文本信息常用的关系抽取模型
3.2.4 常用的关系抽取模型
SDP-LSTM
2015年北大的论文《Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths》中提出了一种新的神经网络SDP-LSTM,用于对句子中两个实体之间的关系进行分类。SDP-LSTM的神经体系结构利用了两个实体之间的最短依赖路径(SDP);具有长短期记忆单元的多通道递归神经网络沿着SDP提取异质信息。该模型具有以下特点:(1)最短的依赖路径保留了大部分相关信息(对关系分类),同时剔除了句子中不相关的词。(2)多通道LSTM网络允许异构源在依赖路径上进行有效的信息集成。(3)自定义dropout策略对神经网络进行正则化,以缓解过拟合。实验在SemEval2010关系分类任务上测试了SDP-LSTM的模型,获得了83.7%的f1得分,高于文献中的竞争方法。
SDP-LSTM的算法原理:
以 “A trillion gallons of water have been poured into an empty region of outer space”为例,下图为其依存解析树。红线表示实体水和区域之间的最短依赖路径。边a→b表示a由b governed。依赖类型由解析器标记,但为了清晰起见,图中未显示。
下图是SDP-LSTM的模型构架图:
首先,由斯坦福解析器将句子解析为依赖树,然后提取最短依赖路径(SDP)作为网络的输入。沿着SDP,四种不同类型的信息被作为通道使用,包括单词、POS标签、语法关系和WordNet上位词。(参见图2)。在每个通道中,离散的输入,例如单词,被映射到实值向量,称为嵌入,它捕获输入的潜在含义。
两个RNN网络(图2b)分别沿着SDP的左右子路径拾取信息。(路径由两个实体的共同祖先节点分隔。)长短期记忆(LSTM)单元用于循环网络中有效的信息传播。然后最大池化层从每个路径的LSTM节点收集信息。
来自不同通道的池化层被连接起来,然后连接到一个隐藏层。最后,SDP-LSTM有一个用于分类的softmax输出层。
最短的依赖路径(The shortest dependency path)
依赖解析树自然适合于关系分类,因为它关注的是句子中的动作和代理。此外,如上文所讨论的,实体之间的最短路径浓缩了最有启发性的实体关系信息。
还可以观察到,由两个实体的共同祖先节点分隔的子路径,为关系的方向性提供了强有力的提示。以图1为例。两个实体water和region有它们共同的祖先节点倾倒,它将SDP分成两部分:

第一个子路径获取e1的信息,而第二个子路径主要是关于e2的信息。通过分别检查这两个子路径,我们知道e1和e2是实体-目的地(e1,e2)关系,而不是实体-目的地(e2, e1)关系。
根据上述分析,论文设计了两个RNN网络,它们自下而上地从实体传播到它们共同的源头。通过这种方式,DSPLSTM的模型是方向敏感的。
通道(channels)
论文利用四种类型的信息沿着SDP进行关系分类。我们称它们为通道,因为这些信息源在循环传播期间不相互作用。详细的通道描述如下。
单词表示。通过查询单词嵌入表,将给定句子中的每个单词映射到实值向量。在大型语料库上进行无监督训练的词语嵌入被认为能够很好地捕捉词语的句法和语义信息。
词性标记。由于词嵌入是在一个大规模的通用语料库上获得的,因此其包含的信息可能与特定的句子不一致。我们处理这个问题的方法是将每个输入的单词与其词性标记(例如名词、动词等)联合起来。在我们的实验中,我们只使用了一个粗粒度的POS类别,其中包含15个不同的标签。
语法关系。统治词和它的子词之间的从属关系造成了意义上的差异。同一个词对可能有不同的依赖关系类型。在DSPLSTM的实验中,语法关系被分为19类,主要基于粗粒度分类。
WordNet上位词。如上文所示,上下位关系信息对关系分类也很有用。(此处不再赘述。)为了利用WordNet上位词,DSPLSTM使用了Ciaramita和Altun(2006)开发的工具。该工具从WordNet中的41个预定义概念(如名词)中为每个词指定一个上位词。食物,动词。运动等。有了上名,每个词都有了一个更抽象的概念,这有助于在不同但概念相近的词之间建立联系。
