Huggingface Transformers库学习笔记(一):入门(Get started)
前言
Huggingface的Transformers库是一个很棒的项目,该库提供了用于自然语言理解(NLU)任务(如分析文本的情感)和自然语言生成(NLG)任务(如用新文本完成提示或用另一种语言翻译)的预先训练的模型。其收录了在100多种语言上超过32种预训练模型。这些先进的模型通过这个库可以非常轻松的调取。同时,也可以通过Pytorch和TensorFlow 2.0进行编写修改等。
本系列学习资料来自于该库的官方文档(v4.4.2),链接为Transformers
Huggingface Transformers库学习笔记(一):入门(Get Started)
- 前言
- 入门(Get Started)
-
- 快速开始(Quick tour)
-
- 使用Pipeline快速上手(Getting started on a task with a pipeline)
- 预训练模型的简要剖析(Under the hood: pretrained models)
-
- 使用分词器(Using the tokenizer)
- 使用模型(Using the model)
- 访问代码(Accessing the code)
- 自定义模型(Customizing the model)
- 安装(Installation)
- 开发理念(Philosophy)
-
- 主要概念(Main concepts)
- 术语表(Glossary)
-
- 一般术语(General terms)
- 模型输入(Model inputs)
-
- 输入ID(Input IDs)
- 注意力掩码(Attention mask)
- Token类型ID(Token Type IDs)
- 位置ID(Position IDs)
- 标签(Labels)
- 解码器输入ID(Decoder input IDs)
- 前馈模块(Feed Forward Chunking)
- 学习总结
入门(Get Started)
快速开始(Quick tour)
该库下载了用于自然语言理解(NLU)任务(如分析文本的情感)和自然语言生成(NLG)任务(如用新文本完成提示或用另一种语言翻译)的预先训练的模型。
首先,我们利用管道API来快速使用那些预先训练好的模型。
然后,我们将进一步挖掘,看看这个库是如何访问这些模型并预处理数据。
使用Pipeline快速上手(Getting started on a task with a pipeline)
在给定任务上使用预训练模型的最简单方法是使用pipeline()方法。Transformers对以下任务提供了开箱即用的方法:
- 情感分析:文本是积极的还是消极的?
- 文本生成(英文):提供一个提示,模型将生成以下内容。
- 名称实体识别(NER):在一个输入句子中,用它所代表的实体(人、地点等)标记每个单词。
- 填空文本:给定一个带有填空单词的文本(例如,用[MASK]代替),填空。
- 摘要:生成一篇长文章的摘要。
- 翻译:用另一种语言翻译一篇文章。
- 特征提取:返回文本的张量表示。
对于一个简单的任务,例如对一个句子进行文本情感分类,利用Pipeline可以在几行代码之间完成这项工作:
from transformers import pipeline # 导入pipeline
classifier = pipeline('sentiment-analysis') # 使用文本情感分析任务的分类器
classifier('We are very happy to show you the Transformers library.') # 进行文本情感分类
输出如下:
[{'label': 'POSITIVE', 'score': 0.9997795224189758}]
可以看到,分类器很快给出了判别结果和得分。当然,也可以使用一个句子列表作为输入,来作为一个batch形式输入到模型中。
results = classifier(["We are very happy to show you the Transformers library.",
"We hope you don't hate it."])
