TensorFlow2.0入门到进阶系列——6_循环神经网络
6_循环神经网络
- 1、理论部分
-
- 1.1、Embedding与变长输入的处理
- 1.2、循环神经网络
- 1.3、LSTM长短期记忆网络
- 2、实战部分
-
- 2.1、Keras实战embedding
- 2.2、循环神经网络—实战
- 2.3、文本生成—实战
- 2.4、LSTM实战
-
- 2.4.1、LSTM文本分类
- 2.4.2、LSTM文本生成
1、理论部分
卷积神经网络-CV
循环神经网络-NLP
- Embedding与变长输入的处理
- 序列式问题
- 循环神经网络
- LSTM模型
1.1、Embedding与变长输入的处理
Embedding
- One-hot编码;
- Word -> index -> [0,0,0,…,0,1,0,…,0]
- Dense embedding(密集编码)
- Word -> index -> [1.2,4.2,2.9,…,0.1]
变长输入
- Word -> index -> [1.2,4.2,2.9,…,0.1]
- Padding
- Word index:[3,2,5,9,1]
- Padding:[3,2,5,9,1,0,0,0,0,0]
- 合并
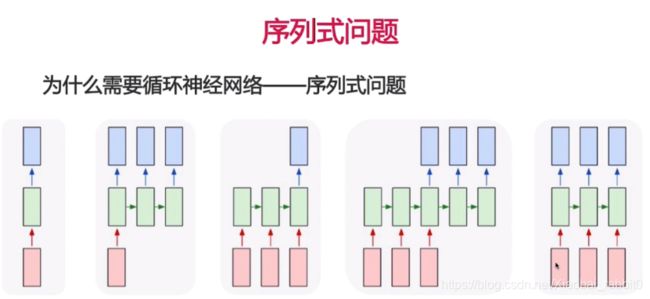
为什么需要循环神经网络——合并+padding的缺点
- 信息丢失
- 多个embedding合并
- Pad噪音、无主次
- 无效计算太多,低效
- 太多的padding
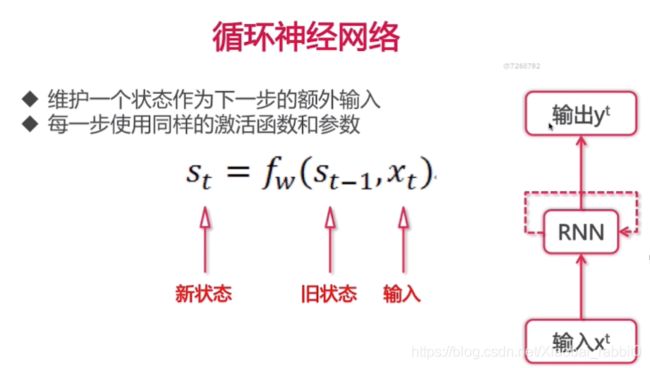
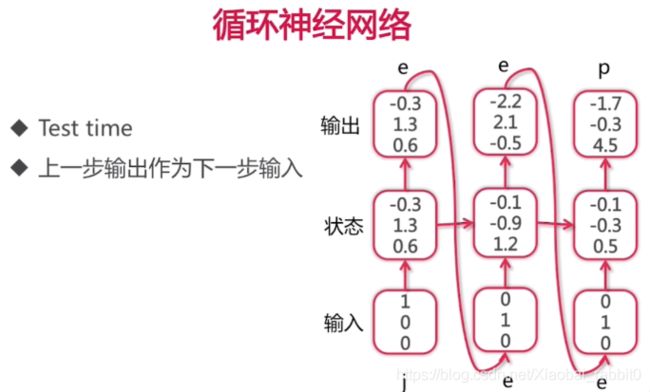
1.2、循环神经网络
序列式问题


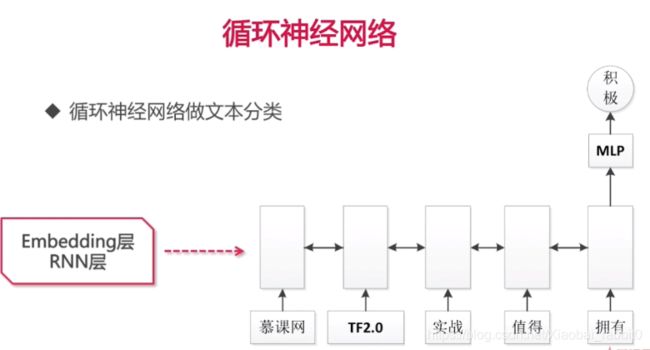
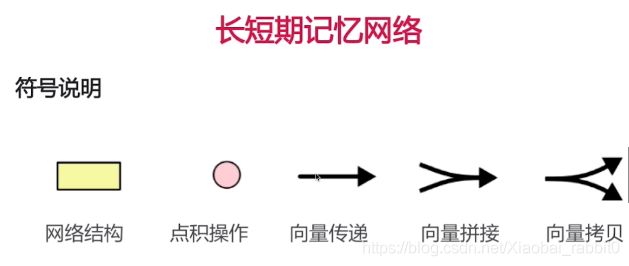
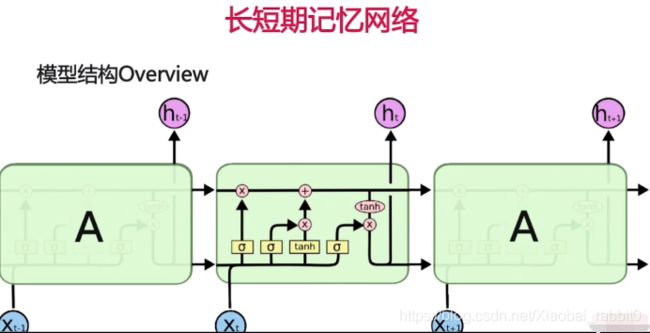
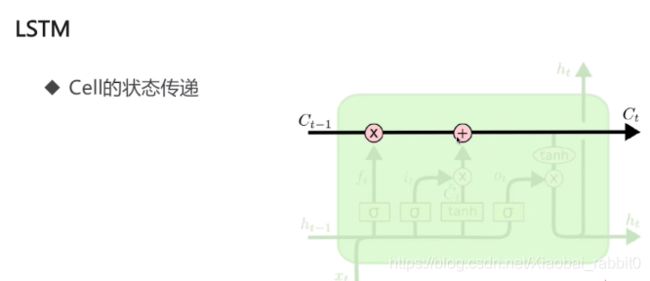
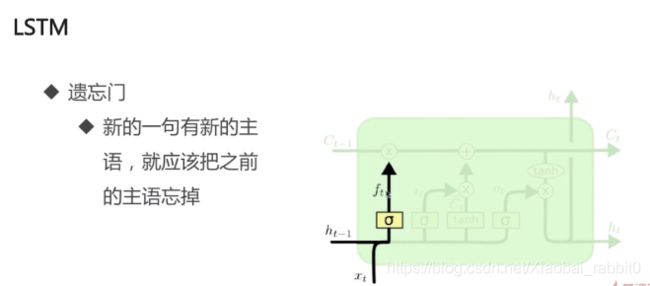
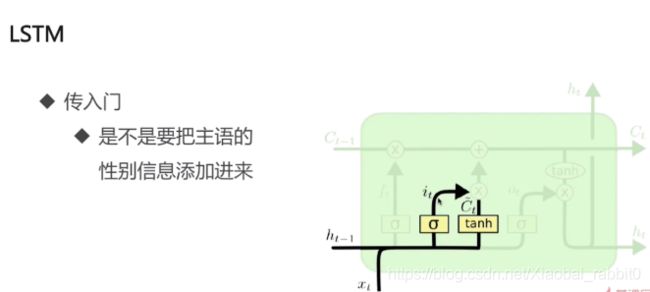
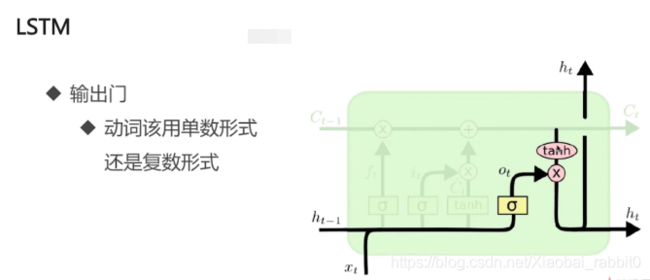
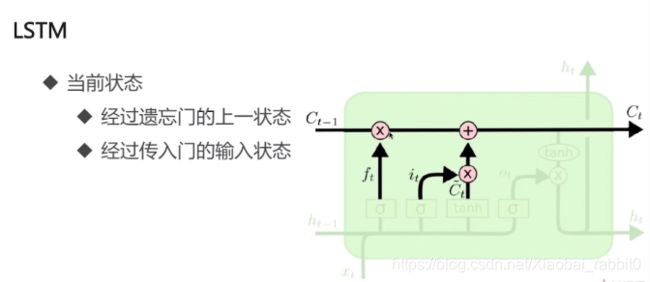
1.3、LSTM长短期记忆网络
为什么需要LSTM
- 普通RNN的信息不能长久传播(存在于理论上)
- 引入选择机制
- 选择性输出
- 选择性输入
- 选择性遗忘
- 选择性 -> 门
- Sigmoid函数:[0,1]
- 门限机制
- 向量A -> sigmoid -> [0.1,0.9,0.4,0,0.6]
- 向量B -> [13.8,14,-7,-4,30.0]
- A为门限,B为信息
- A * B = [0.138,12.6,-2.8,0,18.0]
2、实战部分
- Keras实战embedding
