机器学习:集成学习
定义:通过训练多个个体学习器,及一定的结合策略,形成最终的强学习器;
分类:
- 同质:个体学习器种类一样;
boosting系列(提升):个体学习器存在强依赖关系,串行生成--Adaboost\GBDT\Xgboost
bagging系列(装袋):个体学习器相互独立,并行生成--bagging\随机森林 - 异质:个体学习器种类不一样;
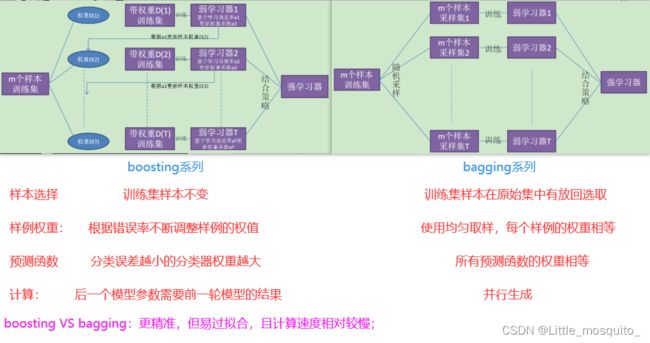
结合策略:
- 平均法:数值类的回归问题;
算数平均:bagging
加权平均:boosting - 投票法:分类问题;
相对多数投票:bagging
加权投票:boosting - 学习法:前一级的输出是后一级的输入; stacking
一、AdaBoost
Adaboost对于噪音数据和异常数据敏感,在每次迭代时候会给噪声点 较大的权重;
1、AdaBoost自适应的三个方面
- 自适应的调整样本权重;
- 自适应的调整算法权重;-- 投票
- 自适应的调整弱学习器的数量;
2、AdaBoost训练过程
初始化样本权重值:初始化相等,每个样本权重1/m(m:样本个数),训练第一个弱学习器;
计算错误率:

计算弱学习器的权重:

更新样本权重:针对第一次被学习错的样本,在接下来的学习中可以重点学习;

重复进行学习:用更新后的样本权重训练第二个弱学习器,同时计算第二个弱学习器的错误率,得到算法权重和样本权重;结合前面弱学习器的结果,若达到要求,自动停止,若未达到要求,重复上述过程,直到达到最大弱学习器数量;
算法输出:

3、AdaBoost预测过程
把样本同时送入t个若学习器,将得到的结果乘以对应的算法权重,累计得到最终的预测结果;
4、sklearn实现
sklearn.ensemble.AdaBoostClassifier — scikit-learn 1.2.0 documentation
sklearn.ensemble.AdaBoostRegressor — scikit-learn 1.2.0 documentation

