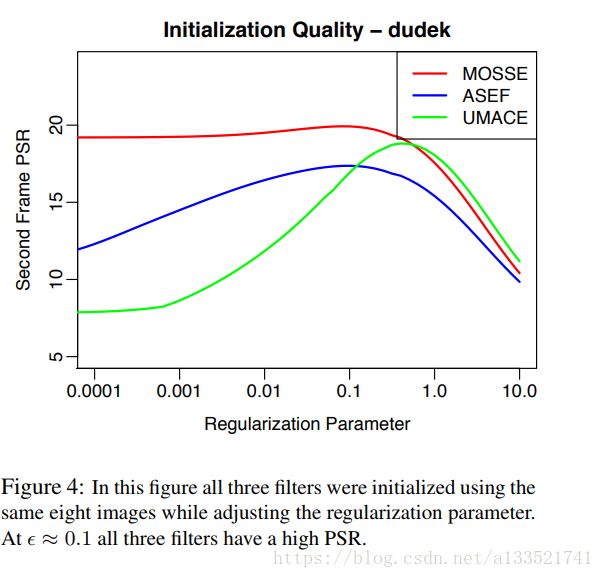
另一种方法是,正则化可以用来校正低能量频率,并产生更稳定的ASEF过滤器。这是通过在能量谱中添加一个小值来实现的。 i被替换为
i被替换为 其中
其中 是正则化参数.
是正则化参数.
正则化类似于OTF理论的结果,它通常与UMACE过滤器一起使用。这一结果表明,将背景噪音的能量谱添加到训练图像中,将产生一个更好的噪声容差(出自P. Refregier. Optimal trade-off filters for noise robustness, sharpness of the correlation peak, and Horner efficiency. Optics Letters, 16:829–832, June 1991.)。这里我们添加了白噪声。
图4显示了调整%的效果。通过适当的正则化所有的过滤器都产生了良好的峰值并且应该足够稳定以产生良好的追踪。
3.4 过滤器初始化和在线更新
方程式8和5描述了在初始化过程中如何构造过滤器。训练集是使用随机仿射变换构造的,在初始帧中产生8个小的扰动()。训练输出()也会产生与目标中心相对应的峰值。
在跟踪过程中,目标通常可以通过改变其旋转、尺度、姿态,通过不同的光照条件,甚至是通过非刚性的变形来改变外观。因此,过滤器需要快速适应以跟踪对象。运行平均值用于此目的。例如,从坐标系i中学习的ASEF过滤器被计算为:
 (9)
(9)
MOSSE过滤器则是这样的:
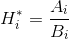 (10)
(10)
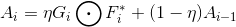 (11)
(11)
 (12)
(12)
其中 代表学习速率。这将使最近的帧更有分量,并让前帧的效果随着时间的推移呈指数衰减。在实践中,我们发现=0.125允许过滤器快速适应外观的变化,同时仍然保持一个健壮的过滤器。
代表学习速率。这将使最近的帧更有分量,并让前帧的效果随着时间的推移呈指数衰减。在实践中,我们发现=0.125允许过滤器快速适应外观的变化,同时仍然保持一个健壮的过滤器。
3.5 失败检测和PSR
正如前面提到的,一个简单的峰值强度测量被称为峰到斜比(PSR)。为了计算PSR,相关输出g被分割成最大值,也就是最大值和侧面,也就是像素的其余部分,不包括在峰值附近的11 ×11个窗口。PSR被定义为 中
中 是峰值值而
是峰值值而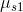 和
和 是侧面的平均值和标准偏差。
是侧面的平均值和标准偏差。
根据我们的经验,在正常跟踪条件下,PSR、ASEF和MOSSE通常在20.0到60.0之间,这表示非常强的峰值。我们发现,当PSR下降到7时左右,这表明物体被遮挡或跟踪失败了。对于简单的实现PSR在3.0到10.0之间,对于预测跟踪质量没有用处。
4 评估
最初,一个实时的基于MOSSE的跟踪系统是在网络摄像头的实时视频中创建和评估的。实时反馈可以很容易地测试跟踪器配置的小变化,并对各种目标和跟踪条件的跟踪性能进行定性分析。这些测试为跟踪器的操作提供了有价值的见解,并帮助生成了本文中介绍的快速和健壮的跟踪器。
对7个常用的测试视频进行了更有控制的评估,这些视频可以从http://www.cs.toronto.edu/∼dross/ivt/免费下载。测试视频都是灰度级的,包括在照明、姿势和外观方面的挑战。摄像机本身在所有的视频中都在移动,这增加了目标的不稳定运动。这七个序列包括两个车辆跟踪场景(car4,car11),两个玩具跟踪场景(fish,sylv)和三个面部跟踪场景(davidin300,dudek和trellis70)。
4.1 过滤器比较
节评估UMACE、ASEF和MOSSE过滤器的跟踪质量。这些都与一个简单的过滤器进行了比较,该过滤器基于一个平均预先处理的跟踪窗口,并带有在线更新。跟踪输出被手动标记为良好的跟踪,跟踪是偏离中心的,或者是丢失的轨迹(见图5)
从定性上说,所有的过滤器,包括单纯的过滤器,都能够在测试集中的范围、旋转和光照变化的范围内追踪物体的轨迹,而大多数的漂移和失败都发生在目标经历了一个大的外平面旋转时。请参见图6中的davidin300序列示例。过滤器倾向于跟踪目标中心的一个点。当目标旋转时,这个点移动到目标边界,跟踪器最终进入一个状态,其中大部分跟踪窗口都被背景所覆盖。过滤器适用于这个半背景窗口当目标旋转回到一个正面的位置时,过滤器有时会转移到一个新的位置或者它们可能会松开目标并跟踪背景。
这些结果表明,先进的相关滤波器跟踪目标的时间比单纯的方法要长。峰值也有好处,PSR可以很好地预测轨迹质量,而PSR对天真的过滤器来说并不是特别有用。对于高级过滤器来说,漂移和故障总是与低PSRs有关。如图7所示,这表明MOSSE PSR可以定位该视频中最具挑战性的部分。



对于基于过滤器的追踪器来说,很难断言任何一个过滤器类型都能很好地执行另一个过滤器。在这七个视频序列中的四个,相关过滤器执行得很好。在davidin300上所有的过滤器在相同的平面旋转过程中从脸部的中心漂移到眼睛里在这个序列的相同的困难部分中过滤器漂移。这两个序列表明,筛选类型的选择并不特别重要,因为过滤器以完全相同的方式失败。

只有在dudek序列中,这三个过滤器之间有显著的区别。虽然MOSSE完美地完成了这一过程,但UMACE和ASEF在视频的部分内容上遇到了问题。尽管在第3节中提供的证据表明MOSSE可能是这个任务的最佳过滤器,但是在一个视频序列上的单个故障不足以支持一个强有力的声明;还需要更多的研究
4.2 与其他追踪器的比较