for result in results:
print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
输出如下:
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
默认情况下,为该pipeline方法下载的模型称为“distilbert-base-uncased-finetuned-sst-2-english”。它使用蒸馏器架构,并在一个名为SST-2的数据集上进行了微调,用于情感分析任务。详细信息参考:https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english
假设我们想使用另一个模型; 比如,一个接受过法语数据训练的文本情感分类模型。那么可以在模型中心搜索,链接为:model hub。然后限定左边的标签栏中选定fr和text classification标签,就可以看到符合任务需求的模型展示,
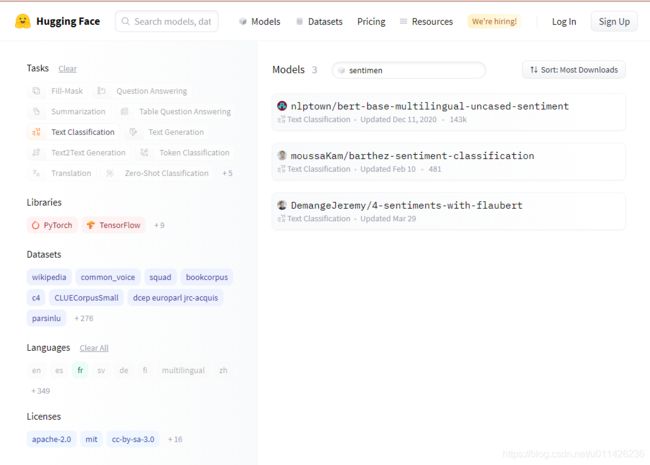
这里可以看到第一个模型的下载量是143k,可以使用这个模型来做法语的文本情感分析。在使用时,可以直接在pipeline方法中指定model为“nlptown/bert-base-multilingual-uncased-sentiment”。
classifier = pipeline('sentiment-analysis', model="nlptown/bert-base-multilingual-uncased-sentiment")
这个分类器现在可以处理文本在英语,法语,也可以处理荷兰语,德语,意大利语和西班牙语! 我们还可以用一个保存了预训练模型的本地文件路径替换该名称。
我们还可以传递一个模型对象及其相关的分词器(Tokenizer)。为此我们需要两个类。
- 第一个是AutoTokenizer,我们将使用它来下载与我们选择的模型相关联的分词器并实例化它。
- 第二个是AutoModelForSequenceClassification,我们将使用它来下载模型本身。
首先我们导入这两个类
from transformers import AutoTokenizer, AutoModelForSequenceClassification
现在,要下载我们前面找到的模型和标记器,我们只需要使用from_pretrained()方法(可以随意用model hub中的任何其他模型替换model_name)
model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
classifier = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
预训练模型的简要剖析(Under the hood: pretrained models)
现在让我们看看在使用这些管道时,在引擎盖下面会发生什么。
正如我们所看到的,模型和标记器是使用from_pretrained方法创建的。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
使用分词器(Using the tokenizer)
分词器负责文本的预处理。
首先,它将以单词(或部分单词、标点符号等)分割给定的文本,通常称为token。有多种规则可以管理这个过程,因此需要使用模型的名称来实例化分词器,以确保使用与模型预先训练时相同的规则。
第二步是将这些token转换为数字,以便能够利用它们构建一个张量并将它们提供给模型。因而,分词器有一个词汇表,在使用from_pretrained方法实例化它时,程序将自动下载。要确保使用与模型预训练时相同的词汇表。
要在给定文本上应用这些步骤,只需将文本提供给分词器。
inputs = tokenizer("We are very happy to show you the Transformers library.")
print(inputs)
得到输出
{'input_ids': [101, 2057, 2024, 2200, 3407, 2000, 2265, 2017, 1996, 100, 19081, 3075, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
可以直接将句子列表传递给标记器。
如果我们的目标是将它们作为批处理发送到模型中,那么首先将它们填充到相同的长度,之后将它们截断到模型可以接受的最大长度,然后返回张量。
pt_batch = tokenizer(
["We are very happy to show you the Transformers library.", "We hope you don't hate it."],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
)
填充将自动应用到模型长度不够的那些句子上(如例子中的第二句,“We hope you don’t hate it.”),并使用模型预训练的填充token。
attention mask也适用。
for key, value in pt_batch.items():
print(f"{key}: {value.numpy().tolist()}")
输出如下:
input_ids: [[101, 2057, 2024, 2200, 3407, 2000, 2265, 2017, 1996, 100, 19081, 3075, 1012, 102], [101, 2057, 3246, 2017, 2123, 1005, 1056, 5223, 2009, 1012, 102, 0, 0, 0]]
attention_mask: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]
使用模型(Using the model)
输入被分词器预处理后,就可以直接发送到模型。对于PyTorch模型,需要通过添加**解包字典方式实现参数传递。关于**方式解包参数,请参考Python函数参数中的*与**运算符
pt_outputs = pt_model(**pt_batch)
print(pt_outputs)
