深度学习arm cache系列--一篇就够了
引流关键词:缓存,高速缓存,cache, CCI,CMN,CCI-550,CCI-500,DSU,SCU,L1,L2,L3,system cache, Non-cacheable,Cacheable, non-shareable,inner-shareable,outer-shareable, optee、ATF、TF-A、Trustzone、optee3.14、MMU、VMSA、cache、TLB、arm、armv8、armv9、TEE、安全、内存管理、页表…
快速链接:
.
个人博客笔记导读目录(全部)
- ARMv8/ARMv9架构精选系列–目录
- ARMV8/ARMV9/Trustzone/TEE安全课程
目录
-
-
- 1. cache的基本概念介绍
-
- 1.1、为什么要用cache?
- 1.2、为什么要学习cache呢?
-
- 1.2.1、软件中维护内存一致性 – invalid cache
- 1.2.2、软件中维护内存一致性 – flush cache
- 1.3、怎么去刷cache呢?
-
- 1.3.1、cache一致性指令介绍
- 1.3.2、cache一致性指令的使用示例
- 1.3.3、 操作系统中软件维护cache一致性的API
- 1.4、总结
- 2. cache的基本概念原理扫盲
-
- 2.1、cache是多级相连的
- 2.2、cache一般是和MMU结合在一起使用的
- 2.3、`bit-LITTLE`架构 和 `DynamIQ`架构 的cache是有区别的
-
- 2.3.1 `bit-LITTLE`架构的cache
- 2.3.2 `DynamIQ`架构架构的cache
- 2.4、L1/L2/L3 cache的大小
- 2.5、cache的组织形式(index, way, set)
- 2.6、cache的种类(VIVT,PIPT,VIPT)
- 2.7、cache的分配策略(alocation,write-through, write-back)
- 2.8、架构中定义的cache的范围(inner, outer)
- 2.9、架构中内存的类型
- 3. cache的查询原理
-
- 3.1. cache的查询原理
- 3.2. cache的查询示例
- 4. 多核多cluster多系统之间缓存一致性概述
-
- 4.1. 质疑
- 4.2. 怎样去维护多核多系统缓存的一致性
- 4.3. bit.LITTLE架构 和 DynamIQ架构 的系统中的缓存一致性
- 4.4. MESI、MOESI 的介绍
- 4.5. 总结
- 5. 多级cache之间的替换策略
-
- 5.1、DynamIQ架构中L1 cache的替换策略(以cortex-A710为例)
- 5.2、core cache的替换策略(以cortex-A710为例)
-
- 5.2.1、L1 data cache 遵从MESI协议
- 5.2.2、L1 instruction cache 没有遵从MESI协议
- 5.2.3、MESI协议的介绍
- 5.3、cluster cache 之间的替换策略
- 5.4、总结
- 5.5 参考
- 6. A53 cache的架构解读
-
- 6.1. A53使用经典的 `bit-LITTLE`架构
- 6.2. A53的cache配置
- 6.3. cache的层级结构:
- 6.4. L2 memory System系统介绍
- 6.5. 多cluster之间的缓存一致性
- 6.6. CCI的介绍(以CCI-550为例)
- 6.7. 经典示例框图
-
1. cache的基本概念介绍
1.1、为什么要用cache?
ARM 架构刚开始开发时,处理器的时钟速度和内存的访问速度大致相似。今天的处理器内核要复杂得多,并且时钟频率可以快几个数量级。然而,外部总线和存储设备的频率并没有达到同样的程度。可以实现可以与内核以相同速度运行的小片上 SRAM块,但与标准 DRAM 块相比,这种 RAM 非常昂贵,标准 DRAM 块的容量可能高出数千倍。在许多基于 ARM 处理器的系统中,访问外部存储器需要数十甚至数百个内核周期。
高速缓存是位于核心和主内存之间的小而快速的内存块。它在主内存中保存项目的副本。对高速缓冲存储器的访问比对主存储器的访问快得多。每当内核读取或写入特定地址时,它首先会在缓存中查找。如果它在高速缓存中找到地址,它就使用高速缓存中的数据,而不是执行对主存储器的访问。通过减少缓慢的外部存储器访问时间的影响,这显着提高了系统的潜在性能。通过避免驱动外部信号的需要,它还降低了系统的功耗

1.2、为什么要学习cache呢?
cache和我们软件工程师有啥关系?其实在很多时候,都没有太大的关系,在很多时候也无需去理解cache的原理。但事实就是事实,不管你理解还是不理解,你都是一直在用的。做为一名底层的软件开发者,在有些时候,你不得不去主动刷新cache,即软件中维护内存一致性 。
那么一般什么时候需要主动刷cache呢(软件中维护内存一致性) ? 基本就是当有不同的Master来访问相同的内存的时候。如下便是几个小示例。
1.2.1、软件中维护内存一致性 – invalid cache