为了评估算法维护轨迹的能力,我们将我们的输出与IVT 17和MILTrack 2的作者发布的视频进行了比较(见第4节)。这些视频还包含了健壮的在线外观模型(漫游)8、在线Ada-Boost(OAB)14和碎片1的示例结果。我们考虑过为其他算法下载代码但我们选择研究作者自己的视频这代表了这些算法的最佳性能同时也减少了我们未能正确实现或优化这些算法的论点。在这些比较中,我们的方法能够保持轨迹,或者比那些算法更好。本着这种精神,我们还将我们的结果发布到我们的网站youtube上(http://youtube.com/users/bolme2008),这样其他人就可以进行相同的比较。图8描述了视频中的格式和注释。
在D. Ross, J. Lim, R. Lin, and M. Yang. Incremental learning for robust visual tracking. IJCV, 77(1):125–141, 2008. 1, 2, 7中,IVT 和ROAM在图5的四个序列中进行了比较。其中,davidin300和dudek的序列成功地完成了。IVT在sylv的第620帧附近失败了,在框架330的框架下也失败了。在已发布的视频序列中,漫游跟踪器执行得很好。这两个追踪器所缺少的两个追踪器的一个特点是,它们估计了目标的规模和方向,提供了关于它在空间位置的更多信息。

I在[2]中,MILTrack [2]、OAB [14]和FragTrack [1]在davidin300和sylv序列上进行了比较。所有的追踪器都显示出明显的漂移,在davidin300上失败了。这些追踪器的漂移与过滤器所看到的完全不同。在这些视频中,跟踪窗口在目标之间来回移动。当过滤器漂移时,当目标发生改变时,它们倾向于偏离中心,然后它们被锁定在一个新的中心点。
4.3 实时性能

测试是在一个2.4 Ghz的核心2双核MacBook Pro的处理器上进行的。本文中测试的跟踪器是用Python编写的,使用PyVision库、OpenCV和SciPy。最初的Python实现在使用64 64跟踪窗口时,平均每秒大约250次跟踪更新。为了更好地测试跟踪器的运行时性能,代码中一些较慢的部分在C中重新实现,其中包括更好的内存管理和更有效的时间消耗任务,如标准化、FFTs和PSRs。这些优化的结果是,帧速率为每秒669次,如图9所示。
基于过滤器的跟踪的计算复杂度是O(P log P),其中P是过滤器中像素的数量。这来自于相关操作和在线更新中使用的FFTs。跟踪初始化会产生一种O(NP log P)的时间成本,其中N是用来初始化第一个过滤器的仿射扰动的数量。虽然这比在线更新慢很多倍,但是初始化仍然比实时的速度快,每秒66.32帧更新。
5 结论
摘要本文研究了利用重权分类器、复杂的外观模型和随机搜索技术来解决的视觉跟踪问题,可以用高效、简单的MOSSE相关滤波器代替。其结果是一种易于实现的算法,可以是准确的,而且速度要快得多。
在这篇论文中,跟踪器被简单地用来评估过滤器的跟踪和适应困难的跟踪场景的能力。有很多简单的方法可以改进这个跟踪器。
例如,如果目标的外观相对稳定,可以通过偶尔重新进入基于初始帧的过滤器来减轻漂移。跟踪器还可以通过在更新后过滤跟踪窗口的log极坐标转换来估计规模和旋转的变化。
相关文献
[1] A. Adam, E. Rivlin, and I. Shimshoni. Robust fragmentsbased tracking using the integral histogram. In CVPR, 2006. 1, 2, 7
[2] B. Babenko, M.-H. Yang, and S. Belongie. Visual Tracking with Online Multiple Instance Learning. In CVPR, 2009. 1, 2, 7
[3] D. S. Bolme, B. A. Draper, and J. R. Beveridge. Average of synthetic exact filters. In CVPR, 2009. 2, 3
[4] D. S. Bolme, Y. M. Lui, B. A. Draper, and J. R. Beveridge. Simple real-time human detection using a single correlation filter. In PETS, 2009. 2, 3
[5] L. Breiman. Bagging Predictors. Machine Learning, 24(2):123–140, 1996. 5
[6] D. Casasent. Unified synthetic discriminant function computational formulation. Appl. Opt, 23(10):1620–1627, 1984. 2
[7] C. Hester and D. Casasent. Multivariant technique for multiclass pattern recognition. Appl. Opt., 19(11):1758–1761, 1980. 2
[8] A. Jepson, D. Fleet, and T. El-Maraghi. Robust online appearance models for visual tracking. T-PAMI, 25(10):1296–1311, 2003. 7
[9] B. Kumar. Minimum-variance synthetic discriminant functions. J. Opt. Soc. of America., 3(10):1579–1584, 1986. 2
