基于卷积神经网络和投票机制的三维模型分类与检索 2019 论文笔记
作者:白静
计算机辅助设计与图形学学报
1、解决的问题
由于三维模型投影得到的视图是由不同视点得到,具有相对独立性,这种像素级的融合运算并没有直接的物理或者几何意义,更有可能造成图像有益信息淹没和混淆。
2、创新点
提出基于卷积神经网络和投票机制的三维模型分类和检索算法。
3、优点
这种加权投票的分类思想既确保了三维物体各个视图间的相对独立性,又避免个别有歧义视图对物体类别判断的误导。
4、缺点
本文算法存在局部特征识别及细分类能力较弱的问题.,无法有效区分table和desk这些模型所属类别。
5、算法原理
首先,利用多视图表征3D模型;
其次,利用卷积神经网络完成基于视图的处不识别;
最后,通过决策层的加权投票完成3D模型的最终分类,以避免像素级的视图融合,突出多数有效视角,减小少数不佳视角干扰,仅为提高三维模型的分类能力。
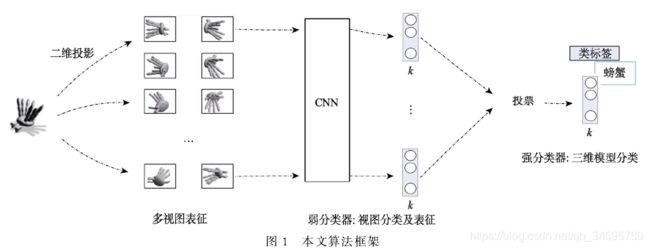
5.1、多视图表征
本文采用Su-MVCNN所提出的12视图渲染方式构建给定网络模型M的多视图表征V(M)
5.2、弱分类器:视图分类及表征
考虑到3D模型库的规模及视图的复杂性,选用Jia提出的C阿飞飞Net作为面向单个二维视图分类及表征的深度学习模型。
该网络共包含8层,其中前5层是卷积层,中间是2个全连接层,最后一层为网络输出层FC8和Softmax分类层。
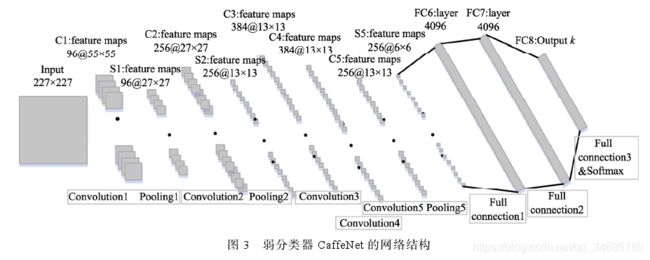
此训练分为2步:
首先利用ImageNet图像资源作为输入,对CaffeNet进行预训练;
然后采用3D模型渲染的二维视图作为输入对获得的网络模型进行微调,使最终获得的网络模型有效适应3D模型对应的二维视图。
训练好后,给定3D模型M的单个视图vl,以FC8层的输出Dl作为该视图的特征描述,其中k为类的数目;以softMax层输出结果Pl作为分类结果,即视图属于各个类的概率。
5.3、强分类器:基于投票的三维模型分类
给定3D模型M多视图表征中每个视图属于各个类别的概率,以其为输入,构建强分类器,完成三维模型的分类。设依据视图属于每个类的概率分布情况,计算类i所获视图投票知为Tvote,k为类的数目,则模型M的分类结果为

(1)概率投票法
将3D模型各个视图属于某类的概率值Pil作为投票值,累加计算wi所获投票,设n为单个模型视图数目
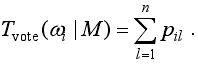
(2)0-1投票法
依据Pil来看,3d模型最可能属于哪个类就给哪个类投出一票;若3D模型以相近似的概率属于多个类,则给这几个类都投出一票。