1.2.2、软件中维护内存一致性 – flush cache

1.3、怎么去刷cache呢?
ARM提供了操作cache的指令, 软件维护操作cache的指令有三类:
- Invalidation:其实就是修改valid bit,让cache无效,主要用于读
- Cleaning: 其实就是我们所说的flush cache,这里会将cache数据回写到内存,并清楚dirty标志
- Zero:将cache中的数据清0, 这里其实是我们所说的clean cache.
什么时候需要软件维护cache:
(1)、当有其它的Master改变的external memory,如DMA操作
(2)、MMU的enable或disable的整个区间的内存访问,如REE enable了mmu,TEE disable了mmu.
针对第(2)点,cache怎么和mmu扯上关系了呢?那是因为:
mmu的开启和关闭,影响了内存的permissions, cache policies
1.3.1、cache一致性指令介绍
因为本节为第一篇,也就是基本的概念介绍。我们很多深入的原理还不明白。所以就不对以下指令做深入的解读。你只需理解有这么多指令可用于“软件维护cache的一致性”就好。后续当深入理解了cache的各种策略原理后,再回过头来看这些指令,相信会有较大的收获。

以下是对维护cache的一致性指令做出的一个总结

1.3.2、cache一致性指令的使用示例

1.3.3、 操作系统中软件维护cache一致性的API
在操作系统中,我们只需要调用相关的API即可,也无需牢记以上的维护cache一致性的命令。
比如在Linux Kernel 操作Cache的API如下所示:
linux/arch/arm64/mm/cache.S
linux/arch/arm64/include/asm/cacheflush.h
void __flush_icache_range(unsigned long start, unsigned long end);
int invalidate_icache_range(unsigned long start, unsigned long end);
void __flush_dcache_area(void *addr, size_t len);
void __inval_dcache_area(void *addr, size_t len);
void __clean_dcache_area_poc(void *addr, size_t len);
void __clean_dcache_area_pop(void *addr, size_t len);
void __clean_dcache_area_pou(void *addr, size_t len);
long __flush_cache_user_range(unsigned long start, unsigned long end);
void sync_icache_aliases(void *kaddr, unsigned long len);
void flush_icache_range(unsigned long start, unsigned long end)
void __flush_icache_all(void)
1.4、总结
小小总结一下,当有其它硬件(如DMA)和CPU访问同一块内存时,那么这个时候的操作需要小心,一般也就是记得调用invalid cache和flush cache相关的函数即可
2. cache的基本概念原理扫盲
2.1、cache是多级相连的
cache是多级的,在一个系统中你可能会看到L1、L2、L3, 当然越靠近core就越小,也是越昂贵。
一般来说,对于bit.LITTLE架构中,在L1是core中,L1又分为L1 data cache和 L1 Instruction cache, L2 cache在cluster中,L3则在BUS总线上。
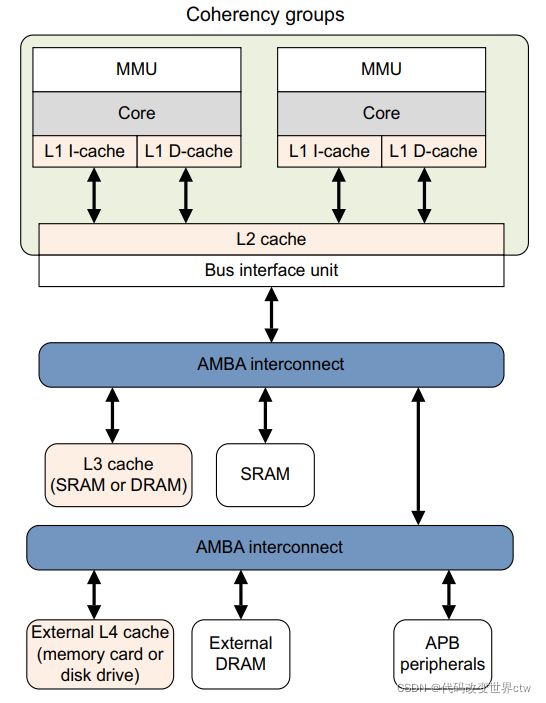
2.2、cache一般是和MMU结合在一起使用的
很多时候cache都是和MMU一起使用的(即同时开启或同时关闭),因为MMU页表的entry的属性中控制着内存权限和cache缓存策略等
在ARM架构中,L1 cache都是VIPT的,也就是当有一个虚拟地址送进来,MMU在开始进行地址翻译的时候,Virtual Index就可以去L1 cache中查询了,MMU查询和L1 cache的index查询是同时进行的。如果L1 Miss了,则再去查询L2,L2还找不到则再去查询L3。 注意在arm架构中,仅仅L1是VIPT,L2和L3都是PIPT。