- Keras搭建循环神经网络
- Keras文本生成实战
- Keras搭建LSTM网络
- Kaggle文本分类数据集实战
2.1、Keras实战embedding
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
imdb = keras.datasets.imdb #电影评论(好/坏)
vocab_size = 10000 #限制数据集中词表数量
index_from = 3 #控制词表的index从哪里开始算
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words = vocab_size, index_from = index_from)
print(train_data[0], train_labels[0]) #train_data每一个样本,都是一个向量
print(train_data.shape, train_labels.shape) #train_data.shape因为第二维度不定长,所以没给出来,train_labels.shape就是一维的
print(len(train_data[0]), len(train_data[1]))
print(test_data.shape, test_labels.shape)
word_index = imdb.get_word_index() #载入词表key:value的形式
print(len(word_index))
print(word_index)
word_index = {k:(v+3) for k, v in word_index.items()}
#前四个槽位存放特殊字符
word_index['' ] = 0 #(做padding的时候用来填充的字符)
word_index['' ] = 1 #起始字符
word_index['' ] = 2 #找不到时添加
word_index['' ] = 3 #结尾字符
#生成一个反向的word_index (value -> key)
reverse_word_index = dict(
[(value, key) for key, value in word_index.items()])
#反向预测,查看文本
def decode_review(text_ids):
return ' '.join(
[reverse_word_index.get(word_id, "" ) for word_id in text_ids])
#解析,train_data数据
decode_review(train_data[0])
max_length = 500 #长度低于500的句子会被补全,长度高于500的句子会被截断
train_data = keras.preprocessing.sequence.pad_sequences( #数据补全
train_data, # list of list
value = word_index['' ],
padding = 'post', # post, pre
maxlen = max_length)