正如所看到的,POS标记、语法关系和WordNet上位词也是离散的(就像单词本身一样)。然而,目前还没有针对POS标签的嵌入学习方法。因此,随机初始化它们的嵌入,并在训练期间以有监督的方式调整它们。研究员注意到,这些信息源包含的符号比词汇量(大于25,000)少得多。因此,研究员认为他们的随机初始化策略是可行的,因为通道可以在有监督的训练中得到充分的调优。
LSTM
RNN网络本质上适合于序列数据的建模,因为它保留了一个隐藏状态向量,并且在每一步都随着输入数据的变化而变化。我们使用递归网络沿着SDP中的每个子路径收集信息(图2b)。
对于子路径中的第t个单词的隐藏状态是它以前的状态ht-1和当前单词xt的函数。传统递归网络具有基本的相互作用,即输入由权矩阵线性变换,并由激活函数非线性压缩。形式上,我们有
其中,Win和Wrec分别为输入连接和递归连接的权值矩阵。bh是隐藏状态向量的偏置项,fh是非线性激活函数(例如,tanh)。
上述模型的一个问题是梯度消失或爆炸。神经网络的训练需要梯度反向传播。如果传播序列(路径)太长,梯度可能会按指数增长或衰减,这取决于Wrec的大小。这就导致了训练的困难。
《The vanishing gradient problem during learning recurrent neural nets and problem solutions.》提出了长短期记忆(LSTM)单元来解决这一问题。其主要思想是引入一种自适应门控机制,该机制决定LSTM单元在多大程度上保持了之前的状态,并记住了提取的当前输入数据的特征。文献中提出了许多LSTM变体。DSPLSTM的方法中采用了《Learning to execute》引入的变体,《Long short-term memory over tree structures》也使用了该变体。
具体来说,基于lstm的RNN网络包括四个组成部分:输入门it、遗忘门ft、输出门和记忆细胞(如图3所示,并通过公式1-6进行了形式化,如下图所示)。
三个自适应门it, ft和ot取决于先前的状态ht-1和电流输入xt(公式1 - 3)。根据公式4计算提取的特征向量gt作为候选记忆单元。

当前记忆细胞ct是先前细胞内容ct−1和候选内容gt的组合,分别由输入门it和遗忘门ft加权。(见下式5)
LSTM单元的输出为递归网络的隐藏状态,由式6计算得到。
式中,σ为二阶函数,⊗为逐元乘法。
Dropout 策略
需要一种良好的正则化方法来缓解过拟合。Dropout是由Hinton等人(提出的,在前馈网络中已经非常成功。通过在训练过程中随机地从网络中省略特征检测器,可以获得无相互依赖的网络单元,从而获得更好的性能。然而,传统的dropout算法在带有LSTM单元的递归神经网络中并不能很好地工作,因为dropout可能会损害记忆单元的宝贵记忆能力。
由于文献中关于如何退出LSTM单元没有共识,论文尝试了以下几种Dropout策略,用于SDP-LSTM网络:
•Dropout embeddings
•在记忆单元内部Dropout,包括it、gt、ot、ct、ht
•在倒数第二层进行Dropout
正如前文中看到的,放弃LSTM单元对我们的模型是不利的,而其他两种策略可以提高性能。
下面的方程形式化了嵌入层上的Dropout操作,其中D表示退出算子。嵌入向量xt中的每个维度都设置为零,并具有预定义的Dropout率。
训练目标
上面描述的SDP-LSTM沿着从实体到(两个实体的)共同祖先节点的子路径传播信息。最大池化层将每个子路径的递归网络状态h打包成一个固定的向量,方法是在每个维度取最大值。
这种体系结构适用于所有通道,即单词、POS标记、语法关系和WordNet上位词。这些通道中的池向量被连接起来,并提供给一个完全连接的隐藏层。最后,我们添加了一个用于分类的softmax输出层。训练目标为惩罚交叉熵误差,为