2.3、bit-LITTLE架构 和 DynamIQ架构 的cache是有区别的
2.3.1 bit-LITTLE架构的cache
以下是一张比较早期的经典的bit-LITTLE的架构图
在bit-LITTLE的架构中,L1是在core中的,是core私有的;L2是在cluster中的,对cluster中的core是共享的;L3则对所有cluster共享。bit-LITTLE的架构的一个cache层级关系图如下所示:
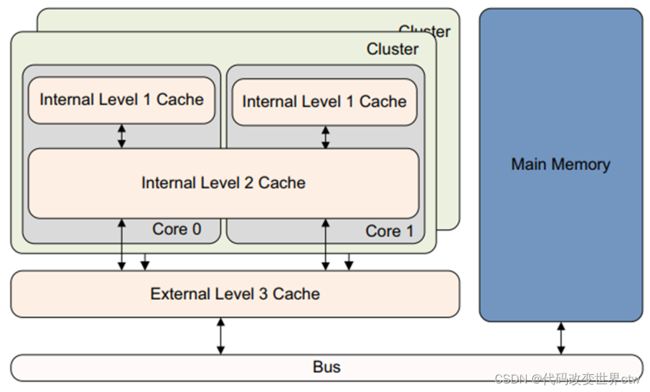
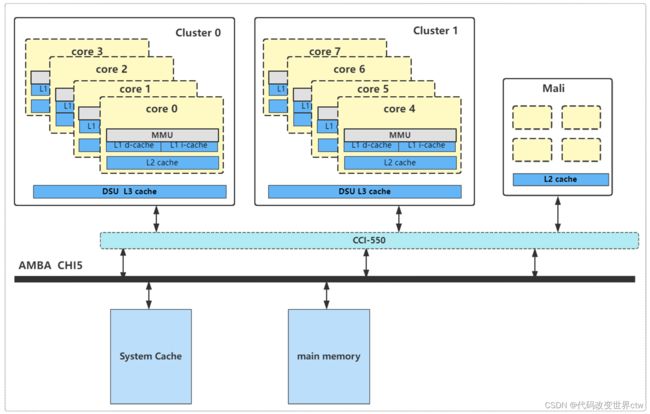
2.3.2 DynamIQ架构架构的cache
随着时代的发展科技的进步,除了了DynamIQ架构后,整个系统的system memory架构也在悄然无息的发生了变化。刚开始的架构如下所示:L1/L2在core中,L3在DSU中,DSU对外是ACE接口,结合CCI 来维护多cluster之间的缓存一致性。

但是在后来,随着CHI的越来越成熟,又变成了:L1/L2在core中,L3在DSU中,DSU对外是CHI接口,结合CMN来维护多cluster之间的缓存一致性。

但是不管怎么说,在dynamIQ的架构中,L1和L2都在core中的,都是core私有的;L3则是在cluster中的,对cluster中的core是共享的;如有L3或system cache,则是所有cluster共享。dynamIQ的架构的一个cache层级关系图如下所示:
2.4、L1/L2/L3 cache的大小
可以参考ARM文档,其实每一个core的cache大小都是固定的或可配置的。

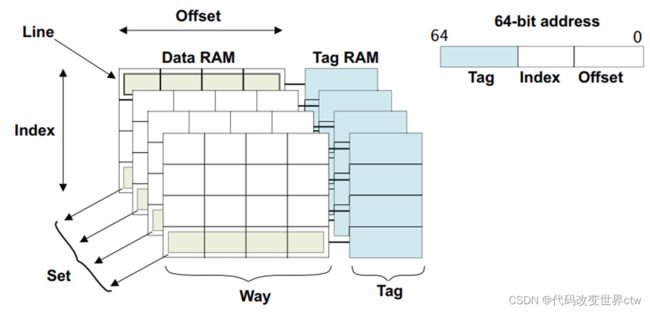
2.5、cache的组织形式(index, way, set)
cache的组织形式有:
- 全相连
- 直接相连
- 多路组相连(如4路组相连)

在一个core中一个架构中一个SOC中,所有cache的组织形式并不是都一样的。即使L1 D-cache和L1 I-cache的组织形式,也都可能不是一样的的。 具体的组织形式是怎样的,需要查询你的core trm手册。
因为有了多路组相连这个cache,所以也就有了这些术语概念:
- index : 用白话理解,其实就是在一块cache中,一行一行的编号(事实是没有编号/地址的)
- Set :用index查询到的cache line可能是多个,这些index值一样的cacheline称之为一个set
- way:用白话来说,将cache分成了多个块(多路),每一块是一个way
- cache TAG :查询到了一行cache后,cachelne由 TAG + DATA组成
- cache Data :查询到了一行cache后,cachelne由 TAG + DATA组成
- cache Line 和 entry 是一个概念
2.6、cache的种类(VIVT,PIPT,VIPT)
cache一般是有如下种类;
- PIPT
- VIVT
- VIPT
在一个core中一个架构中一个SOC中,你所使用的cache是哪种类型的,都是固定的,是软件改不了的。在ARM架构中,一般L1 cache都是VIPT的,其余的都是PIPT的。
VIPT和PIPT的原理,基本也都是一样的,只是硬件查询时稍微有一丁点的区别,在后续讲cache查询时会再次介绍。
那么,你还学什么VIVT?你为什么还要去理解VIVT的原理?你为什么还要去分析cache同名、重名的问题? 这样的问题,在armv7/armv8/armv9架构中都是不存在的
2.7、cache的分配策略(alocation,write-through, write-back)
-
读分配(read allocation)
当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。 -
读分配(read allocation)写分配(write allocation)
当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。 -
写直通(write through)
当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。 -
读分配(read allocation)写回(write back)
当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit(翻翻前面的图片,cache line旁边有一个D就是dirty bit)。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致

