Panoptic SegFormer 全景分割
©作者 |白墨
语义分割和实例分割是两个重要且相关的视觉问题。利用它们之间的潜在关系,全景分割将语义分割和实例分割两个任务进行统一,在同一个全景分割模型中,同时处理语义分割和实例分割。
在全景图像分割中,图像内容分为两类:things和stuff。things是可计数的实例目标, 例如,人和车,每个实例都有一个唯一的id来区分; stuff指的是无定形的区域,如天空、草地和雪,没有实例id。
这里讨论的Panoptic SegFormer是一个基于Transformer的端到端全景分割的通用框架,文章最早于2021年9月,作者包括南京大学、香港大学,NVIDIA和加利福尼亚理工学院。
该方法扩展于可变形DETR,统一了things和stuff的mask预测流程,简化了图像分割的流程。
在理解Panoptic SegFormer之前建议读者对DETR,Deformable DETR和Sparse RCNN有所了解,能够理解基于Object query的目标检测范式,有了这基础后Panoptic SegFormer全景分割就好理解了。
01 研究动机
该模型启发于目前流行的端到端的目标检测框架DETR, DETR将目标检测任务建模为基于可学习的查询词汇的字典查找问题,使用具有编码器和解码器的Transformer在无需额外后处理操作,在框架中移除人工设计如NMS和Anchor等部件,极大地简化了传统的目标检测框架。
改进版的可变形DETR,通过可变形的注意力层进一步降低了DETR中的内存和计算成本。
然而使用DETR进行目标分割时,其缺陷包括:DETR在训练阶段需要漫长时间才能收敛;DETR自注意力层的计算复杂度是输入序列长度的平方阶,使用DETR的特征长度受限,而使用fpn方式生成Mask,其边缘区域的精确性较低;DETR采用包围盒相同的方式处理things和stuff,得到的stuff结果不是最优的结果。
由此在DETR的基础上,设计一种简洁有效的端到端全景分割框架。具体来说,作者主要考虑三个关键点:
● 1.采用Query集来统一表示things和stuff,其中stuff类被认为是具有单实例id的特殊的things类型;
● 2.提出利用things的位置信息来提高分割质量的位置解码器;
● 3.提出新的things和stuff分割结果的后处理策略。
02 模型结构
如下图所示,Panoptic SegFormer模型结构包括Transformer编码器,目标的位置解码器与目标的Mask解码器部分三个部分,注意:相对原始的Transformer相比,可理解为1个编码器与2个解码器。

1.Transformer编码器:图像输入到主干网络中,取主干网络的C3,C4和C5层,即特征图分辨率分别为原图的1/8、1/16和1/32的多尺度特征层通过全连接层后拉平成1维作为Transformer的token输入。
经过编码器输出细化的特征token。这里编码器采用了CNN和Transformer相结合的方法。
为什么需要同时使用CNN和Transformer呢?当然它们有各自的优点。
采用Transformer编码器是因为自注意力机制的魔力,通过自注意力机制的得到的特征上更加容易突显出的图像中的目标,特别地对于有遮掩或高重叠的目标基于Transformer的目标检测模型DETR强于CNN目标检测模型。
至于还需要CNN提取特征,因为Transformer模型最初设计时是针对自然语言的,自然语言处理的对象是以词为最小单元组合的序列,序列中的词单元没有尺度这一概念,自然而言,单独的Transformer没处理尺度的能力,这也是为什么单纯的Transformer的在图像处理领域的能力并不比CNN效果好的原因之一。
所以CNN与Transformer结合才是完美的方法。
这是还使用了CNN的C3,C4和C5三个不同尺度的特征,因为目地是分割,即需要高级语义的特征又需要低层的细节信息,像Unet之类的图像分割模型都是采用多层特征融合提升分割效果的。
2.目标的位置解码器:在理解位置解码器之前,有必要对基于Query的目标检测范式有所了解。
基于Query的目标检测最早见于DETR模型,该方法摆脱了之前目标基于固定空间位置的锚框或者锚点,转而依赖于可学习的向量进行目标预测。
那么如何来理解这个Query向量的作用呢?
