数据挖掘-决策树算法+代码实现(七)

目录
从例子出发
算法原理
算法的优缺点
关于剪枝
代码实现
随机森林、GBDT、XGBOOST
总结
决策树(decision tree):是一种基本的分类与回归方法,此处主要讨论分类的决策树。
在分类问题中,表示基于特征对实例进行分类的过程,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习的本质:从训练集中归纳出一组分类规则,或者说是由训练数据集估计条件概率模型。
决策树学习的损失函数:正则化的极大似然函数
决策树学习的测试:最小化损失函数
决策树学习的目标:在损失函数的意义下,选择最优决策树的问题。

从例子出发
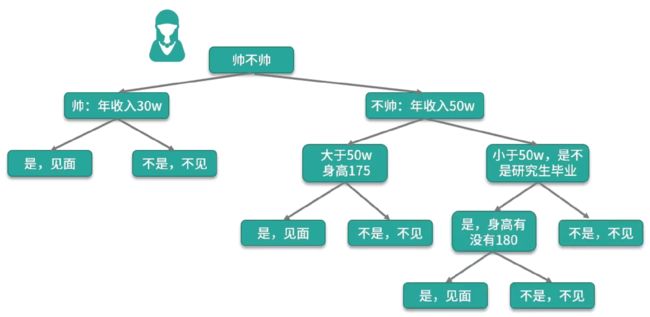
在已知的条件中,选取一个条件作为树根,然后再看是否还需要其他判断条件。
所有的非叶子节点都是特征信息。

根据对应的信息得出结论:
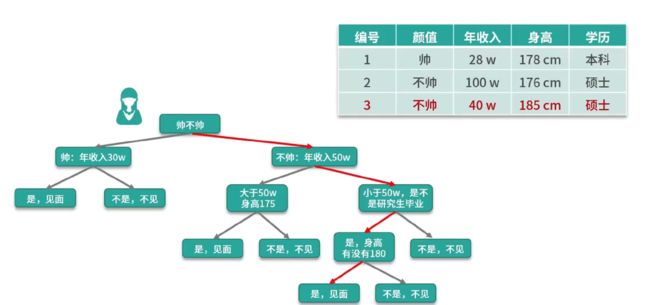 算法原理
算法原理
决策树算法使用信息增益的方法来衡量一个特征和特征之间的重要性。
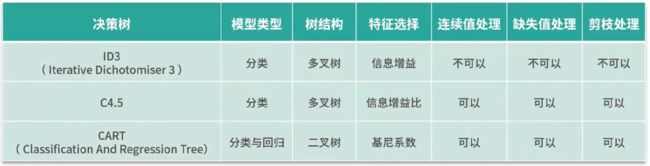
几个版本的决策树的比较
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
1) 开始:构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
2) 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
3)如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如果递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
4)每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一棵决策树。
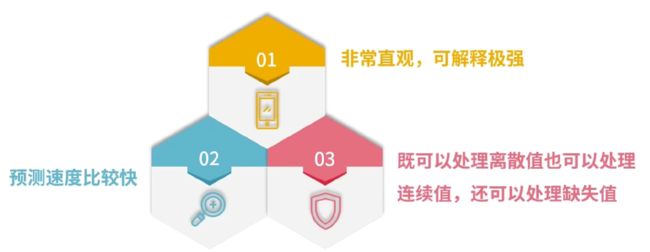
算法的优点
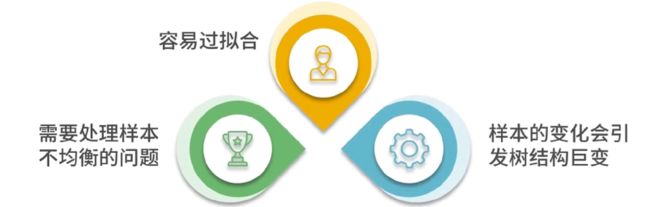
算法的缺点
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配的问题
- 适用数据类型:数值型和标称型
关于剪枝
 代码实现
代码实现
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)[source]
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
#引入决策树算法包
import numpy as np
np.random.seed(0)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices = np.random.permutation(len(iris_x))
iris_x_train = iris_x[indices[:-10]]
iris_y_train = iris_y[indices[:-10]]
iris_x_test = iris_x[indices[-10:]]
iris_y_test = iris_y[indices[-10:]]
设置树的最大的深度为4
clf = DecisionTreeClassifier(max_depth=4)
clf. fit(iris_x_train, iris_y_train)
#引入画图相关的包
from IPython.display import Image
from sklearn import tree
#dot是一个程式化生成流程图的简单语言
import pydotplus
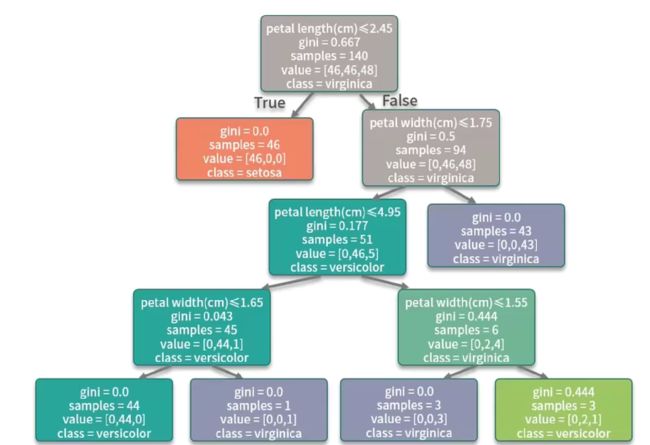
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=iris.feature_names,
class_names=iris.target_names,filled=True, rounded=True,
special_characters=True)
graph= pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
iris_y_predict = clf.predict(iris_x_test)
score=clf.score(iris_x_test, iris_y_test,sample_weight=None)
print('iris_y_predict =')
print(iris_y_predict)
print('iris_y_test =')
print(iris_y_test)
print('Accuracy:', score)
输出代码结果:

随机森林、GBDT、XGBOOST

梯度提升决策树GBDT(Gradient Boosting Decision Tree)也被称为是MART(Multiple Additive Regression Tree))或者是GBRT(Gradient Boosting Regression Tree),也是一种基于集成思想的决策树模型,但是它和Random Forest有着本质上的区别。
不得不提的是,GBDT是目前竞赛中最为常用的一种机器学习算法,因为它不仅可以适用于多种场景,更难能可贵的是,GBDT有着出众的准确率。这也是为什么很多人称GBDT为机器学习领域的“屠龙刀”。
Boosting,迭代,即通过迭代多棵树来共同决策。这怎么实现呢?
难道是每棵树独立训练一遍,比如A这个人,第一棵树认为是10岁,第二棵树认为是0岁,第三棵树认为是20岁,我们就取平均值10岁做最终结论?
当然不是!且不说这是投票方法并不是GBDT,只要训练集不变,独立训练三次的三棵树必定完全相同,这样做完全没有意义。
之前说过,GBDT是把所有树的结论累加起来做最终结论的,所以可以想到每棵树的结论并不是年龄本身,而是年龄的一个累加量。
GBDT的核心就在于:
每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。
那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄。
如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学
如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。这就是Gradient Boosting在GBDT中的意义。
其实从这里我们可以看出GBDT与Random Forest的本质区别,GBDT不仅仅是简单地运用集成思想,而且它是基于对残差的学习的。我们在这里利用一个GBDT的经典实例进行解释。

总结
1、从女神如何决策跟谁约会的问题出发,引出决策树算法的原理
2、研究者提出各种改进方案,并由决策树延伸出了很多新的优秀的算法
3、在尝试动手的环节,加入了一些绘图的技巧
部分参考:http://t.csdn.cn/GfaAS