print(pt_outputs[0])
输出为
SequenceClassifierOutput(loss=None, logits=tensor([[-4.0833, 4.3364],
[ 0.0818, -0.0418]], grad_fn=), hidden_states=None, attentions=None)
tensor([[-4.0833, 4.3364],
[ 0.0818, -0.0418]], grad_fn=)
输出时是一个SequenceClassifierOutput对象,其中logoits属性即经过最后分类(如果config.num_labels==1,则回归)分数(在SoftMax之前)。
之后,可以使用Softmax激活来获取最终的预测结果。
import torch.nn.functional as F
pt_predictions = F.softmax(pt_outputs[0], dim=-1)
print(pt_predictions)
得到输出为:
tensor([[2.2043e-04, 9.9978e-01],
[5.3086e-01, 4.6914e-01]], grad_fn=)
预训练模型本身都是torch.nn.Module或tensorflow.keras.Model类型的, 因此可以在PyTorch或TensorFlow的框架下进行训练。
可以将标签提供给模型,它将返回一个包含loss和最终激活的元组。
import torch
pt_outputs = pt_model(**pt_batch, labels = torch.tensor([1, 0]))
print(pt_outputs[0])
得到输出为:
SequenceClassifierOutput(loss=None, logits=tensor([[-4.0833, 4.3364],
[ 0.0818, -0.0418]], grad_fn=), hidden_states=(tensor([[[ 0.3549, -0.1386, -0.2253, ..., 0.1536, 0.0748, 0.1310],
[-0.5773, 0.6791, -0.9738, ..., 0.8805, 1.1044, -0.7628],
[-0.3451, -0.2094, 0.5709, ..., 0.3208, 0.0853, 0.4575],
...,
[ 0.4431, 0.0931, -0.1034, ..., -0.7737, 0.0813, 0.0728],
[-0.5605, 0.1081, 0.1229, ..., 0.4519, 0.2104, 0.2970],
[-0.6116, 0.0156, -0.0555, ..., -0.1736, 0.1933, -0.0021]],
[[ 0.3549, -0.1386, -0.2253, ..., 0.1536, 0.0748, 0.1310],
[-0.5773, 0.6791, -0.9738, ..., 0.8805, 1.1044, -0.7628],
[-0.7195, -0.0363, -0.6576, ..., 0.4434, 0.3358, -0.9249],
...,
[ 0.0073, -0.5248, 0.0049, ..., 0.2801, -0.2253, 0.1293],
[-0.0790, -0.5581, 0.2347, ..., 0.2370, -0.5104, 0.0770],
[-0.0958, -0.5744, 0.2631, ..., 0.2453, -0.3293, 0.1269]]],
grad_fn=), tensor([[[ 5.0274e-02, 1.2093e-02, -1.1208e-01, ..., 6.2100e-02,
1.9892e-02, 3.6863e-02],
……
# 中间结果太多,省略
……
[[3.4474e-02, 3.1367e-02, 2.3187e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[3.5311e-02, 3.3985e-02, 5.4093e-02, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[1.0943e-02, 3.1733e-03, 2.9226e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[9.0263e-03, 3.5084e-03, 2.9081e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[1.5904e-02, 8.0937e-03, 2.1290e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[1.3486e-02, 6.0674e-03, 2.1980e-01, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]]]], grad_fn=)))
可以看到各种隐藏层的状态也都在这个对象中包含。
Note: 这里给不给标签都有输出的各个类别的概率,我觉得给了标签就相当于是训练所以可以得到loss,而不给标签相当于测试,所以没有loss。
一旦模型经过了微调,就可以按照以下方式与分词器一同保存。
tokenizer.save_pretrained(save_directory)
model.save_pretrained(save_directory)
然后,可以使用from_pretrained()方法通过传递目录名而不是模型名来加载这个模型。
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(save_directory)
model = AutoModel.from_pretrained(save_directory)
最后,如果需要,也可以要求模型返回所有隐藏状态和所有注意权重。
pt_outputs = pt_model(**pt_batch, output_hidden_states=True, output_attentions=True)