[10] B. Kumar, A. Mahalanobis, S. Song, S. Sims, and J. Epperson. Minimum squared error synthetic discriminant functions. Optical Engineering, 31:915, 1992. 2, 3
[11] A. Mahalanobis, B. V. K. V. Kumar, and D. Casasent. Minimum average correlation energy filters. Appl. Opt., 26(17):3633, 1987. 2
[12] A. Mahalanobis, B. Vijaya Kumar, S. Song, S. Sims, and J. Epperson. Unconstrained correlation filters. Applied Optics, 33(17):3751–3759, 1994. 2, 3
[13] D. Messerschmitt. Stationary points of a real-valued function of a complex variable. Technical report, EECS, U.C. Berkeley, 2006. 4, 10
[14] N. C. Oza. Online Ensemble Learning. PhD thesis, U.C. Berkeley, 2001. 7
[15] W. Press, B. Flannery, S. Teukolsky, and W. Vetterling. Numerical Recipes in C. Cambridge Univ. Press, 1988. 3
[16] P. Refregier. Optimal trade-off filters for noise robustness, sharpness of the correlation peak, and Horner efficiency. Optics Letters, 16:829–832, June 1991. 2, 5
[17] D. Ross, J. Lim, R. Lin, and M. Yang. Incremental learning for robust visual tracking. IJCV, 77(1):125–141, 2008. 1, 2, 7
[18] M. Savvides, B. Kumar, and P. Khosla. Face verification using correlation filters. In AIAT, 2002. 4
[19] X. Zhang, W. Hu, S. Maybank, and X. Li. Graph based discriminative learning for robust and efficient object tracking. In ICCV, 2007. 1, 2



KCF
算法作者:João F. Henriques, Rui Caseiro, Pedro Martins, and Jorge Batista
算法提出时间:
算法论文地址:http://www.cs.colostate.edu/~vision/publications/bolme_cvpr10.pdf
相关滤波跟踪在跟踪领域的突破(MOSSE)
在MOSSE成功地将相关滤波加入到追踪领域,并利用卷积定理:在时域的卷积即傅里叶域中元素的点乘。
Real-time compressive tracking,Tracking-learning-detection,Robust object tracking with online multiple instance learning,On-line random forests等算法都是当时最流行的算法类型----------------判别模型类。判别模型类包括在网络上训练一个分类器,受统计机器学习方法的启发,来预测图像中目标的存在与否。跟踪-检测范式的典型例子包括那些基于Support Vec-tor Machines (SVM) , Random Forest classifiers, or boosting variants。以上提到的几种算法都必须适应在线学习,以便对跟踪有用。
作者的目标是能够在转换过的图像块上能够有效地学习和检测。和KCF不一样,大多数其他的方法都把心思花在去除不相关的图像块上。在检测方面,可以使用分支定界来查找分类器的最大响应,避免在不相关的候选块花费资源。
算法产生
作者的idea萌生于MOSSE网路的产生。
这一工作的初步版本早在29年就提出了。它第一次证明了脊回归与周期性变化的样本和经典相关滤波器之间的联系。这使得快速学习与O(n log n)快速的傅里叶变换而不是消耗的矩阵代数。第一个核相关过滤器也被提出,尽管仅限于一个单独的通道。此外,它还提出了在所有循环移位中计算内核的封闭形式的解决方案。这些都带有相同的O(n log n)的计算成本,并且它们是由径向基和点积核推导出来的
算法块建立
线性回归
脊回归能够提供一个简单封闭性的解决方案,并且能够实现与更复杂方法如SVM相当的性能。训练的目标是找到一个函数: .能够最小化样本
.能够最小化样本 和它们的回归值
和它们的回归值 之间的平方差。:
之间的平方差。:
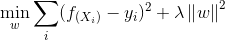 (1)
(1)
 是一个正则化参数用于控制过拟合。正如之前提到的,这个最小化函数有一个闭合形式:
是一个正则化参数用于控制过拟合。正如之前提到的,这个最小化函数有一个闭合形式:
 (2)
(2)
矩阵X每一行X有一个样本,y的每一个元素都是一个回归目标y i。I是一个单位矩阵.