其中, 是阈值;Lk(Pl)表示视图vl属于各类概率Pl中的第k大元素
是阈值;Lk(Pl)表示视图vl属于各类概率Pl中的第k大元素
(3)加权0-1投票法
对于0-1投票法,有的视图可能投了多票具有不公平性。为此提出加权0-1投票法
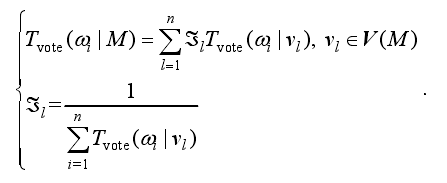
其中,视图vl的权重为其投票数目的倒数,来确保各个视图在投票中的相对平等地位。
5.4、距离度量方法
(1)A2A:视图集V(x)内每个视图到V(y)内所有视图的最短距离的平均值作为模型x到y之间的距离
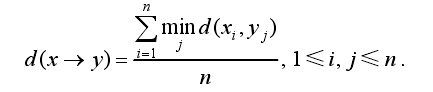
(2)MiniA2A:视图集V(x)内每个视图到V(y)内所有视图的最小距离作为模型x到y之间的距离
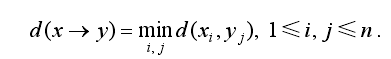
(3)V2A:只考虑投票正确的视图间的距离,用视图集V(x)内投票正确的视图同视图集V(y)内投票正确的视图间距离的平均值作为模型x到y之间的距离
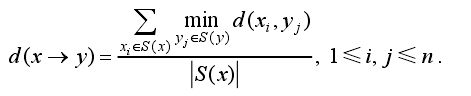
(4)V2V:只考虑投票正确的视图间的距离,用视图集V(x)内投票正确的视图同视图集V(y)内投票正确的视图的最小距离作为模型x到y之间的距离
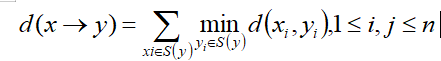
6、实验设计
6.1、分类实验
(1)视图选取实验
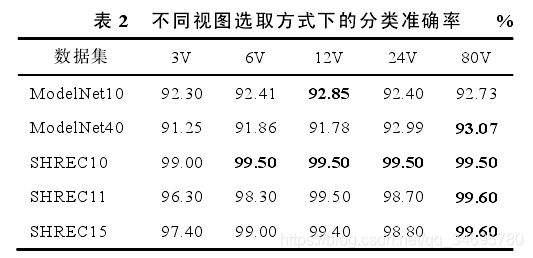
3V表示3视图,从结果整体来看,12V和80V取得了最好的分类效果。在非刚性数据集上,这两种方向相当,在刚性数据集上,模型数目较少的12V由于80V;在数目较多时80V优于12V
(2)投票方式选取实验
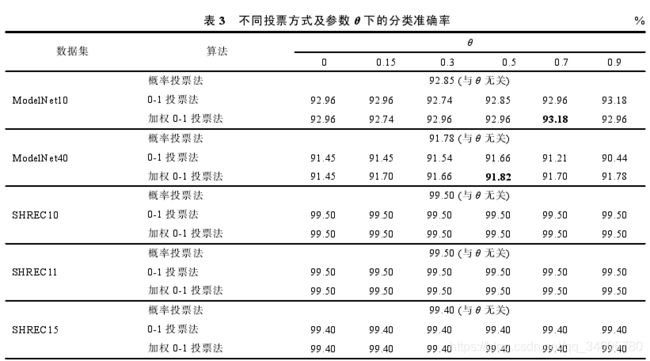
由表3可知,概率投票法不需要设置任何参数,最为鲁棒,分类性能与其他两种方法相当。
无论选用哪种投票方式,参数如何选取,非刚性三维模型数据集都较为鲁棒。说明非刚性数据集的模型特征信息比较丰富。上表得出,ModelNet10 ,ModelNet40,SHREC10,SHREC11,SHREC15的取值依次为0.7,0.5,0,0,0
(3) 基于视图的分类算法的对比试验
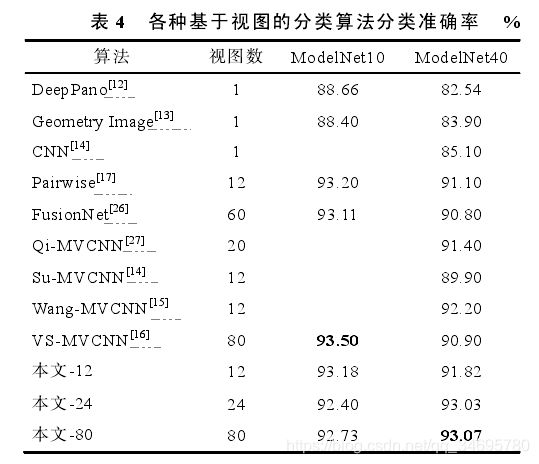
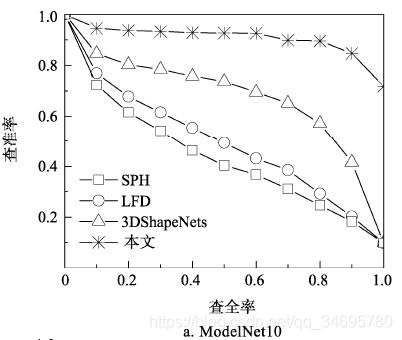
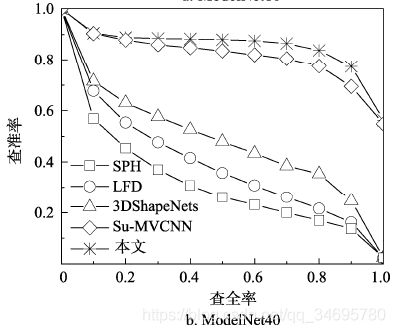
本文算法分类准确率具有一定优势。在更加复杂的ModelNet40数据集上,准确率位居第一。
(4)与其他分类算法的对比试验