其中t∈Rnc为one-hot编码表示的ground truth(正确的数据), y∈Rnc为softmax对每个类的估计概率。||·||F为矩阵的Frobenius范数,ω和υ为权重矩阵的个数(分别为W和U)。λ是一个超参数,它指定权重惩罚的大小。
在英语维基百科语料库上通过word2vec预先训练单词嵌入;其他参数是随机初始化的。DSPLSTM使用随机梯度下降(minibatch 10)进行优化;梯度是通过标准的反向传播来计算的。培训细节将在第4.2节中进一步介绍。
实验
DSPLSTM实施建立在《Discriminative neural sentence modeling by tree-based convolution》的基础上。
数据集
SemEval-2010 Task 8数据集是关系分类中广泛使用的基准。数据集包含8000个用于训练的句子,2717个用于测试的句子。实验从训练集中分离出1/10的样本用于验证。
目标包含19个标签:9个有向关系和一个无向Other类。有向关系列表如下。
•因果关系
•组件-整体
•内容-容器
•实体-目的地
•实体-起源
•消息-主题
•成员-集合
•工具-代理
•产品-生产商
下面是两个有向关系的例句。
数据集还包含一个无向Other类。因此总共有19个目标标签。无向Other类不属于上述类别的实体,如下例所示。

实验使用官方的f1宏观平均分数来评估模型的表现。这个官方测量不包括“Other关系”。但是在实验中并没有特别对待Other 类,这在其他研究中是很典型的。
实验结果
Hendrickx 等人(2010《Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals.》)利用各种手工特征,并使用SVM进行分类,f1得分为82.2%。
神经网络首次用于这项任务是在Socher 等人 (2012《Semi-supervised recursive autoencoders for predicting sentiment distributions.》)。他们沿着选区树建立RNN进行关系分类。他们将基本RNN扩展为矩阵-向量交互,f1得分为82.4%。
Zeng 等人(2014《Relation classification via convolutional deep neural network.》)将句子作为序列数据,利用卷积神经网络(CNN);他们还将单词位置信息整合到他们的模型中。Santos等人(2015《Classifying relations by ranking with convolutional neural networks.》)设计了一个名为CR-CNN的模型;他们提出了一个基于排名的成本函数,并精心减少了“other类”的影响,而“other类”在官方的f1测量中没有被计算在内。通过这种方式,他们取得了最先进的结果,f1得分为84.1%。如果没有这样的特殊待遇,他们的f1得分是82.7%。
Yu等人(2014《Factor-based compositional embedding models.》)提出了一种用于关系分类的特征丰富的成分嵌入模型(FCM),该模型结合了非词汇化的语言上下文和单词嵌入。他们的f1得分为83.0%。
SDP-LSTM模型的f1得分为83.7%。在具有交叉熵误差的softmax条件下,该方法优于现有的竞争方法。
值得注意的是,论文还进行了两个对照实验:(1)不含LSTM单元的传统RNN, f1得分为82.8%;(2) LSTM网络覆盖整个依赖路径(而不是两个子路径),f1得分为82.2%。这些结果证明了LSTM在关系分类中的有效性和方向性。
不同Channels的影响
实验还分析了不同的Channels如何影响模型。实验首先使用单词嵌入作为基线;然后分别添加POS标签、语法关系和WordNet上位词,实验还将所有这些通道合并到模型中。请注意,实验并没有单独尝试后三个通道,因为每一个通道(例如,POS)并不携带太多信息。
从表2中可以看出,SDP-LSTM单词嵌入的性能达到了82.35%,而CNN 69.7%, RNN 74.9-79.1%,FCM 80.6%。