在4.4中,作者的工作不得不在傅里叶域中进行,而在傅里叶域中数量通常是复杂的。但是只要用EQ(2)来处理就不会变得更困难。

 是厄米矩阵的转置,也就是
是厄米矩阵的转置,也就是 ,
, 是X的复共轭。对于实数等式3会降级到等式2
是X的复共轭。对于实数等式3会降级到等式2

循环转换
考虑一个n个矢量,它表示一个带特征的物体的patch,表示为x。我们将把它作为基本样本。我们的目标是用基本样本(一个积极的例子)和通过转换获得的几个虚拟样本(作为反面例子)来训练一个分类器。我们可以用一个循环移位算子来模拟这个矢量的一维变换,也就是置换矩阵

乘积![Px = [x_n,x_1,x_2,...,x_{n-1}]^T](http://img.e-com-net.com/image/info8/8ba95505e4264740b604f77a8ac421a9.gif) 通过一个元素转换x,建模一个小的转换。我们可以通过使用矩阵
通过一个元素转换x,建模一个小的转换。我们可以通过使用矩阵 来把u移到更大的转换
来把u移到更大的转换
由于循环性质,我们每n次移动得到相同的信号x。这意味着所有的移位信号都是通过(5)获得的
 (5)
(5)
由于循环性质,我们可以把这个集合的前半部分看成是正的负向,而下半部分则是负方向的变化
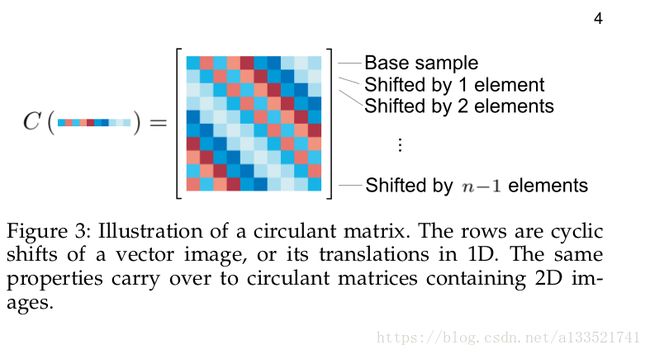
循环矩阵
为了用转换过的样本来计算回归,用式子(5)作为矩阵X的一行数据

所有的循环矩阵都是由离散傅里叶变换(DFT)对角化的,可以表达为:
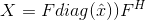 (7)
(7)
其中,F是一个常量矩阵无关于X,并且 表示离散傅里叶变换生成的向量,
表示离散傅里叶变换生成的向量, 。从现在起我们将会用
。从现在起我们将会用  来标记离散傅里叶变换产生的向量。
来标记离散傅里叶变换产生的向量。
常数矩阵F已知为DFT矩阵。并且是用来计算任何输入向量的DFT的唯一矩阵,写为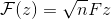 。因为DFT是一个线性操作,所以写为这样是完全可行的。
。因为DFT是一个线性操作,所以写为这样是完全可行的。
组合以上部分
当训练数据由循环转换组成时,我们可以运用新的知识来简化等式3中的线性回归问题。
取 ,它可以被看作是一个非中心的协方差矩阵。取代等式7中的部分。
,它可以被看作是一个非中心的协方差矩阵。取代等式7中的部分。
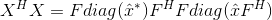 (8)
(8)
因为对角矩阵是对称的,取厄密共轭的转置只留下了一个复共轭,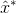 .
.