2.8、架构中定义的cache的范围(inner, outer)
对于cacheable属性,inner和outer描述的是cache的定义或分类。比如把L1/L1看做是inner,把L3看做是outer
通常,内部集成的cache属于inner cache,外部总线AMBA上的cache属于outer cache。例如:
- 对于big.LITTLE架构(A53为例)中,L1/L2属于inner cache,如果SOC上挂了L3的话,则其属于outer cache
- 对于DynamIQ架构(A76为例)中,L1/L2/L3属于inner cache,如果SOC上挂了System cache(或其它名称)的话,则其属于outer cache
然后我们可以对每类cache进行单独是属性配置,例如:
- 配置 inner Non-cacheable 、配置 inner Write-Through Cacheable 、配置 inner Write-back Cacheable
- 配置 outer Non-cacheable 、配置 outer Write-Through Cacheable 、配置 outer Write-back Cacheable

对于shareable属性,inner和outer描述的是cache的范围。比如inner是指L1/L2范围内的cache,outer是指L1/L2/L3范围内的cache

2.9、架构中内存的类型
在arm架构中,将物理内存分成了device和normal两种类型

而是每种的内存下(device和normal)又分出了多种属性。ARM提供一个MAIR寄存器, 将一个64位的寄存器分成8个attr属性域,每个attr属性域有8个比特,可配置成不同的内存属性。
也就是说,在一个arm core,最多支持8中物理内存类型。

而我们在MMU使用的页表的entry中的属性位中,BIT[4:2]占3个比特,表示index,其实就是指向MAIR寄存器中的attr。
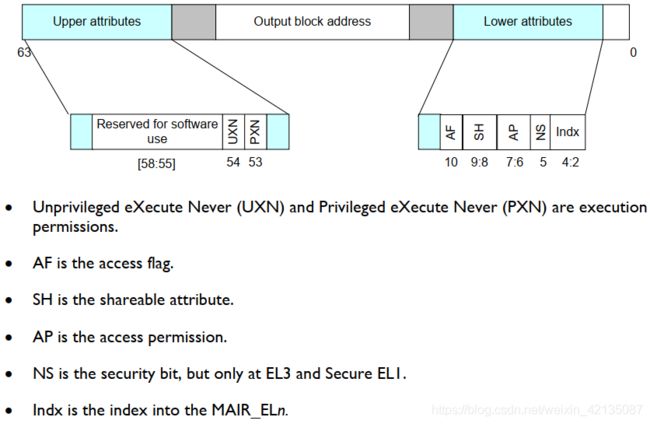
也就说说,页表的每一个entry中,都指向MAIR寄存器中的一个属性域。也就是页表的每一个entry都配置了一种内存类型。
3. cache的查询原理
3.1. cache的查询原理
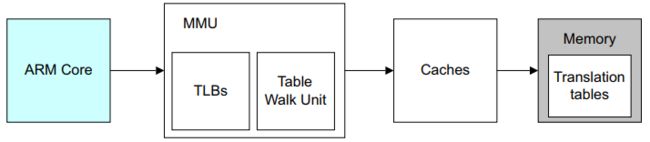
高速缓存控制器(cache controller )是负责管理高速缓存内存的硬件块,其方式对程序来说在很大程度上是不可见的。它自动将代码或数据从主存写入缓存。它从core接收读取和写入内存请求,并对高速缓存或外部存储器执行必要的操作。
当它收到来自core的请求时,它必须检查是否能在缓存中找到所请求的地址。这称为缓存查找(cache look-up)。它通过将请求的地址位的subset(index)与与缓存中的physical TAG 进行比较来做到这一点。如果存在匹配,称为命中(hit),并且该行被标记为有效,则使用高速缓存进行读取或写入。
当core从特定地址请求指令或数据,但与缓存标签不匹配或标签无效时,会导致缓存未命中,请求必须传递到内存层次结构的下一层,即 L2缓存或外部存储器。它还可能导致缓存行填充。缓存行填充会导致将一块主内存的内容复制到缓存中。同时,请求的数据或指令被流式传输到core。这个过程软件开发人员不能直接看到。在使用数据之前,core不需要等待 linefill 完成。高速缓存控制器通常首先访问高速缓存行内的关键字。例如,如果您执行的加载指令在缓存中未命中并触发缓存行填充,则内核首先检索缓存行中包含所请求数据的那部分。这些关键数据被提供给core流水线,而缓存硬件和外部总线接口随后在后台读取缓存线的其余部分。

总结一下就是:先使用index去查询cache,然后再比较TAG,比较TAG之后再检查valid标志位。
但是这里要注意:TAG包含了不仅仅是物理地址,还有很多其它的东西,如NS比特位等,这些都是在比较TAG的时候完成。
3.2. cache的查询示例

