redis集群原理及三种模式解析
1:主从模式
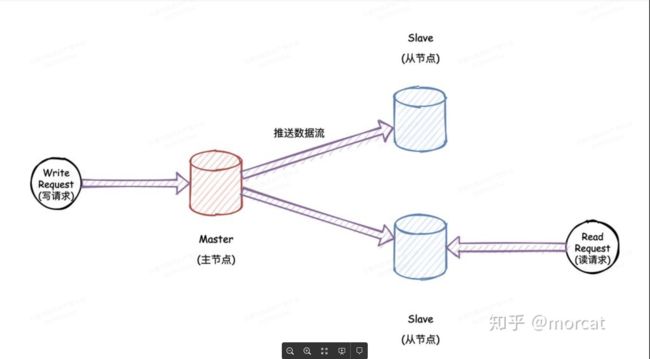
使用sync或者psync进行通信
初次同步:
->从服务器接收slaveof
->像主服务器发送sync或psync命令
->主服务器执行BGSAVE生成RDB文件,并使用缓冲区记录现在开始所有执行命令
->主服务器发送rdb到从服务器
->从服务器开始复制,同步完成后
->主服务器把缓冲区记录的新命令发送给从服务器,知道从服务器执行并保持一致
sync全部同步,psync可以从断开的地方同步,2.8版本以后支持
psync如何实现部分重同步:
主从都会复制一个偏移量,主发送了5就N+5,从接收了5就n+5,当n一致就是数据一致,有偏差,差值就是字节数,字节数如果小于主服务器的(复制积压缓冲区大小)就直接发送缓冲区的部分数据,反之已然要全部复制
复制积压缓冲区:
主服务器维护的先进先出的字节队列,默认1Mb.每个字节都有自己的偏移量。当重连,主收到从的偏移量后,如果偏移量在缓冲区之中,只要发送后面的数据就行。
记录主服务器ID:
主服务器都有一个自己的ID,当从重连主,判断是不是一个id,是就判断是不是需要全量复制。不是那就换了主机器,直接全量。
2:哨兵模式
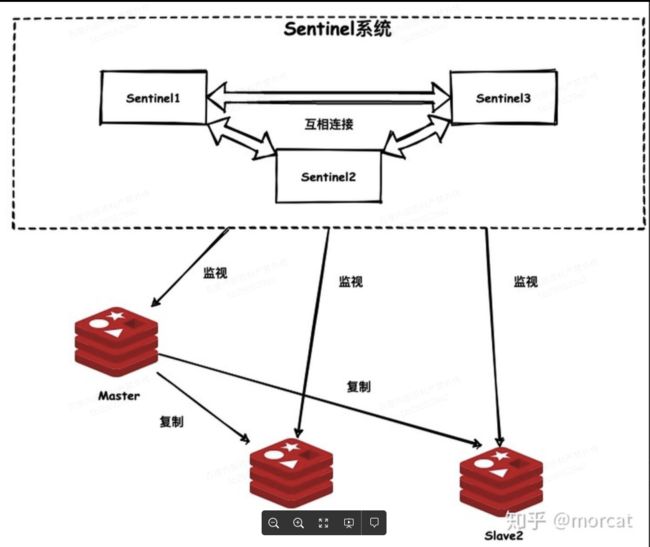
gossip通信
主从不高可用,需要人工切换主
sentinel和redis都是集群,保证高可用,监视redis集群
1:sentinel每隔10s给主发送信号,获取集群中主从的信息,然后对从同样建立连接。
2:sentinel会每秒发送信息给主,是否返回PONG,判断主是否下线。如果sentinel(A)没有收到主的回复,则A认为主,主观下线。当主管下线》N/2,则为客观下线。N最小为3,2个认为就可以。
3:选举leader sentinel 来下线主,通过raft一致性算法选举
大致思路:每个sentinel发现后都要和其他申请自己成为leader,其它可以同意或者拒绝,超过一半的就是主。不同意就一直过一段时间重试。如果收到请求的节点没有选过其他人,则会同意将A设置成主库
4:选举新的主服务器:
选择健康的-》优先级高的-》选择偏移量最大的-》leader sentinel发送命令给主和从,替换为新的组合。
3:redis cluser
哨兵实现了高可用,但是主依然只有一台。redis 3.0采用去中心化的方式进行了完善
一个redis集群有多个节点,每个节点都有自己和其他的信息,以及新加入的节点信息。
整个数据库有16384个插槽,通过cluster addslots 2 3 4 分配个机器指定的插槽。
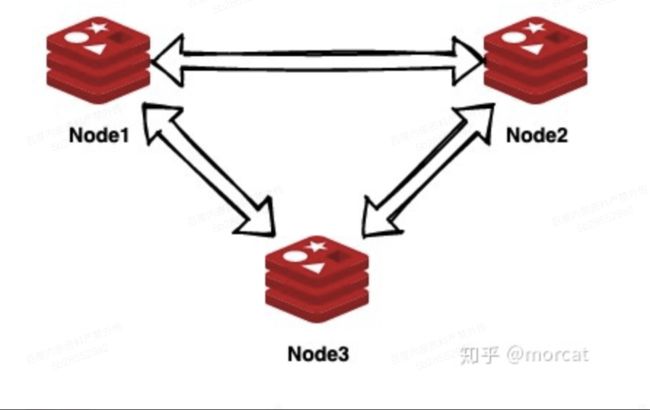
通过crc16取模计算key所在的插槽和节点,再取数据