all_hidden_states, all_attentions = pt_outputs[-2:]
访问代码(Accessing the code)
AutoModel和AutoTokenizer类只是快捷方式,可以自动地与任何预先训练过的模型一起工作。
在幕后,每个体系结构加类的组合都有一个库模型类,所以如果需要,代码很容易访问和调整。
在我们前面的例子中,“distilbert-base-uncased-finetuned-sst-2-english”模型使用DistilBERT架构。
当使用 AutoModelForSequenceClassification时,自动创建的模型是 DistilBertForSequenceClassification。
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
model = DistilBertForSequenceClassification.from_pretrained(model_name)
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
自定义模型(Customizing the model)
如果想要改变模型本身的构建方式,可以定义自定义配置类。
每个架构都有自己的相关配置(例如在DistilBERT模型中, 可以配置DistilBertConfig这个类),它允许设置隐藏层的维度、dropout概率等。
如果做核心修改,比如改变隐藏的大小,将不能再使用一个预先训练的模型,需要从头开始训练。然后,可以直接从这个配置实例化模型。
这里我们使用了DistilBERT的预定义词汇表(因此用from_pretrained()方法加载分词器))并从头初始化模型(因此从配置中实例化模型,而不是使用from_pretrained()方法)。
from transformers import DistilBertConfig, DistilBertTokenizer, DistilBertForSequenceClassification
config = DistilBertConfig(n_heads=8, dim=512, hidden_dim=4*512)
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertForSequenceClassification(config)
对于只更改模型头部的东西(例如,标签的数量),仍然可以为主体使用一个预先训练过的模型。
例如,我们使用一个预先训练的body为10个不同的标签定义一个分类器。可以用所有默认值创建一个配置,只更改标签的数量,但更简单的是,直接将配置需要的任何参数传递给from_pretrained()方法,它将用它更新默认配置。
from transformers import DistilBertConfig, DistilBertTokenizer, DistilBertForSequenceClassification
model_name = "distilbert-base-uncased"
model = DistilBertForSequenceClassification.from_pretrained(model_name, num_labels=10)
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
安装(Installation)
安装部分比较简单,首先需要配置pytorch或TensorFlow 2.0环境。可以根据TensorFlow installation page,PyTorch installation page ,上的提示进行下载安装。
之后直接
pip install transformers
即可
开发理念(Philosophy)
Transformers是一个固执己见的(opinionated)库,它被开发为了以下人群:
- 那些寻求使用/研究/扩展大型Transformer模型的NLP研究人员和教育者
- 想要微调这些模型和/或在生产中为它们服务的实践者
- 只想下载一个预先训练过的模型并使用它来解决给定的自然语言处理任务的工程师。
该库的设计目标有两个:
-
尽可能的简单和能够快速使用
- 该库强烈地限制了要学习的面向用户的抽象的数量,事实上,几乎没有抽象,每个模型只需要三个标准类: configuration, models 和tokenizer.。
- 所有这些类可以被用一种简单和统一的方式初始化:通过使用一个共同from_pretrained()实例化方法。该方法将负责从Hugging Face Hub提供或你自己保存的pretrained checkpoint进行下载(如果需要)、缓存和加载相关的类实例和相关数据(配置hyper-parameters、分词器词汇和模型权重)
- 在这三个基类之上,库提供了两个api: pipeline()用于在给定任务上快速使用模型(及其相关的标记器和配置),Trainer()/TFTrainer()用于快速训练或调优给定模型。
- 因此,这个库不是神经网络构建模块的模块化工具箱。如果你想扩展/构建这个库,只需要使用常规的Python/PyTorch/TensorFlow/Keras模块,并从库的基类继承来重用模型加载/保存等功能。
-
提供最先进的模型,使其性能尽可能接近原始模型
- 我们为每个体系结构提供至少一个例子,它重现了该体系结构的官方作者提供的结果。
- 代码通常尽可能接近原始代码基础,这意味着一些PyTorch代码可能由于被转换为TensorFlow代码而不像它可能的那样pytorchic,反之亦然。
其他几个目标:
- 尽可能一致地公开模型内部:
- 我们使用一个API来访问完整的隐藏状态和注意力权重。
- 标记器和基本模型的API都经过了标准化,可以方便地在模型之间切换。
- 结合对这些模型进行微调/研究的有希望的工具的主观选择:
- 一种简单/一致的方式向词汇表和用于微调的嵌入添加新标记。
- 简单的方法来屏蔽和修剪变压器头。
- 在PyTorch和TensorFlow 2.0之间轻松切换,允许使用一个框架进行训练,使用另一个框架进行推理。
主要概念(Main concepts)