假设一个4路相连的cache(如cortex-A710),大小64KB, cache line = 64bytes,那么 1 way = 16KB,indexs = 16KB / 64bytes = 256 (注: 0x4000 = 16KB、0x40 = 64 bytes)
0x4000 – index 0
0x4040 – index 1
0x4080 – index 2
…
0x7fc0 – index 2550x8000 – index 0
0x8040 – index 1
0x8080 – index 2
…
0xbfc0 – index 255
细心的同学可以发现,这里就有了一个很大的问题,你用于cache look-up的index是vaddr[15:6], 如果granue size是4KB,那么vaddr[11:0] = paddrr[11:0] , 但是vaddr[15:12]比特并不等于paddrr[15:12] ,那么你这样的index查询的cache有效吗?会不会发生同名、歧义 ?
其实大可不必担心,因为对于每个core,L1是VIPT的,其实它们的L1 Cache TAG中,已经规定了physical address[39:12],正好是到BIT12。所以只要TAG比较之后,就不会出现同名和歧义。

4. 多核多cluster多系统之间缓存一致性概述
4.1. 质疑
网上的好多篇博文,一提Cache的多核一致性就必然提到MESI、MOESI ,然后就开始讲MESI、MOESI维护性原理?试问一下,您是真的不理解MES吗?您真的需要学习MESI?你不理解的是架构对吧,而不是学什么鬼协议!
既然您要学了MESI,那么这里也提出几个问题:
(1)、ARM架构中真的使用MESI了吗? 或者是哪一级使用了,哪一级没有使用?
(2)、MESI是一个协议? 是谁来维护的?总得有个硬件实现这个协议吧,是在ARM Core中? CCI-400中?SCU中?DSU中?
(3)、MESI的四种状态,分别记录在哪里的?
4.2. 怎样去维护多核多系统缓存的一致性
有三种机制可以保持一致性:
- 禁用缓存是最简单的机制,但可能会显着降低 CPU 性能。为了获得最高性能,处理器通过管道以高频率运行,并从提供极低延迟的缓存中运行。缓存多次访问的数据可显着提高性能并降低 DRAM 访问和功耗。将数据标记为“非缓存”可能会影响性能和功耗。
- 软件管理的一致性是数据共享问题的传统解决方案。在这里,软件(通常是设备驱动程序)必须清除或刷新缓存中的脏数据,并使旧数据无效,以便与系统中的其他处理器或主设备共享。这需要处理器周期、总线带宽和功率。
- 硬件管理的一致性提供了一种简化软件的替代方案。使用此解决方案,任何标记为“共享”的缓存数据将始终自动更新。该共享域中的所有处理器和总线主控器看到的值完全相同。
燃鹅,我们在ARM架构中,默认使用的却是第三种 硬件管理的一致性, 意思就是:做为一名软件工程师,我们啥也不用管了,有人帮我们干活,虽然如此,但我们还是希望理解下硬件原理。
再讲原理之前,我们先补充一个场景:
假设在某一操作系统中运行了一个线程,该线程不停着操作0x4000_0000地址处内存(所以我们当然期望,它总是命中着),由于系统调度,这一次该线程可能跑在cpu0上,下一次也许就跑在cpu1上了,再下一次也许就是cpu4上了(其实这种行为也叫做CPU migration)
或者举个这样的场景也行:
在Linux Kernel系统中,定义了一个全局性的变量,然后多个内核线程(多个CPU)都会访问该变量.
在以上的场景中,都存在一块内存(如0x4000_0000地址处内存)被不同的ARM CORE来访问,这样就会出现了该数据在main-memory、SCU-0的L2 cache、SCU-1的L2 cache、8个Core的L1 cache不一致的情况。
既然出现了数据在内存和不同的cache中的不一致的情况,那么就需要解决这个问题(也叫维护一致性),那么怎么维护的呢,上面也说了“使用 硬件管理的一致性”,下面就以直接写答案的方式,告诉你硬件是怎样维护一致性的。
4.3. bit.LITTLE架构 和 DynamIQ架构 的系统中的缓存一致性
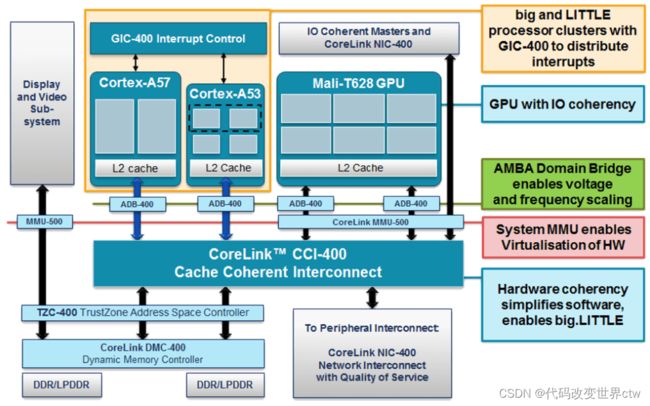
我们先看一张老的图(bit.LITTLE架构的)吧
- core1、core1的cache的一致性,是由SCU-0来维护的(至于这里是不是遵守了MESI协议,答案:YES)
- cluster0、cluster1的cache的一致性,是由于CCI-400来维护的(至于这里是不是遵守了MESI协议,答案:NO)

