论文复现-1:bertscore
Bertscore是计算相似度的一种方法。
遗留问题:使用model layer 中的单一层 还是多个层,会对结果造成很大的影响吗?
sent_encode函数是使用tokenizer将句子做encode。
tokenizer.encode(
sent,
add_special_tokens=True,
add_prefix_space=True,
max_length=tokenizer.model_max_length,
truncation=True,
)
get_tokenizer函数和get_model函数是根据model-name调用相应的Model和Tokenizer函数。
tokenizer = AutoTokenizer.from_pretrained(model_type, use_fast=use_fast)
model = AutoModel.from_pretrained(model_type)
整个bertscore是无梯度更新的过程中完成相似度运算的。model的模式是model.eval()
greedy_cos_idf函数是计算P、R和Recall的关键函数。
论文中指明,使用了cosine函数计算sentence之间的similarity score。
正常的cosine sim= x i T x j ∥ x i ∥ ∥ x j ∥ \frac{x_{i}^Tx_{j}}{\left \| x_{i} \right \|\left \| x_{j} \right \| } ∥xi∥∥xj∥xiTxj,
文中使用了pre-normalized 函数,将embedding做了normalize后,使用的是 x i T ∗ x j x_{i}^T *x_{j} xiT∗xj计算的similarity score。
使用的是greedy search函数最大化的similarity score,每个token match到相似度最高的那一个token。(即表格每个token对应行的max 选择操作)
在代码中的实现:
normalize操作:A.div_(B)是A 中每个值除以B的值
ref_embedding.div_(torch.norm(ref_embedding, dim=-1).unsqueeze(-1))#torch.norm(ref_embedding, dim=-1),维度由b*l*d,缩减为b*l。div_(value),将tensor中每个值除以value
hyp_embedding.div_(torch.norm(hyp_embedding, dim=-1).unsqueeze(-1))# unsqueeze(-1)是在tensor中添加一个维度,由b*l变为b*l*1
sim_metric得到:bmm函数
sim = torch.bmm(hyp_embedding, ref_embedding.transpose(1, 2))#torch.bmm函数最终计算得到的是b*l*l的矩阵。 bmm:b*h*m|b*n*h=b*m*n
masks = torch.bmm(hyp_masks.unsqueeze(2).float(), ref_masks.unsqueeze(1).float())
masks = masks.float().to(sim.device)
sim = sim * masks
greedy search操作,参考原文中的公式:注意底标是两个不同的维度。
word_precision = sim.max(dim=2)[0]
word_recall = sim.max(dim=1)[0]
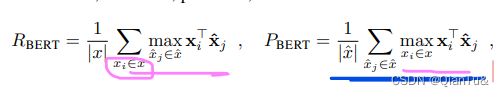
IDF加权操作:
hyp_idf.div_(hyp_idf.sum(dim=1, keepdim=True))
ref_idf.div_(ref_idf.sum(dim=1, keepdim=True))
precision_scale = hyp_idf.to(word_precision.device)
recall_scale = ref_idf.to(word_recall.device)
P = (word_precision * precision_scale).sum(dim=1)
R = (word_recall * recall_scale).sum(dim=1)
F = 2 * P * R / (P + R)
IDF计算,函数详解:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2022/12/18 19:07
# @Author : YOURNAME
# @FileName: get_idf_dict.py
# @Software: PyCharm
from collections import Counter, defaultdict
from functools import partial
from itertools import chain
from math import log
from multiprocessing import Pool
from transformers import AutoTokenizer
tokenizer=AutoTokenizer.from_pretrained('bert-base-chinese')
arr=['空间站应用有效载荷安全性','实验柜通信交换协议','空间站有效载荷安全性、可靠性和维修性']
def process(a, tokenizer=None):
if tokenizer is not None:
a = tokenizer.encode(
a,
add_special_tokens=True,
max_length=tokenizer.model_max_length,
truncation=True,
)
return set(a)
def get_idf_dict(arr, tokenizer, nthreads=0):
"""
Returns mapping from word piece index to its inverse document frequency.
Args:
- :param: `arr` (list of str) : sentences to process.
- :param: `tokenizer` : a BERT tokenizer corresponds to `model`.
- :param: `nthreads` (int) : number of CPU threads to use
"""
idf_count = Counter()
num_docs = len(arr)
process_partial = partial(process,tokenizer=tokenizer)
# if nthreads > 0:
# with Pool(nthreads) as p:
# idf_count.update(chain.from_iterable(p.map(process_partial, arr)))
# else:
idf_count.update(chain.from_iterable(map(process_partial, arr)))# update函数,如果字典中无该键,则添加此键值对,值为数字。如有,则更新值。
# tokenizer.encode()函数每次只能处理一个text,不能一次处理完整个list of str.
idf_dict = defaultdict(lambda: log((num_docs + 1) / (1)))
idf_dict.update(
{idx: log((num_docs + 1) / (c + 1)) for (idx, c) in idf_count.items()}#循环迭代更新idf_dict中的值,值=log()/c+1,在论文中该公式前面有一个负号,转换之后就是当前的公式
)
return idf_dict
idf=get_idf_dict(arr,tokenizer,nthreads=4)
print(idf)
print(idf.keys())
在之前的实验中,是根本没有使用到IDF这一项的,在代码中,这一项默认是False,意味着IDF_dict=[0,1,1,1,1,1…0]。除了CLS和SEP为0 之外,其余的权重值均为1.
若要使用IDF,需设置score参数中的IDF=TRUE,verbalizer=TRUE。
之前的实验结果,也就意味着在不用IDF的情形下,bert score以单个token计算的相似度评分值是可观的。