添加语法关系或WordNet上位词比其他现有方法性能更好(这里不考虑数据清理)。POS标签的信息量相对较小,但仍能使f1得分提高0.63%。
可以注意到,当通道合并时,增益并不是简单地添加。这表明这些信息源在语言的某些方面是互补的。然而,综合上述四个渠道,f1得分将进一步升至83.70%。

结论:
SDP-LSTM提出了一种新的用于关系分类的神经网络模型。它沿着最短的依赖路径迭代地学习关系分类的特征。沿着路径使用几种类型的信息(单词本身、POS标记、语法关系和WordNet上位词)。同时,利用LSTM单元进行远程信息传播和集成。通过在SemEval-2010关系分类任务上对SDP-LSTM模型进行评估,证明了SDP-LSTM的有效性,优于现有的先进方法(在没有数据清理的公平条件下)。实验的结果为以下关系分类任务提供了一些启示。
•最短依赖路径是关系分类的宝贵资源,涵盖了目标关系的大部分充分信息。
•由于自然语言固有的歧义性和句子表达的多样性,分类关系是一项具有挑战性的任务。因此,整合异质语言知识对完成任务是有帮助的。
•将最短的依赖路径视为两个子路径,映射两个不同的神经网络,有助于捕捉关系的方向性。
•LSTM单元能够有效地沿着最短的依赖路径进行特征检测和传播
Att-BiLSTM
2015年中国科学院发表的论文《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification》中提出了基于注意力机制的BiLSTM网络(Att-BiLSTM)用于关系分类,它可以利用BiLSTM和Attention机制,该机制可以自动关注对分类有决定性影响的单词,从而捕获句子中最重要的语义信息,而无需使用额外的知识和NLP系统。
Att-BiLSTM算法原理:
模型主要由五个部分组成:
(1) 输入层:在此模型中输入句子;
(2) 嵌入层:将每个单词映射到低维向量中;
给定一个由T个单词S={x1,x2,…,xT}组成的句子,每个单词xi都转换为实值向量ei。对于S中的每个单词,我们首先查找嵌入矩阵Wwrd∈ Rdw | V |,其中V是固定大小的词汇表,dw是单词嵌入的大小。矩阵Wwrd是需要学习的参数,dw是需要用户选择的超参数。我们使用矩阵向量积将单词xi转换为单词嵌入ei: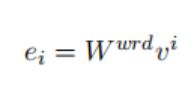
其中,vi是大小为| V |的向量,其在索引ei处的值为1,在所有其他位置的值为0。然后句子作为实值向量embs={e1,e2,…,eT}馈送到下一层。
(3) LSTM层:利用BiLSTM从步骤(2)中获取高级特征;
采用Graves等人(2013)引入的一种变体,该变体将恒定错误转盘(CEC)的加权peephole connections添加到同一内存块的门。通过直接使用当前单元状态生成门度,peephole connections允许所有门进入单元进行检查(即当前单元状态),即使输出门关闭
通常,四个组件组合基于LSTM的递归神经网络:一个输入门it与相应的权重矩阵Wxi、Whi、Wci、bi;一个遗忘门ft,对应权重矩阵Wxf、Whf、Wcf、bf;一个输出门ot具有相应的权重矩阵Wxo、Who、Wco、bo,所有这些门都设置为生成一定的度,使用当前输入xi,状态hi−1生成的上一步骤,以及此单元格的当前状态ci−1(窥视孔),用于决定是否进行输入,忘记之前存储的内存,并输出以后生成的状态。
(4) Attention层:生成权重向量,将每个时间步的单词级特征乘以权重向量,合并成句子级特征向量;
(5) 输出层:最终使用句子级特征向量进行关系分类。
(4)Attention层:
设H是由LSTM层产生的输出向量[h1,h2,…,hT]组成的矩阵,其中T是句子长度。句子的表示r由这些输出向量的加权和构成:
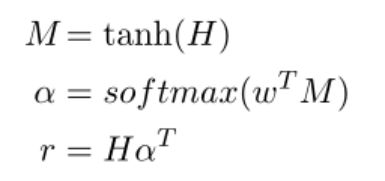
其中H∈ Rdw×T,dw是词向量的维数,w是经过训练的参数向量,wT是转置。w,α,r的维数分别为dw,T,dw
从下式获取用于分类的最终句子对表示:
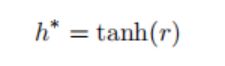
(5)输出层:将最后一层的句子级别的特征向量用于关系分类
使用softmax分类器从一组离散的类y中为句子S预测标签yˆ。该分类器采用隐藏状态h∗ 作为输入:

实验结果:
实验数据集为 SemEval-2010 Task 8,该数据集包含8000个训练句子,2717个测试句子,一共包含9个关系类和一个Other关系类,若考虑关系双向性则可认为是19个类。
Att-BiLSTM模型的F1得分为84.0%。它的性能优于大多数现有的竞争方法,无需使用词汇资源(如WordNet)或NLP系统(如依赖项解析器和NER)来获取高维度特征。实验结果如下图所示:
结论:
本文提出了一种新的关系分类神经网络模型Att BLSTM。该模型不依赖NLP工具或词法资源,而是使用带有位置指示器的原始文本作为输入。通过在SemEval-2010关系分类任务中对模型进行评估,证明了Att-BiLSTM的有效性。
PCNN
2015年中国科学院发表论文《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》,论文中提出了一种新型的关系抽取模型PCNN。
在使用远程监控进行关系提取时,会出现两个问题。首先,该方法将已有的知识库与文本进行对齐,对齐结果作为标记数据处理。然而,对齐可能会失败,导致错误的标签问题。此外,在以前的方法中,统计模型通常应用于特殊特征。特征提取过程中产生的噪声可能会导致性能不佳。
为了解决这两个问题,提出了一种称为分段卷积神经网络(PCNNs)的多实例学习模型。为了解决第一个问题,将远程监督关系抽取视为一个多实例问题,其中考虑了实例标签的不确定性。为了解决后一个问题,PCNN避免了特征工程,而是采用具有分段最大池的卷积体系结构来自动学习相关特征。
PCNN用于自动学习特征,无需复杂的NLP预处理。下图显示了用于远程监督关系提取的神经网络体系结构。它说明了处理一个实例的过程。该过程包括四个主要部分:向量表示(Vector Representation), 卷积层(Convolution), 成对最大池化(Piecewise Max Pooling) 和 softmax输出(Softmax Output)
向量表示:
网络的输入是原始单词标记。使用神经网络时,通常将单词标记转换为低维向量。在PCNN方法中,通过查找预训练的单词嵌入,将每个输入单词标记转换为一个向量。此外,PCNN还使用位置特征(PFs)指定实体对,并通过查找位置嵌入将实体对转换为向量。
词嵌入(word embeddings):单词嵌入是单词的分布式表示,将文本中的每个单词映射到“k”维实值向量。使用skip-gram模型来训练词向量
位置嵌入(position embeddings):使用PFs(位置特征)指定实体对。PF定义为当前单词到e1和e2的相对距离的组合。
如下图,单词son到实体Kojo Annan和Kofi Annan的相对距离分别为3和-2。

随机初始化两个位置嵌入矩阵(PF1和PF2),然后通过查找位置嵌入矩阵将相对距离转换为实值向量。图中词嵌入的维度dω=4,位置嵌入的维度dp=1。结合词嵌入和位置嵌入,句向量表示为
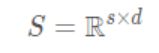
其中,s 是句子长度(单词数),d = dω+ d p ∗ 2
卷积:
在关系提取中,标记为包含目标实体的输入句子仅对应于关系类型;它不会预测每个单词的标签。因此,可能需要利用所有局部特征并全局执行该预测。当使用神经网络时,卷积方法是很好的合并所有这些特征的方法。
卷积是权重向量w和被视为序列q的输入向量之间的运算。权重矩阵w被视为卷积的filter。在图3所示的示例中,我们假设filter的长度为w(w=3);因此,w∈ Rm(m=w∗d) 。我们认为S是序列{q1,q2,··,qs},其中qi∈ Rd.一般来说,让qi:j表示qi到qj的连接。卷积运算涉及取w与序列q中每个w-gram的点积,以获得另一个序列c∈ R s+w-1:
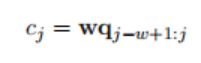
其中,指数j的范围为1到s+w−1.超出范围的输入值qi,其中i<1或i>s,取零。捕获不同特征的能力通常需要在卷积中使用多个滤波器(或特征映射)。假设我们使用n个滤波器(W={w1,w2,··,wn}),卷积运算可以表示为以下形式:
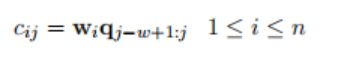
卷积结果是矩阵C={c1,c2,···,cn}∈ Rn×(s+w−1). 图3显示了在卷积过程中使用3个不同滤波器的示例
成对最大池化
卷积输出矩阵C∈ Rn×(s+w−1)的大小取决于输入网络的句子中令牌的数量。为了应用后续层,必须组合卷积层提取的特征,使其与句子长度无关。
尽管单个最大池被广泛使用,但这种方法不足以进行关系提取。单个最大池将隐藏层的大小降低得太快,太粗,无法捕获细粒度特征以进行关系提取。此外,单个最大池不足以捕获两个实体之间的结构信息。在关系提取中,输入句子可以根据所选的两个实体分为三个部分。因此,PCNN提出了一种分段最大池化过程,该过程返回每个段中的最大值,而不是单个最大值。
如上图所示,Kojo Annan 和 Kofi Annan将每个卷积滤波器ci的输出分成三段{ci1、ci2、ci3}。分段最大池过程可以表示为:
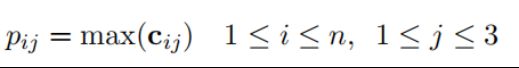
对于每个卷积滤波器的输出,可以获得三维向量pi={pi1,pi2,pi3}。然后,连接所有向量p1:n并应用非线性函数,例如双曲正切。最后,分段最大池过程输出一个向量:
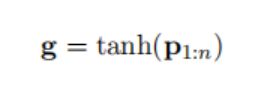
其中g∈ R3n。g的大小是固定的,不再与句子长度相关。
softmax输出
最后经过softmax并输出
为了缓解错误标签问题提出多实例学习
为了缓解错误标签问题,对PCNN使用多实例学习。基于PCNNs的关系提取可以表示为五元组θ=(E,PF1,PF2,W,W1)。进入网络的是一个bag。假设有T个bag{M1,M2,··,MT},并且第i个bag包含qi实例Mi={m1 i,m2 i,··,mqi i}。多实例学习的目标是预先记录看不见的bag的标签。在本文中,一个bag中的所有实例都是独立考虑的。给定输入实例mj i,具有参数θ的网络输出向量o,其中第r分量或对应于与关系r相关的分数。为了获得条件概率p(r | m,θ),对所有关系类型应用softmax运算:
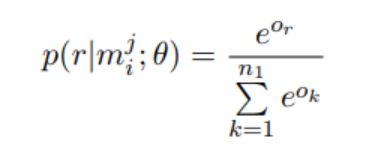
多实例学习的目标是区分bag而不是实例。为此,我们必须定义bsg的目标函数。给定所有(T)个训练bag(Mi,yi),我们可以在包级别使用交叉熵定义目标函数,如下所示:

使用该定义的目标函数,使用Adadelta(Zeiler,2012)更新规则通过随机梯度下降在mini-batches上最大化J(θ)。整个训练过程在算法1中描述。从上述介绍中,可以知道传统的反向传播算法根据所有训练实例修改网络,而带有多实例学习的反向传播修改基于bag的网络。因此,PCNN方法捕捉到了远程监督关系提取的本质,其中一些训练实例将不可避免地被错误标记。当使用经过训练的PCNN进行预测时,当且仅当网络在其至少一个实例上的输出被分配正标签时,才对bag进行正标签。
实验结果:
实验选用NYT corpus作为数据集,得到如下图所示的实验对比结果。为了评估所提出的方法,实验选择以下三种传统方法进行比较。Mintz代表了(Mintz 等人,2009)提出的一种基于距离监控的传统模型。MultiR是由(Hoffmann 等人,2011)提出的一种多实例学习方法。MIML是由(Surdeanu 等人,2012)提出的多实例多标签模型。图4显示了每种方法的精度召回曲线,其中PCNNs+MIL表示PCNN方法,并证明PCNNs+MIL在整个召回范围内实现了更高的精度。PCNNs+MIL将召回率提高到大约34%,而不会损失任何精度。在精确度和召回率方面,PCNNs+MIL优于所有其他评估方法。值得注意的是,评估用于比较的方法的结果是使用手工制作的特征获得的。相比之下,PCNN结果是通过自动学习原始单词的特征来获得的。结果表明,该方法是一种有效的远程监督关系提取方法。通过PCNN自动学习特征可以缓解传统特征提取中出现的错误传播。将多实例学习合并到卷积神经网络中是解决错误标签问题的有效方法。