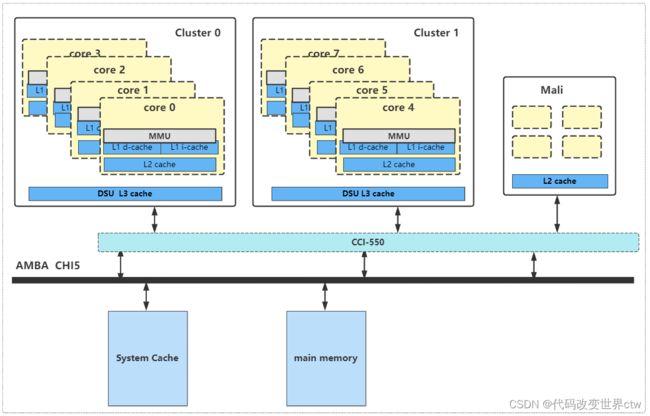
再看一张比较新的图(DynamIQ架构的)吧 - core0的cache(含L1/L2)、core1的cache(含L1/L2)的一致性 由DSU-0来维护(至于这里是不是遵守了MESI协议,答案: YES)
- cluster0的 L3 cache、cluster1的 L3 cache、Mali的L2 cache的一致性是由于CCI-550来维护的(至于这里是不是遵守了MESI协议,NO)
4.4. MESI、MOESI 的介绍
注意着仅仅是一个协议 ,它既不是软件也不是硬件,算上一个标准吧。既然只是一个协议(标准),那总得有硬件来执行维护该协议吧。一般来讲,在core cache之间的一致性是要遵从MESI/MOESI协议的,由SCU(或DSU)硬件来执行维护该协议的。在ARM架构中,也并非所有的缓存都遵从MESI/MOESI协议,仅仅只是在一个cluster中的core cache中,才需要遵从MESI/MOESI协议。而对于不同的core,又遵从着不同的协议,具体请查略你的core TRM手册,上面会说明你的core cache是使用MESI还是MOESI。 接下来我们就来看一下MESI协议部分。
首先是Modified Exclusive Shared Invalid (MESI) 协议中定义了4个状态:
| MESI State | Definition |
|---|---|
| Modified (M) | 这行数据有效,数据已被修改,和内存中的数据不一致,数据只存在于该高速缓存中 |
| Exclusive (E) | 这行数据有效,数据和内存中数据一致,数据只存在于该高速缓存中 |
| Shared (S) | 这行数据有效,数据和内存中数据一致,多个高速缓存有这行数据的副本 |
| Invalid (I) | 这行数据无效 |
其次,在ARM的部分的core中,定义了第五种状态Shared Modified,这种称之为MOESI 协议. 而ARM使用的则是MOESI的变体(啥叫变体,咋变的,变的哪些,文当它没有说)

然后我们通过数据流图的方式,观看下MESI这四种状态的情况:

MESI状态之间的切换:

Events:
RH = Read Hit
RMS = Read miss, shared
RME = Read miss, exclusive
WH = Write hit
WM = Write miss
SHR = Snoop hit on read
SHI = Snoop hit on invalidate
LRU = LRU replacement
Bus Transactions:
Push = Write cache line back to memory
Invalidate = Broadcast invalidate
Read = Read cache line from memory
4.5. 总结
- 看完以上信息,我们再次总结一下,我们学习cache一致性,我们最大的困惑或瓶颈是啥,是不理解MESI吗?应该还是对架构的理解和认知。学习MESI,不如去学习cache硬件基础、cache TAG、DSU、CCI-550原理吧。
- 多核之间的缓存一致性,由SCU(DSU)硬件来执行维护,使用MESI协议
- 多cluster之间的缓存一致性,由 CCI/CMN 来执行维护,没有使用MESI协议
5. 多级cache之间的替换策略
思考:
1、L1 cache的替换策略是什么,L2和L3的呢
2、哪些的替换策略是由硬件决定的(定死的,软件不可更改的),哪些的替换策略是软件可以配置的?
3、在经典的 DynamIQ架构 中,数据是什么时候存在L1 cache,什么时候存进L2 cache,什么时候又存进L3 cache,以及他们的替换策略是怎样的? 比如什么时候数据只在L1? 什么时候数据只在L2? 什么时候数据只在L3? 还有一些组合,比如什么时候数组同时在L1和L3,而L2没有? 这一切的规则是怎样定义的?
说明:
本文讨论经典的DynamIQ的cache架构,忽略 big.LITTLE的cache架构