从表上看出本文算法有效性,同时也揭示了本文算法在刚性三维模型的分类中还存在一些缺陷。
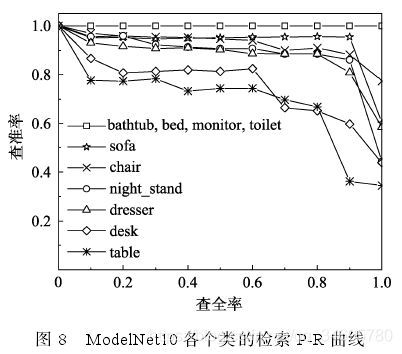
(5)各个类的根类结果分析

在bed,char,monitor,toilet分类准确率均为1;dresser次之,0.91;在desk,night_stand和table上分类准确率为0.86,0.84,0.75.
其中,table类和desk类在局部结构上有所区别,但是整体形状及其相似。可以看出本文算法在模型的细分类以及局部区域识别方面能力不足,因为无法有效区分这些模型所属类别。
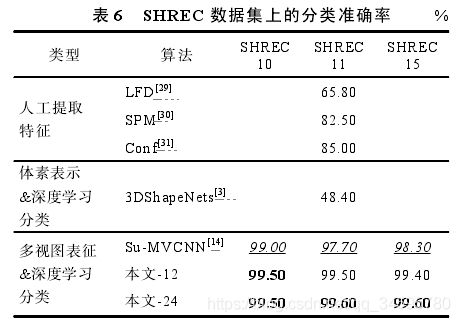
(6)非刚性三维模型分类实验对比
6.2、检索实验
设置视图数目n=12,选取modelnet和shrec完成测试。
(1)4种距离度量算法对比。
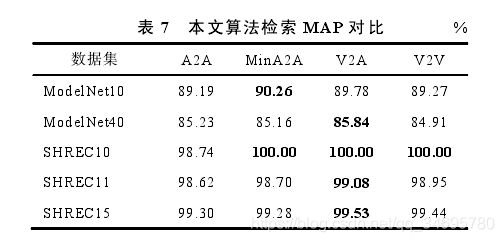
(2)刚性3D模型检索实验对比
本文算法和其他4种典型算法的MAP和P-R曲线。
各个类的检索结果。
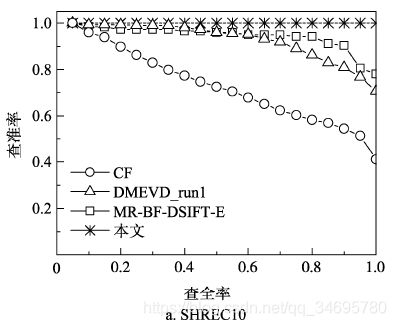
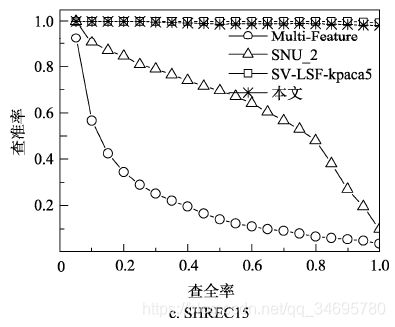
(3)非刚性三维模型检索实验对比
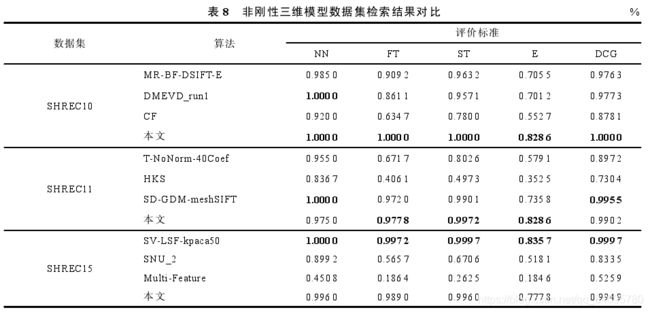
本文算法和其他算法的P-R曲线

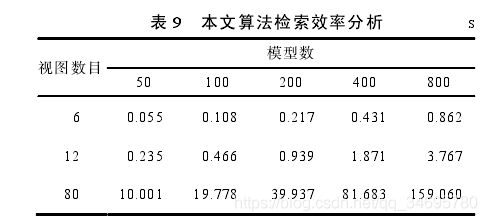
下图是使用V2A检索算法,运行时间如表
PS:
刚性三维模型具有以下特点
1、大多由规则的几何体组成,模型表面的几何信息也比较单一,大多是平面或规则的曲面;
2、局部特征往往几种在特定的功能区域,而不是分散于模型的整个表面,因此不同视角下视图捕获的特征信息较为相似,区别力相对较弱。