在Transformer的解码器中,以初使化的N个Query作为输入,N 是检测目标的最大数量,每个Query与Transformer编码器生成特征token做交互,生成新的Query,经过多层之后的,在解码器最顶的Query上添加生成目标位置模块获取检测结果。
而解码器中初使化的Query中含有位置嵌入信息(Position Embedding)。
可以理解为,每个初使的Query含有粗略的目标位置信息,负责对应位置的目标查找,在逐层解码器中Query不断地与编码器形成的特征做交互,逐步在Query中形成了精细位置信息,最终在编码器中最高层的Query上输出目标的位置, 因此Query称之为具有位置感知的Query.
发在Panoptic SegFormer的位置解码器中,也采用类似DETR中解码器的方法,利用初使化的具有位置感知的query和由Transformer编码器生成特征token通过Transformer结构的解码层得到细化的query,然后query通过MLP分支可得到目标位置。
但Panoptic SegFormer的最终不是为了检测目标的位置,而是利用things目标的位置信息辅助things做实例分割,因此该位置解码器是获取最高层具有精细位置信息的Query, 只是在网络训练阶段,通过在精细位置信息的Query上添加MLP分支取得最终目标的位置,是为了利用训练集中things目标的位置标签监督该位置解码器的训练。
在测试推理阶段,MLP分支即可去掉。
3.目标的Mask解码器:采用类似位置解码器的方式, 其输入的Query集中包括目标的位置解码器输出的Query之外,增C个额外的Query,C为stuff的类别数量,用于解码出stuff的Mask。
在这阶段,将things与stuff的分割方式统一起来了,只是用位置解码器输出的Query负责解码出things的Mask,新添加的Query负责解码stuff,将两类Query组合起来以同等的方法输入于Mask解码器。
在Mask解码器中,通过Query与Transformer编码器生成特征token做交互,在最输出的Query上获取最终的分类与分割信息。
为解码器上获取目标的类别,直接在最高层Query上添加FC层进通过分类器解出目标的类别。
在解码上预测目标Mask,更具体点,通过解码器的4层transformer解编码,获取最终的注意力特征图A和精细的Query,其中注意力特征图A是Query Q 和Token产生 key K的乘积(可以具体理解下transformer中Q,K,V的作用)。
如下图所示,
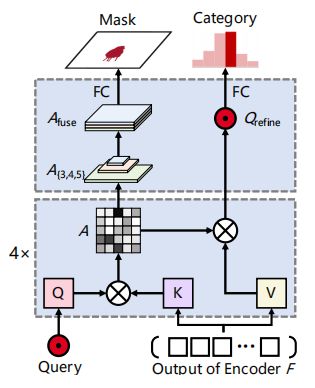
首先将A分离为A3,A4和A5,对应不同尺度特征C3,C4和C5得到,然后将A2进行2倍上采样,A3进行3倍采样后进行拼接成特征图Afuse,公式为:
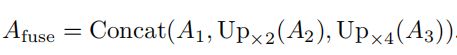
最后在特征图Afuse, 通过1X1的卷积层预测Mask二值图。
在训练过程中,对预测的目标结果采用匈牙利算法进行二部匹配得到与Ground truth目标集合相匹配预测目标顺序,对于没有Ground truth相匹配的预测目标,使用空元素填充。