另外,我们可以消去因子 .这个性质是F的单位性可以在很多表达式中被消掉,我们只剩下
.这个性质是F的单位性可以在很多表达式中被消掉,我们只剩下
 (9)
(9)
因为对角矩阵的运算是元素的,我们可以定义元素的乘积并得到
 (10)
(10)
以上的步骤总结了通常采用的方法-----用循环矩阵在对角表达式中。通过运用这些方法,可以将它们递归到完整的线性回归的表达式(等式3),我们将大部分的表达式放入对角矩阵中:
 (11)
(11)
或者更好:
 (12)
(12)
分数部分表示为元素级别的除法。我们可以轻易地将w用反向DFT转换回空间域,这和前向DFT所花费的代价一样。
另外,在这一点上作者刚刚发现了一个来自经典信号处理的意外公式解决方案是一个正则化的相关滤波器。在进一步探索这种关系之前,我们必须对Eq的计算效率进行高强度的计算,与一般的提取patch的方法相比,并解决一般的回归问题。
和相关滤波器的关系
自80年代以来,相关滤波器一直是信号处理的一部分,在傅里叶域中有无数个目标函数的解。这些过滤器的解决方案看起来像Eq.12,但是有两个关键的区别。首先,MOSSE筛选器是从一个在傅里叶域中特别制定的目标函数中得到的.其次,正则化器以一种特别的方式添加,以避免按零分。我们上面所展示的推导增加了相当的洞察力,通过将起始点指定为带循环移位的脊回归,并到达相同的解。
循环矩阵使我们能够通过经典的信号处理和现代的相关滤波器来丰富工具集,并将傅里叶的技巧应用到新的算法中。在下一节中,我们将看到一个这样的例子,在培训非线性滤波器中。
5 线性回归
允许更强大的非线性回归函数f(z)的一种方法是使用内核技巧23。最吸引人的特性是优化问题仍然是线性的,尽管是在不同的变量集合中(双空间)。在不利方面,评估f(z)通常会随着样本数量的增加而增长。
然而,使用我们的新分析工具,我们将证明有可能克服这一限制,并获得与线性相关滤波器一样快的非线性过滤器,用于培训和评估。
5.1 Kernel trick(核方法) 简要概述
本节将简要回顾内核技巧,并定义相关的符号。
.将线性问题的输入映射到非线性特性空间(x)和内核技巧包括:
(1) 将解决方案w表示为样本的线性组合:
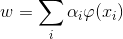 (13)
(13)
因此,优化下的变量是以w代替的。这个替代表示被认为是在双空间中,而不是原始空间w
( 2 ) 用点积 来编写算法,这些都是用核函数
来编写算法,这些都是用核函数 (例如,高斯函数或多项式)来计算的。
(例如,高斯函数或多项式)来计算的。
所有成对样品之间的点积通常是存储在n x n内核矩阵K中,原理如下:
 (14)
(14)
内核技巧的威力来自于对高维特性空间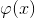 的隐式使用,而不需要实例化该空间中的向量。不幸的是,这也是它最大的弱点,因为回归函数的复杂性随着样本数量的增加而增加.
的隐式使用,而不需要实例化该空间中的向量。不幸的是,这也是它最大的弱点,因为回归函数的复杂性随着样本数量的增加而增加.
 (15)
(15)
5.2 快速核回归
通过对脊回归的角化版本的解决方案
 (16)
(16)
K是内核矩阵,是coeffi-cient i的矢量,它代表了对偶空间中的解.
现在,如果我们能证明K是循环移位数据集的循环,我们可以对Eq.16进行对角化,得到一个快速解,就像线性情况一样。这似乎是正确的,但一般来说是不成立的。任意的非线性映射 不能保证任何形式的结构。然而,我们可以施加一个条件,使K可以循环。结果是相当宽泛的,适用于最有用的内核
不能保证任何形式的结构。然而,我们可以施加一个条件,使K可以循环。结果是相当宽泛的,适用于最有用的内核
定理1:给定循环数据 ,对于任何排列矩阵M,如果内核函数满足
,对于任何排列矩阵M,如果内核函数满足 ,则对应的内核矩阵
,则对应的内核矩阵 是循环的
是循环的
为了证明,请参阅附录A.2。这意味着,对于内核来说,要保持循环结构,它必须平等地对待数据的所有维度。幸运的是,这包括了最有用的内核
检查这个事实是很容易的,因为对这些内核重新排序 和
和 0同时不会改变
0同时不会改变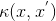 。这适用于任何通过交换操作结合维度的内核,比如sum、product、min和max。
。这适用于任何通过交换操作结合维度的内核,比如sum、product、min和max。
知道我们可以用哪些核来做K循环,就可以对角化Eq,16在线性情况下,得到:
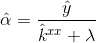 (17)
(17)
 是内核矩阵
是内核矩阵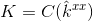 的第一行,再一次,帽子表示一个向量的DFT形式。详细的推导在附录A.3中。
的第一行,再一次,帽子表示一个向量的DFT形式。详细的推导在附录A.3中。
为了更好地理解的作用,我们发现定义一个更一般的内核相关性是很有用的。两个任意向量的核相关,和,是带有元素的向量,用元素
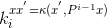 (18)
(18)
总的来说,它包含了对两个参数的不同相对移位的评估。然后是和自身的核相关,在傅里叶域中。我们可以把它称为内核自动相关,与线性情况类似.
这个类比可以更进一步。因为内核等同于高维空间中的点积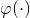 ,另一种看待Eq.18的方法是:
,另一种看待Eq.18的方法是:
 (19)
(19)
这就是在高维空间中和的相互关系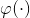
请注意,我们只需要计算和操作内核自动相关,即n x 1矢量,它随样本数量线性增长。这与内核方法的传统智慧相反,它需要计算一个n x n内核矩阵,并与样本进行二次伸缩。我们对K的精确结构的了解使我们比一般算法做得更好.
找到最优的并不是唯一可以加速的问题,因为在跟踪检测的环境中无处不在的翻译补丁。在下一段中,我们将研究循环移位模型对检测阶段的影响,甚至在计算内核相关性方面
5.3 快速检测
很少有这样的情况,我们想要单独地评估一个图像块的回归函数 。为了检测感兴趣的对象,我们通常希望在几个图像位置上评估。对于几个候选块。这些块可以通过循环移位来建模。
。为了检测感兴趣的对象,我们通常希望在几个图像位置上评估。对于几个候选块。这些块可以通过循环移位来建模。
用 表示所有训练样本和所有候选补丁之间的(不对称)内核矩阵。由于样本和补丁是基本样本和基带
表示所有训练样本和所有候选补丁之间的(不对称)内核矩阵。由于样本和补丁是基本样本和基带 的循环移位,所以K z的每个元素都是由
的循环移位,所以K z的每个元素都是由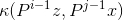 给出的。很容易验证这个内核矩阵是否满足定理1,并且是合适的内核的循环.