值得强调的是,在非常低的召回率下,PCNNs+MIL的保持精度召回曲线急剧下降(图4)。对高置信度生成的错误分类示例进行手动检查后发现,这些示例中的大多数是误判,实际上是由于Freebase的不完整性而错误分类的真实关系实例。因此,保留的评估在Freebase中会出现错误否定。我们执行手动评估以消除这些问题。对于手动评估,PCNN选择至少一个参与实体在Freebase中不存在的实体对作为候选。这意味着持有的候选人和手工候选人之间没有重叠。由于测试数据中表示的关系实例的数量未知,因此我们无法计算这种情况下的召回率。相反,我们计算前N个提取的关系实例的精度。表2显示了前100、前200和前500个提取实例的手动评估精度。结果表明,PCNNs+MIL的性能最好;此外,精度高于所进行的评估。这一发现表明,我们预测的许多错误否定事实上是真实的相关事实。因此,在保持精度召回曲线中观察到的急剧下降是合理的。

PCNN提出了一种分段最大池的方法,并将多实例学习融入到卷积神经网络中,用于远程监督关系提取。为了证明这两种技术的效果,实验通过Held-out评估来实证研究这些技术未实现的系统的性能(图5)。CNNs表示应用单个最大池的卷积神经网络。图5显示,当使用PCNNs时,会产生比使用CNN更好的结果。此外,与CNNs+MIL相比,当召回率大于0.08时,PCNNs的准确率略高。由于所有模型的参数都是通过网格搜索确定的,因此可以观察到,当增加卷积神经网络的隐层大小时,CNN无法获得与PCNN相比的竞争结果。这意味着我们无法通过简单地增加网络参数来捕获更多有用的信息。这些结果表明,所提出的分段最大池技术是有益的,可以有效地捕获结构信息以进行关系提取。在网络中加入多实例学习时,也观察到类似的现象。CNNs+MIL和PCNNs+MIL分别优于CNNs和PCNNs,从而证明将多实例学习纳入神经网络能够成功地解决错误标签问题。正如预期的那样,PCNNs+MIL获得了最佳结果,因为这两种技术的优势是同时实现的。
结论:
利用具有多实例学习的分段卷积神经网络(PCNN)进行远程监督关系提取,在PCNN的方法中,无需复杂的NLP预处理即可自动学习特征。PCNN还成功地在所提出的网络中设计了一个分段最大池层来捕获结构信息,并结合多实例学习来解决错误标签问题。实验结果表明,与同类方法相比,该方法具有显著的改进。
参考文献:
李冬梅,张扬,李东远,林丹琼 .实体关系抽取方法研究综述[J]. 计算机研究与发展,2020,57(7)
Yan Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, Zhi Jin,“Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths ,” arXiv:1508.03720v1 [cs.CL] 15 Aug 2015
Daojian Zeng, Kang Liu, Yubo Chen and Jun Zhao,“Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks ,” Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1753–1762
Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao, Bo Xu,“Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classifification ,” Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 207–212