训练采用的损失函数包含:Lcls : 目标分类损失采用Focal loss; Lseg分割损失采用Dice loss ;Lloc目标位置的损失函数为:
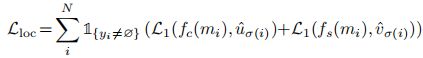
具体解释为:
![]()
:L1 loss;
![]()
:在有序集合第i个目标
![]()
![]()
目标位置编码器预测
的目标中心点和尺寸,
![]()
::Mask对应目标经归一化后
的中心点和尺度;
![]()
:是否匹配到预测目标
03 对比实验与总结
作者使用COCO 2017上的做评估实验,并将其与几种最先进的方法进行了比较。
分别给出了全景分割和实例分割的对比结果:
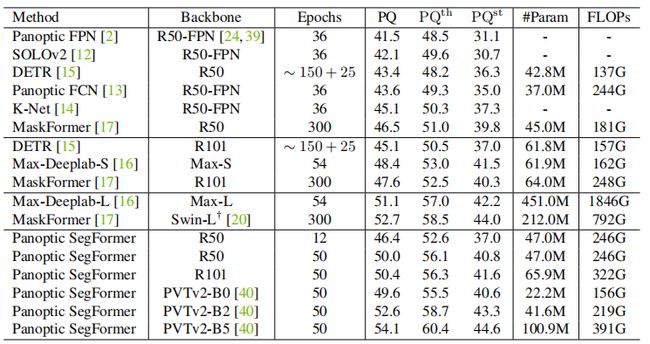
表1:在COCOval数据集上的实验。
以ResNet-50为骨干网络,在COCOval上达到50.0%PQ,超过DETR和PanopticFCN等方法,分别超过6.6%PQ和6.4%PQ。
在12个epoch训练下,也可以达到46.4%的PQ,与训练300epoch的MaskFormer的46.5%的PQ相当。
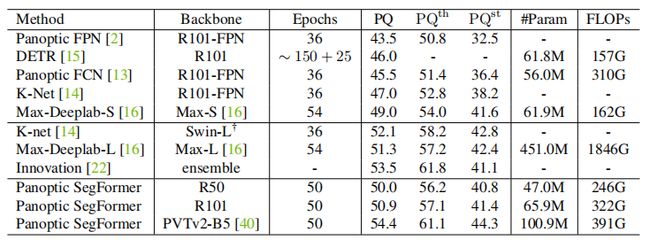
表2:COCOtest-dev测试集的实验。
以PVTv2-B5为骨干网络,在COCOtest-dev上达到54.4%的PQ,超过以往的SOTA方法, 对Max-Deeplab-L和Innovation分别超过3.1%PQ和0.9%PQ,且参数和计算成本更低。
从模型的复杂性和推理效率来看该全景SegFormer,在速度取得了SOTA,这主要依赖于基于Query的目标检测范式,因为它是一种稀疏的目标生成方式,不是基于Anchor之类方法在每个特征点产生过多的稠密矩形框,最终还得用NMS方式去除好多无用的框,而这里Query的数量范围可以是100到300,所处理的目标框较少。
而且提出一种将things与stuff的统一处理方式,简化了全景分割的处理流程。
设计高效的深度学习网络模型有两个主要方向的考虑:是否有效地获取处理目标的丰富特征;简洁有效的目标任务模块。
本文的研究目标是全景分割,需要考虑如何有效的提取的整个图像中的各目标特征以利于分割,以及在特征之上如何实现全景分割这一复杂的作务。
本文在丰富特征方面,起主要作用的是主干网络与Transformer编码器,作者启用的主干网络与一般人员一样,可能不是研究重点,采用CNN多尺度特征与Transformer自注意力机制结合,丰富了特征。
任务处理模块上,由于全景分割任务相对复杂,包括目标检测,实例分割与语义分割。
在其它全景分割文章中我们看到的大多是用复杂的多个分支分别处理,本文只用一个分支,而且无需要人工设计的后处理模块,显得简捷有效。
不过Query初始化上是否可以设计引入更好地具有先验知识的Query,以便更快地查询到目标呢。
原论文
[1] Li Z, Wang W, Xie E, et al. Panoptic SegFormer[J]. arXiv e-prints, 2021: arXiv: 2109.03814.
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。