这个库围绕每个模型的三种类型的类构建:
- Model classes,比如BertModel,它是30多个PyTorch模型(torch.nn.Module)或Keras模型(tf.keras.Model),使用库中提供的预先训练的权重。
- Configuration classes,比如BertConfig,它存储了构建模型所需的所有参数。你并不总是需要自己实例化这些。特别地,如果您使用一个未经任何修改的预先训练的模型,创建模型将自动地处理配置的实例化(它是模型的一部分)。
- Tokenizer classes,比如BertTokenizer,它存储每个模型的词汇表,并提供对输入到模型的token嵌入索引列表中的字符串进行编码/解码的方法。
所有这些类都可以从预先训练的实例中实例化,并使用两种方法在本地保存。
- from_pretrained() 让您从库本身提供的(受支持的模型在这里的列表中提供)或用户本地存储(或服务器上)的预训练版本中实例化模型/配置/标记器
- save_pretrained() 允许你在本地保存模型/配置/标记器,以便可以使用from_pretrained()重新加载它。
术语表(Glossary)
一般术语(General terms)
-
autoencoding models: 自编码器模型。参考 MLM
-
autoregressive models: 自回归模型。参考 CLM
-
CLM: 因果语言模型。因果语言模型是一种训练前的任务,模型按顺序阅读文本,并预测下一个单词。
这通常是通过阅读整个句子来完成的,但是在模型中使用一个掩码来隐藏将来某个时间步长的标记。
causal language modeling, a pretraining task where the model reads the texts in order and has to predict the next word. It’s usually done by reading the whole sentence but using a mask inside the model to hide the future tokens at a certain timestep. -
deep learning: 深度学习。使用多层神经网络的机器学习算法。
machine learning algorithms which uses neural networks with several layers. -
MLM: 遮罩语言模型。这是一种预训练任务,让模型看到文本的损坏版本,通常通过随机屏蔽一些token来完成,并且必须预测原始文本。
masked language modeling, a pretraining task where the model sees a corrupted version of the texts, usually done by masking some tokens randomly, and has to predict the original text. -
multimodal: 多模态。将文本与另一种输入(例如图像)组合在一起的任务。
a task that combines texts with another kind of inputs (for instance images). -
NLG: 自然语言生成。所有与生成文本相关的任务(例如与Transformers对话、翻译)。
natural language generation, all tasks related to generating text (for instance talk with transformers, translation). -
NLP: 自然语言处理。一种处理文本的通用方式。
natural language processing, a generic way to say “deal with texts”. -
NLU: 自然语言理解。所有与理解文本内容相关的任务(例如对整个文本和单个单词进行分类)。
natural language understanding, all tasks related to understanding what is in a text (for instance classifying the whole text, individual words). -
pretrained model: 预训练模型。在某些数据(例如Wikipedia的所有数据)上预先训练过的模型。预训练方法包括一个自我监督的目标,它可以是阅读文本并尝试预测下一个单词(参见CLM),或者屏蔽一些单词并尝试预测它们(参见MLM)。
a model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods involve a self-supervised objective, which can be reading the text and trying to predict the next word (see CLM) or masking some words and trying to predict them (see MLM). -
RNN: 循环神经网络。一种在层上使用循环来处理文本的模型。
recurrent neural network, a type of model that uses a loop over a layer to process texts. -
self-attention: 自注意力。输入的每个元素都找出它们应该“注意”的其他输入元素。
each element of the input finds out which other elements of the input they should attend to. -
seq2seq or sequence-to-sequence: 序列到序列(模型)。从输入中生成新序列的模型,如翻译模型或总结模型(如Bart或T5)。models that generate a new sequence from an input, like translation models, or summarization models (such as Bart or T5).