5.1、DynamIQ架构中L1 cache的替换策略(以cortex-A710为例)
我们先看一下DynamIQ架构中的cache中新增的几个概念:
- (1) Strictly inclusive: 所有存在L1 cache中的数据,必然也存在L2 cache中
- (2) Weakly inclusive: 当miss的时候,数据会被同时缓存到L1和L2,但在之后,L2中的数据可能会被替换
- (3) Fully exclusive: 当miss的时候,数据只会缓存到L1
其实inclusive/exclusive属性描述的正是是 L1和L2之间的替换策略,这部分是硬件定死的,软件不可更改的。
我们再去查阅 ARMV9 cortex-A710 trm手册,查看该core的cache类型,得知:

- L1 I-cache和L2之间是 weakly inclusive的
- L1 D-cache和L2之间是 strictly inclusive的
也就是说:
- 当发生D-cache发生miss时,数据缓存到L1 D-cache的时候,也会被缓存到L2 Cache中,当L2 Cache被替换时,L1 D-cache也会跟着被替换
- 当发生I-cache发生miss时,数据缓存到L1 I-cache的时候,也会被缓存到L2 Cache中,当L2 Cache被替换时,L1 I- cache不会被替换
再次总结 : L1 和 L2之间的cache的替换策略,I-cache和D-cache可以是不同的策略,每一个core都有每一个core的做法,请查阅你使用core的手册。
5.2、core cache的替换策略(以cortex-A710为例)
为了能够将DynamIQ架构和bit.LITTLE架构的cache放在一起介绍,我们将DynamIQ架构中的L1/L2 cache看做成一个单元统称Core cache,bit.LITTLE架构中的L1 Cache也称之为core cache.
DynamIQ架构中DSU中的L3 cache称之为cluster cache,bit.LITTLE架构中SCU中的L2 cache也称之为cluster cache。
5.2.1、L1 data cache 遵从MESI协议
在L1 data cache TAG中,有记录MESI相关比特, 然后将一个core内的cache看做是一个整体,core与core之间的缓存一致性,就由DSU执行MESI协议来维护

5.2.2、L1 instruction cache 没有遵从MESI协议
因为对于Instruction cache来说,都是只读的,cpu不会改写I-cache中的数据,所以也就不需要硬件维护多核之间缓存的不一致

5.2.3、MESI协议的介绍
MESI这四种状态:
MESI状态之间的切换:
Events:
RH = Read Hit
RMS = Read miss, shared
RME = Read miss, exclusive
WH = Write hit
WM = Write miss
SHR = Snoop hit on read
SHI = Snoop hit on invalidate
LRU = LRU replacement
Bus Transactions:
Push = Write cache line back to memory
Invalidate = Broadcast invalidate
Read = Read cache line from memory
5.3、cluster cache 之间的替换策略
说实话,core cache / cluster cache / 这个名字可能不好,感觉叫private cache 和 share cache也会更好,我也不知道官方一般使用哪个,反正我们能理解其意思即可吧。
那么他们之间的替换策略是怎样的呢?
我们知道MMU的页表中的表项中,管理者每一块内存的属性,其实就是cache属性,也就是缓存策略。
其中就有cacheable和shareable、Inner和Outer的概念。如下是针对 DynamIQ 架构做出的总结,注意哦,仅仅是针对 DynamIQ 架构的cache。
-
如果将block的内存属性配置成Non-cacheable,那么数据就不会被缓存到cache,那么所有observer看到的内存是一致的,也就说此时也相当于Outer Shareable。
其实官方文档,也有这一句的描述:
在B2.7.2章节 “Data accesses to memory locations are coherent for all observers in the system, and correspondingly are treated as being Outer Shareable” -
如果将block的内存属性配置成write-through cacheable 或 write-back cacheable,那么数据会被缓存cache中。write-through和write-back是缓存策略。
-
如果将block的内存属性配置成 non-shareable, 那么core0访问该内存时,数据缓存的到Core0的L1 D-cache / L2 cache (将L1/L2看做一个整体,直接说数据会缓存到core0的private cache更好),不会缓存到其它cache中。
-
如果将block的内存属性配置成 inner-shareable, 那么core0访问该内存时,数据只会缓存到core 0的L1 D-cache / L2 cache和 DSU L3 cache,不会缓存到System Cache中(当然如果有system cache的话 ) , (注意这里MESI协议其作用了)此时core0的cache TAG中的MESI状态是E, 接着如果这个时候core1也去读该数据,那么数据也会被缓存core1的L1 D-cache / L2 cache 和DSU0的L3 cache(白字黑字,绝不瞎说,请参见文末的
[1] DSU TRM片段), 此时core0和core1的MESI状态都是S -
如果将block的内存属性配置成 outer-shareable, 那么core0访问该内存时,数据会缓存到core 0的L1 D-cache / L2 cache 、cluster0的DSU L3 cache 、 System Cache中, core0的MESI状态为E。如果core1再去读的话,则也会缓存到core1的L1 D-cache / L2 cache,此时core0和core1的MESI都是S。这个时候,如果core7也去读的话,数据还会被缓存到cluster1的DSU L3 cache. 至于DSU0和DSU1之间的一致性,非MESI维护,具体怎么维护的请看DSU手册,本文不展开讨论。
| Non-cacheable | write-through cacheable |
write-back cacheable |
|
|---|---|---|---|
| non-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) |
core0访问该内存时,数据缓存的到Core0的L1 D-cache / L2 cache (将L1/L2看做一个整体,直接说数据会缓存到core0的private cache更好),不会缓存到其它cache中 | 同左侧 |
| inner-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) |
core0访问该内存时,数据只会缓存到core 0的L1 D-cache / L2 cache和 DSU L3 cache,不会缓存到System Cache中(当然如果有system cache的话 ) , (注意这里MESI协议其作用了)此时core0的cache TAG中的MESI状态是E, 接着如果这个时候core1也去读该数据,那么数据也会被缓存core1的L1 D-cache / L2 cache 和DSU0的L3 cache, 此时core0和core1的MESI状态都是S | 同左侧 |
| outer-shareable | 数据不会缓存到cache (对于观察则而言,又相当于outer-shareable) |
core0访问该内存时,数据会缓存到core 0的L1 D-cache / L2 cache 、cluster0的DSU L3 cache 、 System Cache中, core0的MESI状态为E。如果core1再去读的话,则也会缓存到core1的L1 D-cache / L2 cache,此时core0和core1的MESI都是S 思考:那么此时core7去读取会怎样? |
同左侧 |
5.4、总结
- dynamIQ 架构中 L1和L2之间的替换策略,是由core的inclusive/exclusive的硬件特性决定的,软无法更改
- core cache之间的替换策略,是由SCU(或DSU)执行的MESI协议中定义的,软件也无法更改。
- cluster cache之间的替换策略,是由于MMU页表中的内存属性定义的(innor/outer/cacheable/shareable),软件可以修改
5.5 参考
- [1] DSU TRM片段