test_data = keras.preprocessing.sequence.pad_sequences(
test_data, # list of list
value = word_index['' ],
padding = 'post', # post, pre
maxlen = max_length)
print(train_data[0])
embedding_dim = 16 #每一个word都embadding成长度为16的向量
batch_size = 128
model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim, #输出为三维矩阵
input_length = max_length),
# batch_size * max_length * embedding_dim
# -> batch_size * embedding_dim
keras.layers.GlobalAveragePooling1D(), #消掉max_length这个维度
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation = 'sigmoid'),
])
model.summary()
model.compile(optimizer = 'adam', loss = 'binary_crossentropy',
metrics = ['accuracy'])
history = model.fit(train_data, train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2)
def plot_learning_curves(history, label, epochs, min_value, max_value):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize=(8, 5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
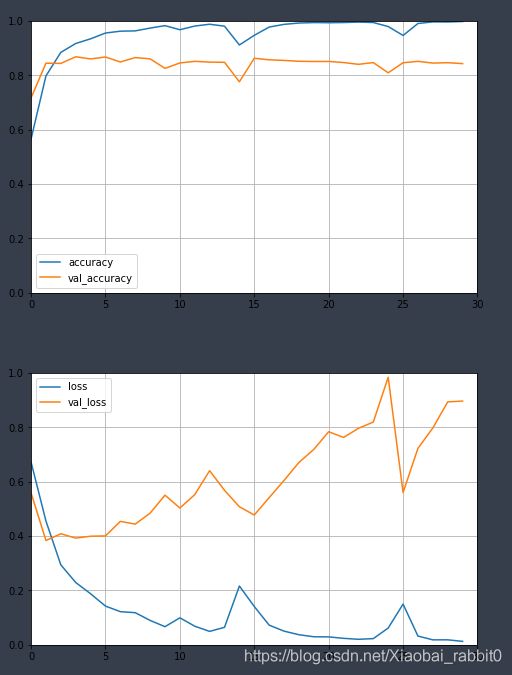
plot_learning_curves(history, 'accuracy', 30, 0, 1) #epochs=30
plot_learning_curves(history, 'loss', 30, 0, 1)
#由上图可以看出,出现了过拟合
model.evaluate(
test_data, test_labels,
batch_size = batch_size,)
2.2、循环神经网络—实战
- 循环神经 网络文本分类实战
- 文本生成实战
修改模型结构
embedding_dim = 16
batch_size = 512
single_rnn_model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
keras.layers.SimpleRNN(units = 64, return_sequences = False), #循环神经网络,添加一个RNN层即可