给出的。很容易验证这个内核矩阵是否满足定理1,并且是合适的内核的循环.
与Section 5.2相似,我们只需要第一行来定义内核矩阵:
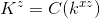 (20)
(20)
 是和的内核相关性,就像之前定义的那样
是和的内核相关性,就像之前定义的那样
从Eq.15,我们可以计算所有候选块的回归函数
 (21)
(21)
请注意,是一个向量,它包含了的所有循环移位的输出。完整的检测反应。为了有效地计算Eq.21,我们把它对角化
 (22)
(22)
直观地说,在所有位置对进行评估可以看作是内核值的空间过滤操作。每一个是来自的相邻内核值的线性组合,由学习系数加权。因为这是一个过滤操作,它可以在傅里叶域中更有效地表述
6 快速核相关
尽管我们已经找到了更快的训练和检测算法,但它们仍然依赖于计算一个内核的关系(分别是 和)。回想一下,内核相关性包括计算两个输入向量的所有相对移位的内核。这代表了最后一个站立的计算瓶颈,因为对于n内核的n个内核的简单评估将具有二次复杂度。然而,使用循环移位模型将使我们能够有效地利用这个昂贵的计算中的冗余
和)。回想一下,内核相关性包括计算两个输入向量的所有相对移位的内核。这代表了最后一个站立的计算瓶颈,因为对于n内核的n个内核的简单评估将具有二次复杂度。然而,使用循环移位模型将使我们能够有效地利用这个昂贵的计算中的冗余
6.1 点积和多项式核
点积核有形式 ,对一些函数g。然后,
,对一些函数g。然后,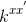 有元素
有元素
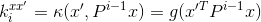 (23)
(23)
让g在任何输入向量上都能工作。这样我们就可以用矢量形式来写Eq.23。
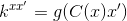 (24)
(24)
这使得它很容易成为对角化的目标
 (25)
(25)
 表示逆DFT的地方
表示逆DFT的地方
特别地,对于一个多项式内核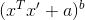
然后,在O(n log n)的时间内,只使用少量的DFT/IDFT和元素操作来计算这些特别的内核相关性。
6.2 径向基函数和高斯粒
对于一些函数 ,RBF内核有形式
,RBF内核有形式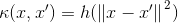 。的元素是
。的元素是
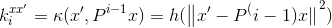 (27)
(27)
我们将展示(Eq,29)这实际上是一个点积内核的特殊情况。我们只需要引申到一般情况:
 (28)
(28)
由于Parseval s定理21,置换 不影响x的范数。由于
不影响x的范数。由于 和
和 是常数,Eq.28具有与点积核(Eq.23)相同的形式。利用上一节的结果
是常数,Eq.28具有与点积核(Eq.23)相同的形式。利用上一节的结果
 (29)
(29)
作为一个特别有用的特殊情况,对于高斯核  ,我们得到
,我们得到
 (30)
(30)
和以前一样,我们可以只在O(n log n)时间内计算完整的内核相关性
6.3 其他核函数
前两部分的方法依赖于单个转换的内核值,比如DFT。这对于其他内核来说并不适用,例如,交集内核。我们仍然可以使用快速训练和检测结果(第5.2和5.3节),但是必须用更昂贵的滑动窗口方法来评估内核相关性。
7 多通道
在这一节中,我们将看到在双重性中工作的优点是,只需在傅里叶域中简单地对它们进行求和,就可以允许多个通道(例如,一个HOG描述符20)。这一特性扩展到线性情况,在特定条件下,简化了最近提出的多通道相关性过滤器。
7.1 通常情况
了处理多个通道,在本节中,我们将假设一个向量x将C通道的单个向量连接起来(例如,一个HOG的梯度方向箱),请注意,第6节中研究的所有内核都是基于点积或参数的规范。一个点积可以通过简单地对每个通道的单独的点积来计算。通过DFT的线性关系,这使得我们可以对傅里叶域中的每个通道的结果求和。作为一个具体的例子,我们可以将这个推理应用到高斯内核中,获得Eq的多通道模拟。
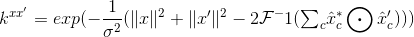 (31)
(31)
值得强调的是,我们只需要在计算内核相关性时对通道进行求和,多通道的集成并不会导致更困难的推理问题.
7.2线性内核
对于一个线性内核 ,上一节的多通道扩展会产生:
,上一节的多通道扩展会产生:
 (32)
(32)
我们把它命名为双相关过滤器(DCF)。这个过滤器是线性的,但是在双空间中训练。我们将很快讨论其他多通道过滤器的优点.