执行流程:
1:客户端请求随机发到任意的节点
2:计算键值所在的插槽
3:判断是否是当前节点,是直接执行命令,否返回客户端moved错误,会带着正确的节点地址与端口
4:客户端直接转向正式的
高可用:
每个节点都有主从,主节点负责槽,从节点负责复制某个主节点的数据,并在主节点下线时代替主
例如a节点下可能有b,c,d的数据都可以进行备份和替换。
故障转移:
Y与哨兵模式相同:
会定期向其它节点发消息,然后就是主观下线,客观下线
通过raft算法选举出新的leader成为主节点(当前节点下)
新的主节点把之前的主的槽分配给自己。
广播出去自己成为新的主,开始接收和处理自己负责的节点
总结:
本文主要介绍了Redis三种集群模式,总结一下
- 主从模式 可以实现读写分离,数据备份。但是并不是「高可用」的
- 哨兵模式 可以看做是主从模式的「高可用」版本,其引入了Sentinel对整个Redis服务集群进行监控。但是由于只有一个主节点,因此仍然有写入瓶颈。
- Cluster模式 不仅提供了高可用的手段,同时数据是分片保存在各个节点中的,可以支持高并发的写入与读取。当然实现也是其中最复杂的。
4.Redis分片是什么?
即使使用哨兵模式,redis集群的每个节点都有全部数据,所以存在木桶效应,总数剧存储取决于最小的数据。
每个分片其实就是上面第三种架构所说的一个小的节点集群,里面有一个主多个从,然后有所属的卡槽。
增加节点:
通过meet命令。
新加节点要么成为某一个分片的从节点,要么成为主节点并分配卡槽
分配未分配的卡槽,直接分配
分配已分配的卡槽
无数据直接通过命令操作即可
有数据,就需要对数据进行迁移,因为迁移卡槽不会把数据一同迁移过去。
先迁移卡槽,然后通过migrate命令进行卡槽数据迁移
数据量太大怎么办?
进行迁移时,假设要把0号插槽从A迁移到B,此时redis-trib.rb会依次执行如下操作:
(1)在B执行cluster setslot 0 importing A。
(2)在A执行cluster setslot 0 migrating B。
(3)执行cluster getkeysinslot 0 获取0号插槽的键列表。
(4)对第3步获取的每个键执行migrate命令,将其从A迁移到B。
(5)执行cluster setslot 0 node B来完成迁移。
(1)(2)的功能就是,客户端-》键值是否在本节点-》在执行(不在返回信息-》客户端-》新节点获取)
卡槽发现:
-c可以自动处理,优化应该计算每个redis的key在哪个卡槽,并缓存记录直接请求对应的卡槽。
故障修复:
集群中的每个节点每隔1秒就会随机选择5个节点,然后选择其中最久没有响应的节点发送ping命令参考文档:初学乍练redis:分片与集群_wzy0623的专栏-CSDN博客_redis分片和集群区别