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
single_rnn_model.summary()
single_rnn_model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
history_single_rnn = single_rnn_model.fit(
train_data, train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2)
这个模型是单层、单向RNN,过于简单所以效果很差
下面改成多层,双向RNN网络
embedding_dim = 16
batch_size = 512
model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
keras.layers.Bidirectional( #这里封装一下,就变成双向RNN了
keras.layers.SimpleRNN(
units = 64, return_sequences = True)),
keras.layers.Bidirectional( #添加层
keras.layers.SimpleRNN(
units = 64, return_sequences = False)),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
model.summary()
model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
history = model.fit(
train_data, train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2)
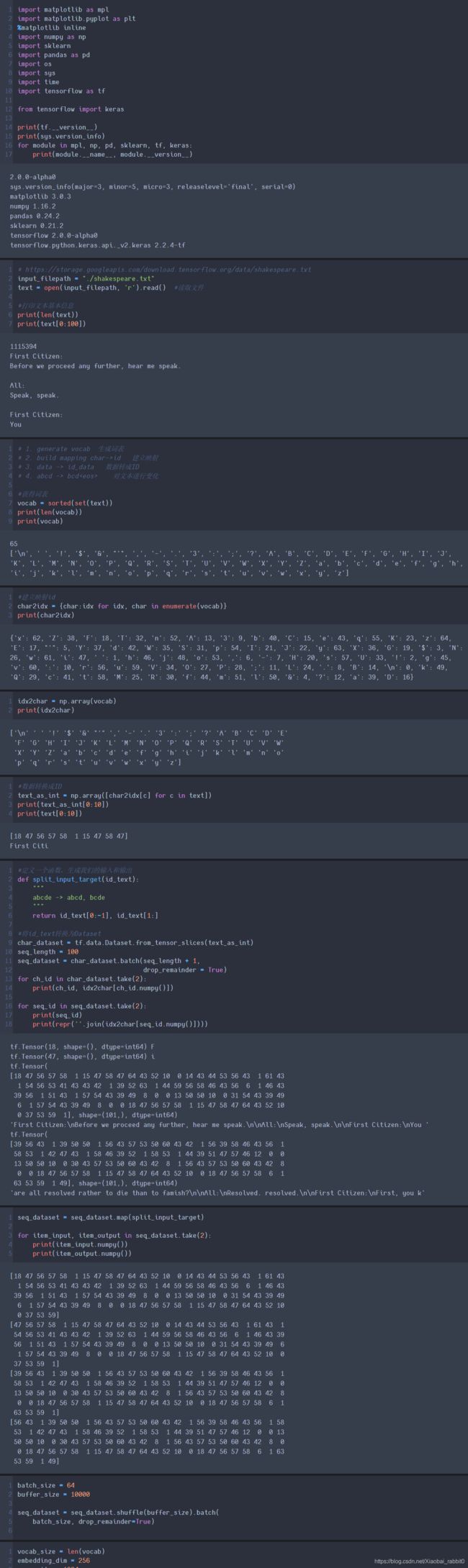
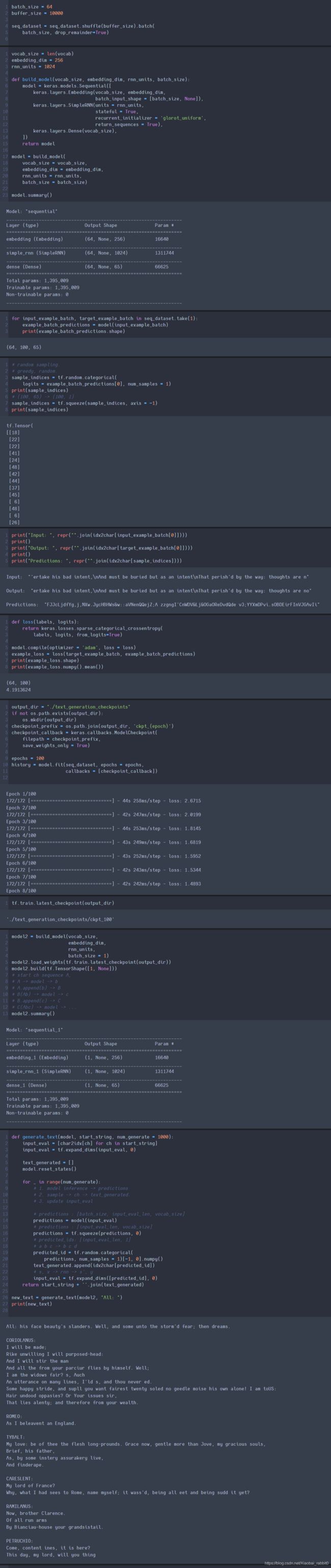
2.3、文本生成—实战
莎士比亚文本数据集
2.4、LSTM实战
2.4.1、LSTM文本分类
将之前的文本分类的代码的SimpleRNN换成LSTM即可
单层单向的LSTM
embedding_dim = 16
batch_size = 512
single_rnn_model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
keras.layers.LSTM(units = 64, return_sequences = False),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
single_rnn_model.summary()
single_rnn_model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
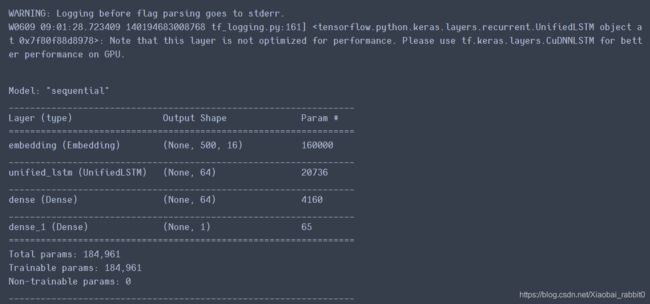
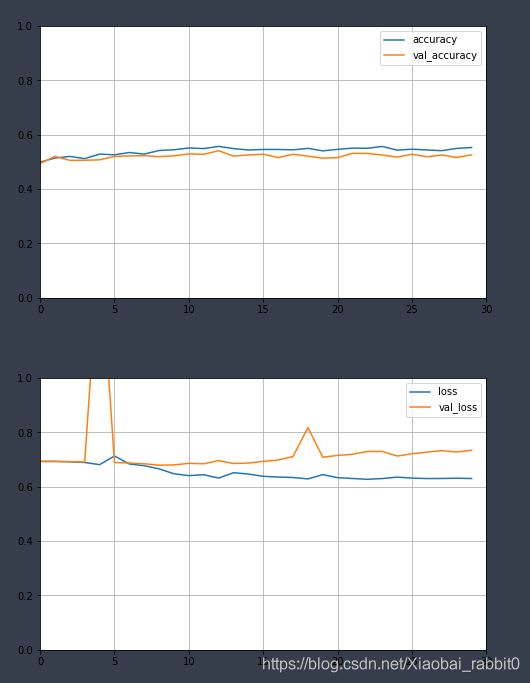