![]()
- estimator:object, default=None:弱学习器:默认深度为1的决策树;
- n_estimators:int, default=50:弱学习器最大数量;
- learning_rate:float, default=1.0:学习率:防止过拟合(后一个学习器不要把前一个学习的误差全部补回来,只学习部分误差),但会增加弱学习器数量(需要和n_estimators一块调);
参数的输出:
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
iris = load_iris()
clf = AdaBoostClassifier(n_estimators=100)
clf = clf.fit(iris.data, iris.target)
clf.score(iris.data, iris.target)
clf.base_estimator_ # 单个的弱学习器类型
clf.estimators_ # 所有的弱学习器
len(clf.estimators_) # 100个弱学习器
clf.estimator_errors_ # 每个弱学习器的误差
clf.feature_importances_ # 输出特征的重要性,可用于特征选择训练预测模型:
# Adaboost预测病马死亡率
import numpy as np
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from sklearn.metrics import accuracy_score
# 训练集
train_data=pd.read_table("horseColicTraining.txt",sep=' ',names=range(22))
trainingSet=train_data.iloc[:,0:21] # 训练的特征
trainingLabels=train_data.iloc[:,21:] # 训练的标签
# 测试集
test_data=pd.read_table("horseColicTest.txt",sep=' ',names=range(22))
testSet=test_data.iloc[:,0:21]
testLabels=test_data.iloc[:,21:]
ada = AdaBoostClassifier()
ada.fit(trainingSet, trainingLabels)
ada.score(testSet,testLabels)
# 对框架内的参数进行调优
from sklearn.model_selection import GridSearchCV
param_grid = {"n_estimators": np.arange(10,200,20),'learning_rate':np.linspace(0.001,0.2,10)}
ada = AdaBoostClassifier()
grid_search_ada = GridSearchCV(ada, param_grid=param_grid, cv=10,verbose=2,n_jobs=-1)
grid_search_ada.fit(trainingSet, trainingLabels)
grid_search_ada.best_params_
grid_search_ada.score(testSet,testLabels) # 调优后结果
# 对基于学习器中的参数进行调优(一般不需要)
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings("ignore")
ada = AdaBoostClassifier(base_estimator=DecisionTreeClassifier())
param_grid = {"base_estimator__max_depth":[1,2,3],
"n_estimators": np.arange(10,200,20),
'learning_rate':np.linspace(0.001,0.2,10)}
grid_search_ada = GridSearchCV(ada,param_grid=param_grid,cv=10,verbose=2,n_jobs=-1)
grid_search_ada.fit(trainingSet, trainingLabels)
grid_search_ada.best_params_
grid_search_ada.score(testSet,testLabels)
# 决策树模型对比
from sklearn import tree
dtree = tree.DecisionTreeClassifier()
dtree.fit(trainingSet, trainingLabels)
dtree.score(testSet,testLabels)
二、随机森林
随机森林算法是一种重要的基于bagging的集成学习方法;
1、随机森林的生成:
(样本随机、特征随机;不容易过拟合,且具有很好的抗噪声能力,对缺省值不敏感)
- 从样本集(m)中通过自助采样(随机且有放回地)的方式产生m个 样本;
当样本量足够大,约有1/e的样本未被抽到,此部分称为袋外样本; - 假设样本特征数目为n(属性),随机选择n个中的n ′个特征,输入决策树训练模型;
- 重复t次,产生t棵决策树;
- 多数投票机制来进行预测;
2、随机森林分类效果(错误率)影响因素
- 森林中任意两棵树的相关性:相关性越大,错误率越大;--越小越好
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低;--越大越好
减小特征选择个数n ′ ,树的相关性和分类能力也会相应的降低;增大n ′ ,两者也会随之增大,所以关键问题是如何选择最优的n ′;
3、根据袋外误差选择最优的n ′
随机森林对袋外样本的预测错误率被称为袋外误差;
计算流程:
- 对于每个样本,计算它作为袋外样本的树对它的分类情况
- 以投票的方式确定该样本的分类结果
- 将误分类样本个数占总数的比率作为随机森林的袋外误差
4、sklearn实现
sklearn.ensemble.RandomForestClassifier — scikit-learn 1.2.0 documentation