-
token: 一个句子的一部分,通常是一个词,但也可以是一个子词(非常用词常被拆分在子词中)或标点符号。
a part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a punctuation symbol. -
transformer: 基于自我注意的深度学习模型体系结构。
self-attention based deep learning model architecture.
模型输入(Model inputs)
每一种模型都是不同的,但也有相似之处。因此,大多数模型使用相同的输入,这里将详细介绍使用示例。
输入ID(Input IDs)
输入id通常是作为输入传递给模型的唯一必需参数。
它们是token的索引,是构建序列的token的数字表示,这些序列将被模型用作输入。分词器负责将序列拆分为分词器词汇表中可用的token。
每个分词器的工作方式不同,但底层机制是相同的。下面是一个使用BERT分词器的例子,这是一个Word-piece 分词器。
分词器负责将序列拆分为分词器词汇表中可用的标记。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
sequence = "A Titan RTX has 24GB of VRAM"
tokenized_sequence = tokenizer.tokenize(sequence)
print(tokenized_sequence)
得到输出为
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
可以看到,标记可以是单词,也可以是子单词。例如,在这里,VRAM不在模型词汇表中,所以它被分为V、RA和M。为了表明这些标记不是单独的单词,而是同一个单词的一部分,为RA和M添加了一个双哈希前缀(即#)
然后可以将这些token转换为模型可以理解的id。
这可以通过直接将句子提供给分词器来实现,该分词器利用huggingface/tokenizers的Rust实现峰值性能。
标记器返回一个字典,其中包含其对应模型正常工作所需的所有参数。
token的索引位于键input_ids之下。
inputs = tokenizer(sequence)
encoded_sequence = inputs["input_ids"]
print(encoded_sequence)
得到输出
[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
注意,标记器会自动添加特殊的标记(如果关联的模型依赖它们的话),这些标记是模型有时使用的特殊id。
如果我们对之前序列的id进行解码输出,可以看到
decoded_sequence = tokenizer.decode(encoded_sequence)
print(decoded_sequence)
输出为
[CLS] A Titan RTX has 24GB of VRAM [SEP]
这个就是BERT模型所希望的输入格式。
注意力掩码(Attention mask)
Attention mask是一个可选参数,当将序列批处理在一起时使用。这个参数指示模型应该关注哪些token,哪些不应该关注。
例如,考虑这两个序列
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
sequence_a = "This is a short sequence."
sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
两个序列编码后的长度并不一致。
len(encoded_sequence_a), len(encoded_sequence_b)
输出
(8, 19)
因此,我们不能把它们放在同一个张量中。除非第一个序列需要填充到第二个序列的长度,或者第二个序列需要截断到第一个序列的长度。在第一种情况下,id列表将由填充(Padding)索引扩展。我们可以传递一个列表给分词器,并要求它像这样填充。
padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
padded_sequences["input_ids"]
输出
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
我们可以看到,在第一个句子的右边添加了0,使它与第二个句子的长度相同,然后可以将其转换为PyTorch或TensorFlow中的张量。
注意attention mask是一个二值张量,表示填充指标的位置,这样模型就不会注意到它们。
对于BertTokenizer, 1表示应该处理的值,而0表示填充的值。这个attention mask位于标记器返回的键attention_mask下的字典中。
padded_sequences["attention_mask"]
输出
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
Token类型ID(Token Type IDs)
有些模型的目的是进行序列分类或回答问题。这需要将两个不同的序列连接到单个input_ids条目中,这通常需要特殊标记的帮助,例如分类器([CLS])和分隔符([SEP])。
例如,BERT模型这样构建它的两个序列输入
# [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
我们可以像这样使用分词器自动生成这样的句子,方法是将这两个序列作为两个参数(而不是像前面那样的列表)传递给分词器。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
sequence_a = "HuggingFace is based in NYC"
sequence_b = "Where is HuggingFace based?"