结果:和之前的效果差不多,存在严重的过拟合现象。
双层双向LSTM
embedding_dim = 16
batch_size = 512
model = keras.models.Sequential([
# 1. define matrix: [vocab_size, embedding_dim]
# 2. [1,2,3,4..], max_length * embedding_dim
# 3. batch_size * max_length * embedding_dim
keras.layers.Embedding(vocab_size, embedding_dim,
input_length = max_length),
keras.layers.Bidirectional(
keras.layers.LSTM(
units = 64, return_sequences = True)),
keras.layers.Bidirectional(
keras.layers.LSTM(
units = 64, return_sequences = False)),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(1, activation='sigmoid'),
])
model.summary()
model.compile(optimizer = 'adam',
loss = 'binary_crossentropy',
metrics = ['accuracy'])
结果:依旧存在过拟合现象,不过效果比之前好很多
2.4.2、LSTM文本生成
将之前文本生成的代码的SimpleRNN换成LSTM
在添加stateful = True,recurrent_initializer = ‘glorot_uniform’,这两个参数,进行调参。
vocab_size = len(vocab)
embedding_dim = 256
rnn_units = 1024
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = keras.models.Sequential([
keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape = [batch_size, None]),
keras.layers.LSTM(units = rnn_units,
stateful = True,
recurrent_initializer = 'glorot_uniform',
return_sequences = True),
keras.layers.Dense(vocab_size),
])
return model
model = build_model(
vocab_size = vocab_size,
embedding_dim = embedding_dim,
rnn_units = rnn_units,
batch_size = batch_size)
model.summary()
结果:效果变好很多,都是一些正常的单词