n_estimators:int, default=100; -- 学习器数量
criterion:{“gini”, “entropy”, “log_loss”}, default=”gini”; -- 分裂准则
max_features:{“sqrt”, “log2”, None}, int or float, default=”sqrt”;; -- 特征数量
bootstrap:bool, default=True; -- 样本随机
oob_score:bool, default=False; -- 是否计算袋外准确率
class_weight:{“balanced”, “balanced_subsample”}, dict or list of dicts, default=None; -- 权重
# 随机森林预测病马死亡率
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import tree
# 训练集
train_data=pd.read_table("horseColicTraining.txt",sep=' ',names=range(22))
trainingSet=train_data.iloc[:,0:21] # 特征
trainingLabels=train_data.iloc[:,21:] # 标签
# 测试集
test_data=pd.read_table("horseColicTest.txt",sep=' ',names=range(22))
testSet=test_data.iloc[:,0:21]
testLabels=test_data.iloc[:,21:]
# 训练模型
RF = RandomForestClassifier(oob_score=True)
RF.fit(trainingSet, trainingLabels)
# 结果
RF.oob_score_ # 袋外准确率
RF.score(testSet,testLabels)
学习器的数量和袋外准确率的关系:单调递增,但达到一定值后,精度提升不在明显;
import warnings
warnings.filterwarnings("ignore")
scores=[]
for i in range(2,200):
RF = RandomForestClassifier(n_estimators=i,oob_score=True,n_jobs=-1)
RF.fit(trainingSet, trainingLabels)
scores.append(RF.oob_score_)
plt.plot(range(2,200),scores) # 弱学习器数量跟袋外准确率的关系
plt.show()特征数量跟袋外准确率的关系:随特征数量增大,袋外准确率先增大,后减小;
import warnings
warnings.filterwarnings("ignore")
scores=[]
for i in range(1,22):
RF = RandomForestClassifier(n_estimators=100,max_features=i,oob_score=True)
RF.fit(trainingSet, trainingLabels)
scores.append(RF.oob_score_)
plt.plot(range(1,22),scores)
plt.show()学习器数量&特征数量一块调优:
import warnings
warnings.filterwarnings("ignore")
scores=[]
for i in range(1,22):
for j in range(2,10):
RF = RandomForestClassifier(n_estimators=100,max_features=i,max_depth=j,oob_score=True)
RF.fit(trainingSet, trainingLabels)
scores.append([i,j,RF.oob_score_])
scores[scores[:,2].argmax()] # 返回最大score所对应的参数
# 训练模型
RF = RandomForestClassifier(n_estimators=100,max_features=2,max_depth=4,random_state=3)
RF.fit(trainingSet, trainingLabels)
RF.score(testSet,testLabels) 特征重要性:
原理:若给某个特征随机加入噪声之后,袋外的准确率大幅度降低,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高;
方法:计算单颗数的袋外数据误差(err00B1);对袋外数据特征x加入噪声干扰,计算袋外误差(err00B2),计算(err00B2-rr00B1),求和取平均;
feature_importances_ :输出特征重要性,常用于特征选择;
feature_importances_ .argsort()[::-1] :返回特征重要性排序;
5、随机森林的优缺点
优点:
- 不易过拟合;
- 能够处理高维特征的输入样本,不需要降维,且评估各个特征在分类问题上的重要性;
- 对缺失值不敏感;
- 有效的运行在大数据上;
缺点:
- 对于回归问题,表现不是很好,输出非连续变量,不能够作出超越训练集数据范围的预测;
- 对噪声敏感,易过拟合;
- 无法控制模型内部的运行,像一个黑盒子;
三、Stacking、Bigging、Voting
1、Stacking原理
将训练集弱学习器的学习结果作为输入,重新训练一个学习器来得到最终结果;

2、sklearn
sklearn.ensemble.BaggingClassifier — scikit-learn 1.2.0 documentation

Stacking:
from mlxtend.classifier import StackingClassifier
#初级
knn = KNeighborsClassifier()
dt = DecisionTreeClassifier()
lr = LogisticRegression()
# 次级分类器
meta = LogisticRegression()
Sta = StackingClassifier(classifiers=[knn, dt, lr], meta_classifier=meta) # 两层
Sta.fit(trainingSet,trainingLabels)
Sta.score(testSet,testLabels)Bagging:
# 只有样本随机
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
#训练集
train_data=pd.read_table("horseColicTraining.txt",sep=' ',names=range(22))
trainingSet=train_data.iloc[:,0:21]
trainingLabels=train_data.iloc[:,21:]
# 测试集
test_data=pd.read_table("horseColicTest.txt",sep=' ')
testSet=test_data.iloc[:,0:21]
testLabels=test_data.iloc[:,21:]
knn=KNeighborsClassifier() # 基学习器用knn,默认是决策树
Bag=BaggingClassifier(knn,n_estimators=100,max_samples=0.9)
Bag.fit(trainingSet,trainingLabels)
Bag.score(testSet,testLabels)Voting:
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
# 定义三个不同的分类器
knn = KNeighborsClassifier()
dt = DecisionTreeClassifier()
lr = LogisticRegression()
# 投票
Vot = VotingClassifier([('knn',knn),('dtree',dt), ('lr',lr)]) # 投票
Vot.fit(trainingSet,trainingLabels)
Vot.score(testSet,testLabels)
Kaggle: Your Machine Learning and Data Science Community
天池大数据众智平台-阿里云天池