6. A53 cache的架构解读
6.1. A53使用经典的 bit-LITTLE架构
以下是一张比较早期的经典的bit-LITTLE的架构图

6.2. A53的cache配置
L1 I-Cache
- 可配:8KB, 16KB, 32KB, or 64KB
- cacheline:64bytes
- 2路组相连
- 128-bit的读L2 memory的接口
L1 D-Cache
- 可配:8KB, 16KB, 32KB, or 64KB
- cacheline:64bytes
- 4路组相连
- 256-bit的写L2 memory的接口
- 128-bit的读L2 memory的接口
- 64-bit的读L1到datapath
- 128-bit的写datapath到L1
L2 memory System
- 集成了SCU( Snoop Control Unit ),做多可以连接4个core
- SCU内重复拷贝了 L1 Data Cache的TAGs
- L2 memory system对外的接口,可以是ACE 或 CHI,128-bit宽度
L2 cache
- 可配置的: 128KB, 256KB, 512KB, 1MB and 2MB.
- cacheline:64bytes
- Physically indexed and tagged cache(PIPT)
- 16路组相连的结构
L1 data cache TAG
A53的L1 Data cache遵从的是MOESI协议,如下所示在L1 data cache的tag中存有MOESI的标记位

MOESI state

L1 Instruction cache TAG
L1 instruction cache是只读的,所以也就无需硬件维护的多core之间instruction cache的一致性,所以也就无需组从MOESI协议,以下展示了*L1 Instruction cache的TAG,其中标记为很少,无MESI标记位。

6.3. cache的层级结构:
- L1 cache是private的在core中
- L2 cache是share的在cluster中

6.4. L2 memory System系统介绍
在bit.LITTLE架构中中,在Cluster中,有一个SCU单元,SCU单元主要是执行和维护L1 cache的一致性(MESI协议 或 其变体如MOESI协议)。

在L2 Memory System的中,除了包含L2 cache,也会包含L1 Duplicate tag RAM(这里指的其实是L1 Data Cache Tags)。

6.5. 多cluster之间的缓存一致性
cluster和外界的接口,可以是ACE或CHI(目前常用的是ACE,后面的趋势可能是CHI)

- 如果使用的是ACE,那么多cluster之间的一致性,依靠
CCI + ACE来维护 - 如果使用的是CHI,那么多cluster之间的一致性,依靠
CMN + CHI来维护

6.6. CCI的介绍(以CCI-550为例)
CCI-550 包含一个包容性监听过滤器(snoop filter),用于记录存储在ACE 主缓存。
侦听过滤器可以在未命中的情况下响应侦听事务,并侦听适当的主控只有在命中的情况下。Snoop 过滤器条目通过观察来自 ACE 主节点的事务来维护以确定何时必须分配和取消分配条目。
侦听过滤器可以响应多个一致性请求,而无需向所有人广播ACE 接口。例如,如果地址不在任何缓存中,则监听过滤器会以未命中和将请求定向到内存。如果地址在处理器缓存中,则请求被视为命中,并且指向在其缓存中包含该地址的 ACE 端口。


6.7. 经典示例框图