encoded_dict = tokenizer(sequence_a, sequence_b)
decoded = tokenizer.decode(encoded_dict["input_ids"])
我们打印输出一下解码后的句子
print(decoded)
输出为
[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
对于一些模型来说,这足以理解一个序列在哪里结束,另一个序列在哪里开始。然而,其他模型,如BERT,也部署Token type id(也称为segment id)。它们被表示为一个二进制mask,标识模型中的两种序列类型。
分词器将此mask作为token_type_ids条目返回。
encoded_dict['token_type_ids']
输出为
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
第一个序列是用于问题的上下文,它的所有标记都用0表示,而第二个序列对应于问题,它的所有标记都用1表示。
有些模型,如XLNetModel,使用了一个额外的token,由2表示。
位置ID(Position IDs)
与将每个token的位置嵌入其中的RNN相反,transformer不知道每个令牌的位置。因此,模型使用位置id (position_ids)来标识每个标记在标记列表中的位置。
它们是一个可选参数。如果没有将position_ids传递给模型,则IDs将自动创建为绝对位置嵌入。
绝对位置嵌入在范围[0,config.max_position_embeddings - 1)。一些模型使用其他类型的位置嵌入,如正弦位置嵌入或相对位置嵌入。
标签(Labels)
标签是一个可选参数,它可以被传递给模型来计算自己的损失。
这些标签应该是模型的预期预测:它将使用标准损失来计算预测和期望值(标签)之间的损失。
例如,这些标签根据模型头的类型而不同。
- 对于序列分类模型(例如, BertForSequenceClassification),模型期望一个维度张量为(batch_size),其中每个batch的值都对应于整个序列的期望标签。
- 对于token分类模型(例如,BertForTokenClassification),模型需要一个维度张量为(batch_size, seq_length),其中的每个值都对应于每个单个token的期望标签。
- 对于遮罩语言模型(例如,BertForMaskedLM),模型需要一个维度张量(batch_size, seq_length),其中的每个值都对应于每个单个token的预期标签:标签是mask token的token ID,其余的值将被忽略(通常为-100)。
- 对于seq2seq任务,(例如。 BartForConditionalGeneration, MBartForConditionalGeneration,模型期望一个维度张量(batch_size, tgt_seq_length),每个值对应于与每个输入序列相关联的目标序列。在训练期间,BART和T5都将在内部制作适当的decoder_input_ids和 decoder attention masks。它们通常不需要供应。这不适用于利用编码器-解码器框架的模型。
基本模型(例如,BertModel)不接受标签,因为这些是基本transformer模型,只是输出特性。
解码器输入ID(Decoder input IDs)
这个输入是特定于编码器-解码器模型的,并且包含将被输入到解码器的输入id。这些输入应该用于序列到序列任务,例如翻译或摘要,并且通常以特定于每个模型的方式构建。
大多数编码器-解码器模型(BART, T5)自己从标签中创建decoder_input_id。在这些模型中,传递标签是处理训练过程的首选方式。
前馈模块(Feed Forward Chunking)
在Transformer的每个残差块中,自我注意层通常后面跟着2个前馈层。前馈层的中间嵌入尺寸通常大于模型的隐藏尺寸(例如,bert-base-uncased)。
对于input size为 [batch_size, sequence_length] 的输入,存储中间前馈嵌入所需的内存 [batch_size, sequence_length, config.intermediate_size] 可以占内存使用的很大一部分。Reformer: The Efficient Transformer的作者注意到,由于计算是独立于sequence_length维度的,它在数学上等价于计算两个前馈层的输出嵌入 _[batch_size, config.hidden_size]_0, …, [batch_size, config.hidden_size]n 配置。然后将它们连接到 [batch_size, sequence_length, config.hidden_size] 中。其中n = sequence_length,这会增加计算时间,减少内存使用,但会产生数学上等价的结果。
对于使用apply_chunking_to_forward()函数的模型,chunk_size定义了并行计算的输出嵌入的数量,从而定义了内存和时间复杂性之间的权衡。如果chunk_size设置为0,则不进行前馈分块。