最近将线性相关滤波器扩展到多个通道,由3组独立发现。它们允许比非结构化算法更快的训练时间,通过将问题分解为每个DFT频率的一个线性系统,在脊回归的情况下。亨利科等人另外31人将分解分解为其他训练算法
然而,Eq.32表明,通过在双线性内核中工作,我们可以用多个通道来训练一个线性分类器,但是只使用元素的操作。
我们通过指出这是可能的,因为我们只考虑一个基本的x样本。在这种情况下,不管有多少特性或通道,内核矩阵 都是n x n。它与基本样本的n次循环移位有关,并且可以由DFT的n个基底对角化。因为K是完全对角的,所以我们可以只使用元素的操作。但是,如果我们考虑两个基本样本,K就变成了2n x 2n而n DFT的基础已经不足以完全对角化它了.这种不完全的对角化(块-对角化)需要更昂贵的操作来处理,这是在这些工作中提出的.
都是n x n。它与基本样本的n次循环移位有关,并且可以由DFT的n个基底对角化。因为K是完全对角的,所以我们可以只使用元素的操作。但是,如果我们考虑两个基本样本,K就变成了2n x 2n而n DFT的基础已经不足以完全对角化它了.这种不完全的对角化(块-对角化)需要更昂贵的操作来处理,这是在这些工作中提出的.
有了一个有趣的对称的论点,可以在原始的基础上进行训练,并且只有元素的操作(附录a.6)。在此之后,将相同的推理应用于非中心的协方差矩阵 ,而不是
,而不是 。在这种情况下,我们获得了原始的MOSSE过滤器
。在这种情况下,我们获得了原始的MOSSE过滤器
总之,对于快速元素的操作,我们可以选择多个通道(在双通道中,获得DCF)或多个基本样本(在原始数据中,获得MOSSE),但不能同时进行。这对时间关键的应用程序有重要的影响,比如跟踪。一般情况下31的成本要高得多,而且适用于离线培训应用程序
8 实验部分
8.1 追踪部分
我们在Matlab中实现了两个简单的跟踪器,它基于所建议的kerne化相关过滤器(KCF),使用高斯内核,以及使用线性内核的双相关滤波器(DCF)。我们不会报告一个多项式内核的结果,因为它们实际上与高s-sian内核的结果完全相同,并且需要更多的参数。我们测试了另外两种变体:一种直接作用于原始像素值,另一种则适用于具有4像素大小的猪描述符,特别是Felzenszwalb的变种20、22。请注意,我们的线性DCF在单个通道(原始像素)的极限情况下相当于MOSSE 9,但它也有支持多个通道的优势(例如,HOG)。我们的跟踪器只需要很少的参数,并且我们报告了我们在表2中使用的所有视频的值
KCF的大部分功能在算法1中作为Matlab代码呈现。与此工作29的早期版本不同,它准备处理多个通道,作为输入阵列的第三个维度。它的功能是:train(Eq,17),detect(Eq,22)和kernel_correlation(Eq,31),这是前两个函数所使用的算法。
跟踪器的管道故意简单,不包括任何用于故障检测或mo-建模的启发式。在第一帧中,我们在目标的初始位置上训练一个带有图像补丁的模型。这个补丁比目标大,以提供一些上下文。对于每一个新框架,我们检测到前一个位置的补丁,并且目标位置被更新到产生最大值的那个位置。最后,我们在新位置上训练一个新模型,并线性地将所获得的值和x与上一帧中的值进行插值,以便为跟踪器提供一些内存。

8.2 推理
我们使用一个包含50个视频序列11的基准测试(见图1)来测试我们的跟踪器,这个数据集收集了以前工作中使用的许多视频,因此我们避免了过度拟合的危险。
对于性能标准,我们没有选择平均位置错误或其他在框架上平均的度量,因为它们对依赖于偶然因素的丢失的跟踪器施加了任意的惩罚(例如这条轨道失去的位置),使它们无法与之相比。一个类似的选择是边界框重叠,这有一个缺点,那就是严重地惩罚那些不按比例追踪的追踪器,即使目标位置被完美地跟踪。
我们选择的一个越来越受欢迎的选择,是精确曲线11,5,29。如果预测的目标中心在距离地面真理的距离范围内,那么一个框架就可以被正确地跟踪。Preci-sion曲线仅仅显示了一系列距离阈值的正确跟踪帧的百分比。请注意,通过绘制所有阈值的精度,不需要参数。这使得曲线清晰且易于解释。在低阈值上更高的精度意味着跟踪器更准确,而丢失的目标将阻止它在一个非常大的阈值范围内达到完美的精度。当需要一个具有代表性的精度分数时,所选的阈值是20个像素,就像在以前的工作中所做的那样。

8.3 对全数据集的实验
我们首先总结一下表1和图4中所有视频的结果。为了进行比较,我们还报告了其他几个系统的结果,包括7、4、9、5、14、3,其中包括一些最具弹性的跟踪器,即“Struck”和“TLD”。与我们简单的实现(算法1)不同,这些跟踪器包含了大量的工程改进。Struck对许多不同的特性和越来越多的支持向量进行了操作。TLD专门用于重新检测,使用一组具有许多参数的结构规则。
尽管存在这种不对称性,但我们的kerne化相关性(KCF)可以通过仅靠原始像素来实现竞争性能,如图4所示。在这个设置中,由高斯内核引起的丰富的隐式特性比所提议的双相关过滤器(DCF具有明显的优势。)
我们说,带有单通道特性(原始像素)的DCF在理论上相当于一个MOSSE过滤器。为了进行直接比较,我们将在图4中为作者MOSSE跟踪器9提供结果。两者的性能都非常接近,这表明它们的实现之间的任何特定差异似乎并不重要。然而,我们建议的kerne化算法(KCF)确实能显著提高性能。
用hog代替像素特征允许KCF和DCF超越甚至TLD和袭击,以较大的优势(图4)。这表明,高绩效的最重要因素,相比其他追踪器使用类似的功能,有效整合成千上万的负样本目标环境,它们非常小的开销
Timing:如前所述,我们的封闭形式解决方案的整体复杂性是O(n log n),从而导致其高速(表1)。跟踪器的速度与跟踪区域的大小直接相关。这是比较基于相关过滤器的追踪器的一个重要因素

MOSSE 9跟踪一个与目标对象有相同支持的区域,而我们的实现跟踪一个2.5倍大的区域(平均为116x170)。减少跟踪区域将允许我们接近其615(表1)的FPS,但是我们发现它会损害性能,特别是对于内核变体。表1的另一个有趣的发现是,在每个空间单元中运行31个HOG的特性比在原始像素上操作要快一些,即使我们考虑到计算HOG的特性的开销。因为每个4x4像素的单元格都是由一个HOG描述符来表示的,这个较小的DFTs计数器——平衡了遍历特性通道的成本。利用台式计算机的所有4个核心,kcf/dcf用不到2分钟的时间处理所有50个视频(29000帧)
8.4 序列属性实验
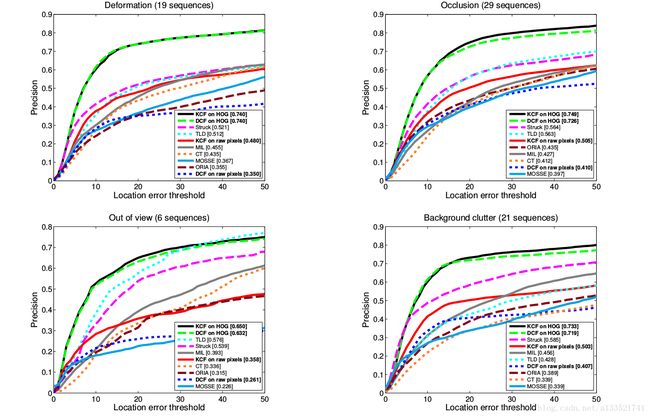
基准数据集11中的视频被注释为属性,描述了跟踪器在每个序列中所面临的挑战,例如,光照变化或-。这些属性对于诊断和在如此大的数据集中对跟踪器的行为进行分析是很有用的,而不需要分析每一个单独的视频。我们报告图5中4个属性的结果:非刚性的变形、遮挡、视图外目标和背景混乱
我们的跟踪器对非刚性hog变形和遮挡的健壮性的健壮性并不令人惊讶,因为这些特征被认为是高度歧视的20。然而,仅在原始像素上的KCF仍然几乎和敲击和TLD一样好,内核弥补了特性的不足。
我们所实施的系统的一个挑战是一个不可见的目标,因为缺乏一个失败的恢复。在这种情况下,TLD比大多数其他追踪器表现得更好,这说明了它对重新检测和故障恢复的关注。这样的工程改进可能会使我们的跟踪器受益,但是kcf/dcf仍然可以比TLD更好的事实表明它们不是决定性的因素。
背景杂乱会严重影响几乎所有的追踪器,除了那些被提议的追踪器,而且在较小程度上也会受到影响。对于我们的跟踪器变体,这可以通过在跟踪对象周围的数千个负样本的隐式来解释。因为在这种情况下,即使是我们的追踪器的原始像素变异体的性能也非常接近于最优,而TLD,CT,ORIA和MIL显示出性能下降,我们推测这是由于它们对底片的采样不足造成的
我们还报告了图7中其他属性的结果。一般来说,建议的追踪器是7个挑战中最强大的6个,除了低分辨率,它同样影响所有的追踪器,除了Struck

9 总结与展望
在这项工作中,我们证明了对自然图像翻译进行分析是可能的,这表明在某些条件下,得到的数据和内核矩阵是-循环的。DFT的对角化提供了一个通用的蓝图,用于创建处理翻译的快速算法。我们已经将这个蓝图应用到线性和内核山脊回归中,获得了最先进的跟踪器,运行在数百FPS下,并且只需几行代码就可以实现。我们的基本方法的扩展似乎在其他问题上很有用。自该工作的第一个版本以来,循环数据已经成功地应用于其他算法,用于检测31和视频事件检索30。进一步工作的一个有趣的方向是放松对周期边界的假设,这可能会提高性能许多有用的算法也可以从研究其他目标函数的循环数据中获得,包括经典的滤波器,如SDF或MACE还有比损失更大的损失函数。我们还希望将这个框架推广到其他操作符,比如仿射转换或非刚性变形
其他:
